

1. 前言
随着移动互联网的发展,越来越多的业务数据和日志数据需要用户处理。从而,用数据去驱动和迭代业务发展。数据处理主要包括:计算和查询。计算主要为离线计算、实时流计算、图计算、迭代计算等;查询主要包括 Ahdoc、OLAP、OLTP、KV、索引等。然而,在数据业务中,我们时常听到数据需求方和数据开发方对性能慢的不满,所以,如何高效响应海量且迫切的数据需求,是大数据平台需要面对的一个关键问题,本文将介绍如何基于 Alluxio 建设分布式多级缓存系统对数据进行计算加速和查询加速。
2. 离线数据计算查询加速问题
对于加速组件,结合生态兼容性和系统成熟性的基础上,我们选择 Alluxio,我们知道,Alluxio 是通过 UFS 思想访问底层持久化的分布式数据。通常,我们的数据主要存放在公司私有 HDFS 和 MySQL 上。那么,如何通过 UFS 思想访问到私有 HDFS 数据进行加速是我们面对的主要问题。私有 HDFS 由于历史原因,其基于的 HDFS 版本较低,加上公司对 HDFS 进行了部分改造,使得开源的计算和查询组件访问公司内部的离线数据较为困难。因此,如何打通 Alluxio 访问私有 HDFS 成为了系统的关键,后面的章节中,我们会做相关介绍。
3. 基于 Alluxio 的解决方案
整体上,我们当前的多级缓存系统由私有 HDFS(PB 级别) + MEM(400G) + SSD(64T)共 3 层组成。 示意如下:
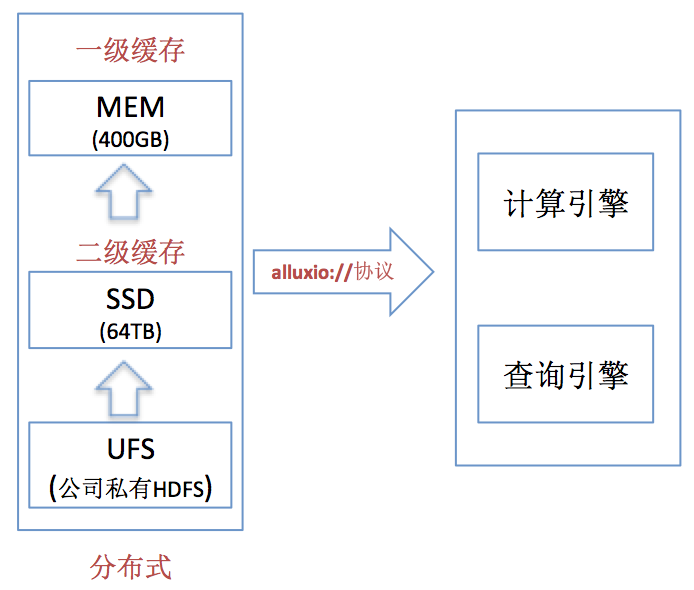
系统会根据类似 LRU 思想对热点数据进行缓存。我们主要存放热点部门核心数据。由于资源申请原因,我们的 Alluxio 在南方,UFS 在北方,所以后面的测试数据均为跨地域性能数据,提供基于 Spark、Hive、 Presto、YARN、API 等方式访问数据。
对于多级分布式缓存系统,我们实现的整体示意图如下:
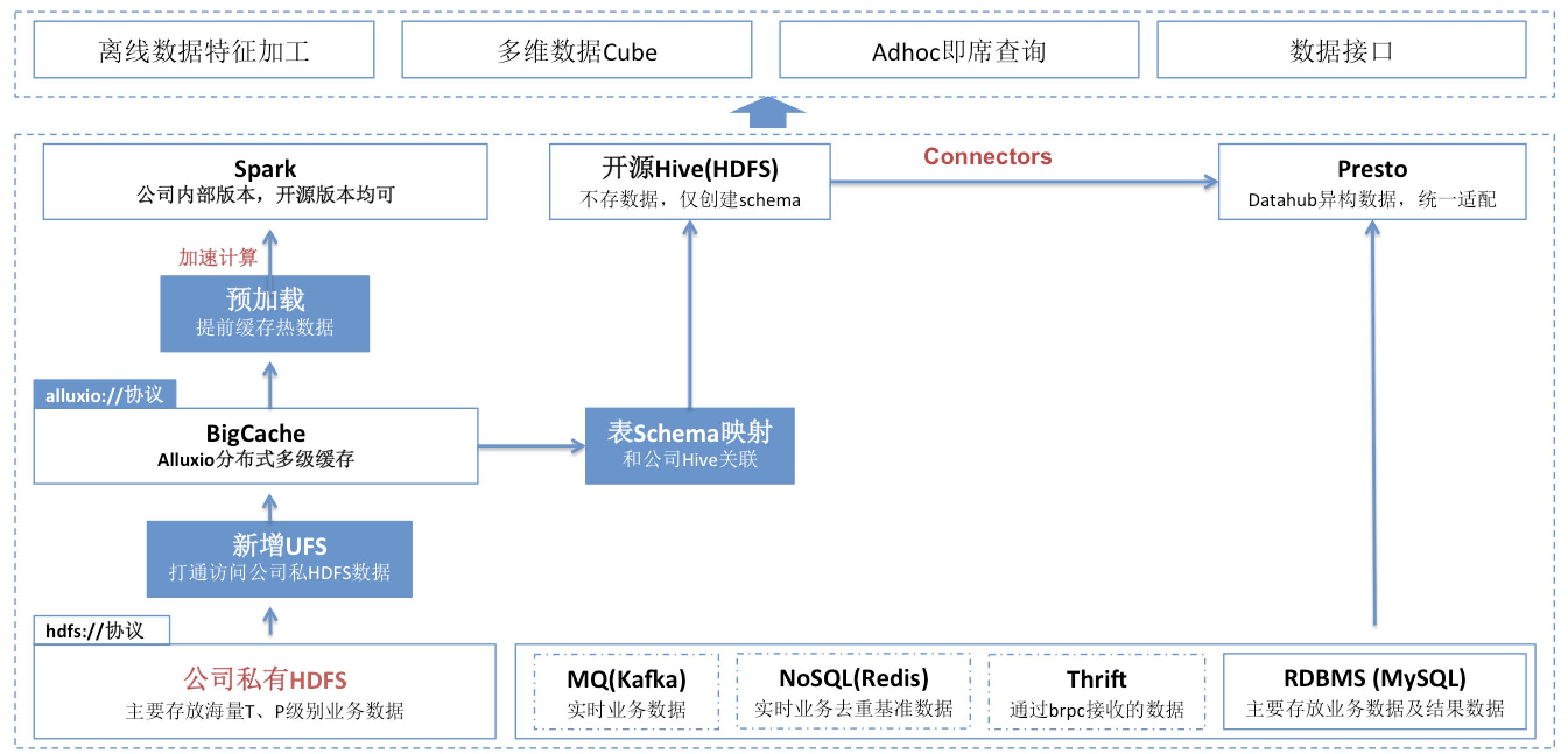
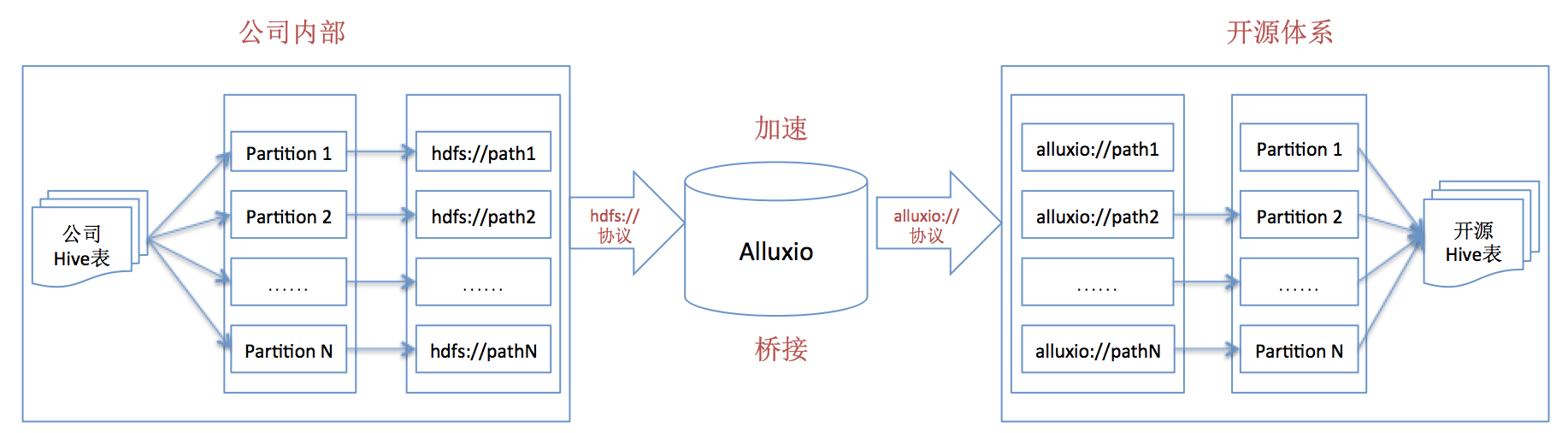
从上述方案中,我们可以看出,如果通过 path 路径方式访问私有 HDFS 数据,直接使用 alluxio://协议路径即可;但是,如果要开源的 Hive 或者开源组件(基于 Hive 桥接)以数据表方式访问公司内部的私有 HDFS 数据,需要进行“表 schema 映射”,思路如下图:
基于上述方案,可以大致抽象出使用 Alluxio 的几个一般性步骤,如下:
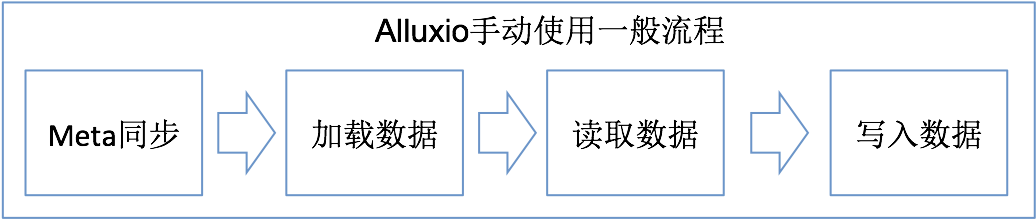
下面,我们会一一对每个步骤进行相关说明及案例数据分析。
3.1 Alluxio Meta 数据同步(load 和 sync)
由于 UFS 随时可能会有变动,导致 Alluxio Meta 和 UFS 的 Meta 不一致,那么,如何在 Alluxio 的 master 中同步 UFS 文件的 Meta 十分重要,由于 Alluxio Meta 的 load 和 sync 性能成本较高(对于 load 和 sync 区别,本文不赘述),官方不推荐过度频繁 load 和 sync Alluxio 的 Meta 数据。
3.1.1 同步方案
在我们的集群中,我们均采用了默认的配置,而对于 Aluxio Meta 和 UFS Meta 的状态主要有以下 3 种:
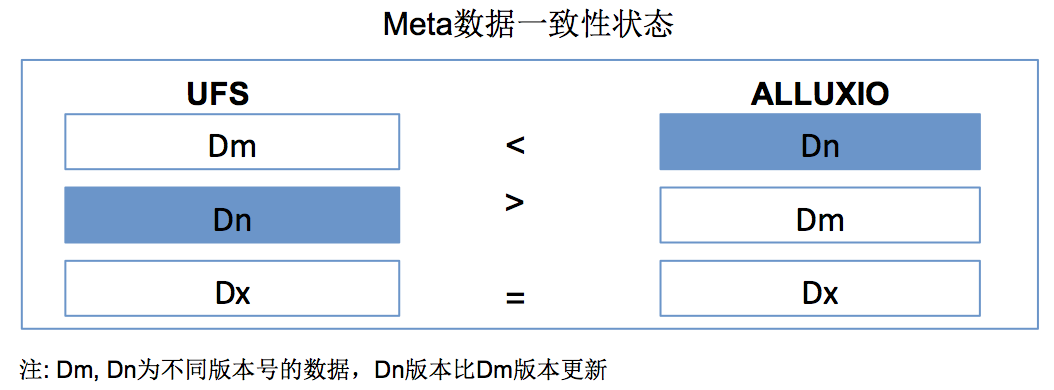
如果通过上面 2 种方法,Meta 无论如何无法同步(大家应该会遇到这类情况),可以考虑 fs rm -R --alluxioOnly path 从 Alluxio 中删除数据(仅删除 Alluxio 中的数据,不删除对应 UFS 上的数据),然后再 fs ls path 便可以让 Alluxio 中的 Meta 和 UFS 的真实 Meta 同步一致。
3.1.2 Meta 同步性能
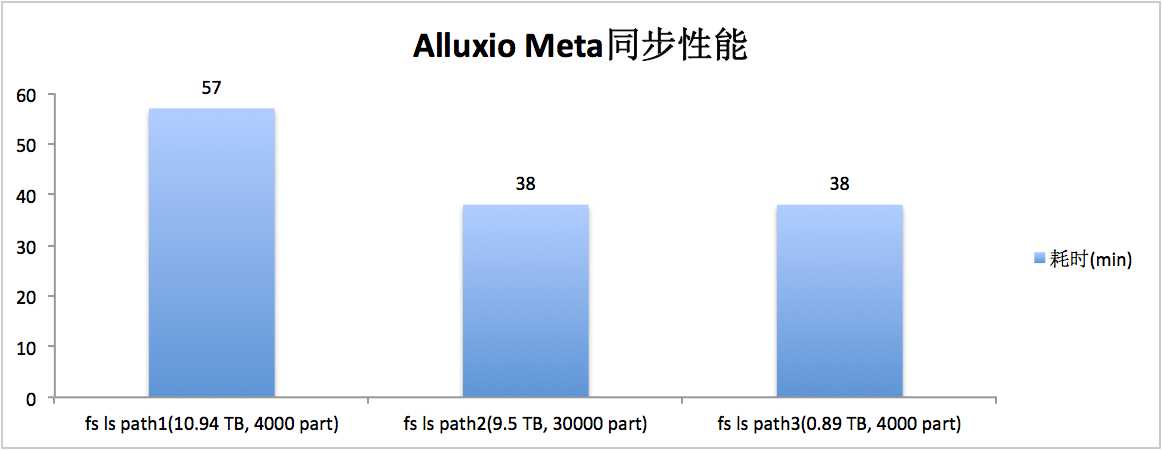
我们使用 Alluxio 自带的 fs ls 命令进行 Meta 同步,相关 Alluxio 设置如下:
上面的设置主要是为了解决网络超时,Meta 同步是非常耗时的操作。
数据同步性能数据如下(请忽略分区大小的合理性):
3.2 Alluxio 加载数据
3.2.1 数据加载方案
有了缓存系统,那么,我们需要提前常用数据预加载到缓存系统中,如此,当用户使用时候,直接从缓存中读取,加快读取速度。数据预加载的方式有如下图的 3 种方式:

3.2.2 数据加载性能
我们主要利用 Spark RDD count 方式来预加载数据,Spark 任务参数如下:
可以注意到上面开启了比较严格的探测执行,因为在实际应用中,我们经常发现极少个别 part 的 load 非常慢。所以,在严格条件下开起探测执行,既保证了计算执行效率,又不太会影响到集群性能。

3.3 Alluxio 数据的读取
3.3.1 数据本地化
本地化数据,相信大家都比较清楚,使用本地数据可以有效地提到数据读取效率,具体可以将每个 worker 节点的 alluxio.worker.hostname 设置为对应的 $HOSTNAME,熟悉 Spark 的同学知道,这个设置类似 Spark 中的 SPARK_LOCAL_HOSTNAME 设置。
3.3.2 读取性能数据 1(私有 HDFS->Alluxio->Hive/Presto)
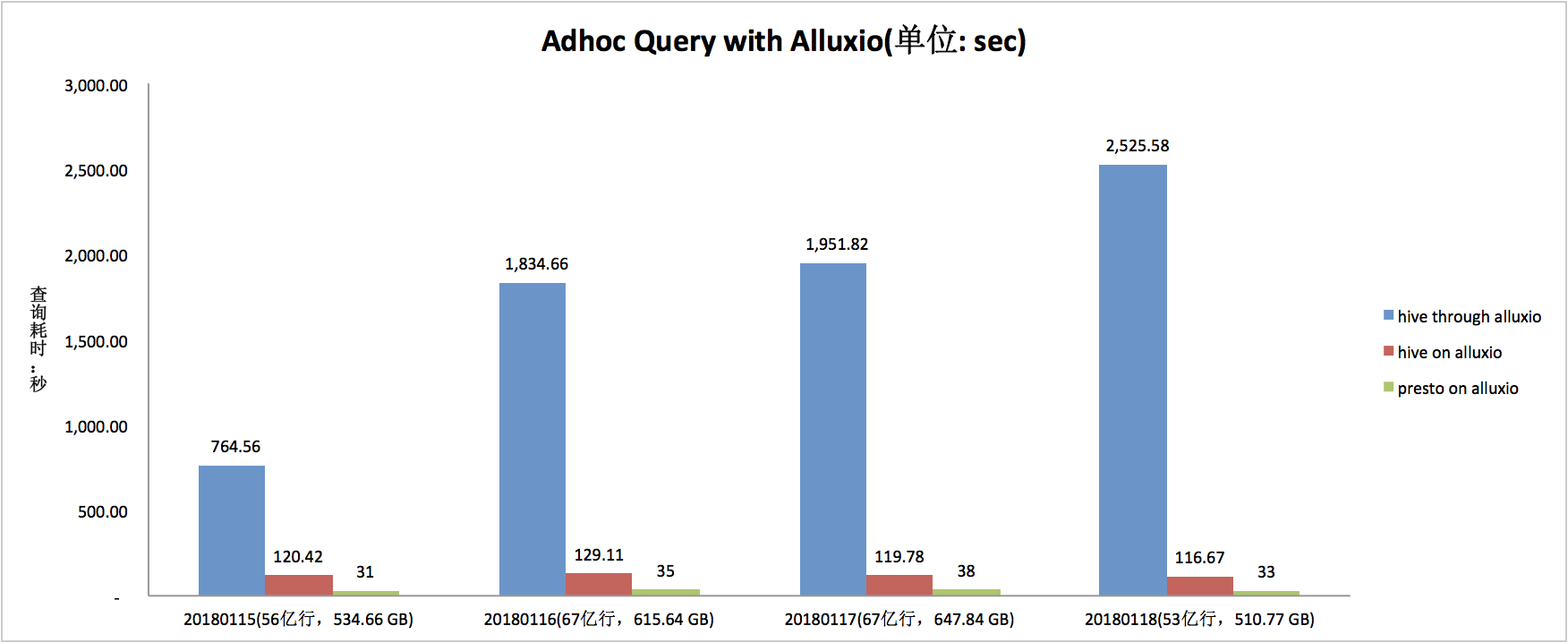
上图中,介词 through 和 on 的区别是,前者为首次从 UFS 上加载数据(即直接从私有 HDFS 上读取数据),后者为直接从 Alluxio 缓存中读取数据。
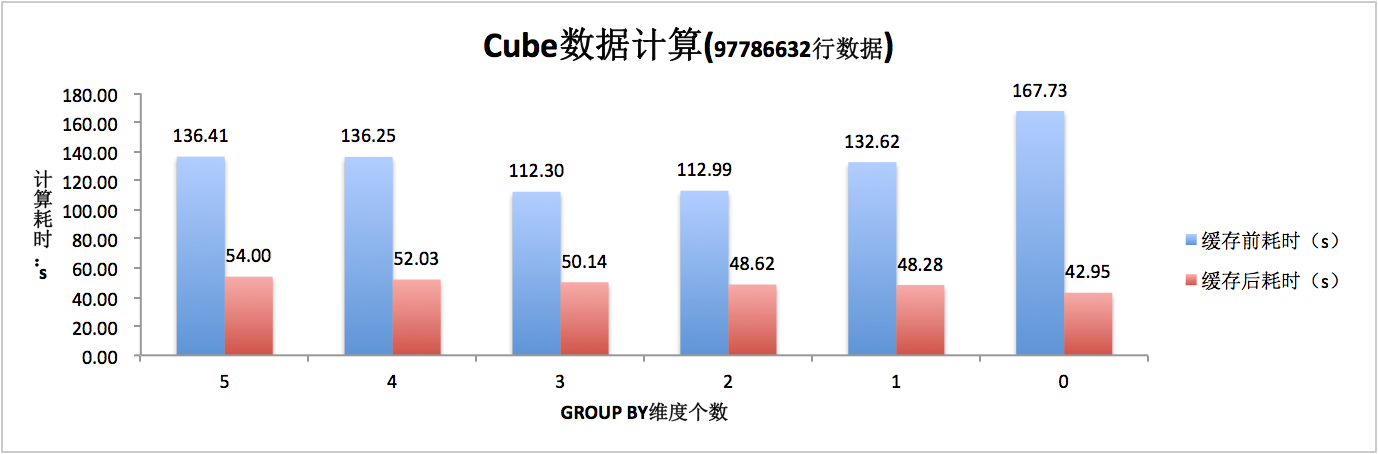
3.3.3 读取性能数据 2(私有 HDFS->Alluxio->Hive->Cube)
3.3.4 读取性能数据 3(私有 HDFS->Alluxio->Spark)
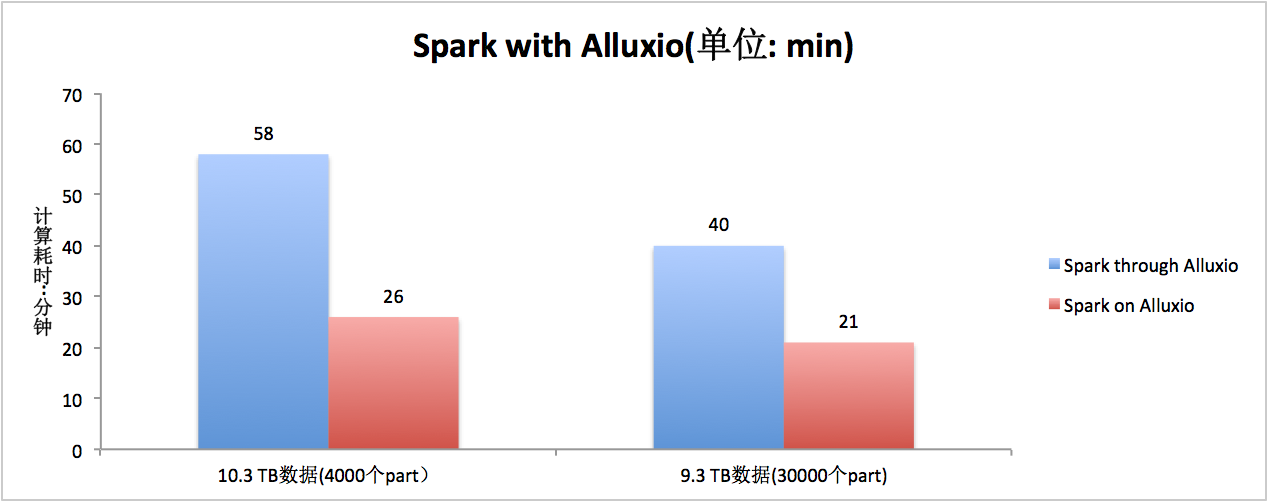
3.4 写入数据性能
3.4.1 通过 alluxio://写入
根据 Alluxio 官方介绍,写数据方式主要有 3 种:
Default write type when creating Alluxio files. Valid options are
MUST_CACHE(write will only go to Alluxio and must be stored in Alluxio),CACHE_THROUGH(try to cache, write to UnderFS synchronously),THROUGH(no cache, write to UnderFS synchronously).
本文仅测试 CACHE_THROUGH, 数据为 150G,8000 个 part,由于性能不佳,推测主要由于 Meta 同步导致,所以后放弃此方法,由于任务结算结果数据通常不大, 改用 MUST_CACHE 或者直写 HDFS。
3.4.2 通过 hdfs://直接写入
当结果数据无需缓存到 Alluxio 时,我们同样可以选择直接将数据写入到 HDFS,此方案也无需进行 Alluxio 和 UFS 之前的 Meta 同步。
4 Alluxio 集群建设
4.1 打通私有 HDFS
4.1.1 增加模块
由于公司内部的私有 HDFS 系统和开源最新版本的 HADOOP 生态难以直接融合,有些接口不支持,于是想到办法就是增加 1 个 UFS 存储支持。借鉴公司 Spark 对于私有 HDFS 访问思路,基于公司基础部门访问私有 HDFS 的动态库及 JNI 的思想,实现对私有 HDFS 的打通。
4.1.2 遇到的 libstdc++.so.6 及 libc.so.6 版本过低问题
关于 libstdc++.so.6 和 libc.so.6 的关系,本文不赘述。由于我们增加的 UFS 是利用 java 通过 jni 调用 so 库,而使用的 so 文件依赖的 libstdc++.so.6 版本较高,提示错误如下:
或者
可利用如:strings /usr/lib64/libstdc++.so.6 | grep "GLIB"查看 libstdc++.so.6 和 libc.so.6 的符号库版本。
其本质原因主要是,因为我们环境使用的 java 目录内部的 so 库依赖的 libstdc++.so.6 的路径有问题,可通过命令scanelf -F "%F %r" -BR $JAVA_HOME中的 so 对于 libstdc++.so.6 的搜索路径,同样也可以利用命令patchelf --set-interpreter和patchelf --force-rpath --set-rpath去修改优先搜索路径。
4.1.3 无法连通的问题
在测试连通公司私有 HDFS 集群的过程中,我们遇到了一个表现个比较奇怪的问题,就是启动 master 后,Alluxio 前端 web 页面菜单"Browse"点击无响应,debug 代码发现,某个 reentrantLock 的读计数没有正确降为 0(Master 启动过程中出现,所以 debug 时候需要设置 suspend=y,同时可从 AlluxioMaster 的 main 函数开始入手),导致一直处于死锁状态,这个问题排查了很久,近乎把 Alluxio 启动代码逻辑都看完了,代码上没有发现问题,后来无意发现是因为各节点(master 和 workers)上没有安装 Agent,因为前文提到 JNI 使用的 so 库需要通过类似代理的方式先访问 Agent, 利用本地的 Agent 去访问私有 HDFS。
4.1.4 recoverLease 函数
由于私有 HDFS 和和最新 HDFS 的差异,不存在 recoverLease, 这个函数主要在 XXXUnderFileSystem.java 中,主要用户当 Alluxio 的 journal 文件非正常关闭下进行恢复。目前,由于时间比较紧,这个功能暂时被跳过。
4.2 集群部署
相关机器配置和组件版本如下:
4.2.1 用户
Alluxio 集群使用 alluxio 用户创建,便于迁移及维护。如果是 root 账户部署,可能会减少不少权限问题,但是和 root 账号耦合度太高。所以,不推荐直接用 root 账号安装 Alluxio。
4.2.2 部署常见问题
4.2.2.1 日志显示
Alluxio 启动(bin/alluxio-start.sh)、关闭(bin/alluxio-top.sh)等脚本中的日志显示不够友好,都是用 echo 方式显示,它的启动关闭日志没有日期,对于新手来说,安装部署问题很多,而日志又没有时间,造成无法区分日志对应哪次操作,造成效率低下。
4.2.2.2 集群启动
目前的./bin/alluxio-start.sh [workers|master|all] [NoMount|SudoMount],它会默认不给任何提示,先杀死进程后再启动进程,而且不是类似 hadoop,提示进程运行中,需要先人肉杀死再启动,我们进行了改造。不然,对于缓存在内存中的数据丢失。
4.2.2.3 RAM 内存申请
为了保证速度,我们可能设置 MEM 作为一级缓存如下
那么在执行./bin/start-alluxio.sh workers SudoMount 时会提示出错,因为申请内存申请没有权限,解决方案,可以在/etc/sudoers 文件中增加一行: alluxio ALL=(ALL) ALL
5 未来计划
5.1 更多应用场景
本文中的多级缓存系统(BigCache)除了可以加速访问热数据外,还变相起到了桥接作用。
让原本无法直接访问公司存储系统数据的新生代开源计算查询组件,可以通过访问 alluxio 协议变相访问私有 HDFS 数据,从 0 到 1 开启了访问公司私有 HDFS 数据的可能!
另外,多级缓存系统不但在离线数据加工方面能有效加速,同时它亦可在对象存储系统中得到较好的应用潜力。
5.2 Hive 表映射自动探测更新
如上面第 3 章节提到,现在我们如果要让一些开源组件(基于 Hive 访问数据)访问到公司内部 Hive(私有 HDFS)的数据,我们需要人工建设表的 schema 进行映射,然后利用脚本进行表的 partition 加载,这一类通用工作,后续计划 web 化、自动化。
5.3 HA 的支持
这个问题在整个新增 UFS 模块开发中,耽误了非常多的时间,主要原因是因为我们底层是通过 JNI 利用公司基础部门的.so 动态库访问公司底层的私有 HDFS,在我们配置了 HA 后,重启过程中,会出现 core dump,参考了公司相关 wiki,定位成本比较高,所以后续需要对 core 的问题进行进一步排查,支持系统的 HA。
5.4 容器化部署
近年来,公司物理机器的配置越来越好,很多机器上都配置有 SSD 硬盘,而很多线上服务可能只用到了 HD 部分,对 SSD 的需求不大,所以如果能够通过混部的方式,将各台机器的 SSD 利用起来,形成一个巨大的多级缓存池,用来加速离线数据计算和查询,带来时效提高收益的同时,也大大提高了机器的利用率,降低成本。
5.5 易用性与性能
如上文一些章节提到,目前易用性还需要进一步提高,比如对于 In Alluxio Data 的搜索,某些数据缓存过期时间的设置,集群的维护等等都较为不便,同时,对于 Meta 同步、数据加载、数据读取等性能提高也有较大需求。
6 参考资料
https://www.alluxio.org/docs/1.8/en/reference/Properties-List.html
https://www.alluxio.org/docs/1.8/en/deploy/Running-Alluxio-On-Yarn.html
https://www.alluxio.org/docs/1.7/en/DevelopingUFSExtensions.html
https://www.alluxio.org/docs/1.8/en/operation/Troubleshooting.html
https://hortonworks.com/blog/resource-localization-in-yarn-deep-dive/
作者介绍
王冬,软件研发工程师,2012 年北京理工大学计算机本硕毕业,从事大数据领域 7 年多,先后负责大数据组件研发、大数据平台架构、大数据研发等工作,对大数据整体生态较为熟悉了解。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论