
MeLU 全称为 Meta-Learned User Preference Estimator for Cold-Start Recommendation,旨在解决推荐中的冷启动问题,能够保证新用户只有少量行为的基础上训练出一个不过拟合并且效果不错的模型。除此之外 MeLU 还可以找到验证商品集,将这些验证商品集展示给新用户能帮助推荐系统更快速的识别出用户兴趣。
MAML
首先我们需要先介绍一下 MeLU 里面的核心算法:Model-Agnostic Meta-Learning,本文简称 MAML。该算法的目的是给定一个新任务,我们能通过该任务下极少量的样本达到一个不错的模型效果。因为样本比较少因此模型的训练迭代次数也会很少。这种能力对于模型来说很难,因为样本少的情况下很容易过拟合,让模型学习出只适用于这几个样本的一些无用的知识。另一方面人类却很擅长这方面,我们总是能找出新领域和自己已经积累的知识的联系,比如人类有语言大师,同时掌握很多门语言。他们在掌握一两门语言的基础上,会利用自己学习语言的经验比其他人更快的掌握新的语言。你可以理解为这些语言大师其实学到了某种元知识,适用于所有语言,而不是只适用于某一种语言。这种元知识帮助他们更快的学习新的语言。用模型的语言描述一下就是:对于新任务,在元知识的基础上经过几步 back propagation 就能达到比较低的 loss。
MAML 的伪代码如下。其实 MAML 就是在显式的建模上述描述的过程:让模型学习元知识,而不是只适用于某一个任务的知识。假设我们有 T 个任务,p(T)表示训练时从这些任务里面抽样的概率,实践中完全随机采样也可以当作一种概率分布。我们要学习的元知识就是θ。我们通过概率分布获得一些需要训练的任务。之后针对每个任务我们拿 K 个样本进行梯度下降,并拿这个梯度更新原始参数得到θ。之后把更新后的参数带入损失函数得到 loss,这个 loss 代表了θ经过一步迭代之后的模型效果(这里也可以进行多步迭代)。这个 loss 越小,表示θ越有效,即能在极少迭代的情况下达到一个不错的模型精度。这里完全和我们上面描述的元知识匹配。并且这里的梯度方向是所有任务梯度的加和,得到的元知识也是适用于所有任务的。注意到θ是通过$θ'$间接影响到最终的 loss。

实践中第 6 步和第 8 步用于计算梯度的样本是不相交的,第 6 步的样本用于减少具体任务的 loss,叫做 support set,同时这一步的参数更新称为 local update。第 8 步用于验证经过几步迭代后的效果,叫做 query set, 同时这一步的参数更新称为 global update。
当一个新的任务来的时候,只有 support set,我们通过 support set 进行训练后使用模型进行预测。可以看到 MAML 只储存适用全部任务的元知识,如果应用于某一个新任务是需要先在 support set 上基于元知识来训练的。
User preference estimator
在推荐领域,我们可以把学习不同用户的兴趣偏好当作不同的任务,这样就能从老用户丰富的行为里面学习到能快速迁移到新用户的元知识。用户兴趣识别模型如下,其中 input layer 就是用户侧和商品侧的泛化特征,比如用户年龄、用户邮编、内容体裁、内容的演员等等。注意这里是没有任何 uid、gid 等能唯一标记用户或者内容的特化特征的。然后 input layer 的原始特征经过 embedding 之后就 concat 起来经过几层 nn(决策层)输出最终的预测结果。上述模型的全部参数就是我们所需要的元知识。利用上面 MAML 的流程优化得到的θ能够保证对所有用户来说,进行几步迭代之后(给定几个用户行为过的商品进行训练), 得到的 loss 最低。
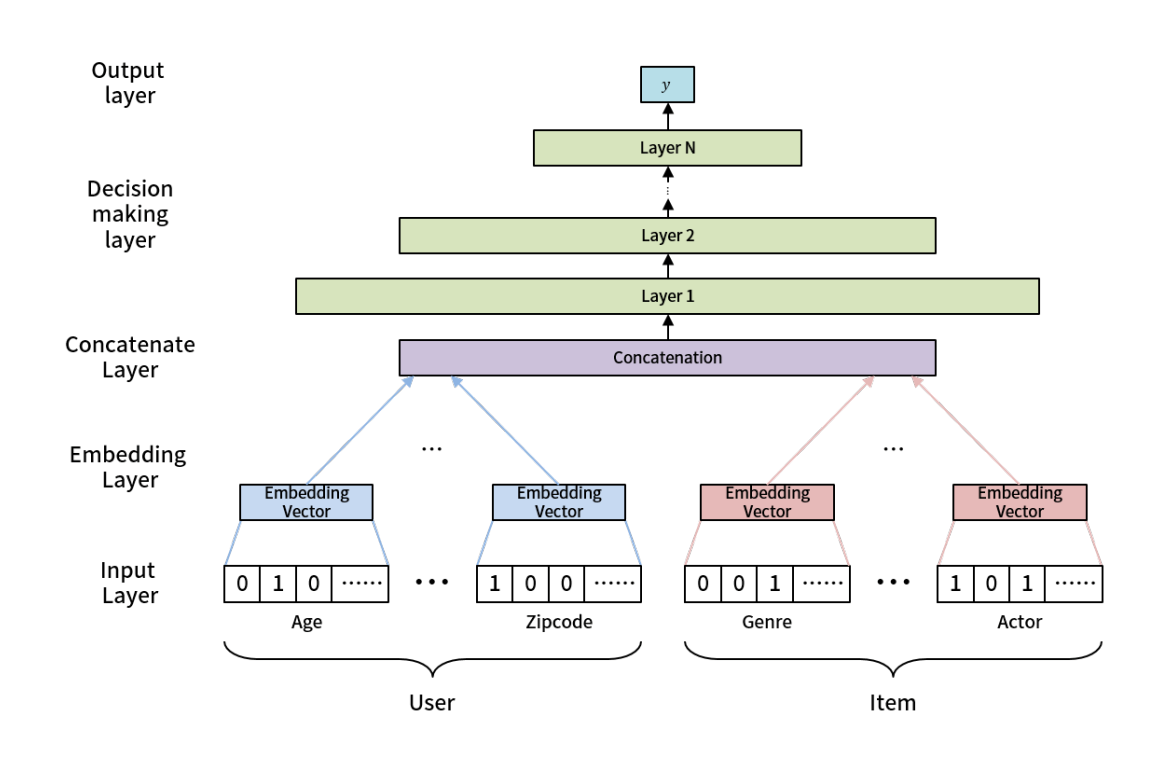
区分通用参数和个性化参数
MeLU 不仅仅是直接套用 MAML 的框架,而是做了如下的修改
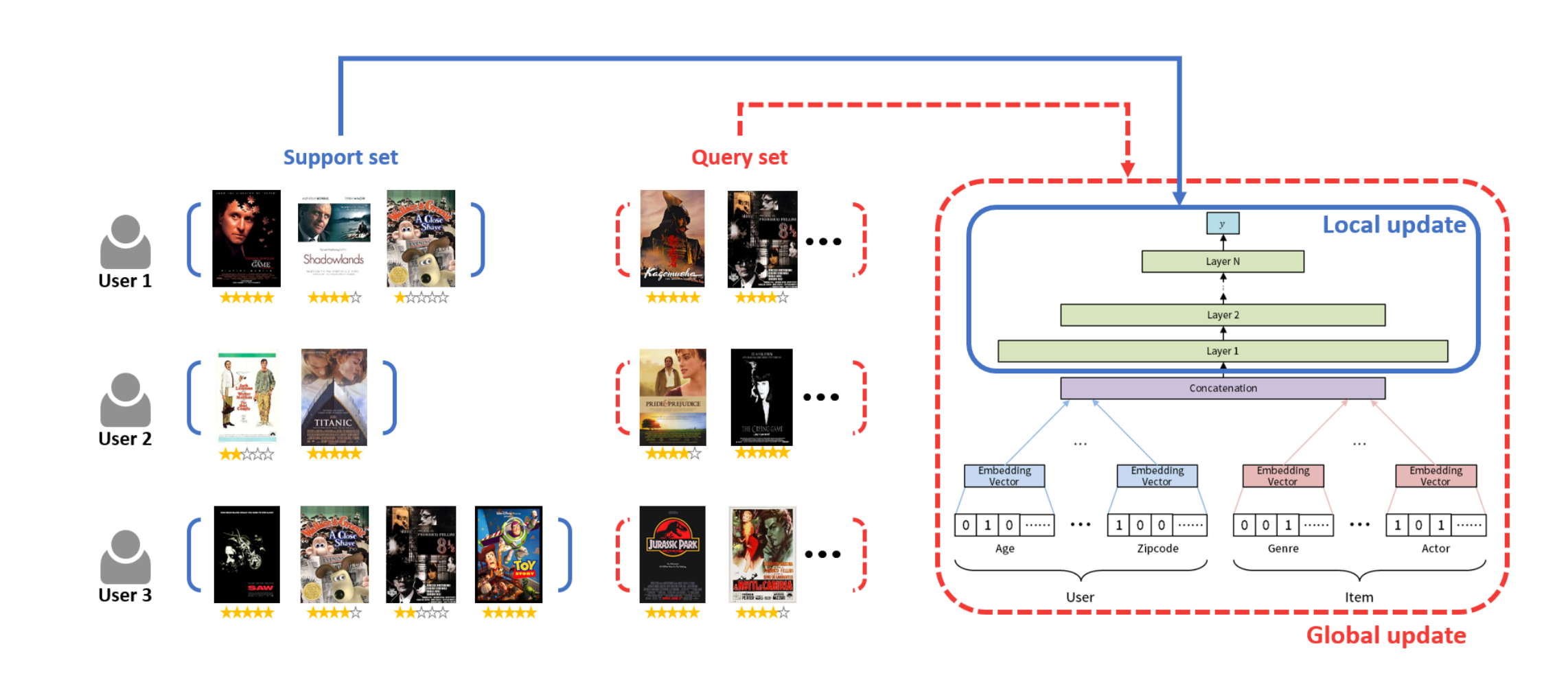
上图可以清晰的看到 local update 的时候不是更新全部参数的,而是只更新决策层,泛化特征的 emb 不会进行更新。也就是如果两个泛化特征相同的用户对同类的内容反馈不一样的时候,只调整决策层。泛化特征不负责特定用户的个性化兴趣。举个例子来说比如两个都是 18 岁的男性,第一个对恐怖电影有正反馈,第二个有负反馈,这两个样本对应的 embeding layer 是完全一样的,但是却有相反的 label,梯度回传的时候会导致泛化特征的 emb 学习的不稳定。因此需要把用户个性化的信息储存在决策层。所以整个的 MeLU 训练流程如下:

$θ_1$表示泛化特征的 embedding,$θ_2$表示决策层的参数
当我们需要预测新用户的时候,需要把新用户行为过的内容作为 support set 来 local update,之后拿训练好的模型进行预测。
验证商品集
MeLU 另一个作用是可以找出验证商品,验证商品可以理解为能帮助模型快速识别用户兴趣的商品。
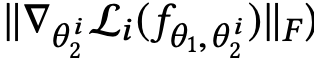
如果有一个商品在决策层的平均梯度越大,表示我们需要越费力气从元知识进行改变来适配这个用户对商品的反馈。也就表示这个商品对用户的个人兴趣影响越大并且不同于普适的规则。所以我们可以给新用户展示这些决策层平均梯度大的商品来帮助模型更快的识别用户的兴趣。但是我们还需要保证这个商品的典型性,也就是大部分人都行为过这个商品,保证这个商品不是小众而变的特殊。MeLU 最终会根据上面两个维度进行归一加权,找出符合要求的商品集。




