

本文作者是 GPT-2 的热心用户,GPT-2 风靡 AI 领域的那段时间里,他撰写了不少相关的文章。然而当 GPT-3 的论文发布后,身为忠实用户的他却感觉到了一些失望,本文他将深扒 GPT-3 中那些令人失望的地方。另注:这篇文章是作者最近在 tumblr 上发表的两篇文章的汇总。
利益相关:我一直是 GPT-2 的热心用户,也写过很多关于 GPT-2 和 transformer 模型的文章,包括"human psycholinguists: a critical appraisal"和"the transformer … “explained?”。我还用 GPT-2 作为核心组件做了一个tumblr bot。
第一部分
这篇论文(https://arxiv.org/pdf/2005.14165.pdf)我还没特别仔细地研究过,但下面几点是我可以肯定的:
1.1:GPT-3 有多大开创性
“GPT-3”只是 GPT-2 的放大版。换句话说,这只是“就让 transformers 变大就行了”这种方法的粗暴延伸。自 GPT-2 诞生以来,很多研究小组都在使用这种方法。
论文摘要就这一点讲得很清楚:
有一些工作主要是增加语言模型中的参数数量和/或计算量,以此作为改进生成或任务性能的手段。[……]一项工作直接增加了 transformer 模型的大小,并按接近的比例增加了参数量和每个令牌的 FLOPS。这方面的工作让模型大小不断扩张:原始论文中有 2.13 亿个参数[VSP+17],3 亿个参数[DCLT18],15 亿个参数[RWC+19],80 亿参数[SPP+19],110 亿参数[RSR+19],最近更是来到了 170 亿参数[Tur20]。
这里提到的前两篇论文分别是机器翻译的原始 transformer(VSP+17)和 BERT(DCLT18)。这两篇论文之间的参数量还没膨胀那么多。
第三篇(RWC+19)是 GPT-2,其参数量扩大到了 5 倍。GPT-2 论文的重点大概就是“虽然看起来这方法很笨很粗暴,但只要你扩大 transformer 就会看到神奇的结果”——而这篇"GPT-3"论文的论点还是一样,只不过数字变得更大了。
“GPT-3”是一个拥有 1750 亿个参数的 transformer。数字上这又是一次飞跃,但是基础架构并没有太大变化。
从某种意义上说,把它叫做"GPT-3"也挺合理的:它就是 GPT-2 带起来的这种风气的延续而已。
但换个角度来说,把它叫做“GPT-3”也很碍眼,而且会误导人。GPT-2(可以说)是一项开创性的进步,因为它第一次向人们展示了大规模的 transformer 拥有多大的力量。现在大家都知道了这个道理,所以 GPT-3 完全称不上什么本质上的进步。(既然他们这个新的大模型能叫"GPT-3",那么上一段引文里最后提到的那仨大模型也有资格叫这个名字了。)
1.2:“小样本学习”
这篇论文好像要讨好的就是 NLP 社区,只不过他们完全走反了方向。
GPT-2 论文认为,语言模型(文本预测器)在用作 NLP 基准测试的一些特定任务上可以做得很好,或者在某些场景下“至少不是很糟糕”——即使模型事先并不了解这些任务的细节。这主要是为了证明语言模型的能力有多强。
他们在论文中展示的“零样本(zero-shot)”学习——就是“在文本后添加一句话总结,并将 GPT-2 的续写(continuation)当作’摘要’来看待”这种东西——又怪又蠢,实践中没人想要这么干。这种方法更适合用来证明优秀的语言模型"无所不能",就算不是它们设计目标的任务也能搞定;重点不是说它们在这些任务中"表现优秀",而是说它们即便没有充分的准备也能获得不错的性能水平。这有点像在夸奖一个小神童。
在 GPT-3 论文中,他们为语言模型引入了一种新方法,以提升模型在标准测试中的表现。现在的关键是根据文本的走向来"搞清楚"它们应该做什么事情。以前是给模型一个提示(prompt),比如说:
问:法国的首都是哪里?
答:
现在则给出多个提示:
问:法国的首都是什么?
答:巴黎
问:西班牙的首都是什么?
答:马德里
问:立陶宛的首都是什么?
答:维尔纽斯
问:巴西的首都是什么?
答:
对 NLP 社区来说,"GPT-3"中值得关注的一点是,语言模型在标准测试集上的表现可以比我们想的要强很多,途径就是这种多提示方法和更大的参数量。将这两种方式结合起来后,你甚至可以在一部分任务中获得最顶尖的成绩。
我觉得有些人会认为这是很重要的,他们会觉得这表明 transformer 语言模型具备像人类那样,只需很少的数据就"迅速抓住重点"的能力。这和 Gary Marcus 的某些看法也有关系。
但在"直接学习(learning on-the-fly)"这个层面,这篇论文似乎完全没兴趣可言,这很古怪。论文中有一大堆图表,展示的都是各种参数条件下的性能表现,总之就是为了说明越大越好。但是我只找到了一个图表展示的是和参数 K 相关的性能表现,K 就是提示中不同任务示例的数量。
而且这张图展示的数据并没那么好看:
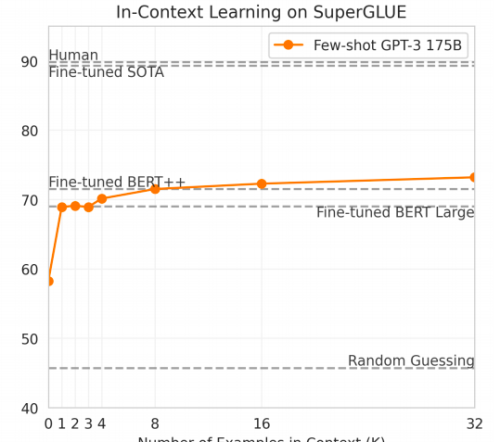
一个任务示例的表现要好于零个示例(GPT-2 论文就是零),但示例数量继续增长下去就没什么效果了;显然这里"越大越好"的理论没怎么生效。
奇怪的是,这张图的标题说明了这些是开发数据集的结果,因此不能直接与水平线给出的测试集结果对比——可他们还是这么画了!他们的确在其他地方报告了 SuperGLUE 的测试集结果,但是只适用于 K=32。此外,这张图缺少误差线也是个问题。
1.3:基准测试
他们在这篇论文中谈的全是如何在测试集的某些指标上取得出色的成绩。
所以我说它就是为了讨好 NLP 社区:整个社区都用这些指标衡量自己的水平,因此理所当然地,社区“必须”重视这些结果。可是到这一步,这就有点像古德哈特定律的样子了(为刷分而刷分)。
GPT-2 并不是因为在这些任务上表现出色才脱颖而出的。它之所以有那么高的地位,是因为它是一个非常好的语言模型,展示了一种对语言的全新理解方式。它在标准测试中做的好不好对我来说没那么重要,强调这一点就好像是习惯用右手的人只用左手画了一幅画(还画得不怎么样),以此来证明他多有艺术天赋一样。
GPT-2 的优秀之处并不在于它擅长“回答问题”,而在于它擅长所有任务,因此只盯着"回答问题"就显得目光很短浅了。
GPT-2 为 transformer 带来的进步太大了,所以社区甚至创建了一个新的基准测试“SuperGLUE”,因为以前的黄金标准(GLUE)现在显得太简单了。
GPT-3 实在没什么进步,甚至在 SuperGLUE 上表现都不怎么样。它也就相当于把人的右手绑背后还能勉强画一幅画的水平。
可能有人会说,10 岁的数学神童并没有证明什么新定理,但是他用 10 分钟就能在高考数学卷上拿到不错的成绩,这难道不算是突破性的进步吗?
也许是吧?有那么一点?
1.4:烦恼
我思考这篇论文思考得越多,它就越让我心烦意乱。本来 transformer 是非常有趣的事物。可是在 2020 年,这可能是关于 transformer 最无趣的论文了。
第二部分
2.1:再谈“小样本学习”
初读时,我以为论文中只有一个图展示了性能随 K(小样本数量)变化的情况,但我没注意论文第 4 页的图 1.2。
这张图比前文提到的那张给的数据要好些,但并不足以改变我的看法,那就是作者并没有多大兴趣来展示在文本走向上的"渐进式学习"。
他们试图用图 1.2 证明的论点是,更大的模型会带来更多的渐进式学习,因此,他们的整体策略——“使用大模型+小样本学习以提升基准测试表现”——是让两个部分(大型模型,少量学习)产生一加一大于二的效果。
同样,如果你关心的是 NLP 基准测试上的成绩,那他们的说法还是很有趣的。但就整体的语言理解水平而言,我看不到有什么明显的进展。
2.2:关于新颖词
他们其中一项实验,“学习和使用新单词”给我留下了深刻的印象,但其他实验就没这效果了。可是这篇论文并没有在这里着墨很多,这让我很奇怪。(这部分在第 3.9.5 节和表 3.16。)这个任务与 Wug 测试联系很紧密——这也是 Gary Marcus 在批评 GPT-2 时很关注的一件事:
[人类的提示]“farduddle”的意思是快速地蹦蹦跳跳。这个词的例句:
[GPT-3 延续]有一天我和妹妹玩耍时,她越玩越兴奋,开始撒欢儿似的蹦蹦跳跳。
语言学家研究人类儿童时就会涉及这类任务,过去的 NLP 模型在这方面表现很差。这方面的进展本应该得到最高的认可。作者显然提到了他们在这方面取得的成就,但却只是随口一提:论文说他们尝试了 6 次并全部成功(100%的准确度?!),但他们显然没把它当回事,并没有在较大的样本上重复实验,测一个真实指标,并展示 w/r/t 参数下的表现,等等。可是他们在其他 40 项任务上都做了这套流程,而我觉得那些任务根本没这么有趣,真是让人困惑!
2.3:关于抽象推理
除了常见的 NLP 基准测试外,他们还尝试了一些“综合或定性”任务(第 3.9 节)。他们的目标是阐明“小样本学习”中学习的实际作用:
在小样本(或单样本和零样本)设置下探究 GPT-3 的能力范围的一种方法,是赋予它要求执行简单的即时计算推理的任务,识别一种新颖的模式,即不太可能在训练中发生,或迅速适应异常任务。
这里的“综合或定性”任务是:
各种形式的简单算术(例如“加两个 2 位数”)
对单个单词的字母所做的各种解谜/反转等任务
SAT 类比
感觉这项工作的理论基础还不够牢固,所以解释起来很困难。
拿算术任务来说。我们先认可作者的前提,那就是模型不仅存储了一些算术问题的查找表,而且还可以即时“解决问题”。这样,模型在这里可能有两种状态(也可能是同时做的):
在训练文本中看到许多相关数字后,模型可能已经在内部开发出了一个真正的算术模型,并且正在应用该模型来解决你我会遇到的问题;
它可能为各种抽象任务发展出了一些通用推理能力,进而可以将算术作为更通用的问题类别的特殊情况来做处理(比如说,如果有合适的提示,它也会考虑很多算术符号没有实际含义的场景。)
只要第 1 种情况出现了,小样本学习中的多次提示就没什么意义了:如果模型知道真正的(不是虚假的)算术是如何进行的(它从文本中学到了这一点),那么再多的示例也无助于"定位任务"。就是说,如果它只学会了真实的算术,就不需要告诉它“在这个任务中,+号是加号的标准含义”,因为它的能力就是基于这一假设的。
因此,如果我们在这里主要看到的是第 1 种情况,那么这个演示就并不能像作者想的那样展示小样本学习的意义。
如果是第 2 种情况,那么小样本提示确实很重要:它们在可能的形式系统的大空间中“定位了符号的含义”。但是这种情况太疯狂了:它意味着语言模型获得了更加一般化的智力,这可不是什么小事情。
我不觉得作者的目的是要证明这一点。如果他们认为语言模型是通用的推理机,为什么不强调这一点呢?人们已经充分探索过 transformer 的抽象推理能力,并且没理由认为非常大型的特定于语言的模型可以发展出强大的通用推理能力。(当然了,也可以认为这种能力是作者的方法没能检测出来的文本识别/记忆能力的某种变体。)
我觉得作者应该是把任务分解为“知道如何做”和“知道我们现在正在做”两个部分。用文本训练模型可以告诉它如何做(真实的)算术,而小样本提示会告诉模型“现在我们正在做(真实的)算术,不是你学会的其他那些内容”。
但如果你想探索这个方向,算术是非常糟糕的选项!作者在此处使用了 K=50,也就是说他们为模型提供了 50 个简单的数学问题的正确示例,以使其“定位任务”。但如果需要 50 个示例这么多的话,没人可以完成这项任务。
第 50 个示例包含哪些第 49 个示例中所没有的信息?这里我们要排除什么内容?难道是要排除大部分时间都像加法的陷阱系统吗?"加法,只是 52 实际等于 37,其他都一样?"当模型必须学习真正的加法时,我们真的应该排除它吗?
我不知道作者在这里想做什么,我想他们自己也许也不知道。
编者注:最后附上图灵奖得主 Geoffrey Hinton 对 GPT-3 的评价——鉴于 GPT-3 在未来的惊人前景,可以得出结论:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已。
原文链接:
https://www.lesswrong.com/posts/ZHrpjDc3CepSeeBuE/gpt-3-a-disappointing-paper

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论