

在本文中,作者将介绍 Freewheel 如何在面对 2000 万用户订阅的条件下,利用机器学习技术为客户构建广告投放方案,并在有效触达的同时从整体上降低成本,提升广告预算利用率。
写在前面
在计算广告领域,虽然互联网数字广告势不可挡,但到目前为止,传统电视广告仍与之分庭抗礼、不分伯仲。康卡斯特(Comcast)在全美范围内为 2000 万订阅家庭提供有线电视接入服务,并为数以千、万计广告主提供广告投放业务。传统电视广告投放相对刻板,在社区范围内,同一时间同一频道所有住户观看的都是同样的广告创意,这与互联网数字广告基于千人千面的个性化投放有着天壤之别。在电视广告个性化投放方面,康卡斯特走在行业前列。基于 Freewheel 全局优化广告投放引擎,康卡斯特旨在为家庭用户提供差别化的观看体验,为广告主提供更加精准的受众定向服务,在有效触达的同时从整体上降低成本,提升广告预算利用率。
图-1 计算广告 2010-2019 市场份额占比趋势图(按媒体类型分类)
广告投放全局优化的基础,是稳健地预测未来一段时间,有多少当量的广告库存可供投放。基于现有的投放需求与未来的库存情况,从全局上对供需进行分配,才能更好地指导投放引擎的执行策略。在这样的业务背景下,我们基于 2000 万订阅家庭的投放历史,构建机器学习模型,以小时为粒度预测未来 90 天康卡斯特全网电视广告库存。
Freewheel 业务遍布欧美,每天的电视广告投放请求达到 10 亿级规模。为符合 MRC(Media Rating Council)与 GDPR(General Data Protection Regulations)数据安全相关标准,与用户有关的数据只保留脱敏后的 ID 编号。同样,为符合相关法律法规,与地区、频道相关的信息也只保留脱敏后的 ID 信息。虽然投放历史数据量巨大,但是贫瘠的字段信息对于机器学习的模型构建来说无疑是个艰难的挑战。

图-2 数据源数据模式
为弥补属性特征的不足,我们从特征生成和时序特征两个角度出发来丰富特征向量,尽可能地让模型挖掘、捕捉用户的观看模式和广告库存的分布。在电视广告场景中,广告库存主要取决于两个方面,一方面是相对固定的电视台节目安排,术语叫作 CBP(Commercial Break Pattern),也即一个时段中在哪些时间点提供多少广告位;另一方面取决于用户的观看习惯,用户的观看习惯(在不同地区、不同频道的观看历史)决定哪些广告更容易曝光,哪些广告还没来得及曝光用户就已经切换频道。因此用户的观看历史时序蕴含丰富的库存分布信息,这些信息对于模型的拟合来说至关重要。
时序特征的引入需要我们采用时序预测模型来对样本进行拟合。我们的业务目标是在不同维度组合上预测未来 90 天的广告库存,具体来说,模型应该有能力预测未来 90 天每个地区在所有频道上每个小时的广告库存。康卡斯特在全美有大约 600 个地区,提供约 40 个频道的接入服务。一种模型选型是我们为所有这些维度组合(600 * 40)都提供一个独立的时序预测模型。这种方法的优点是简单、直接,模型比较纯粹,只需要训练时序特征,因历史数据量足够大,不用担心拟合问题。
同时模型受到的数据干扰较小,模型不会因为不同维度组合之间数据分布方差较大而倾向于平均化、折中化,只需负责拟合一份相对稳定的数据分布即可。另外,每种组合训练一个模型,当预测结果变动较大时,对于业务的可解释性也更友好。然而这种方法的缺点也很明显,前期工程开发与后期产品维度的成本都很高,因此我们需要一种可以同时考虑静态属性特征和时序特征的模型结构。
结合之前的工作经验,同时受机器学习推荐场景的启发,我们尝试采用 Wide&Deep 的网络结构来构建一个统一的模型来捕捉所有维度组合下的时序规律,在降低工程实现成本的同时,保证模型的整体性能。
特征工程
我们首先以小时粒度把数据源按照维度组合进行聚合,统计每个维度组合上每个小时的广告库存。

图-3 按地区、频道、小时聚合后的数据样本
模型的特征向量主要由三部分构成,ID 类属性特征,生成特征和时序特征。属性特征和生成特征交给 Wide 部分学习,时序特征交由 Deep 部分拟合。属性特征如图中的地区 ID、频道 ID、电视台 ID;生成特征是指由“广告曝光时间戳”衍生出的相关时间特征,如小时、时段(美国将一天划分为多个不同的时段,如晚间黄金时段,早间新闻时段等)、周几、是否周末。时序特征是指不同维度组合过去 30 天的以小时为粒度顺序排序的库存序列。预测标的则是未来 90 天以小时为粒度顺序排序的库存序列。
需要指出的是,生产系统中保存的是广告曝光数据,以[地区 x 频道 x 小时]为粒度对不同广告位的曝光量进行汇总,并不能保证该划分粒度在时间上能构成连续时间序列,也即 24 小时中,有些小时是缺失的。缺失的小时意味着在那段时间内,没有广告曝光,曝光量为零。因此,我们需要做负样本补齐工作(正负样本比在 1:75 左右),从而在之前的划分粒度上形成完整的时间序列。这意味着,我们需要根据[地区 x 频道 x 小时]最细粒度的关联键将正负样本关联。
因两份样本数据量巨大,我们采用分布式计算引擎 Spark 进行数据处理。如果不采取任何优化措施,Spark 默认采用 Shuffle Join 来关联正负样本表,这会引入大量的网络 IO 与磁盘 IO,需要 4 个小时才能完成数据的关联。给定正样本是负样本的 1/75,很容易想到采用 Broadcast Join 来避免 Shuffle 过程,避免数据分发带来的网络开销和磁盘开销。但我们的正样本数据量过大,广播变量(2G)无法容纳,一种办法是强行修改广播变量大小,让其可容纳全部正样本,但是这种“强扭的瓜”会带来新的问题。
Spark 采用点对点(Peer to peer)的方式实现广播变量的分发,如果广播变量过大,在分发的过程中网络开销会呈指数级增长,并不比 Shuffle 带来的网络开销更小,因此强行修改广播变量参数不可行。唯一可行的思路是把正样本“变小”,让它可以放进广播变量。我们仔细观察数据模式,发现大部分字段都是关联键,只有库存量是需要关联在一起的字段。由此可见,正样本中的大部分存储空间都被关联键占据,但我们真正关心的是关联表 Payload,也即我们场景中的库存量。受 Hash Join 实现原理的启发,我们将 7 个 Join keys 拼接在一起并计算其哈希值作为新的 Join key,并将新的 Join key 与 Payload 拼接在一起形成新的样本表,原始的 Join keys 在新的样本表中被抛弃。
新样本表与原样本表相比,所需存储空间降低一个数量级,足以放入广播变量中。在负样本表中对 Join keys 做同样的操作,生成与新的正样本表对应的 md5 哈希关联键,用于与正样本表关联。与正样本表不同的是,负样本表需要保留原始的 Join keys,用于后续的特征工程(索引化、向量化等)。值得注意的是,用 md5 哈希值替代原始的 7 个 Join keys,在数据量较大时,需要考虑可能的哈希冲突问题,不过我们在 10 亿级样本的场景下,经过多次试验验证,未发现哈希冲突的情况。将 Shuffle Join 转化为 Broadcast Join 之后,执行时间从 4 小时降低至 20 分钟左右。
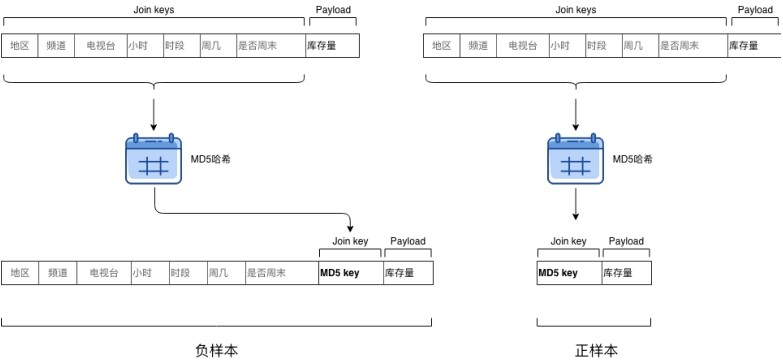
图-4 将原始 Shuffle Join 转换为 Broadcast Join
模型选型与调优
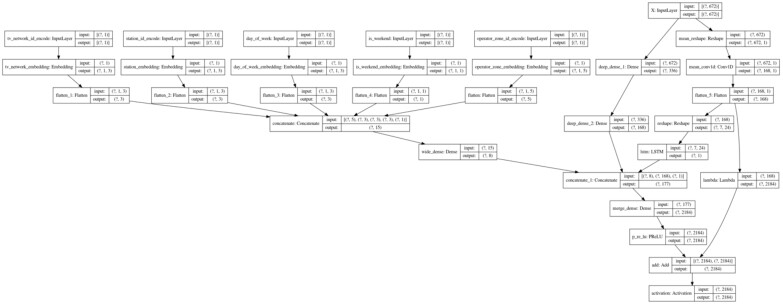
图-5 最终版模型网络结构
最终版模型网络结构如上图所示,左侧 Wide 部分承载属性特征与生成特征,Deep 部分的设计用来捕捉用户观看习惯。模型的演进经历多次 Deep 部分的调整与改进。对于时序预测,通常想到的算法簇是 RNN/LSTM/GRU,因此在第一版模型的 Deep 部分,我们用 MLP 结合 LSTM 的方式来学习时序数据中的规律与特征表示,最终与 Wide 部分拼接对未来 90 天库存进行预测。对于模型效果,一方面采用 MAE、MSE 等机器学习指标来衡量,另一方面采用基于不同维度(如基于地区、基于频道或基于时间)的统计 MAPE 等业务指标来衡量。
第一版模型效果与对比基准四周中位数相比稍好,但因数据量较大且 LSTM 串行计算,模型训练时间过长,在 10 台 ml.c5.4xlarge 配置的 AWS SageMaker 中,需要运行 2 天。在我们的场景中,时间步长为 672(28 天 * 24 小时),过长的时间序列会增加梯度在 BPTT(Back Propagation Through Time)反向传播中消失的概率,进而导致收敛速度变慢,进一步从整体上拖慢执行时间。
为大幅降低模型训练时间,在第二版模型中,我们采用“截断序列”的方式进行改进,也即对于 672 步长的时间序列,我们只截取就近几个(超参数)步长的序列作为 LSTM 层输入。经过多次对比试验,我们发现截取 168(7 天 * 24 小时)个步长时,能够在模型效果(平均 MAPE=30%)与训练速度(10 小时)之间达到平衡。但这与我们的目标相差甚远,我们期望平均 MAPE 能控制在 10%左右。“截断序列”虽然可以有效降低训练时长,但同时也带来严重的信息损失,这也是模型效果无法进一步提升的根本原因。
不过,第二版“截断序列”的实验给我们更多启发,即在不考虑突发事件和大型节日的情况下,用户观看电视的习惯是相对稳定的。对于互联网平台上的视频内容,用户有主动权和选择权;但在电视视频中,用户看到的节目内容都是事先编排好的,用户对于视频内容的消费是被动的。对于某个用户来说,可选择、感兴趣的频道与时段,很可能是相当有限的,因而观看习惯相对稳定。
我们假设周与周之间的观看模式是相对固定的,那么就可以想办法将 28 天的时间序列以周为单位进行折叠,从而在不损失信息的前提下将时间序列变短。参考行业中将 CNN(卷积神经网络)应用到时序预测场景的案例,我们在第三版改进中加入一维空洞卷积,用于对时间序列进行转换,将(672 步长,1 维)的时间序转换为(168 步长,4 维)时间序,再输入到 LSTM 层。改进的初衷是在不损失时序信息的前提下,降低执行时间的同时提升模型效果。因为训练时间较长,较难通过描绘训练损失与验证损失之间的关系来判断模型欠拟合或过拟合,我们采用早停法(Early Stopping)让框架帮我们决定最佳的收敛位置,在多次试验后,模型平均 MAPE 控制在 15%左右。
第三版模型性能的提升验证了我们的假设,即电视观看行为是相对稳定的。在这个假设成立的基础上,我们可以引入梯度提升算法的思想来进一步优化模型。梯度提升算法的核心思想之一,是以步进、阶段式的方式,通过拟合真值与上一个弱预测模型之间的残差,来完成当前一轮迭代中预测模型的构建。既然我们已经验证电视观看行为是相对稳定的,那么我们是否可以尝试预测实际观看行为与稳定模式之间的残差,来改进模型的预测效果。基于这样的构思,我们将 Wide&Deep 网络调整为上图中的结构。注意网络结构中最右侧的分支,该分支主要负责捕捉平均的、稳定的电视观看行为。除最右侧分支以外的其他网络结构,沿用第三版模型的网络设计。
模型在输出之前,将第三版模型输出与稳定的观看行为按元素相加,然后通过激活函数计算得到最终的预测序列。很显然,在最终版模型中,我们尝试构建 Wide&Deep 网络结构来学习实际观看行为与稳定观看模式之间的残差,通过将残差最小化来提升模型的预测性能。残差是期望为零的分布、有正有负,RELU 激活函数会将负值归零,这会导致负残差的梯度为零从而无法训练,因此我们用 PRELU 替换 RELU,让模型有能力将负方向的残差也降到最低。对第四版模型多次试验后,平均 MAPE 降低至 10%左右,基本达到最初的预期。
随着效果的提升,模型的复杂度也越来越高,相关超参数越来越多。如何合理有效地选择超参,一直是算法同学需要攻克的问题。一般来说,我们基于对业务、数据和算法的理解,对每个超参给定一个搜索范围,然后随机生成几种组合,针对对比基准,分别进行对比试验,最终采用效果最好的超参组合来构建网络。
比如对于学习率来说,通常在 1e-1 到 1e-5 范围进行搜索。但通常我们需要调整的超参数量较多,而且超参的值域相差较大,如刚刚提的学习率、学习率衰减系数、优化器的选择、激活函数的选择、MLP 层数的选择、神经元数量、卷积核个数、LSTM 神经元等等。仅凭借算法同学随机选取超参组合是不够的,因此我们需要一些方法来辅助我们自动选择可能带来更高性能的超参组合。常见的方法有网格搜索和随机搜索,但这些方法效率低下。当训练时间较长,比如在我们的场景中,一次全量训练需要至少 10 个小时,很难在较短的时间内找到效果更好的组合。网格搜索和随机搜索更多地是提供一种工程上自动化的方法,免去算法同学每次随机选择超参后都需要重新启动任务的麻烦。
从算法的角度看,网格与随机搜索并不比算法同学更明智,这些方法把每一次尝试都看作独立事件,并不会利用已有经验去寻找更优解。与之相对,Bayes 优化用机器学习算法来对每次尝试(超参组合采样点)进行拟合,通过后验概率不断调整先验分布
(基于高斯过程的 Bayes 优化),使用可以保证“探索”与“利用”平衡的采样函数(Acquisition Function)来选择下一次尝试的超参组合,如此往复迭代。样本越多,高斯过程越逼近真实分布,采样函数有更大的概率采样到更好的超参组合。
我们采用基于高斯随机过程的 Bayes 优化作为对人选超参的补充,将人选超参作为初始值,调用 Bayes 优化来训练模型。不过在 12 轮迭代后,令人失望的是,Bayes 优化并没有给出比人选超参更好的超参组合。因为时间的原因我们没有再增大迭代次数,虽然 Bayes 优化没有给出更好的结果,但使用 Bayes 优化的初衷之一是增强我们对于人选超参的信心。换个角度来看,在我们的实验中,Bayes 机选超参与人选超参还有一定差距,在 Auto Machine Learning(特征工程自动化,模型选型自动化,超参调优自动化)蓬勃发展的当下,算法同学暂时还不会被 Auto Machine Learning 取代而失业,这倒不失为一个好消息。
深度模型的优化难点在于,各个维度方向二阶曲率的巨大差异,造成深度模型的成本函数空间异常复杂。在经典算法中,优化主要围绕如何绕开局部极小点;而在深度模型中,优化围绕在如何跳过“鞍点”、“盆地”,避免因不同维度方向二阶曲率差异过大导致的在梯度下降过程中反复震荡的问题,如此种种。一些一阶优化算法,如带动量加速的 Momentum,能够很好地跳过“鞍点”;根据二阶曲率对不同方向梯度下降学习率进行调整的算法如 RMSPROP,ADAM,能够很好地解决反复震荡的问题。但是对于成本函数空间中的“盆地”、“悬崖”等复杂“地形”,这些算法依然无能为力。为了让模型的预测性能更稳定,我们引入 Polyak 平均(指数衰减平均)来计算最终的模型权重。通过早停法(Early Stopping)得到的权重,往往是围绕某个局部极小点震荡多次之后的权重向量,很难完全收敛到梯度为零的权重向量。Polyak 平均的思路简单、直接,通过求取早停之前所有权重的指数衰减平均,来构建最终的深度模型。采用 Polyak 平均后,我们的深度模型能够稳定地将平均 MAPE 维持在 10%以下。
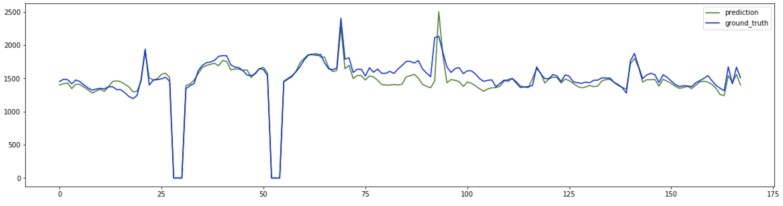
图-6 未来 168 小时(7 天*24 小时)某电视频道预测库存与实际库存对比
我们的预测标的是未来 90 天以小时为粒度的库存,如果采用 Tensorflow 默认的成本函数如 MSE,会对 2160 个小时(90 天 * 24 小时)的预测值、真实值作为整体计算 MSE,这与我们的预期不符。我们需要模型将未来 90 天的每个小时区别对待,尽可能都预测的足够准确。如果基于整体计算 MSE,在反向传播过程中每个小时都乘以同一个误差初始值,很显然这是不科学的。每个小时的反向传播,应该只依赖于该小时的预测误差,为此,我们设计基于 Element-wise 的 MSE,也即每次前馈计算的误差也是一个 2160 维的向量,而不是基于整体计算 MSE 的单一值。
工程部署
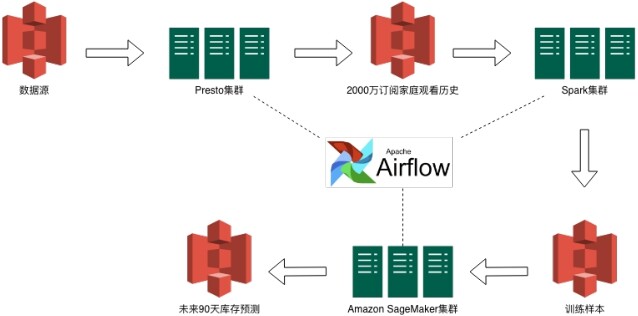
图-7 端到端离线工程工作流
Freewheel 现有业务都已云化,我们的端到端部署均采用云原生组件(S3,Presto,Databricks,Amazon SageMaker),如上图所示。Presto 分布式集群用于从 S3 获取数据源,得到 2000 万订阅家庭的观看历史并存储于 S3。Spark 集群用来进行数据处理、特征工程以及样本工程,最终生成可供 Wide&Deep 模型训练、验证的训练样本。SageMaker 是 AWS 在 2017 年 re:Invent 大会推出的云原生分布式模型训练与服务平台,支持多种主流机器学习框架如 Tensorflow、MxNet、PyTorch、Caffe 等。
Freewheel 采用 Keras/Tensorflow 进行开发,通过 SageMaker 分布式集群部署机器学习应用,完成模型的分布式训练与预测。每个分布式组件都以 S3 数据的方式对上个组件构成依赖关系,为方便维护分布式任务之间的依赖关系以及更流畅的任务调度(启动条件、执行状态、重试机制等),整条 DAG(有向无环图)工作流交由 Airflow 进行调度、维护和管理。工作流的输出结果是存储在 S3 的未来 90 天库存预测,不同于传统以模型为接口的离线、线上耦合方式,在我们的场景中,离线训练、预测以预测文件为接口和下游服务进行对接。一方面是因为下游服务以天为粒度进行全局优化,实时性要求相对较低;另一方面以文件为接口的方式大大降低系统的耦合度,使得下游系统在实现上更加灵活,如下游系统既可以直接访问 S3 获取预测结果,也可以将外部表与 S3 数据关联,通过数据仓库在前端 UI 对预测结果、趋势进行展示,方便客户查看。
用户观看电视的行为模式相对稳定,因此我们不需要频繁地全量训练模型,但同时为保证模型能够捕捉最新的行为变化,我们采用迁移学习的思路来迭代模型。即用全量数据完成一次模型初始化,随后每天用新增数据对模型参数微调,保证模型性能的同时提升工程效率。与全量数据相比,每天新增数据大幅减少,增量训练只需 10 分钟即可完成。因此我们在 Airflow 中建立两套 DAG,一套用于全量训练,冷启动模型,属于一次性任务,为模型性能打下基础;另一套用于每天以新增数据更新模型权重,属于定时任务,保证模型性能同时,大幅降低系统端到端执行时间。系统在部署之初,运行第一套 DAG,一旦完成,启动第二套 DAG 每天定时执行增量训练任务。
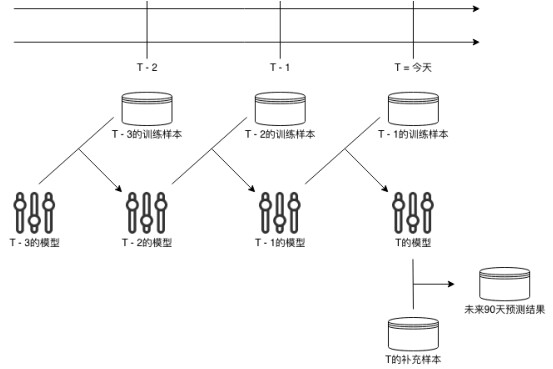
图-8 迁移学习增量训练示意图
一些“失败”的尝试
在介绍数据源的时候提到,我们的数据模式比较贫瘠,比如频道特征,除 ID 本身没有其他的属性信息(如频道的类别),良好的属性特征能够帮助模型更好地区分不同频道之间的差异。受推荐场景的启发我们想到,用户与频道的交互关系(用户倾向于观看哪些频道,厌恶哪些频道),实际上和推荐领域中用户与物品之间的关系如出一辙。基于矩阵分解的协同过滤算法被广泛应用于搜索、排序、推荐等业务场景中,矩阵分解产生的隐式用户矩阵和隐式物品矩阵,一方面可以用来直接计算相似度从而用于推荐,一方面隐式特征向量本身可以作为用户或物品的 Embedding 特征,用来扩充模型的特征向量。
我们用 Spark 统计过去一个月用户与频道的交互历史,并使用 Spark 内置的 ALS(最小交叉二乘协同过滤)算法计算隐式用户矩阵和隐式频道矩阵。将每个频道的 Embedding 隐式向量作为生成特征输入到 Deep&Wide 网络结构之中,从而丰富特征向量。但在多次试验后,发现频道 Embedding 隐式向量的引入,并没有给模型性能带来可观的提升,反而加重了整体工程实现的复杂度和耦合度。因此在最终版模型中,我们并没有纳入频道的隐式特性。但我们想要强调的是,机器学习领域中很多方法都是相通的,可以在不同的场景中互相借鉴。
在我们的案例中,Wide&Deep 与协同过滤均诞生于推荐领域,但这些方法在时序预测场景也能够发挥重要作用。尤其是 Wide&Deep 思想,在大幅降低工程复杂度的同时,能够保持模型良好的预测性能。反过来,时序预测场景中的流行算法如 RNN、LSTM、Attention 机制,同样被大量应用于推荐领域、NLP 领域,甚至是计算机视觉领域。因此,算法同学应该有意识地学习、掌握不同场景下的经典算法与思想,从而在应对不同场景的业务需求时,能够更加游刃有余。
作者简介
吴磊,Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地以及推广。曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论