
内容提要
任何基于微服务的应用都是分布式系统,因此,服务不独立运行。如果出现故障,则导致级联故障,使监控和警报复杂化。
为适应监控微服务应用带来的挑战,Wells 提出一种三管齐下的办法:构建可被支持的系统,专注于“重要的东西”,以及筛选和增添警报和它们所包括的信息。
由于服务量和网络通讯产生的潜在延时,日志可能丢失或延迟,因此任何分布式系统都需要日志聚合。
当在基于微服务的系统内实施监控时,Nagios 等传统监控工具往往受到限制,因为它不提供“服务级别”视图,而且默认(基础设施)检查出来的某些问题无法被修复。
监控与报警的一个核心目标是在客户使用之前发现问题,因此,运行模拟用户功能行为的“模拟请求”至关重要。
必须不断筛选和增添警报,如果接收到无意义或者无需人为干预的警报,则必须进行修正或移除。
创建警报应为标准开发工作流程的一部分即:“代码、测试、警报”。为确保开发团队知道警报是否停止工作,还应加入验证该警报的测试。
在维护和处理重要系统中的警报时需要积极主动,过期的信息可能比没有信息更糟糕。
微服务架构允许您快速行动,但也产生相关的操作成本,尤其在监控和可观察性方面。确定您是否愿意承担该成本。
Sarah Wells 在 QCon 伦敦发表了“防止来自微服务的警报过载”的演讲,他警告人们说,开发者和操作者在构建分布式的微服务系统时必须从根本上改变他们看待监控的方式。
《金融时报》首席工程师 Wells 在座谈开始时表示,发现什么时间有问题还不够,必须要在需要人为干预时触发警报。微服务架构允许开发团队迅速行动,但同时也会产生操作成本 ,而且基于微服务的系统产生的警报的数量(和复杂性)可能令人震惊。
_“微服务构架允许您迅速行动,但会产生相应的操作成本。_您要 __ 确定是否愿意承担该成本。”
《金融时报》 FT.com 网站由微服务后台支持,主要使用 Java 和 Go 编程语言,与 Docker 和 CoreOS 一起打包并部署到 Amazon 网络服务(AWS)平台。FT 将数据存储在 mongoDB、elastic、neo4j 和 Apache Kafka 中。
在任何时候,该后台都有 99 种功能服务和 350 个运行实例,以及 52 种非功能服务和 218 个运行实例。Wells 表示,如果每分钟检查这 568 个实例一次,则一天需要检查 817920 次。
共享虚拟机(VM)上的运行容器需要 92160 次系统级别检查,一天检查的总次数为 910080 次。另外,任何基于微服务的应用都是分布式系统,因此服务不会独立运行。
如果出现故障,则导致级联故障,使监控和报警复杂化。
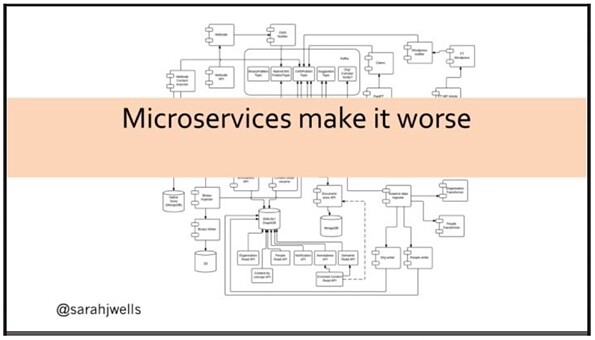
Wells 认为,基于微服务的应用为监控带来了更严峻的挑战。
为适应监控微服务应用带来的挑战,Wells 提出一种三管齐下的办法:构建可被支持的系统,专注于“重要的东西”,以及筛选和增添警报和它们所包括的信息。
为构建可被支持的系统,日志聚合和监控必不可少。由于服务量和网络通讯产生的时延,日志可能丢失或延迟,因此任何分布式系统都需要日志聚合。反过来说,这意味着基于日志的警报可能存在丢失问题,尤其是存在时效性的问题。有效的日志聚合需要一种找到所有相关日志的方法,因此 FT 团队使用事务 id 进行关联。
当实施监控时, Nagios 等传统监控工具往往受到限制,因为它不提供“服务级别”视图,而且默认(基础设施)检查出来的某些问题无法被修复。在基于微服务的系统中,监控应该处于服务和虚拟机级别。监控需要被聚合且可视化,FT 技术团队使用名为 SAWS (由 Silvano Dossan 构建)的自定义框架和 Dashing 。通过 Graphite 和 Grafana 也可广泛地绘制相关图表等。

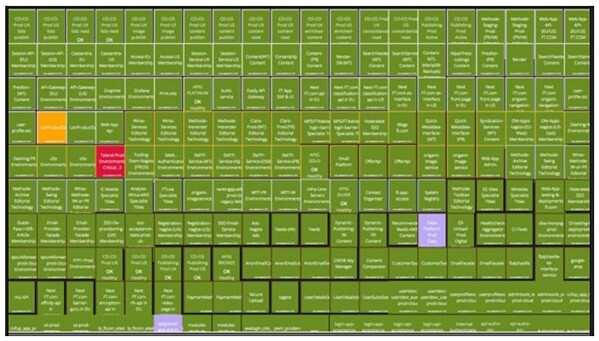
FT.com 技术团队的 SAWS 聚合监控
在开发多语言服务时,对于所使用的语言必须易于日志聚合和监控整合。必须指明期望值或操作合同,而且每位服务负责人需负责实现满足该需求的功能。例如,FT healthcheck 标准要求每种服务通过 HTTP, ' http://service/__health’公开一个供 healthcheck 的端点,如果服务能够运行 healthcheck 的话,它会返回 200;除此之外,FT healthcheck 还要求每种服务需要提供 1 个 JSON 文档,其中需要包含多次 healthcheck,以提供附加信息,但返回值必须为“ok”:“true”或“ok”:“false”。
 ****
****
****FT.com 微服务警报仪表盘,由 dashing.io 框架支持。
监控与警报的一个核心目标是在客户使用之前发现问题,因此,运行模拟用户功能行为的“模拟请求(s ynthetic requests )”至关重要。如果与用户主进程有关的功能崩溃,则必须马上解决该故障,例如,FT 编辑器不能发布新文章。Wells 表示,工程师必须学会如何安排优先顺序,而且“关注重要的事情”。FT 技术团队还创建了显示错误数量和响应延迟等客户核心统计数据的仪表盘,但是,Wells 强调,“重要的是端到端(业务功能)”,而且“如果您只需要信息 ,去新建一个仪表盘或报告就好”。
必须不断筛选和增添警报,如果接收到无意义或者无需人为干预的警报,则必须进行修正或移除。如果出现问题且没有警报,则应将该问题列入需修复部分。每个警报中必须包含主要信息,例如,业务影响概览、相关的 run book (运行资料)位置、以及触发该问题的相应事务 id。

例如,FT.com 警报包括问题、影响、事务 ID 和以及相关运行资料的链接等信息。
FT 团队使用专门的“Ops Cops”(开发团队的成员定期轮换随时待命),观察监控问题,将警报集成到团队的 Slack 信息发送系统。预定义 emoji 表情符号列表(每个都描述有清楚明确的目的)用于表明管理和处理问题的时间和方法。
在座谈总结中,Wells 提出创建警报应为标准开发流程的一部分该标准流程应当为“代码、测试、警报”。为确保开发团队知道警报是否停止工作,还应加入验证该警报的测试。FT 技术团队认同混乱测试哲学,受 Netflix’s Simian Army 和 Chaos Monkey 的启发,创建了“Chaos Snail”(它比 Monkey 更小,用 Bash shell 编写!)。Wells 警告说,在维护和处理重要系统中的警报时,需要积极主动性,过时的信息比没有信息更糟糕。尽可能自动化更新,并找到办法分享更新的内容。
在 Speaker Deck 上可以观看 Sarah Wells 的 QCon 伦敦讲座“避免来自微服务的警报过载”的幻灯片,您也可以在 InfoQ 观看视频。
关于作者
 Daniel Bryant 正引领组织和科技领域的变革。他目前的工作内容包括,通过引入更好的需求收集和规划技术增强组织内部敏捷,关注敏捷开发内构架的相关性,促进持续的集成 / 交付。Daniel 目前的技术专长主要是“DevOps”工具,云 / 容器平台,以及微服务实现。他还是伦敦 Java 团体(LJC)的领导者,为开放源码项目提供帮助,为 InfoQ、DZone 和 Voxxed 等知名技术网站撰写文章,并定期出席 QCon、JavaOne 和 Devoxx 等国际会议。
Daniel Bryant 正引领组织和科技领域的变革。他目前的工作内容包括,通过引入更好的需求收集和规划技术增强组织内部敏捷,关注敏捷开发内构架的相关性,促进持续的集成 / 交付。Daniel 目前的技术专长主要是“DevOps”工具,云 / 容器平台,以及微服务实现。他还是伦敦 Java 团体(LJC)的领导者,为开放源码项目提供帮助,为 InfoQ、DZone 和 Voxxed 等知名技术网站撰写文章,并定期出席 QCon、JavaOne 和 Devoxx 等国际会议。
查看英文原文: https://www.infoq.com/articles/observability-financial-times
感谢罗远航对本文的审校。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论