

导读: 本次分享将围绕以图为基础衍生的一类推荐算法原理和应用,以及 E&E 问题 ( 如何应对新用户和新内容 ) 的一些处理方法。E&E 指探索与利用,是推荐系统当中的两个核心问题。
主要内容包括:
Background
Related Work
Our Work
01 Background
1. 推荐系统在 E&E 上的两大难点

在建立推荐系统的模型之前,我们需要获得用户和内容的相关数据。可是在推荐系统的实践中,经常会遇到冷启动的问题,即缺少新进入的用户信息和新进入的内容信息。对于用户信息,很多公司都会有市场部从市场上的各个渠道导入进来,成本较高,且无法完全覆盖。对于新进入的用户,他们往往是没有历史行为的,而这个行为特征却是推荐系统中最重要的特征之一。而新用户的留存对于公司是至关重要的,所以对于新用户的推荐要求尽可能的精准,使其对于平台产生忠诚度。新用户的推荐是推荐系统的第一个难题。第二个难点则是新内容的推荐,新内容首先是没有用户的反馈,没有用户的反馈也就无法利用相应的评估体系总结内容的真实价值。同时,新内容还存在难曝光的问题。现存的推荐系统,从比较传统的推荐系统,到 Word2Vec,再到现在各种各样的神经网络,在召回阶段都无法很好的召回新内容, 所以很难进入到训练样本中去,这是新内容的长尾问题。
2. 经典图模型—协同过滤
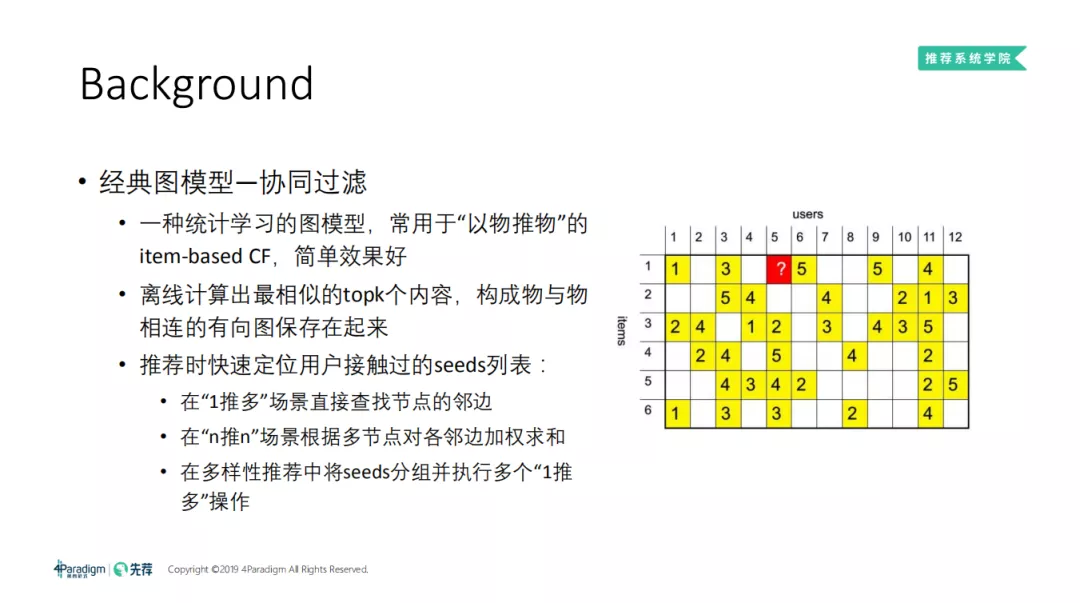
我们可以把协同过滤认为是一种图推荐模型, 因为用户和内容可以认为是二分图结构。推荐系统的宗旨是建立更多的用户到内容的链接,随着图越来越大,就可以抽取到更多的信息, 从而服务更多的用户。以 item-based CF 为例,通过计算 item 之间的相似度,从而计算出最相似的 topK 内容,把它们当作当前 item 的邻接点,构成物与物相连的有向图保存在起来。推荐时快速定位用户接触过的 seeds 列表:在"一推多"场景直接查找节点的邻边。 在 “n 推 n” 场景根据多节点对各邻边加权求和。在多样性推荐中将 seeds 分组并执行多个"一推多"操作。

CF 的缺点也很明显,首先,由于算法的设计问题,导致了它是一种偏热门推荐。在数据过滤的初期,没有达到某种阈值的 user 和 item 将会被过滤掉,形成马太效应。第二,容易形成内部环路。比如某些很受欢迎的主播,他们互为 topK,导致一直在他们内部互推。
这时,我们可以通过知识图谱和 node2vec 来拓展图的泛化能力。
3. Graph Embedding
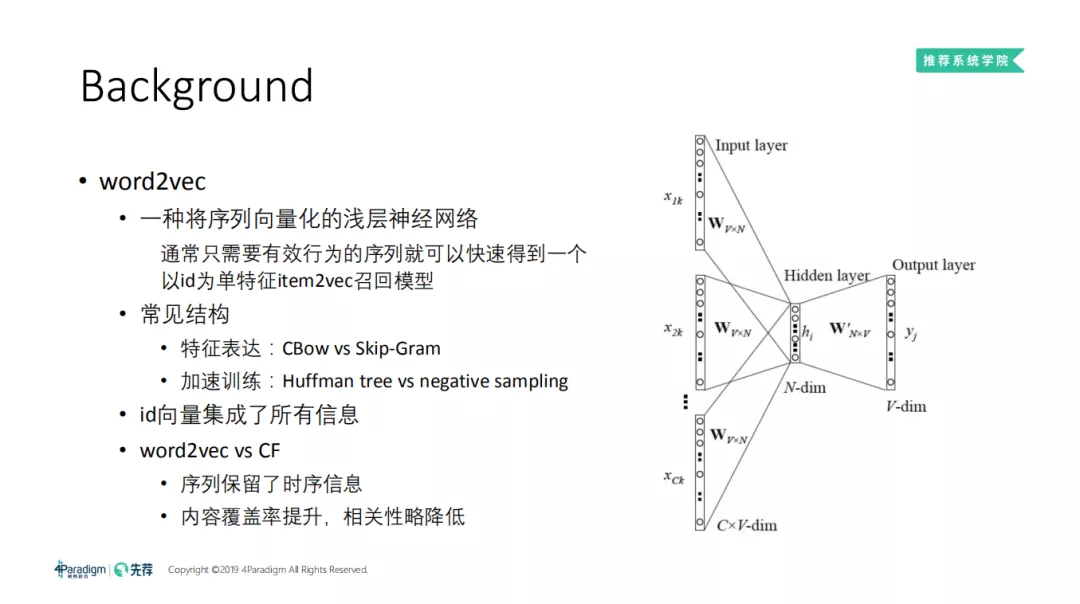
我们都知道在 NLP 任务中,word2vec 是一种常用的 word embedding 方法,来源于神经网络模型,是神经网络的一种中间结构的简化。结构如上图所示:
word2vec 通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示。它是将序列向量化的一个浅层神经网络,通常只需要有效行为的序列就可以快速得到一个以 id 为单特征 item2vec 召回模型。
Graph Embedding 的思想类似 word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。在 graph 中随机游走生成顶点序列,构成训练集,然后采用 skip-gram 算法,训练出低维稠密向量来表示顶点。这种思想与传统的协同过滤相比有两个比较明显的特点:
序列保留了时序信息
内容覆盖率提升,相关性略降低
在 graph 中主要存在两种关系,homophily 和 structural equivalence。所谓 homophily,即是在 graph 中紧密相连的邻域。具有这种关系的顶点之间,学习出来的向量应该接近或者相似。structural equivalence,就是指在图中具有相似作用的顶点,他们之间未必相邻,甚至可能相隔较远,都是所在邻域的中心顶点。满足这种关系的顶点之间,特征向量也应该接近或者相似。通常在现实世界的 graph 中,会同时存在这两种关系。可以表示如下结构:
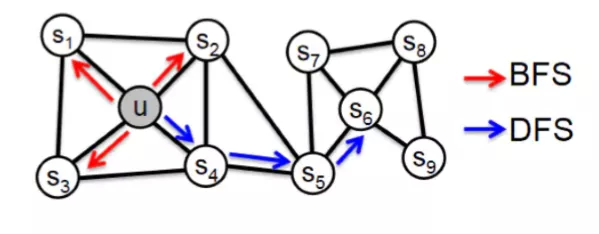
但是在不同的任务中需要关注的重点不同,可能有些任务需要关注网络 homophily,而有些任务比较关注网络的 structural equivalence,可能还有些任务两者兼而有之。那么关键的问题就是如何来描述节点与节点的共现关系。RandomWalk 是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
DeepWalk 从一个节点开始采样,跳到下一个节点的概率完全取决于邻边的权重, 无法灵活地捕捉这两种关系,在这两种关系中有所侧重。而实际上,对于这两种关系的偏好,可以通过不同的序列采样方式来实现。有两种极端的方式,一种是 Breadth-First Sampling ( BFS ),广度优先搜索,如图中红色箭头所示,从 u 出发做随机游走,但是每次都只采样顶点 u 的直接邻域,这样生成的序列通过无监督训练之后,特征向量表现出来的是 structural equivalence 特性。另外一种是 Depth-First Sampling ( DFS ),深度优先搜索,如图中蓝色箭头所示,从 u 出发越走越远,学习得到的特征向量反应的是图中的 homophily 关系。Node2vec 则额外定义了参数 p、q,用于控制回退、BFS、DFS 动作。
02 RelatedWork
1. Alibaba graph-embedding
首先我们介绍一篇阿里巴巴的图嵌入技术论文 “Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba ( kdd 2018 )”, 其流程如下图所示:
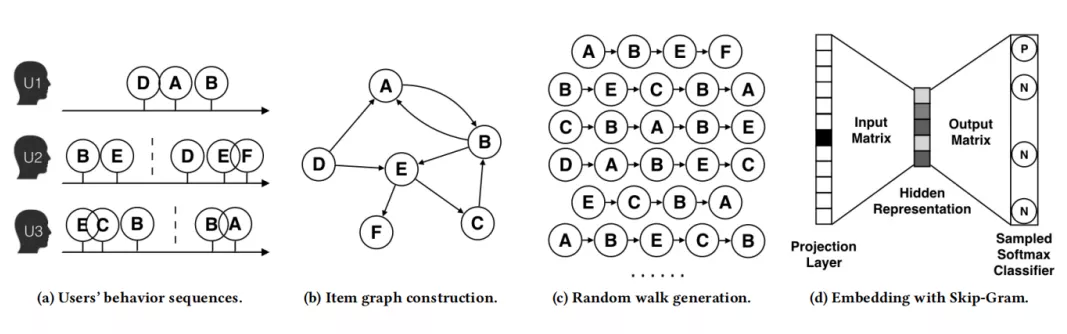
首先如图 (a),假设每个用户有不同的用户行为,每个用户浏览过不同的 item 按时间顺序排列。这里有一个业务上的技巧,就是把用户在某个时间窗内的连续行为作为一个 session,例如一个小时,如果超过时间窗,就划分为不同的 session。通常在短周期内访问的商品更具有相似性。每个 session 构成一个 sampled sequence,将所有 sampled sequence 构成有向图,图边表示该方向流过的次数,得到的 graph。
如图 (b),边权重记录了商品的出现次数。计算商品的转移概率,并根据转移概率做游走,生成商品序列,图 ©。最后通过 skip-gram 训练出 embedding。
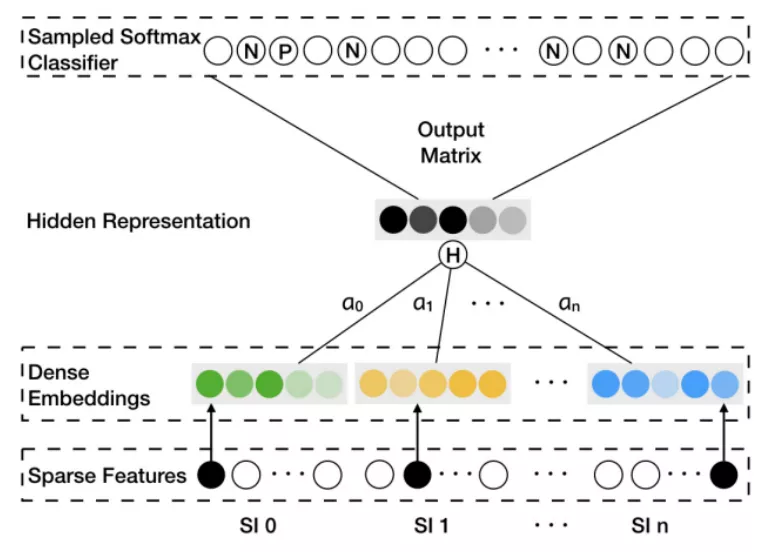
新商品没有用户行为,因此无法根据 Base Graph Embedding ( BGE ) 训练得出向量。为了解决物品的冷启动问题,阿里加上了物品的边信息 Side Information ( SI ),例如品牌,类别,商店等信息。SI 相似的商品,在向量空间中也应该接近。如下图所示:
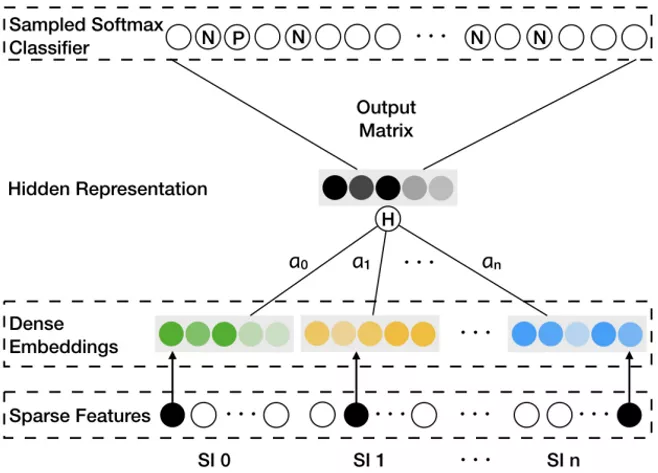
在最下面的 Sparse Features 中, SI0 表示商品本身的 one-hot 特征, SI1到 SIn表示 n 个边信息的 one-hot 特征,阿里采用了 13 种边信息特征。每个特征都索引到对应的 embedding 向量,得到第二层的 Dense Embeddings,然后将这 (n+1) 个向量做平均来表示这个商品,公式如下图。 其中,Wvs表示商品 v 的第 s 个边信息向量, Hv是隐向量。
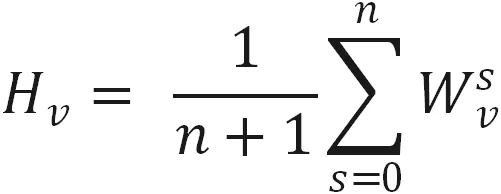
剩下的事情就和 BGE 相同了。这个做法叫 Graph Embedding with Side Information ( GES )。不同的边信息对于商品的向量可能会有不同的贡献,可以另外学习一个权重矩阵 A∈R|V|×(n+1),其中 |V| 表示商品集合 V 的数量,Aij表示第 i 个商品的第 j 个边信息权重。计算方法如下所示,从平均变成了加权求和。对权重取 e 的指数是为了保证所有边信息的权重大于 0。
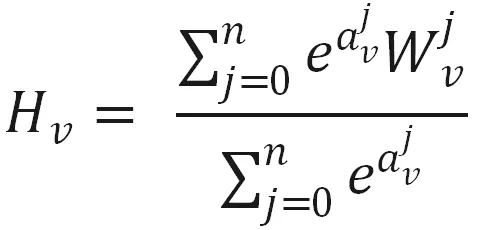
这个方法叫做 Enhanced Graph Embedding with Side Information ( EGES )。
2. Airbnb Word2Vec
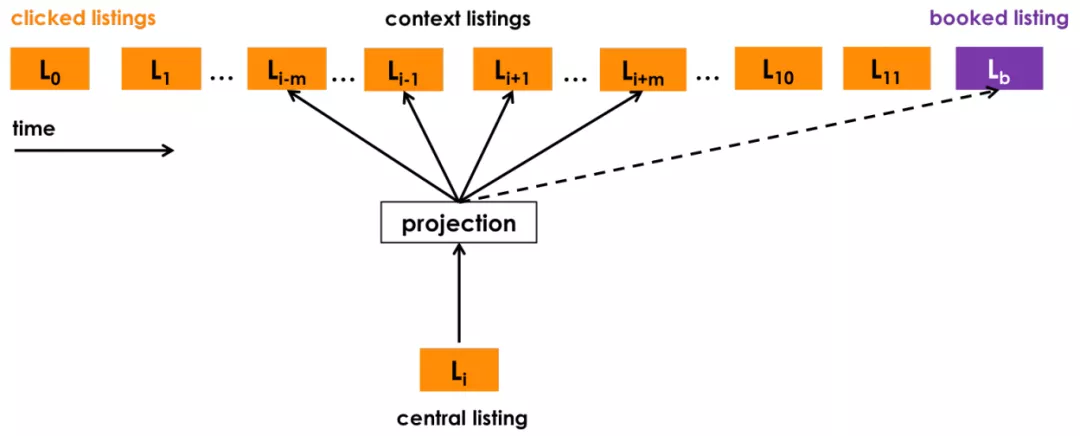
Airbnb 提出的冷启动和采样方式同样值得我们借鉴。首先,它同样是采用 session 进行分割的,而且明确指出 30mins 内的连续有序 sequences。同时提出了一个新的负采样策略,即从与当前 item 的同一个 cluster 里面采样负样本。而且 Airbnb 强化了付费行为的训练。点击序列中若有付费行为,则将这个 item 强制纳入该序列每个 item 的上下文窗口。
Airbnb 的冷启动策略很简单, 他并没有做 end2end 的学习属性的 embedding,而是直接把 new item 按主要属性 ( 房间数,地域,地段等等 ) 检索到最相似的 top3 个已知的 item,取 3 个 item 向量的平均值初始化 new item embedding。
更多详情,请参考:
Real-time Personalization using Embeddings for Search Ranking at Airbnb ( kdd 2018 )
03 Our Work
1. Mixed Graph-Vector model
在实践中,我们发现 CF 算法用于实时召回表现出的点击率较高,但召回存在上限,word2vec 算法表现出的泛化能力较好,可以让更多的内容得到召回,但也就带了泛化提升后的不确定性。两个召回策略是存在很多数据重叠,思考能否从精简算法的角度将两者合并起来,并各取所长。
具体来说,生成策略可以表示为下图:
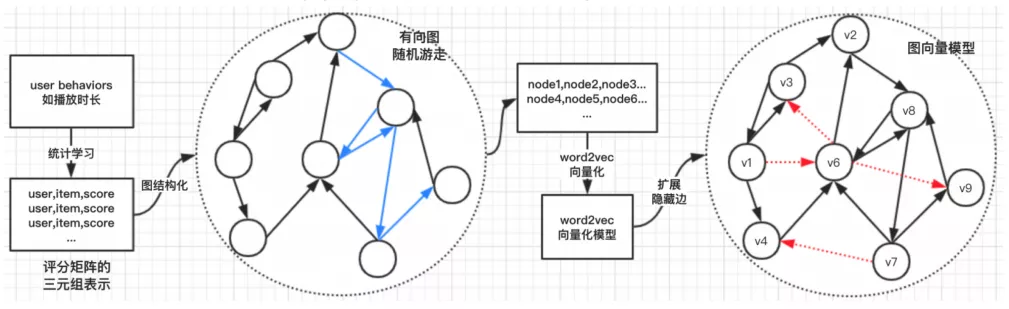
先利用之前 CF 算法的计算得到的内容相似度矩阵,取最相似的 topK 重建一个 item 间相似性关联图,采用 node2vec 算法,对上图进行随机游走生成序列,再使用 word2vec 完成 graph embedding。所以我们最终可以得到两个产物,一个 item similarity graph,即原来的协同过滤图。第二个则是由 graph embedding 产生的 item embedding。
在推荐时,先通过用户触摸过的 item seed 定位到图节点,如果 item 不在模型则终止。然后获取到图节点距离 1 的邻接点,如果已推荐则扩展到距离 2 的邻接点,此时会进行一个过滤操作,已推荐的不会再推。如果推荐数据不足则使用图节点向量进行 vector search,运用向量最简单的方法就是内积或者余弦相似度,寻找出 N 个与其最相似的 item 进行补充。所以最终的推荐结果,结合了 CF 与 Graph embedding 两者的优势。
2. Side Info Graph
上述的混合模型在性能上的提升仅来自其模型层面做的 graph embedding,即图中的节点为所有内容的边界,带来的覆盖提升也不会突破这个边界。因此对于冷启动内容的处理,我们将标签作为一种冷启动参数参与到模型训练,使得新内容可以被高级模型接受。
这里与阿里巴巴的 EGES 构建图的策略不同,我们沿用了协同过滤生成的 item 相似矩阵构建 graph。在 embedding 和权重的训练过程与 EGES 过程一样。训练完之后,我们可以获得特征的 embedding 和权重矩阵。这个方法主要是针对新内容的冷启动问题。
3. Two tower DSSM
对于 user 和 item 的匹配,我们采用的是双塔结构进行匹配,具体结构如下:
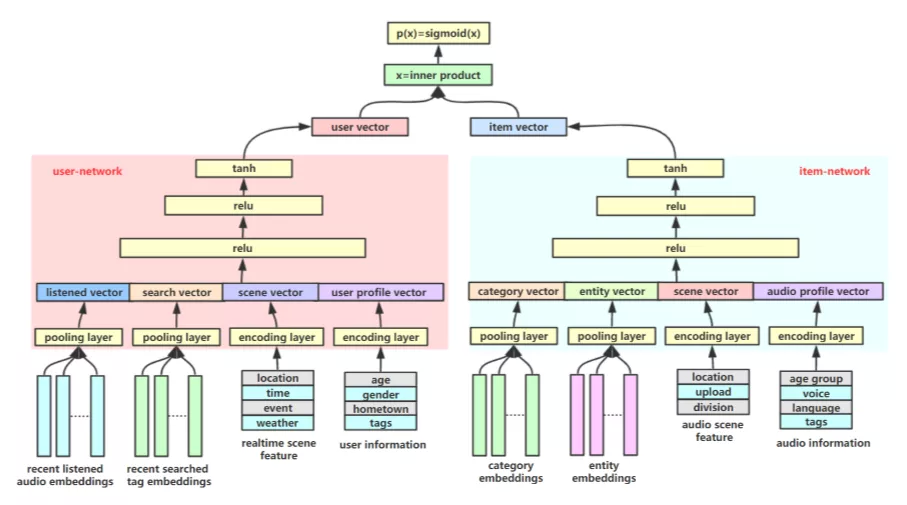
双塔结构很简单,左侧为 user 的行为特征和基本特征的 embedding,拼接后经过全连接层和激活层的特征融合和提取,形成 user vector。同理右侧的 item network,可以通过之前 GES 计算的 item 的 embedding,进行特征融合。最后将 user vector 和 item vector 进行内积和 sigmoid 函数输出匹配分数。
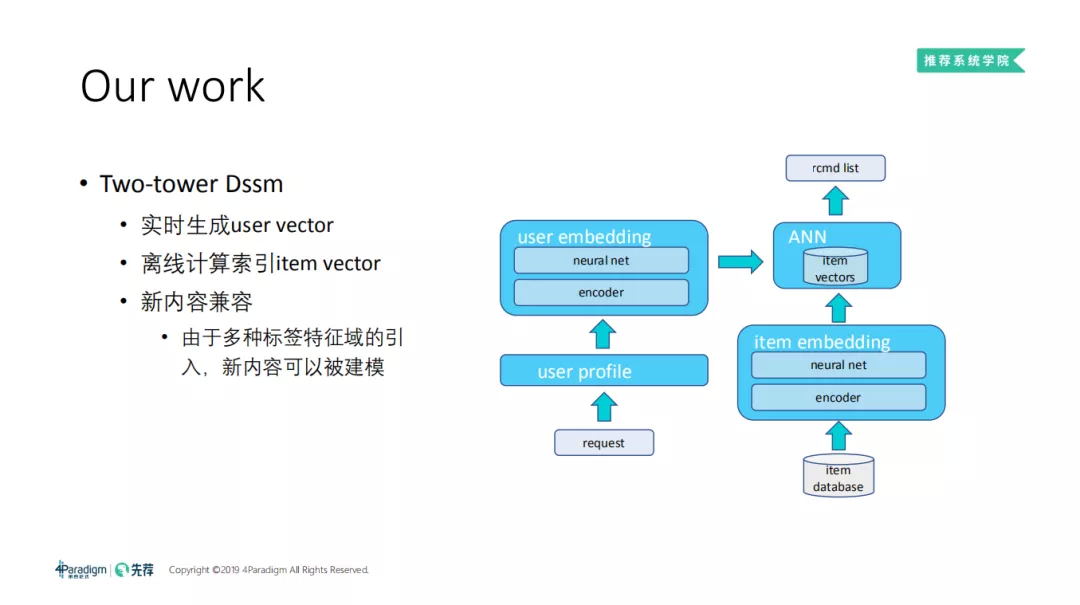
在工程上,由于用户行为的实时性,user vector 需要进行实时计算。但 item 侧的相关 embedding 可以通过查表得到,节省资源和计算时间。
4. Graph Restrict Vector Search
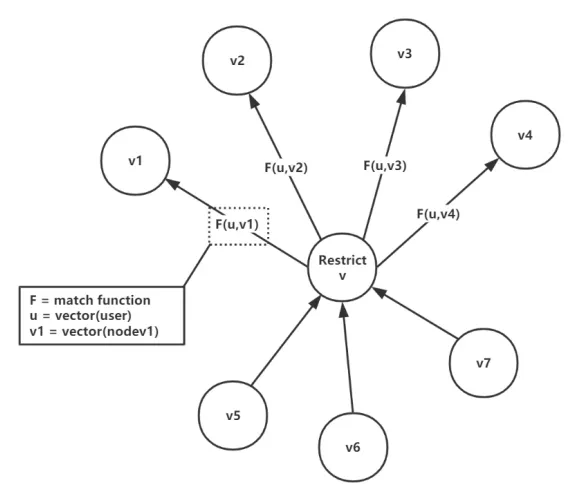
我们采用图来约束推荐的搜索范围。我们的新用户面临两种类型:
第一种是他可能有标签但是没有行为,或者行为很少。
第二种是完全没有行为,需要我们去探索。
我们主要利用图结构 item 之间的约束关系,比如说我们刚刚生成的用户向量,它的搜索结果仅限于用户刚刚点击或者浏览的 item 相邻的节点,而这些节点是我们通过大量的用户反馈所生成的边的关系。所以用图约束进行搜索,一方面可以加快计算速度,还可以进一步探索下一个曝光 item 的性质。
04
问答环节 ****
问:构建 session 过程中怎么过滤异常的数据?
答:这里我提出几个比较典型的异常情况:
异常点击 ( 时间太短的点击 )
异常 item ( 更新异常频繁的 item )
异常用户 ( 点击量异常多的 user )
问:Two tower 中的 user scene vector 和 item scene vector 的区别?
答:这两个是 user 和 item 的 feature field,可以根据需要进行整理。比如 user scene 包括 location、time、event、weather 等, item scene 包括 location、upload、division 等。
问:图不是全连通的,有多个子图,这种怎么样做 embedding 比较好?
答:如果图是隔断的,那直接当作两个图来做两次 embedding,因为很难有额外信息通过边把两个图联系起来。
今天的分享就到这里,谢谢大家。
作者介绍:
庄正中,前荔枝 FM 资深数据挖掘工程师
现于某互联网公司任资深推荐算法工程师,负责直播产品推荐系统的设计开发工作。曾在荔枝 FM 和酷狗音乐负责推荐算法和文本处理相关工作,擅长神经网络的数据建模。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论