

容器运行时(ContainerRuntime),运行于 kubernetes(k8s)集群的每个节点中,负责容器的整个生命周期。其中 docker 是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了解决这些容器运行时和 k8s 的集成问题,在 k8s1.5 版本中,社区推出了 CRI(ContainerRuntimeInterface,容器运行时接口)(如图 1 所示),以支持更多的容器运行时。
Kubelet 通过 CRI 和容器运行时进行通信,使得容器运行时能够像插件一样单独运行。可以说每个容器运行时都有自己的优势,这就允许用户更容易选择和替换自己的容器运行时。
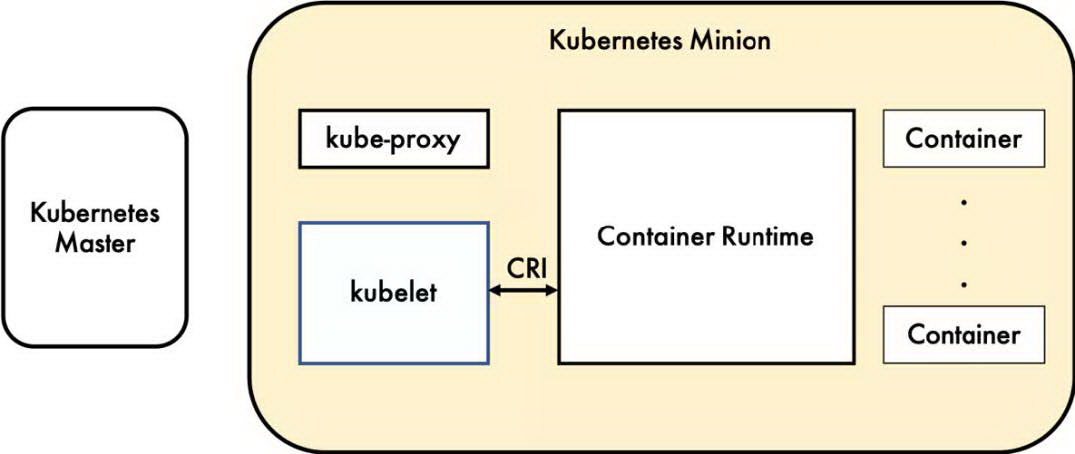
图 1 CRI 在 kubernetes 中的位置
一、CRI&OCI
CRI 是 kubernetes 定义的一组 gRPC 服务。Kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和容器运行时通信。它包括两类服务:镜像服务(ImageService)和运行时服务(RuntimeService)。镜像服务提供下载、检查和删除镜像的远程程序调用。运行时服务包含用于管理容器生命周期,以及与容器交互的调用(exec/attach/port-forward)的远程程序调用。
如图 2 所示,dockershim,containerd 和 cri-o 都是遵循 CRI 的容器运行时,我们称他们为高层级运行时(High-levelRuntime)。
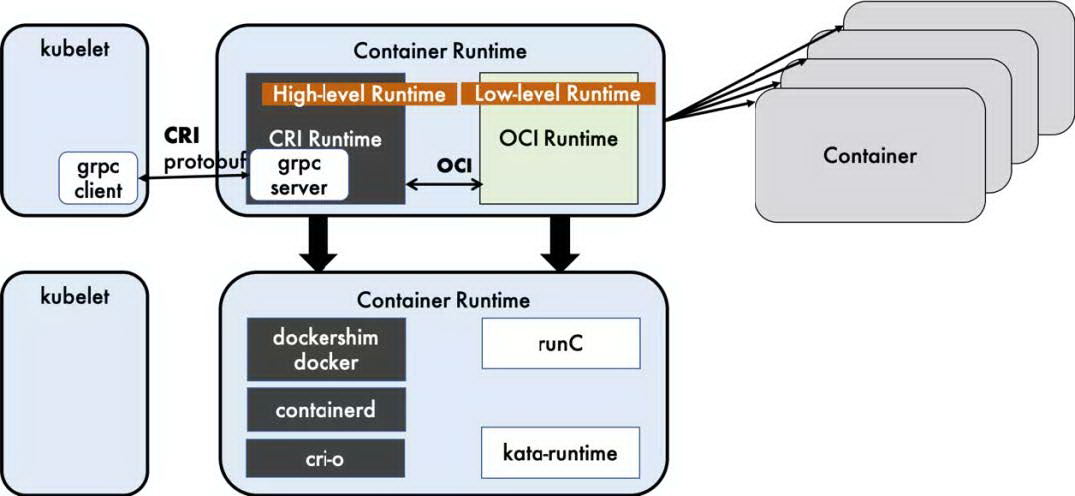
图 2 常用的运行时举例
OCI(OpenContainerInitiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包括镜像规范(ImageSpecification)和运行时规范(RuntimeSpecification)。
镜像规范定义了 OCI 镜像的标准。如图 2 所示,高层级运行时将会下载一个 OCI 镜像,并把它解压成 OCI 运行时文件系统包(filesystembundle)。
运行时规范则描述了如何从 OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期。如何为新容器设置命名空间(namepsaces)和控制组(cgroups),以及挂载根文件系统等等操作,都是在这里定义的。它的一个参考实现是 runC。我们称其为低层级运行时(Low-levelRuntime)。除 runC 以外,也有很多其他的运行时遵循 OCI 标准,例如 kata-runtime。
二、ContainerdvsCri-o
目前 docker 仍是 kubernetes 默认的容器运行时。那为什么会选择换掉 docker 呢?主要的原因是它的复杂性。
如图 3 所示,我们总结了 docker,containerd 以及 cri-o 的详细调用层级。Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度(貌似除了重启 docker,我们就毫无他法了)。Containerd 和 cri-o 的方案比起 docker 简洁很多。因此我们更偏向于选用更加简单和纯粹的 containerd 和 cri-o 作为我们的容器运行时。
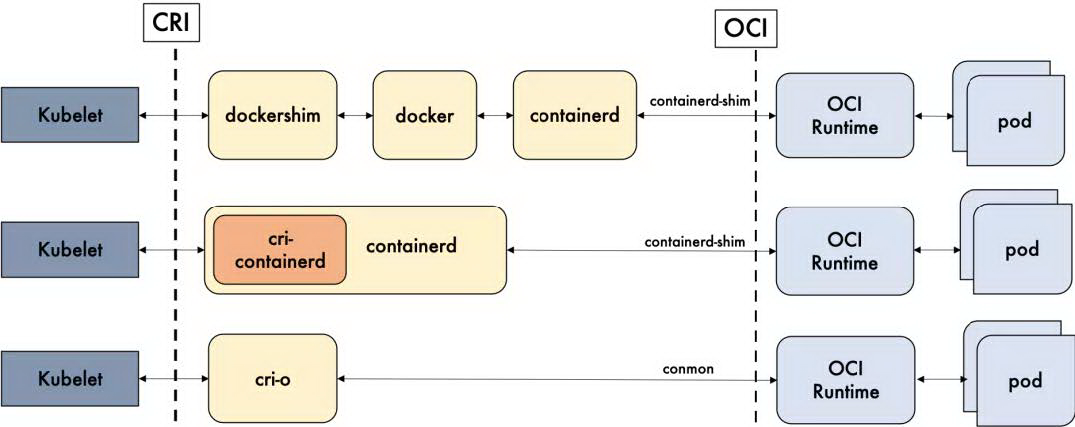
图 3 容器运行时调用层级
我们对 containerd 和 cri-o 进行了一组性能测试,包括创建、启动、停止和删除容器,以比较它们所耗的时间。如图 4 所示,containerd 在各个方面都表现良好,除了启动容器这项。从总用时来看,containerd 的用时还是要比 cri-o 要短的。
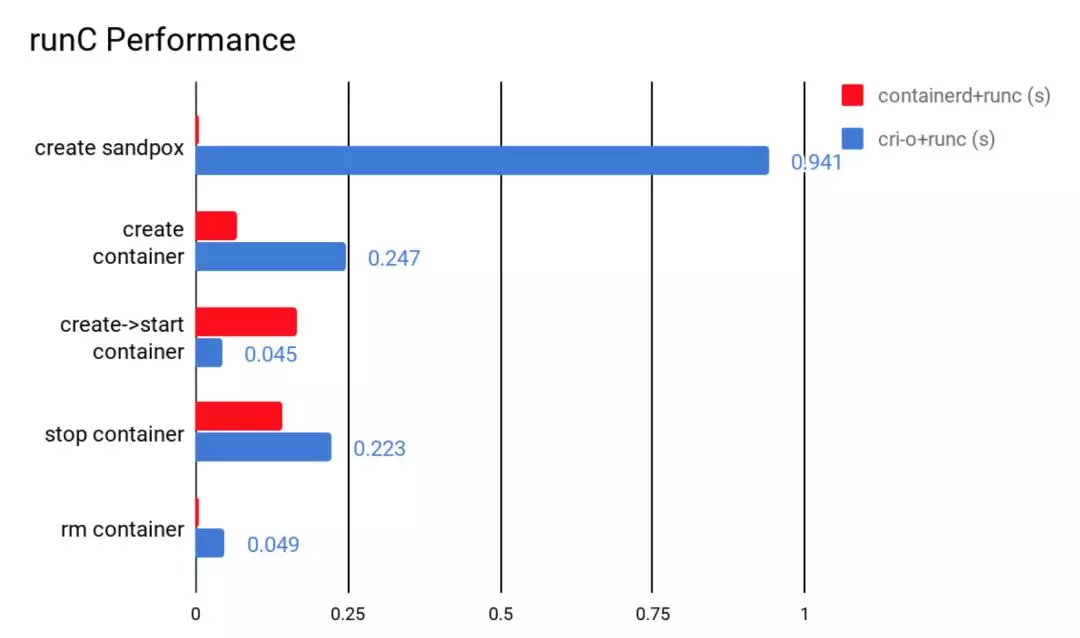
图 4 containerd 和 crio 的性能比较
如图 5 所示,从功能性来讲,containerd 和 cri-o 都符合 CRI 和 OCI 的标准。从稳定性来说,单独使用 containerd 和 cri-o 都没有足够的生产环境经验。但庆幸的是,containerd 一直在 docker 里使用,而 docker 的生产环境经验可以说比较充足。可见在稳定性上 containerd 略胜一筹。所以我们最终选用了 containerd。
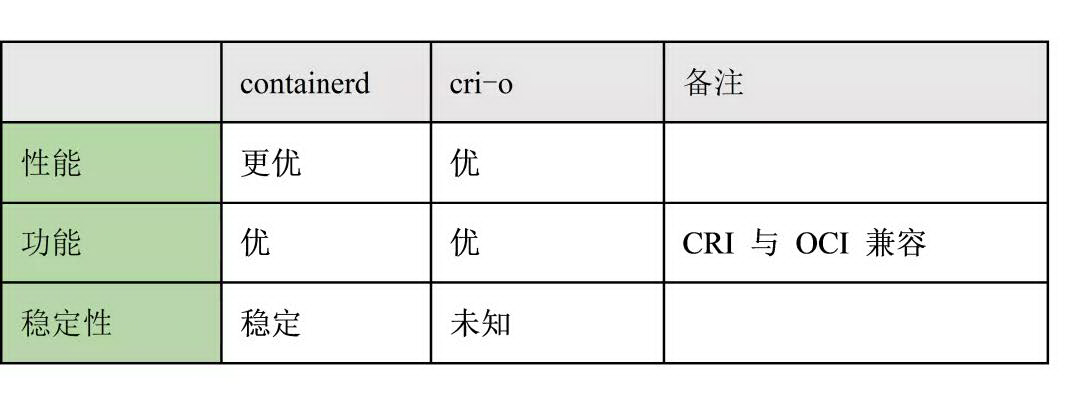
图 5 containerd 和 cri-o 的综合比较
三、DeviceMappervs.Overlayfs
容器运行时使用存储驱动程序(storagedriver)来管理镜像和容器的数据。目前我们生产环境选用的是 DeviceMapper。然而目前 DeviceMapper 在新版本的 docker 中已经被弃用,containerd 也放弃对 DeviceMapper 的支持。
当初选用 DeviceMapper,也是有历史原因的。我们大概是在 2014 年开始 k8s 这个项目的。那时候 Overlayfs 都还没合进 kernel。当时我们评估了 docker 支持的存储驱动程序,发现 DeviceMapper 是最稳定的。所以我们选用了 DeviceMapper。但是实际使用下来,由 DeviceMapper 引起的 docker 问题也不少。所以我们也借这个契机把 DeviceMapper 给换掉,换成现在 containerd 和 docker 都默认的 Overlayfs。
从图 6 的测试结果来看,Overlayfs 的 IO 性能比 DeviceMapper 好很多。Overlayfs 的 IOPS 大体上能比 DeviceMapper 高 20%,和直接操作主机路径差不多。
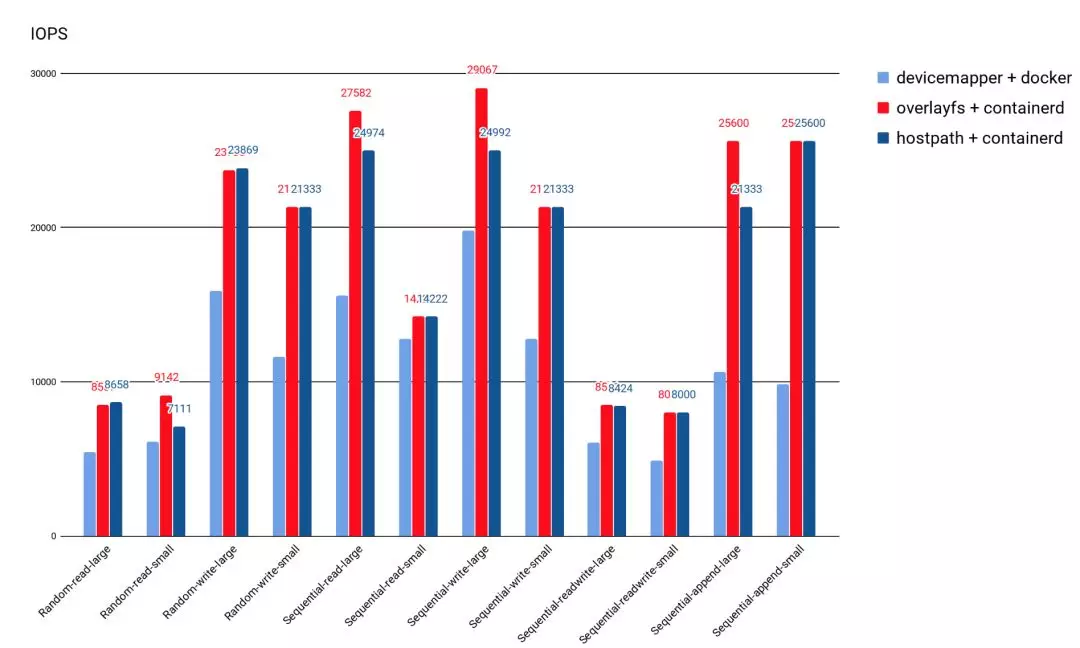
图 6 后端存储文件系统性能比较
四、迁移方案
最终,我们选用了 containerd,并以 Overlayfs 作为存储后端的文件系统,替换了原有的 docker 加 DeviceMapper 的搭配。那迁移前后的性能是否得到提升呢?我们在同一个节点上同时起 10,30,50 和 80 的 pod,然后再同时删除,去比较迁移前后创建和删除的用时。从图 7 和图 8 可知,containerd 用时明显优于 docker。
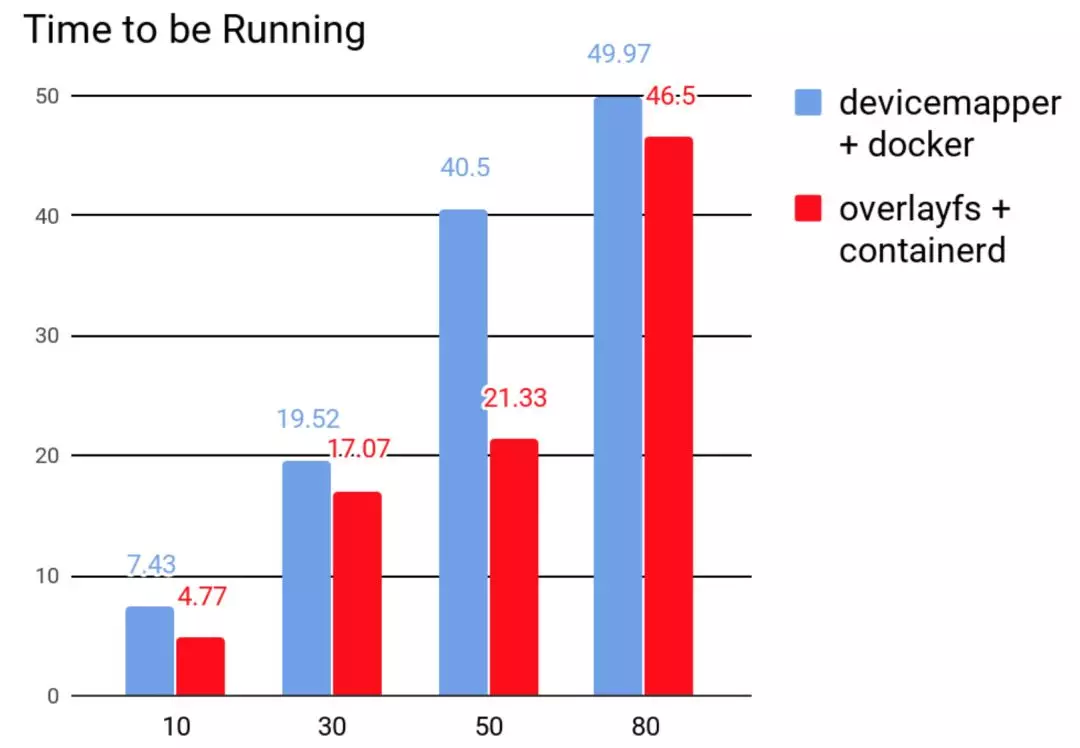
图 7 创建 pod 的用时比较
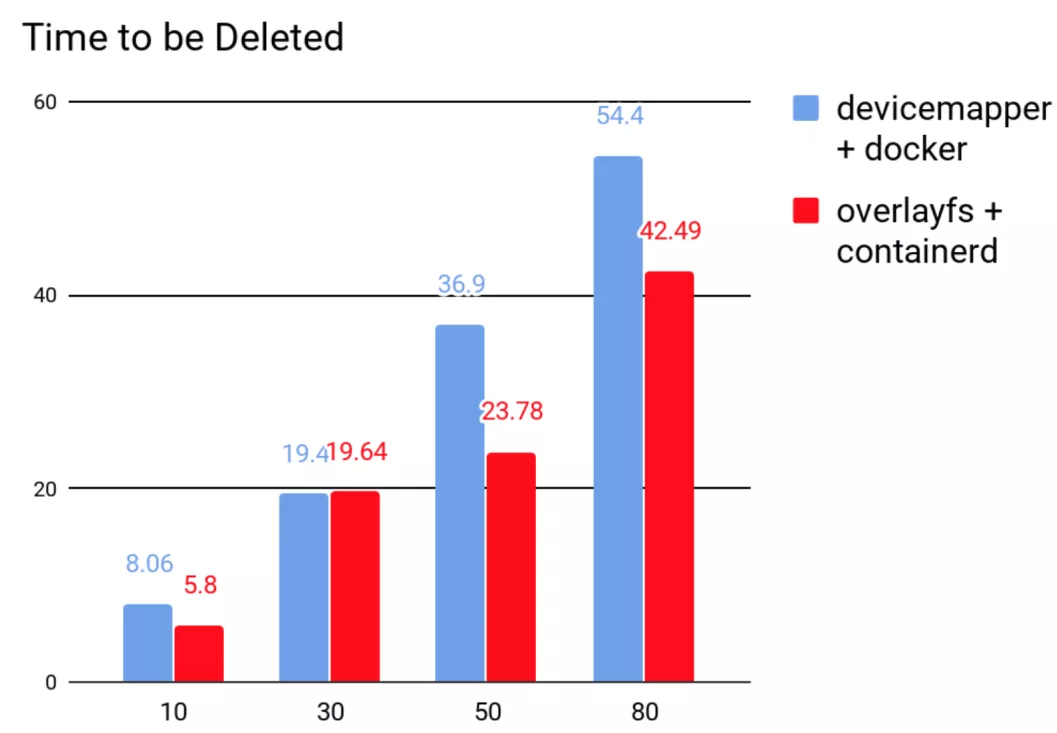
图 8 删除 pod 的用时比较
五、迁移挑战
从 docker+DeviceMapper 到 containerd+Overlayfs,容器运行时的迁移并非易事。这个过程中需要删除 DeviceMapper 的 thin_pool,全部重新下载用户的容器镜像,全新重建用户的容器。
如图 9 所示,迁移过程看似简单,但是这对于已运行了 5 年且拥有**100K+**光怪陆离的应用程序的集群而言,如何将用户的影响降到最低才是最难的。Containerd 在我们生产环境中是否会出现“重大”问题也未可知。
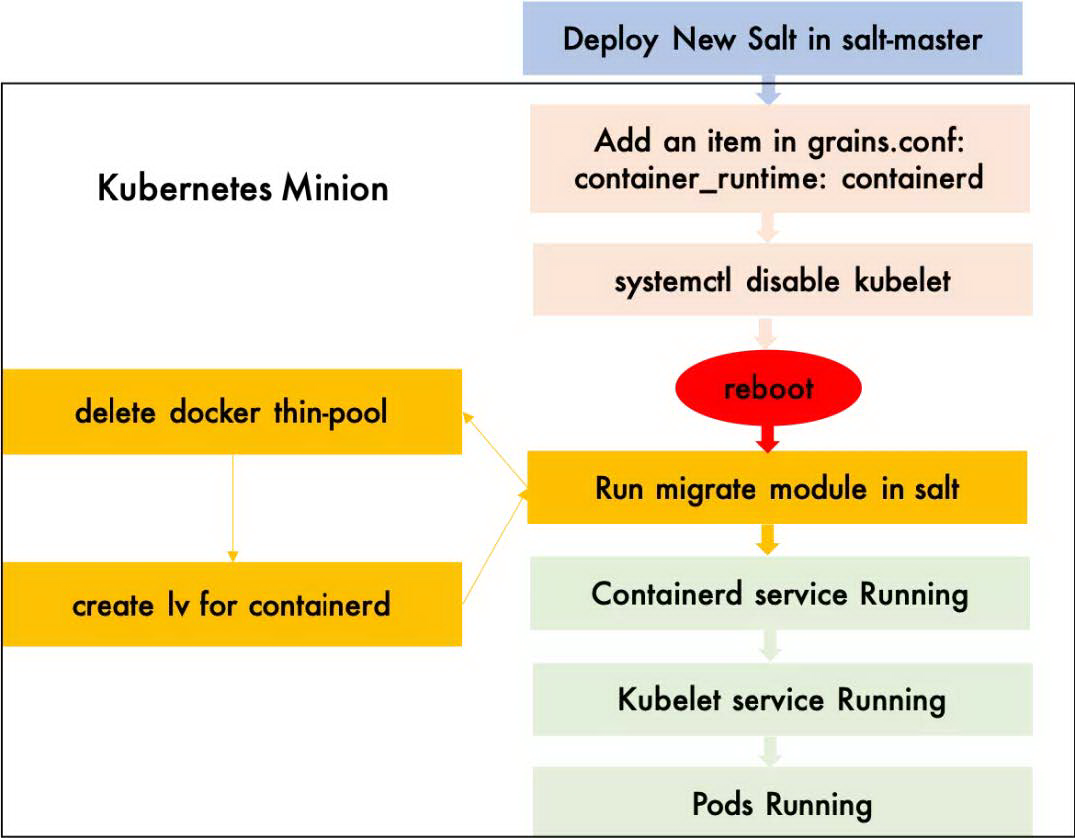
图 9 具体的迁移步骤
针对这些挑战,我们也从下面几个方面做出了优化,来保证我们迁移过程的顺利进行。
01 多样的迁移策略
最基本的是以容错域(FaultDomain,fd)为单元迁移。针对我们集群,是以 rack(机架)为单元(rackbyrack)迁移。针对云原生(cloud-native)且跨容错域部署的应用程序,此升级策略最为安全有效。针对非云原生的应用程序,我们根据其特性和部署拓扑,定制了专属他们的升级策略,例如针对 Cassini 的集群,我们采用了 jenga(层层叠)的升级策略,保证应用程序 0 宕机。
02 自动化的迁移过程
以 rackbyrack 的策略为例,需要等到一个 rack 迁移完成以后且客户应用程序恢复到迁移前的状态,才能进行下一个 rack 的迁移。因此我们对迁移控制器(Controller)进行了加强,利用控制平面(ControlPlane)的监控指标(Metrics)和数据平面(DataPlane,即应用程序)的告警(Alerts),实现典型问题的自动干预和修复功能,详见图 10。如果问题不能被修复,错误率达到阈值,迁移才会被暂停。对于大集群,实现了人为的 0 干预。
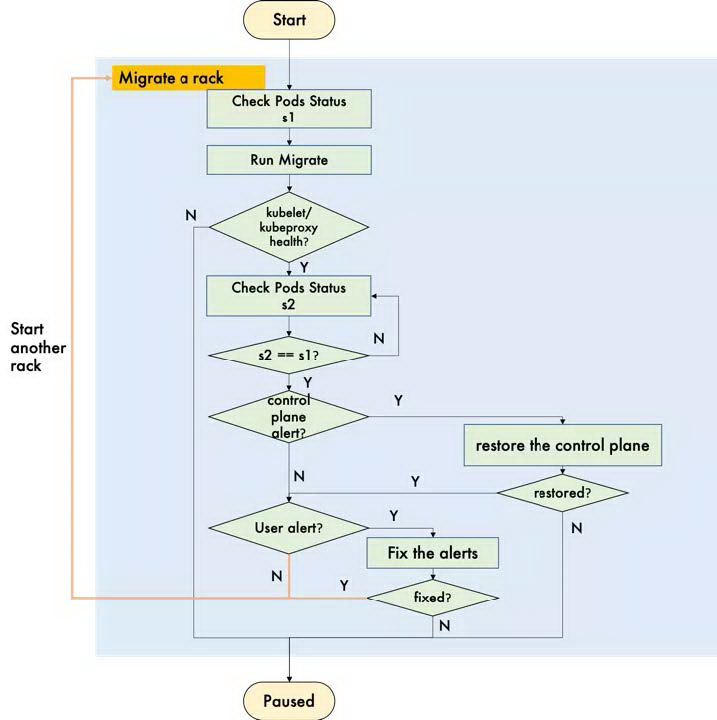
图 10 自动化迁移流程
03 高可用的镜像仓库
一个 rack 共有 76 台机器。假设每个机器上只有 50 个 pod,就可能最多有 3800 个镜像需要下载。这对镜像仓库的压力是非常大的。除了使用本地仓库,这次迁移过程中还使用了基于 gossip 协议的镜像本地缓存的功能,来减少远端服务端的压力,具体参见图 11。
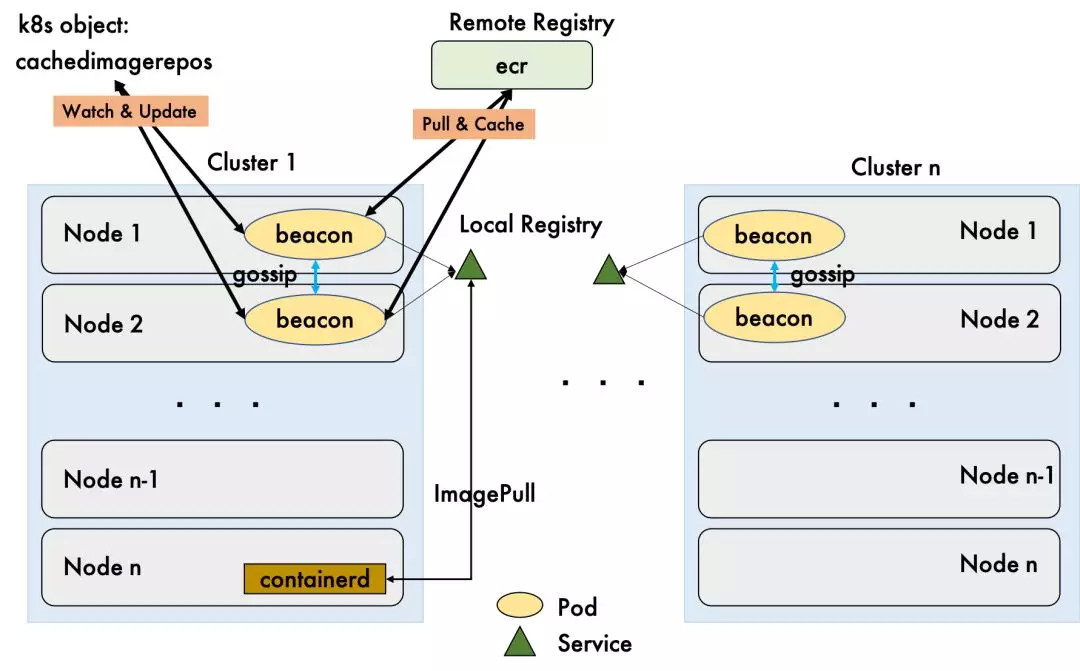
图 11 镜像仓库架构
04 可逆的迁移过程
虽然我们对 containerd 的问题修复是有信心的,但是毕竟缺少生产环境经验,得做好随时回退的准备。一旦发现迁移后,存在极大程度影响集群的可靠性和可用性的问题,我们就要换回 docker。虽然迁移后,在线上的确发现了镜像不能成功下载,容器不能启动和删除等问题,但是我们都找到了根本原因,并修复。所以令人庆幸的是,这个回退方法并未发挥其作用。
六、用户体验
容器运行时是 kubernetes 的后端服务。容器运行时的迁移不会改变任何的用户体验。但是有一个 Overlayfs 的问题需要特别说明一下。如果容器的基础镜像(BaseImage)是 centos6,利用 Dockerfile 去创建镜像时,如果用 yum 去安装包,或者在运行的 centos6 容器中用 yum 安装包的,会报以下错误:
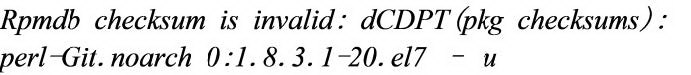
因为 yum 在安装包的过程中,会先以只读模式,然后再以写模式去打开 rmpdb 文件。
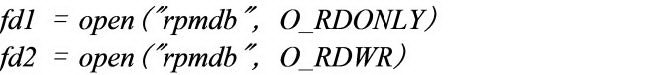
如图 12 所示,对于 Overlayfs 来说,以只读模式打开一个文件的话,文件直接在下层(lowerlayer)被打开,我们得到一个 fd1。当我们再以写模式打开,就会触发一个 copy_up。rmpdb 就会拷贝到上层(upperlayer)。文件就会在上层打开得到 fd2。这两个 fd 本来是想打开同一个文件,事实却并非如此。
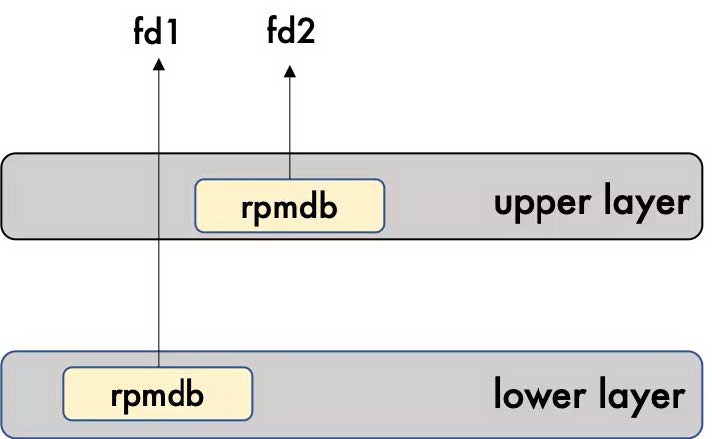
图 12
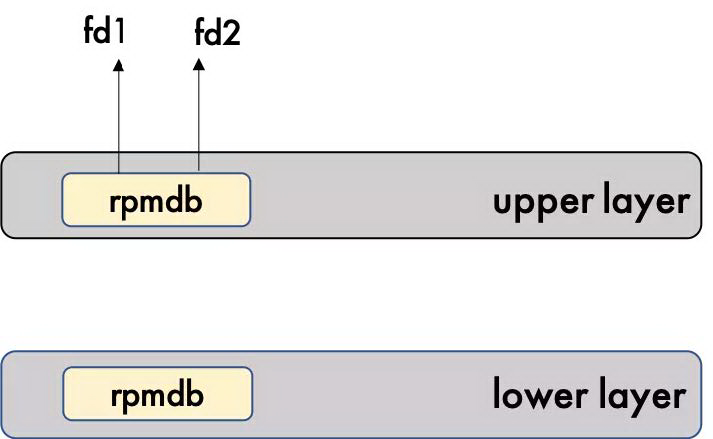
图 13
解决方案就是在执行 yum 命令之前先装一个 yum-plugin-ovl 插件。这个插件就是去做一个初始的 copy_up,如图 13 所示。将 rpmdb 先拷贝到上层,参考 Dockerfile 如下:

如果基础镜像是 centos7,则没有这个问题,因为 centos7 的基础镜像已经有这个规避方法了。
七、总结
目前我们 50 个集群,20K+的节点已经全部迁到 containerd,历时 2 个月(非执行时间)。从目前情况来看,还比较稳定。虽然迁移过程中也出了不少问题,但经过各个小组的不懈努力,此次迁移终于顺利完成了。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/9dhmQeCPuA_TysMwhzKqGA

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论 2 条评论