

最开始公司运维同学反馈,个别宿主机上存在进程 CPU 峰值使用率异常的现象。而数万台机器中只出现了几例,也就是说万分之几的概率。监控产生的些小误差,不会造成宕机等严重后果,很容易就此被忽略了。但我们考虑到这个异常转瞬即逝、并不易被察觉,可能还存在更多这样的机器,又或者现在正常将来又不正常,内核研发本能的好奇心让我们感到:此事必有蹊跷!于是追查下去。
问题现象
现象一:CPU 监控非 0 即 100%
该问题现象表现在 Redis 进程 CPU 监控的峰值时而 100% 时而为 0,有的甚至是几十分钟都为 0,突发 1 秒 100%后又变为 0,如下图。
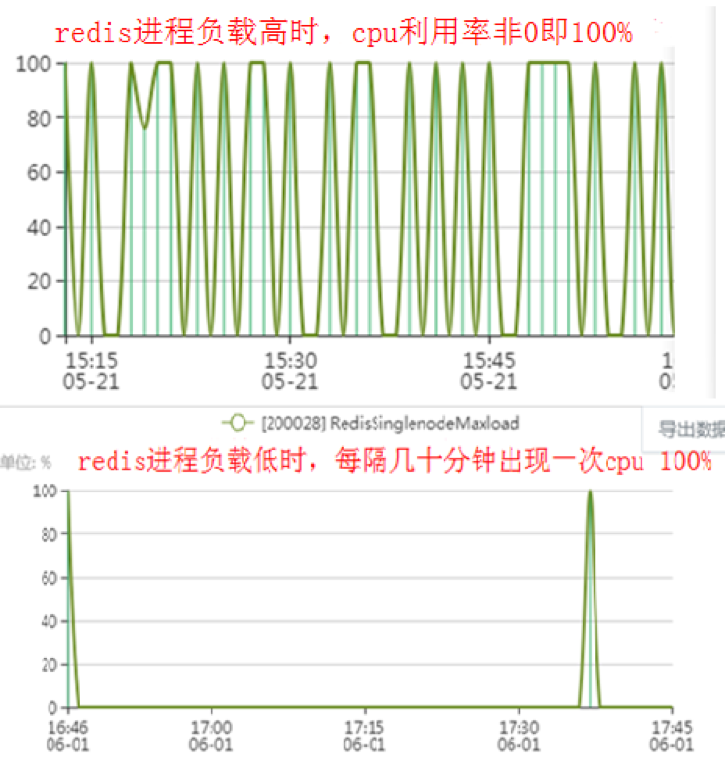
而从大量机器的统计规律看,这个现象在 2.6.32 内核不存在,在 4.1 内核存在几例。2.6.32 是我们较早期采用的版本,为平台的稳定发展做了有力支撑,4.1 可以满足很多新技术需求,如新款 CPU、新板卡、RDMA、NVMe 和 binlog2.0 等。后台无缝维护着两个版本,并为了能力提升和优化而逐步向 4.1 及更高版本过渡。
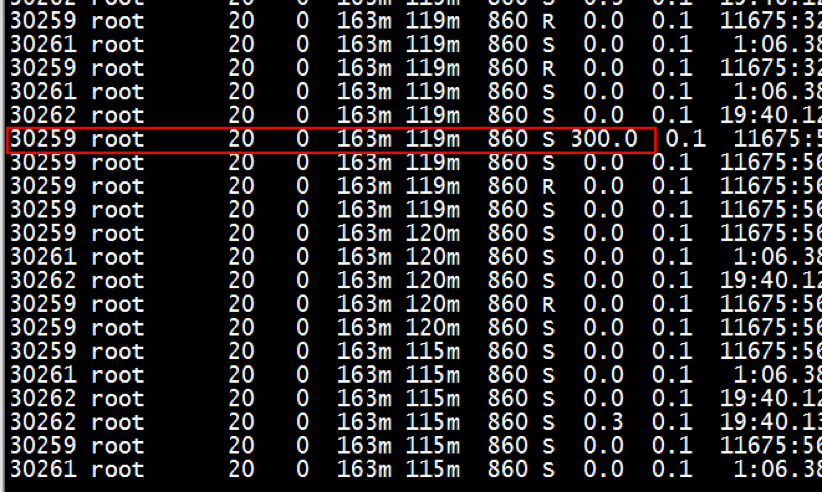
现象二:top 显示非 0 即 300%
登录到机器上执行 top -b -d 1 –p| grep, 可以看到进程的 CPU 利用率每隔几分钟到几十分钟出现一次 300%,这意味着该进程 3 个线程占用的 3 个 CPU 都跑满了,跟监控程序呈现同样的异常。
问题分析
上述异常程序使用的是同样的数据源:/proc/pid/stat 中进程运行占用的用户态时间 utime 和内核态时间 stime。我们抓取 utime 和 stime 更新情况后,发现 utime 或者 stime 每隔几分钟或者几十分钟才更新,更新的步进值达到几百到 1000+,而正常进程看到的是每几秒更新,步进值是几十。
定位到异常点后,还要找出原因。排除了监控逻辑、IO 负载、调用瓶颈等可能后,确认是 4.1 内核的 CPU 时间统计有 bug。
cputime 统计逻辑
检查/proc/pid/stat 中 utime 和 stime 被更新的代码执行路径,在 cputime_adjust()发现了一处可疑的地方:

当 utime+stime>=rtime 的时候就直接跳出了,也就是不更新 utime 和 stime 了!这里的 rtime 是 runtime,代表进程运行占用的所有 CPU 时长,正常应该等于或近似进程用户态时间+内核态时间。 但内核配置了 CONFIG_VIRT_CPU_ACCOUNTING_GEN 选项,这会让 utime 和 stime 分别单调增长。而 runtime 是调度器里统计到的进程真正运行总时长。
内核每次更新/proc/pid/stat 的 utime 和 stime 的时候,都会跟 rtime 对比。如果 utime+stime 很长一段时间都大于 rtime,那代码直接 goto out 了, /proc/pid/stat 就不更新了。只有当 rtime 持续更新追上 utime+stime 后,才更新 utime 和 stime。

冷补丁和热补丁
第一回合:冷补丁
出现问题的代码位置已经找到,那就先去内核社区看看有没有成熟补丁可用,看一下 kernel/sched/cputime.c 的 changelog,看到一个 patch:确保 stime+utime=rtime。再看描述:像 top 这样的工具,会出现超过 100%的利用率,之后又一段时间为 0,这不就是我们遇到的问题吗?真是踏破铁鞋无觅处,得来全不费工夫!(patch 链接:https://lore.kernel.org/patchwork/patch/609410/)

该补丁在 4.3 内核及以后版本才提交, 却并未提交到 4.1 稳定版分支,于是移植到 4.1 内核。打上该补丁后进行压测,再没出现 cputime 时而 100%时而 0%的现象,而是 0-100%之间平滑波动的值。
至此,你可能觉得问题已经解决了。但是,问题才解决了一半。而往往“但是”后边才是重点。
第二回合:热补丁
给内核代码打上该冷补丁只能解决新增服务器的问题,但公司还有数万存量服务器是无法升级内核后重启的。
如果没有其它好选择,那存量更新将被迫采用如下的妥协方案:监控程序修改统计方式进行规避,不再使用 utime 和 stime,而是通过 runtime 来统计进程的执行时间。
虽然该方案快速可行,但也有很大的缺点:
很多业务部门都要修改统计程序,研发成本较高;
/proc/pid/stat 的 utime 和 stime 是标准统计方式,一些第三方组件并不容易修改;
并没有根本解决 utime 和 stime 不准的问题,用户、研发、运维使用 ps、top 命令时还会产生困惑,产生额外的沟通协调成本。
幸好,我们还可以依靠 UCloud 已多次成功应用的技术:热补丁技术。
所谓热补丁技术,是指在有缺陷的服务器内核或进程正在运行时,对已经加载到内存的程序二进制打上补丁,使得程序实时在线状态下执行新的正确逻辑。可以简单理解为像关二爷那样不打麻药在清醒状态下刮骨疗伤。当然,对内核刮骨疗伤内核是不会痛的,但刮不好内核就会直接死给你看,没有丝毫犹豫,非常干脆利索又耿直。
热补丁修复
而本次热补丁修复存在两个难点:
难点一: 热补丁制作
这次热补丁在结构体新增了 spinlock 成员变量,那就涉及新成员的内存分配和释放,在结构体实例被复制和释放时,都要额外的对新成员做处理,稍有遗漏可能会造成内存泄漏进而导致宕机,这就加大了风险。
再一个就是,结构体实例是在进程启动时初始化的,对于已经存在的实例如何塞进新的 spinlock 成员?所谓兵来将挡水来土掩,我们想到可以在原生补丁使用 spinlock 成员的代码路径上拦截,如果发现实例不含该成员,则进行分配、初始化、加锁、释放锁。
要解决问题,既要攀登困难的山峰,又得控制潜在的风险。团队编写了脚本进行几百万次的加载、卸载热补丁测试,并无内存泄漏,单机稳定运行,再下一城。
难点二:难以复现
另一个难题是该问题难以复现,只有在现网生产环境才有几个 case 可验证热补丁,而又不可以拿用户的环境去冒险。针对这种情况我们已经有标准化处理流程去应对,那就是设计完善的灰度策略,这也是 UCloud 内部一直在强调的核心理念和能力。经过分析,这个问题可以拆解为验证热补丁稳定性和验证热补丁正确性。于是我们采取了如下灰度策略:
稳定性验证:先拿几台机器测试正常,再拿公司内部 500 台次级重要的机器打热补丁,灰度运行几天正常,从而验证了稳定性,风险尽在掌控之中。
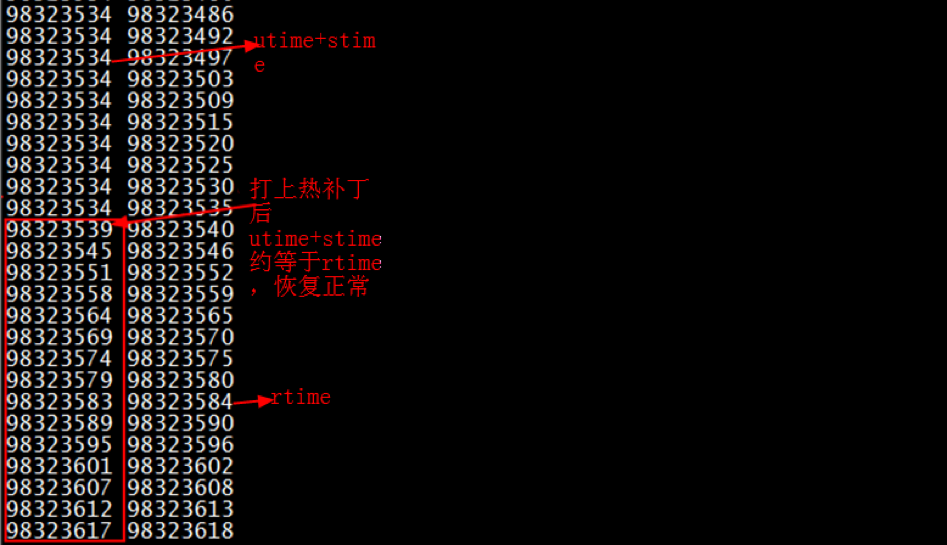
正确性验证:找到一台出现问题的机器,同时打印 utime+stime 以及 rtime,根据代码的逻辑,当 rtime 小于 utime+stime 时会执行老逻辑,当 rtime 大于 utime+stime 时会执行新的热补丁逻辑。如下图所示,进入热补丁的新逻辑后,utime+stime 打印正常且与 rtime 保持了同步更新,从而验证了热补丁的正确性。
全网变更: 最后再分批在现网环境机器上打热补丁,执行全网变更,问题得到根本解决,此处要感谢运维同学的全力协助。
总结
综上,我们详细介绍了进程 cputime 统计异常问题的完整分析和解决思路。该问题并非严重的宕机问题,但却可能会让用户对监控数据产生困惑,误认为可能机器负载太高需要加资源,问题的解决会避免产生不必要的开支。此外,该问题也会让研发、运维和技术支持的同学们使用 top 和 ps 命令时产生困惑。最终我们对问题的本质仔细分析并求证,用热补丁的方式妥善的解决了问题。
文章首发于公众号"UCloud 技术": https://mp.weixin.qq.com/s/nIOvQuLtdQwLPi8AqJiBPg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论