

近日,国内领先的中立云计算服务商 UCloud 与国内开源分布式 NewSQL 数据库 TiDB 团队 PingCAP 正式达成合作,双方联手在 UCloud 全球数据中心推出了新一代 TiDB 的云端版本——Cloud TiDB。
作为一款定位于 Cloud-native 的数据库,截至目前 TiDB 在云整合上已取得了阶段性进展。Cloud TiDB 产品在 UCloud 平台正式开启公测,TiDB 弹性伸缩特性在 Cloud 提供的基础设施支持下得到了淋漓尽致的展现。
在感受云数据库魅力的同时,让我们来探索一下 TiDB 与 Cloud 背后的技术秘密。
TiDB 与传统单机关系型数据库的区别
首先,从 TiDB 的架构说起。TiDB 作为一款开源的分布式数据库产品,具有多副本强一致性,能够根据业务需求非常方便的进行弹性伸缩,并且扩缩容期间对上层业务无感知。
TiDB 的主体架构包含三个模块,对应 Github 上 PingCAP 组织下的三个开源项目(TiDB / TiKV / PD):
TiDB 主要是负责 SQL 的解析器和优化器,它相当于计算执行层,同时也负责客户端接入和交互;
TiKV 是一套分布式的 Key-Value 存储引擎,它承担整个数据库的存储层,数据水平扩展和多副本高可用特性都在这一层实现;
PD 相当于分布式数据库的大脑,一方面负责收集和维护数据在各个 TiKV 节点的分布情况,另一方面 PD 承担调度器的角色,根据数据分布状况以及各个存储节点的负载来采取合适的调度策略,维持整个系统的平衡与稳定。
上述三个模块中的每个角色都是一个多节点组成的集群,所以最终 TiDB 的架构如下图所示:
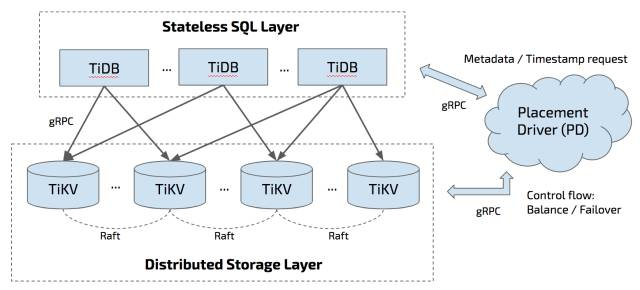
由此可见,分布式系统本身的复杂性不仅导致手工部署和运维成本较高,而且容易出错。传统的自动化部署运维工具(如:Puppet/Chef/SaltStack/Ansible 等),由于缺乏状态管理,在节点出现问题时不能及时自动完成故障转移,需要运维人员人工干预,有些则需要写大量 DSL 甚至与 Shell 脚本一起混合使用,可移植性较差,维护成本比较高。
在云时代,容器成为应用分发部署的基本单位,谷歌基于内部使用数十年的容器编排系统 Borg 经验,推出的开源容器编排系统 Kubernetes 就成为当前容器编排技术的主流。
TiDB 与 Kubernetes 的深度整合
作为 Cloud Native Database,TiDB 选择拥抱容器技术,并与 Kubernetes 进行深度整合,使其可以非常方便地基于 Kubernetes 完成数据库自动化管理。甚至可以说 Kubernetes 项目是为 Cloud 而生,利用云平台 IaaS 层提供的 API 可以很方便地与云进行整合。这样只要让 TiDB 与 Kubernetes 结合得更好,进而就能实现其与各个云平台的整合,使 TiDB 在云上的快速部署和高效运维成为现实。
1 Kubernetes 简介
Kubernetes 最早是作为一个纯粹的容器编排系统而诞生,用户部署好 Kubernetes 集群之后,直接使用其内置的各种功能部署应用服务。由于这个 PaaS 平台使用起来非常便利,吸引了很多用户,不同用户也提出了各种不同需求,有些特性需求 Kubernetes 可直接在其核心代码里实现,但有些特性并不适合合并到主干分支。
为了满足这类需求,Kubernetes 开放出一些 API 供用户自己扩展,实现自身需求。当前 Kubernetes 已经升级到 v1.8 版本,内部 API 变得越来越开放,使其更像是一个跑在云上的操作系统。用户可以把它当作一套云的 SDK 或 Framework 来使用,而且可以很方便地开发组件来扩展满足自身业务需求,对有状态服务的支持就是一个代表性实例。
在最早期,Kubernetes 项目只支持无状态服务(Stateless Service) 来管理,无状态服务通过 ReplicationController 定义多个副本,由 Kubernetes 调度器来决定在不同节点上启动多个 Pod,实现负载均衡和故障转移。对于无状态服务,多个副本对应的 Pod 是等价的,所以当节点出现故障时,在新节点上启动一个 Pod 与失效的 Pod 是等价的,不会涉及状态迁移问题,因而管理非常简单。
2 有状态服务 Stateful Service
不过,对于有状态服务 (Stateful Service),由于需要将数据持久化到磁盘,使得不同 Pod 之间不能再认为成等价,也就不能再像无状态服务那样随意地进行调度迁移。Kubernetes v1.3 版本提出 PetSet 的概念,用来管理有状态服务并在 v1.5 版本中将其更名为 StatefulSet。
StatefulSet 明确定义了一组 Pod 中的每个身份,启动和升级都按特定顺序来操作。另外,使用持久化卷存储(PersistentVolume)来作为存储数据的载体,当节点失效 Pod 需要迁移时,对应的 PV 通过 umount/mount 方式跟着一起迁移到新节点,或者直接使用分布式文件系统作 PV 底层存储,使 Pod 在迁移后仍然能访问到之前的数据。
同时,Pod 在发生迁移时,其网络身份(例如 IP 地址)是会发生变化的,很多分布式系统不能接受这种情况,所以 StatefulSet 在迁移 Pod 时可以通过绑定域名的方式来保证 Pod 在集群中网络身份不发生变化。
然而,现实中一些分布式系统更为复杂,StatefulSet 也显得捉襟见肘。举例来说,某些分布式系统的节点在加入集群或下线时,还需要做些额外的注册和清理操作,或者在滚动升级时,要考量版本兼容性等问题。
基于上述原因,CoreOS 公司提出了 Operator 概念,并实现了 etcd-operator 和 prometheus-operator 来管理 Etcd 和 Prometheus 这样复杂的分布式系统。用户可以开发自己的 Operator,在 Kubernetes 之上实现自定义的 Controller,将有状态服务领域中特定的运维知识编码进去,从而实现对特定分布式系统的管理。同时,Operator 本身也是跑在 Kubernetes 中的一个 Pod(deployment),对 Kubernetes 系统并无侵入性。
3 TiDB 多组件支持
针对 TiDB 这种复杂的分布式服务,我们开发了 tidb-operator 等一系列组件,来管理 TiDB 集群实例在 Kubernetes 平台上的创建、销毁、扩缩容、滚动升级和故障转移等运维操作。同时,在上层封装了一个 tidb-cloud-manager 组件,提供 RESTful 接口,实现了与云平台的控制台打通功能。这就完成了一个 DBaaS(数据库即服务)架构的基本形态。
由于 TiDB 对磁盘 I/O 有比较高的要求,通过 PV 挂载网络盘,会有明显的性能损耗。另外,TiKV 本身维护了数据多副本,这点和分布式文件系统的多副本是有重复的,所以要给 Pod 上挂载本地磁盘,并且在 Kubernetes 上把 Local PV 管理起来,作为一种特定资源来维护。
Kubernetes 官方长期以来一直没有提供 Local PV 支持,本地存储只支持 hostPath 和 emptyDir 两种方式。其中,hostPath 的生命周期是脱离 Kubernetes 管理的,使用 hostPath 的 Pod 销毁后,里面的数据是不会被自动清理,下次再挂载 Pod 就会造成脏数据。而 emptyDir 更像是一个临时磁盘,在 Pod 重建时会被清理重置,不能成为持久化 PV 来使用。
为此,我们开发了一个 tidb-volume-manager 组件,用于管理 Kubernetes 集群中每台物理主机上的本地磁盘,并且将其暴露成一种特殊的 PV 资源。结合 Operator 在部署 TiDB 节点时会参考 Local PV 资源的情况,来选择特定节点进行部署,分配一个空的 Local PV 和 Pod 绑定。而当 Pod 销毁时,会根据具体情况决定是否结束 Local PV 的生命周期,释放掉的 Local PV 在经历一个 GC 周期后,被 tidb-volume-manager 回收,清理其盘上数据等待再次被分配使用。
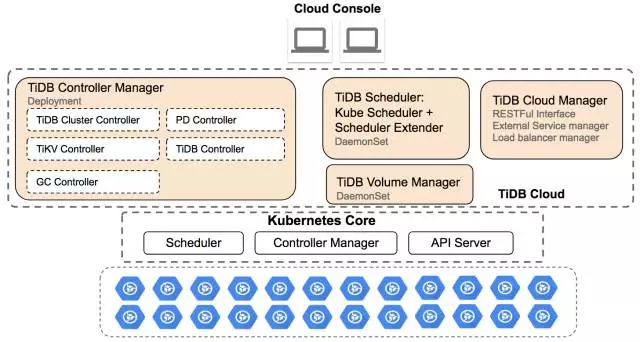
Cloud TiDB 总体架构图
将这些组件整合起来,就形成了上图描述的 Cloud TiDB 总体架构。在 Kubenetes 管理的集群上,通过 tidb-operator 等组件针对性的调配和使用集群资源,从而实现 TiDB 集群实例的生命周期管理。通过这种方式实现 TiDB 分布式数据库和云平台的整合。
我们将在下一篇中详细介绍针对 Cloud TiDB 的关键特性和实现细节。
本文转载自公众号 UCloud 技术(ID:ucloud_tech)。
原文链接:
https://mp.weixin.qq.com/s/-t4lIgU_6YX_PvTx_DjVOw

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论