
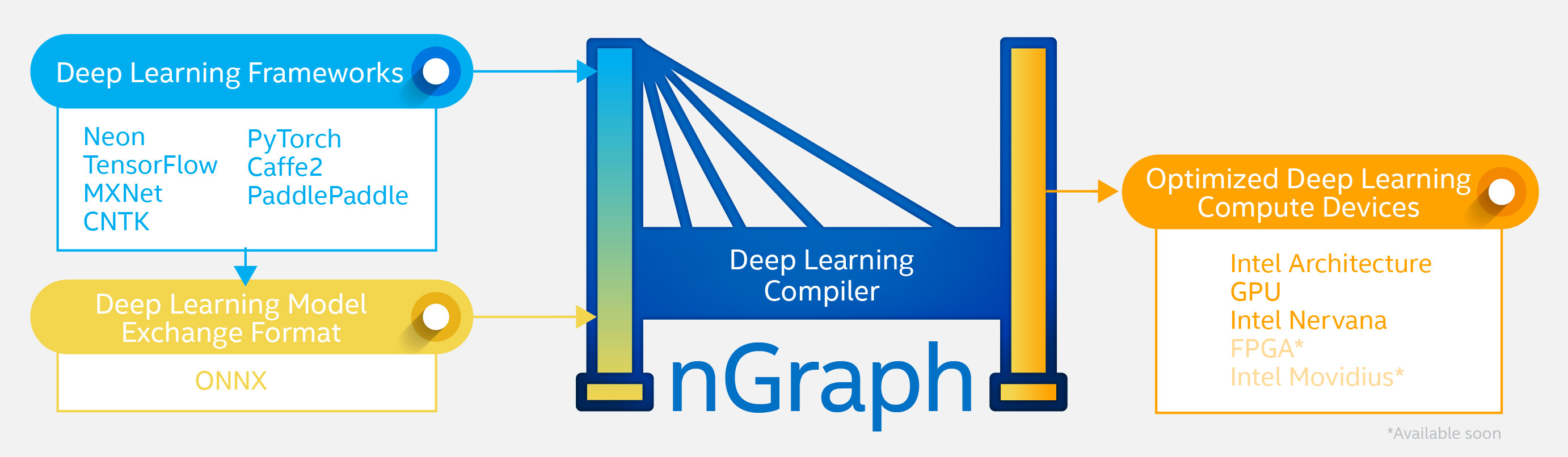
深度学习计算性能对于科学家和工程师来说至关重要,他们需要利用深度学习技术来应对医疗、上午、自动驾驶等诸多领域的挑战。这也是英特尔今年 3 月份将 nGraph 库和编译器的早期版本在 GitHub 上开源的原因。 我们很早就清楚地看到,开放标准和互操作性的横向协作对于帮助科学家和工程师在各自领域实现下一波突破至关重要。英特尔内部的很多研究人员已经开始使用 nGraph 探索更前沿的 AI 话题,比如使用同态加密使基于私有数据的推理成为可能。
我们将在今天正式发布:nGraph编译器堆栈的Beta版本。这一版本侧重于加速英特尔®至强®可扩展处理器上的深度学习推理工作负载,并具有以下主要特性:
为 TensorFlow、MXNet 和 ONNX 提供开箱即用的安装体验。
对 TensorFlow 中可用的 20 个常见工作负载、MXNet 中的 18 个常见工作负载、ONNX 中的 14 个常见工作负载做了优化并对优化效果做了验证。
支持Ubuntu 16.04(TensorFlow、MXNet 和 ONNX)和 MacOS X 13.x 版本(支持 TensorFlow 和 MXNet 构建)。
这一版本对已经在生产环境中广泛部署的一些常见工作负载均做了优化。这些工作负载涵盖了各种类型的深度学习,包括:
图像识别和分割
物体检测
语言翻译
语音生成和识别
推荐系统
对抗生成网络(GAN)
强化学习
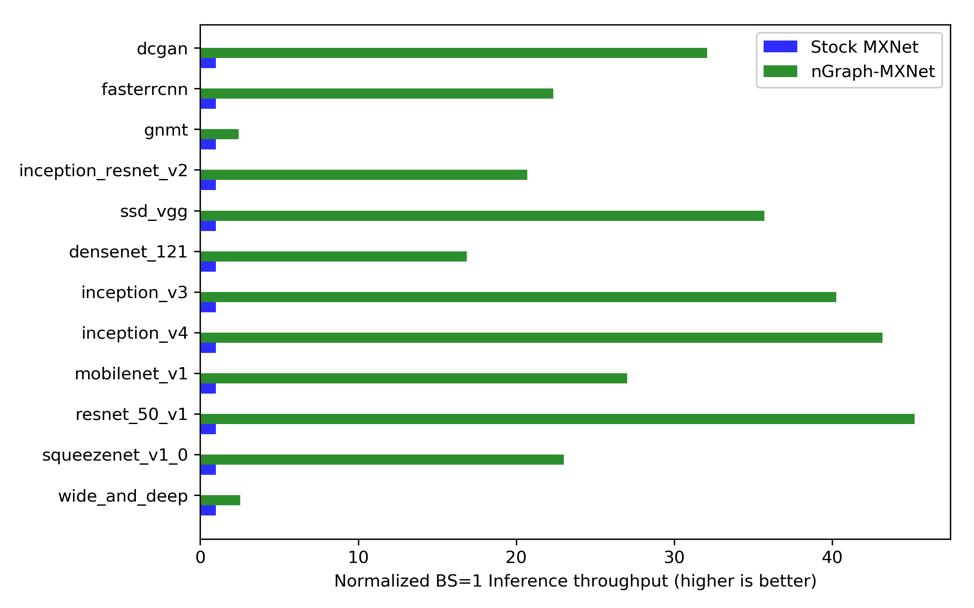
图 1 使用 nGraph 对 MXNet 推理性能的提升效果
在我们的测试中,优化后的工作负载最多可以比原生框架快 45 倍,并且我们期望通过下面描述的强大的模式匹配功能来提升其他工作负载的性能。
传统上,为了从硬件中获得更高的深度学习性能,用户必须等待硬件制造商创建并更新内核库,这些内核库能在“立即模式”执行接口中公开(有时需要手动调整)各个操作。虽然这些内核优化通常会带来惊人的性能提升,但它们往往是基于特定硬件的,这就预先消除了在非特定设备上优化的任何机会。通过匹配非特定设备和特定设备的优化,我们可以解锁更多性能提升的可能,这就是我们构建 nGraph 编译器的原因。
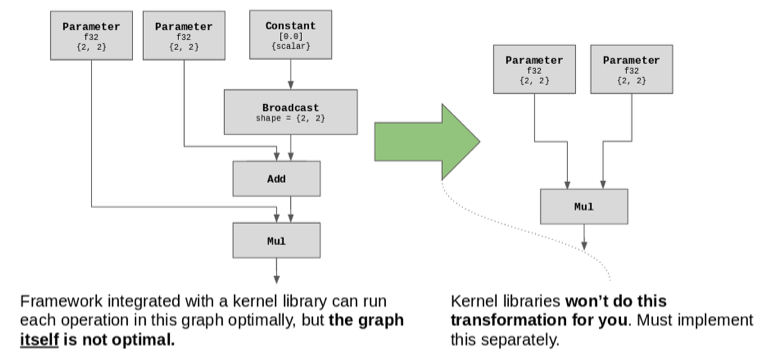
在我们发布的 Beta 版本中有许多关键特性:nGraph 是第一个同时支持训练和推理且支持多个框架的图形编译器;它允许开发人员将同一概念模型或算法设计自由地用在不同硬件后端。 这些特性中的任何一个可能都已经足够好;综合起来,这些特性使开发人员确信他们的神经网络(NN)设计不仅可以不断扩展,而且还能适应各种变化因素。未来,适应性将变得越来越重要,对于开发人员来说,要提前猜到后续可能需要大量或复杂优化的机器学习问题的界限将越来越困难。
在我们计划于 2019 年 Q2 初发布的 Gold 版本中,我们将进一步扩大更多框架上工作负载的覆盖范围,包括对量化图和 Int8 格式的额外支持。我们设计 nGraph 编译器以支持不断增加的 AI 硬件列表,因此英特尔®Nervana™神经网络处理器和其他加速器的早期采用者将能够在整个 2019 年使用 nGraph 编译器进行测试。更多详细信息,请参阅我们的生态系统文档。我们建议你查阅我们的快速入门指南或下载最新版本的 nGraph,如果有任何反馈或评论,欢迎你在GitHub上告诉我们。
阅读英文原文:nGraph Compiler Stack–Beta Release


InfoQ主编

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论