
作者 | Timothy B Lee
译者 | 核子可乐
策划 | Tina
OpenAI 仍未明确解释 Q*究竟是什么,但透露的线索倒是相当不少。
11 月 22 日,就在 OpenAI 决定解雇(后又重新聘用)CEO Sam Altman 的几天之后,技术媒体 The Information 报道称 OpenAI 取得了一项重大技术突破,使其能够“开发出更强大的 AI 模型”。新模型被命名为 Q*(音为「Q star」),“具备解决全新数学问题的能力。”
路透社也发表了类似的报道,但细节同样含糊不清。
两篇报道都将这项突破与董事会解雇 Altman 的决策联系起来。路透社在报道中指出,几名 OpenAI 员工向董事会发函,“警告称这项强大的 AI 发现可能对人类构成威胁。”然而,“路透社未能拿到这封信的副本”,随后的报道也没有继续将 Altman 下台与 Q*一事联系起来。
The Information 指出,今年早些时候,OpenAI 开发出“能够解决基本数学问题的系统,攻克了这一对现有 AI 模型来说颇为艰巨的任务。”路透社则表示 Q*“具备小学生水平的数学计算能力。”
为了避免妄下结论,我们又花了几天时间搜集相关内容。OpenAI 确实没有公布 Q*项目的详细信息,但发表了两篇关于其解决小学数学问题的论文。在 OpenAI 之外,不少研究人员(包括 Google DeepMind 的研究人员)也一直在这方面开展探索。
我个人怀疑 Q*正是指向通用人工智能(AGI)的关键技术突破。虽然不一定会对人类构成威胁,但这可能标志着迈向具有一般推理能力的 AI 的重要一步。
在本文中,我们将一同了解 AI 研究领域的这一重大事件,并解释专为数学问题设计的分步推理技术如何发挥关键作用。
分步推理的力量
我们首先考虑以下数学问题:
John 给了 Susan 五个苹果,之后又给了她六个。之后 Susan 吃掉其中三个,又给了 Charlie 三个苹果。她把剩下的苹果给了 Bob,Bob 吃掉一个。接下来,Bob 把手中半数苹果给了 Charlie。John 给了 Charlie 七个苹果,Charlie 将手中三分之二的苹果给了 Susan,最后 Susan 又把其中四个还给了 Charlie。问,现在 Charlie 还剩几个苹果?
大家可以先试着自己算算。
其实我们都在小学阶段学过简单的加减乘除,所以看到问题里说“John 给了 Susan 五个苹果,之后又给了她六个”,就知道这时候 Susan 有 11 个苹果。
但对于更复杂的问题,那人类在尝试解决时就需要借助笔算或者心算了。比如在此问题中,先有 5+6=11,之后是 11-3=8,接着 8-3=5,以此类推。通过一步步思考,我们最终会得到正确答案:8。
同样的技巧也适用于大语言模型。在 2022 年 1 月发表的著名论文中,谷歌研究人员指出,如果大语言模型能按照提示词分步进行推理,就会产生更好的结果。以下是论文中的一份关键图表:
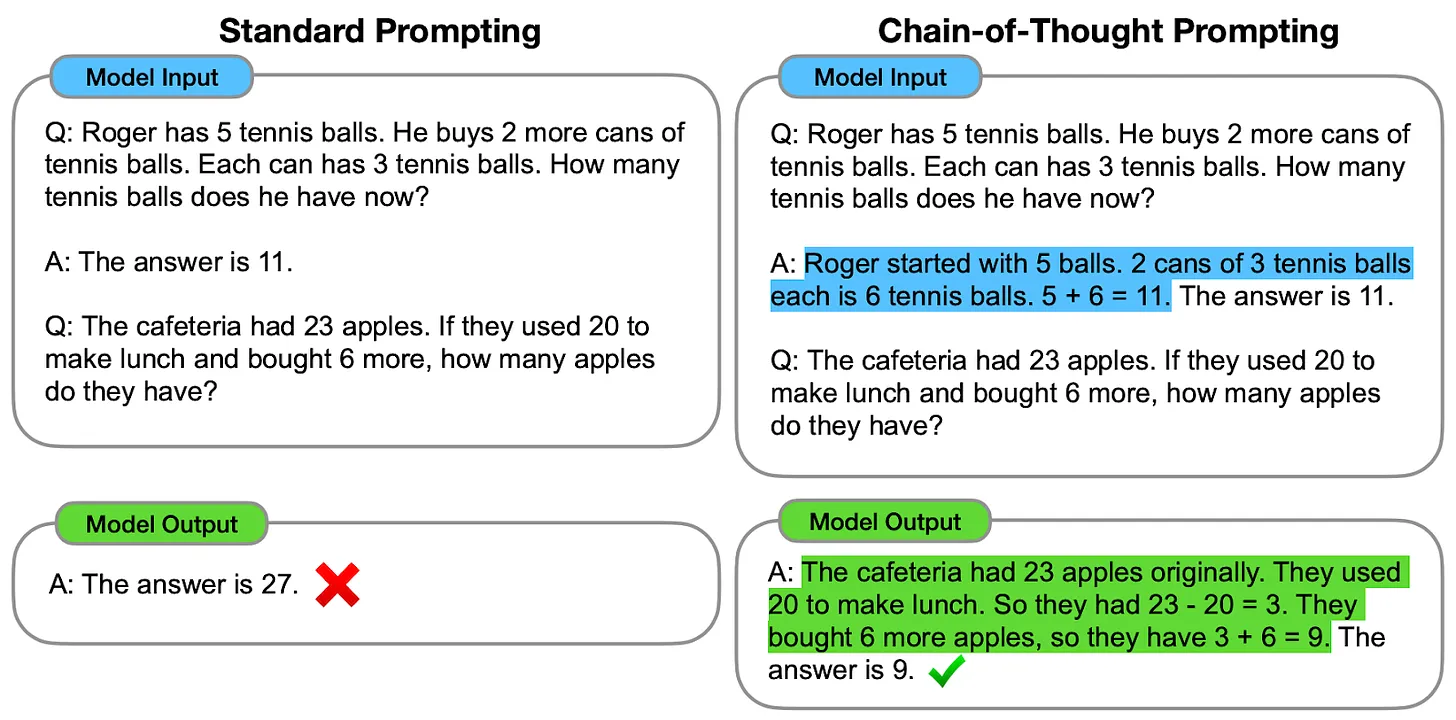
这篇论文的发表时间还早于“零样本”提示技术,因此研究人员通过给出示例答案的方式来提示模型。在左图中,系统会提示模型直接给出最终答案,但结果是划的。而在右侧,系统会一步步提示模型并最终推理出正确答案。谷歌研究人员将这项技术称为“思维链提示法”,且至今仍被广泛应用。
对于大语言模型来说,“五”和“六”这样的数字只是 token,跟“这”、“那”或者“猫”没什么区别。这些模型之所以能把大写数字转换成 5+6=11,是因为这个 token 序列曾经在训练数据中出现过。但大模型的训练数据中可能并不包含长计算示例,比如((5+6-3-3-1)/2+3+7)/3+4=8,所以如果要求模型直接给出计算结果,那它就很可能搞不清状况并生成错误答案。
或者用另一种思路来解释,大语言模型没有可用于记忆中间结果(例如 5+6=11)的外部“临时空间”。而思维链推理使得大模型能够有效使用自己的输出作为暂时记忆空间,从而将复杂问题拆分成更多步骤——每个步骤都可能与模型训练数据中的示例相匹配。
解决更复杂的数学难题
在谷歌发表关于思维链提示法论文的几个月前,OpenAI 曾经推出一套包含 8500 道小学数学应用题的 GSM8K 数据集,以及一篇描述问题解法新技术的论文。OpenAI 没有让模型逐一给出答案,而是要求其一次性给出 100 个思路答案,再通过名为验证器的另一套模型对各个答案进行评分。在这 100 条回复中,系统将只返回评分最高的答案。
乍看起来,训练验证器模型也需要大费周章,难度不啻于训练大语言模型来生成正确答案。但从 OpenAI 的测试结果来看,情况并非如此。OpenAI 发现只需小型生成器与小型验证器的组合,就能提供与单独使用超大生成器模型(参数是前者的 30 倍)相当的结果。
2023 年 5 月的一篇论文介绍了 OpenAI 在该领域的最新研究情况。OpenAI 已经跨越小学数学,开始研究更具挑战性的 MATH 数据集。OpenAI 现在不再让验证器对完整答案打分,而是训练验证器具体评估各个步骤,具体参见论文给出的下图:

每一步都有一个绿色笑脸符号,代表该步骤处于正确的思路之上,直到最后一步模型得出“x=7”,这时打出的是红色的皱眉符号。
文章得出的结论是,在推理过程中的各个步骤上都使用验证器,其结果比直接验证最终答案更好。
这种逐步验证方法的最大缺点,就是更难实现自动化。MATH 训练数据集中包含每个问题的正确答案,因此很容易自动检查模型是否得出了正确的结论。但 OpenAI 未能找到更好的方法来自动验证中间步骤。于是,该公司只能聘请了一些审查员,为 7.5 万个解题思路的共 80 万个计算步骤提供反馈。
求解路漫漫

需要注意的是,GSMK8K 和 MATH 数据集中的问题至少还可以通过分步方式简单解决。但在实际应用中,相当一部分数学问题根本无法拆解,例如:
你正在筹划一场分五张餐桌、每桌三位客人的婚宴。
Alice 不想跟 Bethany、Ellen 或者 Kimmie 一起坐。
Bethany 不想跟 Margaret 一起坐。
Chuck 不想跟 Nancy 一起坐。
Fiona 不想跟 Henry 或者 Chuck 一起坐。
Jason 不想跟 Bethany 或 Donald 一起坐。
Grant 不想跟 Ingrid、Nancy 或 Olivia 一起坐。
Henry 不想跟 Olivia、Louise 或 Margaret 一起坐。
Louise 不想跟 Margaret 或 Olivia 一起坐。
要如何安排客人座位,才能充分满足他们的要求?
在把这样的提示词输入 GPT_4 时,它开始分步进行问题推理:
餐桌 1:Alice、Chcuk 和 Donald。
餐桌 2:Bethany、Fiona 和 Ellen。
餐桌 3:Jason、Grant 和 Ingrid。
但到第四张餐桌时,它就卡住了。这时候 Henry、Margaret 和 Louise 还没有入座,他们彼此都不想坐在一起,但接下来只剩两张桌子可以安排。
在这个问题中,我们不知道 GPT-4 具体错在哪个具体步骤上。它在前三张桌子的安排上完全满足规则,但这些前期选择也导致余下的客人没办法正确入座。
这就是计算机科学家们所说的 NP 难题,即不存在通用算法以线性方式加以解决。唯一的办法就是尝试一种可能的安排,看看是否符合要求,如果不行则推倒重来。
GPT-4 可以通过在上下文窗口中添加更多文本来完成回溯,但其扩展能力仍然有限。更好的方法是为 GPT-4 提供一个“退格键”,这样它就能删除最后一个或几个推理步骤,然后重试。为此,系统还需要一种方法来跟踪它已经尝试过的组合,避免重复尝试。如此一来,大语言模型就能探索下图所示的可能性树:
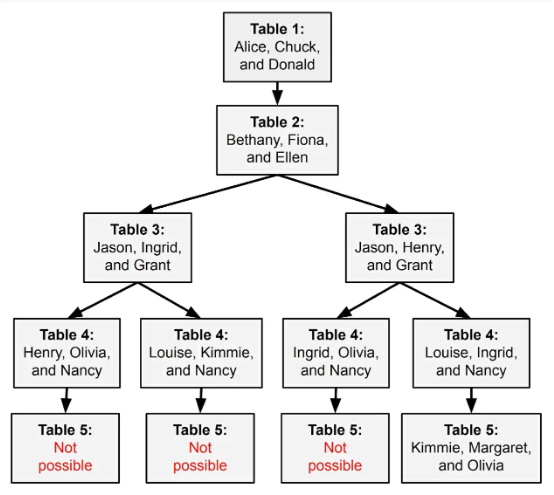
今年 5 月,普林斯顿大学和 Google DeepMind 的研究人员共同发表论文,提出一种名为“思路树”的方法。思路树不再用单一推理链来解决问题,而是允许大模型系统探索一系列指向不同方向的推理链“分支”。
研究人员发现,该算法在解决某些传统大语言模型难以解决的问题上表现良好。其中不仅包括所谓“24 点游戏”(即通过添加运算符号将随机给出的几个数字计算为 24),还实现了创意写作能力。
AlphaGo 模型
以上,就是 OpenAI 和 DeepMind 迄今为止发表过的所有研究成果,可以看到他们都在让大语言模型更好地解决数学问题方面付出了不懈努力。现在,我们一起来推测这项研究最终可能会走向何方。当然,这些猜测没有任何依据,大家也可以根据自己掌握的情况做出展望。
今年 10 月,播客 Dwarkesh Patel 曾就通用人工智能开发计划采访过 DeepMind 联合创始人兼首席科学家 Shane Legg。Legg 认为,迈向 AGI 的关键一步就是把大语言模型跟搜索可能响应的树结构结合起来:
这些基础模型属于某种世界模型,通过搜索方式实现问题的创造性解决能力。以 AlphaGo 为例,它那惊人的棋路到底是从何而来?是学习了人类棋手的经验,还是参考了原有数据?不,根本没有。它其实是选择了一个非常罕见、但也极为合理的棋步,再通过搜索过程思考这步棋会造成怎样的后续影响。也就是说,要想获得真正的创造力,必须探索可能性空间并找出隐藏其中的最佳答案。
Legg 在这里提到了著名的“第 37 手”,即 2016 年 DeepMind AlphaGo 软件与顶尖棋手李世石第二场比赛中的一步。大多数人类选手最初都觉得 AlphaGo 在这步棋上出现了失误,但其最终刻了比赛,且复盘分析发现这是一手强棋。换言之,AlphaGo 表现出了超越人类棋手的布局洞察力。
AlphaGo 能够根据当前棋盘状态模拟出数千种可能的后续发展,从而获取类似的见解。对于计算机来说,潜在棋序实在太多,根本不可能一一检查,所以 AlphaGO 使用神经网络来简化整个过程。
其中的策略网络能够预测出哪些棋路最有希望,值得进一步做模拟分析。而价值网络则负责估算棋盘的当前状态是对白方有利、还是对黑方有利。根据这些估算,AlphaGo 再逆向计算下面一步该怎么走。
Legg 的观点是,这类树搜索方法有望提高大语言模型的推理能力。大语言模型要预测的不只是单个最可能出现的 token,而应在给出回答之前探索数千种不同的响应。事实上,DeepMind 的思维树论文似乎就是朝这个方向迈出的第一步。
前文提到,OpenAI 曾经尝试使用生成器(生成潜在答案)与验证器(估算这些答案是否正确)组合来解决数学问题。这与 AlphaGo 明显有几分相似,同样可以理解成策略网络(生成潜在棋步)与价值网络(估算这些棋步能否导向更有利的盘面状态)。
如果将 OpenAI 的生成器/验证器网络与 DeepMind 的思维树概念相结合,就能得到一套与 AlphaGo 非常相似的语言模型,同时保留 AlphaGo 的强大推理能力。
为何命名为 Q*
在 AlphaGO 之前,DeepMind 曾在 2013 年发表过一篇关于训练神经网络以打通雅达利电子游戏的论文。DeepMind 并没有手动录入每款游戏的规则,而是让网络不断游玩这些游戏,通过反复试验自行理解玩法。
参考早期强化学习技术 Q-learning,DeepMind 将这套雅达利解决方案命名为 Deep Q-learning。DeepMind 的雅达利 AI 中包含一个 Q 函数,用于估算任意特定操作(例如向左或向右推操纵杆)可能获得的奖励(比如更高的得分)。当系统游玩雅达利游戏时,它会不断优化 Q 函数,提升获取更佳得分的估算能力。
DeepMind 2016 年在 AlphaGo 论文同样使用字母 Q 来表示 AlphaGo 中的棋步价值函数——该函数用于估算任意给定棋步有多大可能通往对局胜利。
AlphaGo 和 DeepMind 的雅达利 AI 都属于强化学习的范畴,这是一种从经验中学习知识的机器学习技术。在大语言模型兴起之前,OpenA 也 I 一直将强化学习作为关注重点。例如,OpenAI 曾在 2019 年使用强化学习让机械臂在自行探索中学会解开魔方。
参考这些背景,我们似乎可以对 Q*做出有理有据的解读:它是将大语言模型同 AlphaGo 式搜索能力相结合的产物,而且应该是在以强化学习的方式进行混合模型训练。其重点就是找到一种在困难的推理任务中“自我较量”的方式,借此改进语言模型的实际能力。
其中一条重要线索,就是 OpenAI 今年早些时候决定聘请计算机科学家 Noam Brown。Brown 在卡耐基梅隆大学获得博士学位,并在那里开发出首个能够超越人类水平的扑克 AI。之后 Brown 加入 Meta,并开发出玩《强权外交》桌游的 AI。这款游戏的成功秘诀在于同其他玩家结成联盟,因此 AI 必须把战略思维与自然语言能力结合起来。
由此看来,这似乎就是帮助大语言模型提高推理能力的绝佳案例。
Brown 今年 6 月在推文中表示,“多年以来,我一直在研究扑克和〈强权外交〉桌游中的 AI 自我对弈和推理课题。现在,我想探索如何将成果转化为普适性能力。”
AlphaGo 和 Brown 扑克 AI 中使用的搜索方法,明显只适用于这些特定游戏。但 Brown 预测称,“如果我们能发现一个通用版本,则必然带来巨大的收益。没错,推理速度可能会降低至千分之一且成本迅速膨胀,但如果能够发现新的抗癌药物、或者证明黎曼猜想,这一切难道不值得吗?”
而在 Brown 于今年早些时候离职之后,Meta 公司首席 AI 科学家 Yann LeCun 表示,他认为 Brown 研究的就是 Q*。
LeCun 在 11 月的推文中指出,“看起来 OpenAI 更进一步的探索就是 Q*,他们还聘请了 Noam Brown 来协助解决这个问题。”
两大挑战
如果大家跟科学家或者工程师共事时,就会注意到他们特别喜欢用白板。当我自己在研究生院学习计算机科学时,我们就经常站在白板前面绘制图表或者议程。随后在谷歌的实习经历,也让我意识到技术大厂里同样到处都是白板。
白板确实很有启发意义,因为面对极为困难的技术问题,人们刚开始根本不知道该如何下手。他们可能会花几小时勾勒出了种潜在的解决思路,却发现根本就不适用。之后他们就擦掉一切,从零开始找个不同的切入角度。或者,他们也可能觉得方案的前半部分还行,于是擦掉后半部分再换条新的探索路线。
这本质上就是一种智能树搜索:对多种可能的解决方案进行迭代,直到找出一个似乎可以实际解决问题的路线。
OpenAI 和 DeepMind 之所以对大语言模型加 AlphaGo 搜索树感到如此兴奋,就是因为他们希望计算机也能执行同样的开放式智能探索。到那个时候,我们只需要把充满挑战的数学问题输入给大语言模型,然后安心上床睡觉。第二天早上醒来,它已经考虑了几千种可能的解决方案,并最终给出一些可能有希望的探索方向。
这当然是个鼓舞人心的愿景,但 OpenAI 至少还要克服两大挑战才能将其转化为现实。
首先,就是找到一种让大语言模型进行“自我对弈”的方法。AlphaGo 就是通过自我对弈完成了对顶尖人类棋手的碾压。OpenAI 也在模拟物理环境中进行魔方实验,通过判断魔方是否处于“解开”状态来判断哪些操作有正向作用。
而他们的梦想就是建立起一套大语言模型,通过类似的自动化“自我对弈”方式提高推理能力。但这就需要一种能够自动检查特定解决方案是否正确的办法。如果系统还需要人类来检查每条答案正确与否,那么训练规模将非常有限、难以带来可与人类匹敌的推理水平。
就在 2023 年 5 月发表的论文中,OpenAI 还在聘用审查员来核对数学答案的正确性。所以如果真的出现了突破,那肯定是发生在过去这几个月间。
学习是个动态的过程
我认为第二个挑战才是根本:通用推理算法,必须在探索各种可能性时表现出动态学习能力。
当人们尝试在白板上推衍解题思路时,他们并不是在机械地迭代各种可能路线。相反,每试过一个失误的路线,人们对问题的理解也就又加深了一步。在推理过程中,他们的心理模型也在不断演进,逐渐生出能快速判断哪种方法更好的强大直觉。
换句话说,人类内心的“策略网络”和“价值网络”并非一成不变。我们在同一个问题上花费的时间越多,在思考潜在答案时的判断能力也就增强,自然更善于预测当前思路是否有效。如果没有这种实时学习能力,我们一定会迷失在无穷无尽的潜在推理步骤当中。
相比之下,目前大多数神经网络在训练和推理之间保持着严格的边界。一旦训练完成,AlphaGo 的策略和价值网络就被固定下来了——后续任何比赛过程都不会产生改变。这对围棋来说没有问题,因为这项游戏的规则足够简单,可以在自我对弈的过程中体验各种可能的情况。
但现实世界要比方寸棋枰复杂得多。从定义上讲,研究者想要解决的是以往未能解决过的问题,所以实际情况很可能与训练期间遇到的任何问题都存在巨大差异。
因此,通用推理算法的实现必须在推理过程中持续获取见解,以便在模型解决问题的同时不断增强后续决策质量。然而,目前的大语言模型完全通过上下文窗口来维持状态,而思维树方法在现有模型的一个分支跳往另一分支时,之前的记忆信息会被新的上下文窗口直接删除。
一种可能的解决方案,就是使用图搜索来取代树搜索。今年 8 月的一篇论文就提到这种方法,尝试让大语言模型将来自多个“分支”的见解结合起来。
但我高度怀疑,真正的通用推理引擎恐怕需要在底层架构上做根本性创新。语言模型必须借助新的方法来学习超越训练数据的抽象概念,并利用这些不断发展的抽象概念强化探索潜在解决方案空间时的具体选择。
我们都知道这绝非妄言,毕竟人类的大脑就能做到这一点。而 OpenAI、DeepMind 乃至其他厂商可能还需要一段时间,才能搞清楚如何把这种方法照搬到硅芯片之上。
原文链接:
https://www.understandingai.org/p/how-to-think-about-the-openai-q-rumors




