
这是 LinkedIn 公司在 Kafka Summit 中演讲整理的系列文章的第一篇。
Apache Kafka 在 LinkedIn 和其他公司中是作为各种数据管道和异步消息的后端。Netflix 和 Microsoft 公司作为 Kafka 的重量级使用者( Four Comma Club ,每天万亿级别的消息量),他们在 Kafka Summit 的分享也让人受益良多。
虽然 Kafka 有着极其稳定的架构,但是在每天万亿级别消息量的大规模下也会偶尔出现有趣的 bug。在本篇文章以及以后的几篇文章中会深度的分析过去几年在 LinkedIn 所遭遇的重大“危机故障”。在这里阐述 Kafka 的“重大”bug 产生的根本原因(多种 bug、不正常的客户端行为和监控不当多种因素相互作用导致的)是“后见之明”(有点像“马后炮”的意思),但分享出来可以给广大同仁以借鉴。本文将讲述如何探测、研究和修复这些问题,并总结出 Kafka 的一些特色以供将来消除或者减缓类似的 bug。
Offset Rewinds
Kafka 的 broker 分配到每条消息的偏移量都是单调增加的,它会追加到每个 topic 的分区日志。Kafka 的 consumer 分发消费任务(“fetch”请求)时会指定从哪个偏移位置(offset)开始消费。当一个“fetch”请求所指的偏移量(offset)越界,将会收到 OffsetOutOfRange 错误回复。然后,consumer 根据 auto.offset.reset 配置参数自动把偏移量重置为最小偏有效移量(the earliest valid offset)或者最新有效偏移量(the latest valid offset),见下图所标示。这种偏移量的重置对线上应用有重大影响——重置为最小偏移量会引起重复消费数据;重置为最新偏移量意味着有丢失消息数据的潜在可能(偏移量重置到下次“fetch”请求之间到达到消息)。
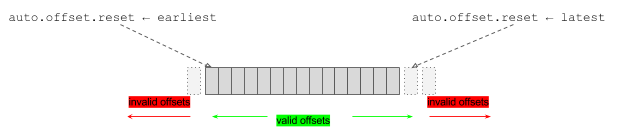
Kafka 的 consumer 会周期性地 checkpoint 每个 topic 分区消费者的偏移量(i.e. 位置信息)。当 consumer 因某种情况重启后,consumer 能从最后一次 checkpoint 重新消费。比如,如果 consumer 失败了,consumer 会从最近一次 checkpoint 重新消费;或者如果更多的分区加入到 topic,跨消费实例的分区分布发生变化,这时 consumer 也会从最近一次 checkpoint 重新消费。在 Kafka 0.8.2 中引入 consumer 的偏移量管理( offset management )。早在 2015 年早期,Kafka 的 consumer 偏移量管理仍然还是个新功能,而且作者也会偶尔出现偏移量重置的现象。解决这个难题是比较棘手的,也从而导致其他 bug 的修复,包含偏移量管理、日志压缩和监控。
如何发现Offset Rewinds
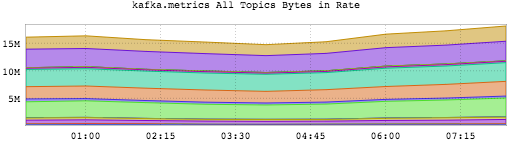
Kafka 的 broker 并未维护客户端的错误度量(比如,offset reset),但是有几个指标会出现,比如,当 consumer 失败后重置为最小偏移量时会有偏移量“倒回”。服务端最明显的指标是:消息输出量非常大,而相应的输入量并未增加,如下图所示:

客户端最明显的指标是 consumer 延迟突然增加,在这个故障中,作者注意到 Kafka 跨集群同步( mirror maker ,是 Kafka 内置的跨集群同步工具)延迟监控上出现“毛刺”。
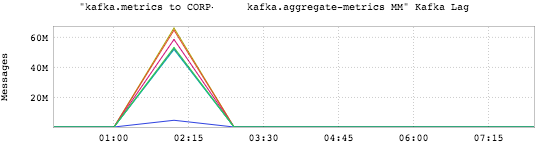
延迟监控有点棘手,因为并不是所有的延迟“毛刺”都会引起警报。延迟趋势监控是相当重要的,你可以使用 LinkedIn 提供的延迟监控服务 Burrow (Kafka 消费延迟监测)。
第一次“危机故障”
CRT (Change Request Tracker)[]是 LinkedIn 持续集成发布平台,用来监控构建和发布服务,并发出邮件。在七月初,许多开发者(包括作者在内)反应收到重复的 CRT 邮件。与之相关的原因是包含发布事件的 Kafka topic 复制管道出现偏移量重置。
偏移量重置(offset reset)的一个典型的原因是未知的 leader 选举。当一个分区的 leader broker 失败,而其它复制副本也并未跟上,那就会发生这种情况。一个未同步的复制不得不接管 leader,同时导致日志截断。这意味着,正在读取日志尾部的 consumer 发生突然越界的错误。最好的做法是监控集群的未知 leader 选举率。但是在七月份这次故障中并未看到任何未知 leader 选举。
然而,consumer 的日志很明显的显示好几个分区有偏移量重置的情况。为了 debug 这个故障,我们需要懂得 consumer 偏移量管理是如何工作的。
Consumer 偏移量管理
Consumer 通过发送 OffsetCommitRequest 请求到指定 broker(偏移量管理者)提交偏移量。这个请求中包含一系列分区以及在这些分区中的消费位置(偏移量)。偏移量管理者会追加键值(key-value)形式的消息到一个指定的 topic(__consumer_offsets)。key 是由 consumerGroup-topic-partition 组成的,而 value 是偏移量,如下图所示。内存中也会维护一份最近的记录,为了在指定 key 的情况下能快速的给出 OffsetFetchRequests 而不用扫描全部偏移量 topic 日志。如果偏移量管理者因某种原因失败,新的 broker 将会成为偏移量管理者并且通过扫描偏移量 topic 来重新生成偏移量缓存。在下面的例子中,mirror-maker 消费 topic(PageViewEvent)到分区 0 的位置 321。
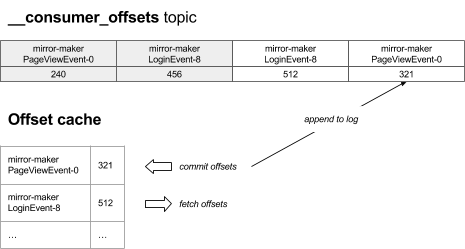
偏移量 topic 是会日志压缩的,这意味着旧的冗余项最终会被清除。因为有些瞬时 consumer(比如,控制台 consumer)来来回回的,偏移量管理者会周期地扫描偏移量缓存,并移除死亡 consumer group 的偏移量项(比如,在配置指定周期内未进行更新)。这个过程也会在偏移量 topic 日志中追加一个公告来通知下次进行日志压缩的时候就从持久化的日志中移除。

调试故障
下面是偏移量重置时间周围的消费日志摘要:
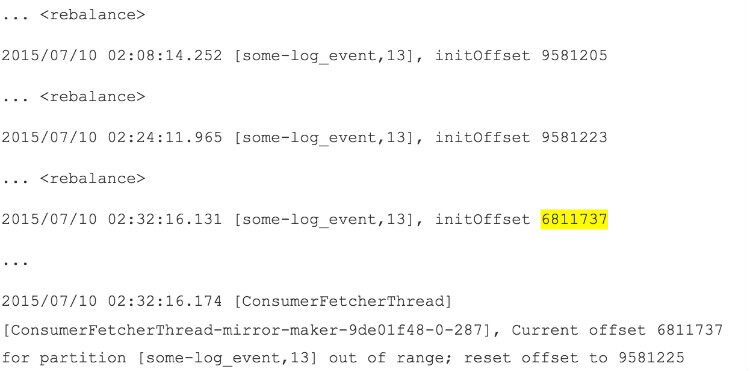

在偏移量发生重置之前出现了几个 consumer 的 rebalance。Rebalance 一般发生在 consumer 离开或者加入 consumer group,或者新的 topic 或分区变成可以消费的情况。在 rebalance 期间,consumer 依次经过:停止消费数据;提交它们的偏移量;跨 group 重新分配分区;从新所属的分区获取偏移量;重新消费数据。在前面的打印日志中,initOffset 所在行会指出 consumer 将会从哪个位置开始消费。前两个 rebalance 从有效的偏移量开始重新消费,而第三个 rebalance 试图从明显是旧偏移量消费。当调试这些故障时,最好能在消费者控制台使用以下命令 dump 偏移量的 topic(因为日志压缩会随时发生):

记住在配置中设置 exclude.internal.topics 值为 false,因为偏移量 topic 是一个内部的 topic。
进一步深入的研究下偏移量 topic 的 dump 发生了什么:
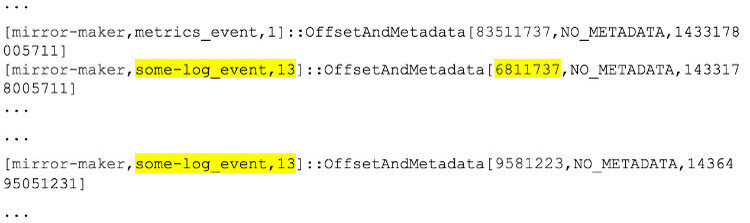
无效偏移量(6811737)被 checkpoint 是在这次故障一个月之前。但是最近也有有效的 checkpoint 返回了偏移量。那为什么偏移量管理者会返回一个很长时间的旧偏移量?
偏移量管理者打印的日志清晰的指出:在加载偏移量到偏移量缓存中时,偏移量管理者发生了移动,随之发生了问题。

这是偏移量 topic 消息的格式发生改变时的一个 bug。在缓存中加入过期的偏移量之后,偏移量管理者会短暂移动。这也是为什么偏移量获取会返回过期的偏移量。
重复邮件的缘由
在这个故障中,mirror maker 设置的 auto.offset.reset 为“latest”, 按理来说应该不会出现重复消费数据。所以需要进一步的看看包含发布事件的 topic 到底发生了什么?

虽然这个 topic 展示了雷同的错误——i.e.,在早期的 rebalance 之后偏移量“fetch”到当前的偏移量,而最近的 rebalance 之后偏移量“fetch”到了过期的偏移量,虽然过期的偏移量是一个月之前的,但它仍然是有效的。最开始大家对这个问题比较吃惊,因为作者在 Kafka 集群设置的 topic 保留时间为四天。最后发现,发布记录的 topic 数据量太小,没有触发基于数据量大小的阈值。基于时间的保留依赖于最后的修改时间,但是在小数据量 topic 时无效。
偏移量管理 bug 最近修复了。
第二次故障
这次的故障发生在数据发布管道中:Hadoop 的push-jobs 发送数据到CORP 环境的(比如,非生产环境)Kafka 中,然后镜像到PROD 来为线上服务来消费。作者收到了延迟警报,mirror maker 因为某种原因卡住了。许多重复的消息发送到下游,也就意味着出现偏移量“倒回”。
consumer 打印的日志显示偏移量“fetch”返回 -1 (这意味着没有偏移量被 checkpoint)。换句话说,偏移量管理者丢失了以前的一些 checkpoint 偏移量:

偏移量管理者打印的日志提供了一些帮助:

偏移量管理者发生移动,偏移量缓存加载了 17 分钟。偏移量 topic 是非常小的,正常只需要几秒钟就可以处理完。这很明显的说明日志压缩过程因为某种原因发生中断,造成未 checkpoint 的偏移量 topic 一直在增长。这种情况发生不会导致已经 checkpoint 的偏移量信息丢失。在加载过程中偏移量“fetch”收到错误代码意味着加载过程有问题,consumer 只是重试偏移量“fetch”。在这个故障中,偏移量“fetch”实际返回的意思是“没有有效的偏移被找到”。
这证明了日志压缩过程时间太久,有些旧偏移量仍然在偏移量 topic 中。偏移量缓存加载过程会把这些旧偏移量加载进缓存。然而它自己认为在日志里有更多最近的偏移量最终会覆盖旧偏移量项,所以没啥问题。问题就在这里,在长时间的偏移量加载中旧偏移量的清除任务被杀掉,并且在清除掉旧偏移量项后会在日志尾部添加通知。偏移量加载过程继续加载最近的偏移量到缓存中,但是只有当它发现追加的通知才会移除这些旧偏移量。这也旧解释了为什么偏移量总是丢失。
结论
基于 Kafka 的偏移量管理是 Kafka consumer 默认的偏移量管理机制。很好的理解偏移量管理是如何工作的对使用 Kafka 是非常有用的。
简单总结如下:
Consumer 延迟警报对监控 consumer 健康和探测偏移量“倒回”是非常必要的。Burrow 会很好的帮助你做好每个 consumer 的延迟监控服务。激活监控日志压缩度量也是非常重要的,特别是 max-dirty-ratio。其它的度量 offset-cache-size, commit-rate 和 group-count sensors 也会对偏移量管理有帮助。当出现偏移量“倒回”,就要对 topic(__consumer_offsets)进行 dump。你也需要检查未知 leader 选举以及偏移量管理者和 consumer 打印日志。
查看英文原文: Kafkaesque Days at LinkedIn – Part 1
译者信息:侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny 分享相关技术文章。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论