

本文来自“深度推荐系统”专栏,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要介绍深度 CTR 预估新积木:PNN + FFM - FM = ONN 模型[1],效果好于 DeepFM 和 PNN。
介绍
ONN 全称 Operation-aware Neural Networks,是在[1]中提出的一种新的用于点击率预测/广告推荐的深度学习网络模型,相比之前的同类模型,不同点在于丰富了 embedding 表达的处理:对于每个不同的操作(复制或内积)所使用的 embedding 方法不同,具体来说是每个特征都要在 embedding 层训练足够多的系数,产生足够多的中间结果向量,用于后面一次性的内积或其他操作。
初见这篇文章我是有点抗拒的,我第一反应判断这是灌水文,因为文章本身的影响力几乎没有,写作的方式和结构也不是很好,表达有些混乱,符号标记也不是很严谨规范,关键的是文章提出的思路我认为也不是特别精巧,也没有比较 solid 的工业级落地数据支持。不过实在扛不住它在业务数据上的表现优异,而且这几天也请假回家陪家人了难免有点不能继续工作的寂寞感,就顺带陪老人孩子聊天和洗菜做饭的时候顺带把这篇信息量不是很大的文章读完了,总结一下论文的方法和可取之处。
框架
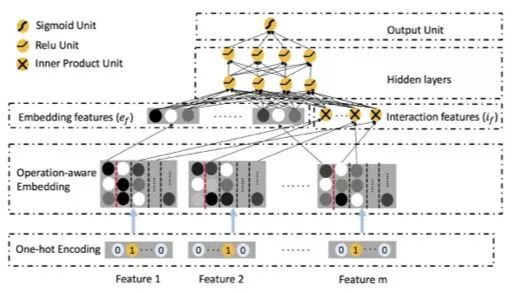
输入为经过 one-hot encode 的

个稀疏特征

,一般的 embedding 处理会给每个
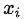
指定一个系数矩阵
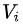
,这一层的输出结果
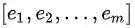
,其中

。而 ONN 则对
特征将要参与的每个操作分开训练 embedding 的系数,如果
要参与
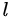
个操作,那么
经过 embedding 的计算结果为
个中间向量即
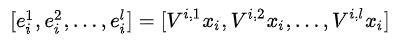
这些
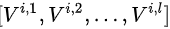
需要在训练时分别获得。文中把第
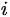
个特征与第

个特征的内积操作,与第个
特征与第
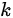
个特征的内积,视为不同的操作,需要分配不同的
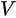
。
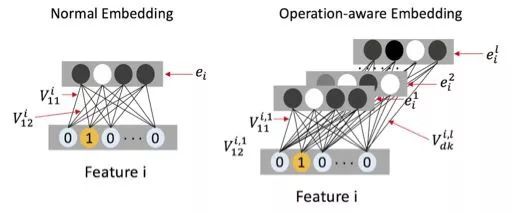
文中在 embedding 层之后只使用了对单个特征的复制,以及对于特征之间两两作内积的操作,这些结果作为 DNN 部分的输入开始 DNN 的训练。DNN 部分除了每层多加了 batch normalize,也没任何有别于传统 DNN 的地方,不再展开说明。
与其他模型的结构对比
FM 的 embedding 层并没有对特征区分不同的操作,embedding 之后即对

进行内积操作得到结果后简单的输出最终结果
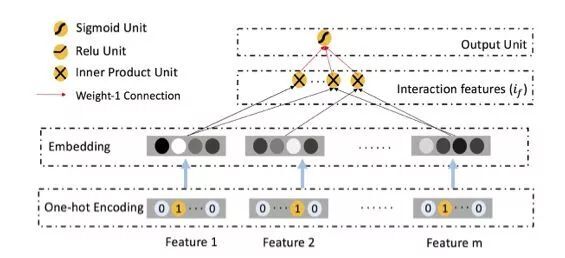
FFM 相比 FM 在 embedding 层加入了文中的 operation-aware 操作,即对每次不同的内积操作,同一个特征的 embedding 方法是不同的。但相比 ONN 没有 deep 部分以及 embedding 的原始结果作为 deep 部分的输入,所以表现力还是有所欠缺。
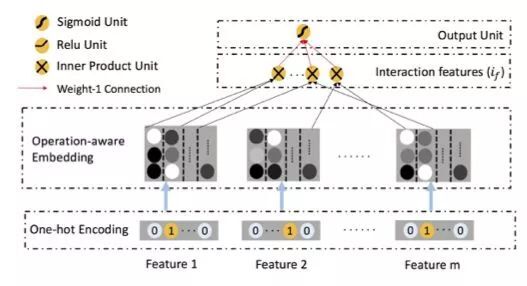
与 ONN 最相似的还是 PNN 的结构,除了 ONN 在 embedding 层没有对后续的不同操作作出区分,而 ONN 根据后续用以不同的操作区分生成了很多不同的 embedding 向量。
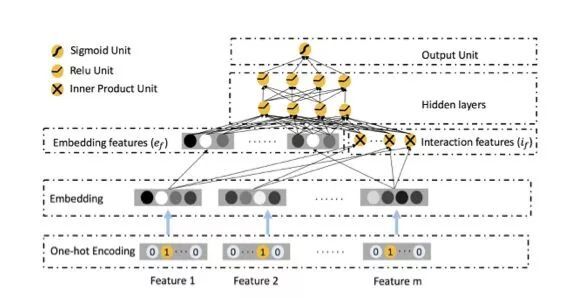
源码阅读
ONN 在 DeepCTR 库[2]对应的实现为 NFFM 模型。把关键的 embedding 和 inner product 部分代码摘出来是
使用总结
文章里面的数据很好,当然不好是不可能发的,所以讨论这个意义不大。
我自己在业务数据上使用的效果也非常好,比其他 deep based 的准确率高出很多,所以我特地去把文章读了一遍,感觉有点失望,因为原理上它确实没有太惊艳的地方,所以一开始我也怀疑是不是内置的 BN 起了作用,于是把 BN 关了发现效果也没降低太多。
随着后来观察到这个模型训练起来几乎是不可接受的慢,以及模型的参数数量远超其他模型,我大概能理解到底发生了什么,这就是简单粗暴的拓宽了假设空间,计算资源足够的情况下确实会更有可能学到更多的模式。而我的测试数据量也不大,所以用起来劣势没那么明显,真正在工业级场景落地则会对算力要求极高,所以……

文章给我最大的启发就是这种细致入微的系数分配和简单粗暴的增加模型复杂度的思路,
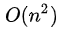
级矩阵参数的设置吊打

说明我们目前连训练集上的精度都还有很大的提升空间,就不要想着怎样在模型大小和效率上优化了。
参考
1. Operation-aware Neural Networks for User Response Prediction
2. https://github.com/shenweichen/DeepCTR
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/p/80830028
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论