

Uber Eats 为了更好地服务庞大的用户群,将图学习理论应用到了 Uber 的美食推荐上,并开发了图像学习技术,基于此给用户推荐更符合他们需求的餐厅和菜肴。这种技术方法提高了平台上对食物和餐厅推荐的质量及相关性。本文基于其应用实践,向我们介绍了其中的算法实现逻辑,及搜索和推荐系统模型。
Uber Eats 应用程序为全球 36 个国家、500 多个城市的 32 万多家餐厅合作伙伴提供服务。为了使用户使用更加方便顺畅并拥有更佳的用户体验,我们会向用户推荐他们可能喜欢的菜肴、餐馆和菜系。为此,我们之前开发了机器学习模型使查询更智能,并在 Uber Eats 搜索和推荐系统中进行了多目标优化。
已有的研究理论[1]已经证明了图学习方法在推荐任务中的有效性。我们把这个理论应用到了 Uber 的美食推荐上,并开发了图像学习技术,基于此我们会给用户推荐最有可能吸引他们的食物。这种技术方法提高了我们平台上对食物和餐厅推荐的质量及与用户需求的相关性。
图学习简介
为了更好地理解我们是如何让 Uber Eats 推荐算法变得更准确的,了解图学习的基本原理很有必要。通过学习节点的表示形式,许多机器学习任务可以在图形数据结构上执行。我们从图中学习的表示法可以对图的结构属性进行编码,可以方便地用于上述机器学习任务中。例如,为了在我们的 Uber Eats 模型中表示一个食客,在提供订单建议的时候,我们不仅使用订单历史记录,而且还会将食品与过去的 Uber Eats 订单进行相关分析,并参考相似用户的一些意见见解。
具体来说,为了获得具有这些属性的表示,我们为图中的每个节点(在本例中是用户、餐馆和食品)计算一个向量,使节点向量相似性近似于图中两个节点之间的连接强度。我们的目标是找到一个从节点映射到其向量表示(一个编码函数)的节点,使图中结构相似的节点具有相似的表示。
对于 Uber Eats 的用户场景,我们选择了基于图神经网络(GNN)的方法来获得编码函数。虽然这种方法最初是在 20 世纪 90 年代末和 21 世纪初提出的[2,3],但最近被研究界广泛采用,用于各种任务实现[6,7,8],并已被证明对推荐问题[1]特别有效。
GNNs 的基本思想是使用神经网络,通过将相邻节点的表示以一定深度的递归方式聚集,得到节点的表示,如下图 1 所示:
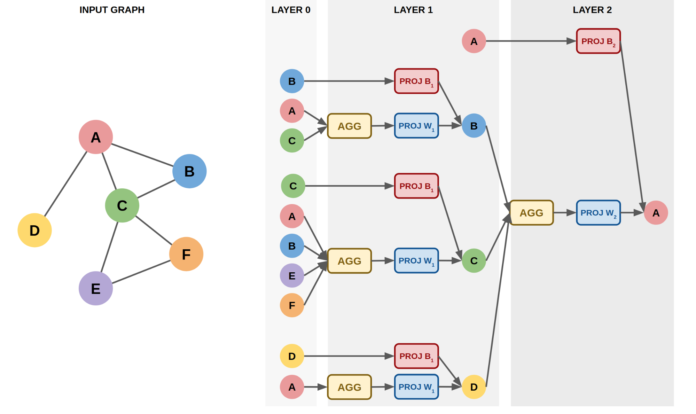
图 1:图神经网络(图右)从一个输入图(图左)中获得节点 A 的描述
假设我们将递归深度限制为 2,以获得图 1 中节点 A 的表示形式,我们首先从 A 节点开始执行一个广度优先搜索,接下来,两步后我们获得节点的 x 属性,这些属性通过聚合/池功能被聚合,例如,通过取平均值并通过矩阵乘法与学习权矩阵 W 投影(图中为 PROJ W),得到距 A 一跳距离处节点的邻域表示。
这些相邻表示会结合信息节点本身所预测的矩阵乘法学习权重矩阵 B( PROJ B 在图 1 中),这种结合形成一个 h 表示距离 A 较远的节点,这种表示被递归地聚合和投影,以获得节点 A 的表示,在递归的每一步,使用新的矩阵 W 和 B (图 1 中第一层为 W1 和 B1,第二层为 W2 和 B2)。以这种方式获得表征的主要优势是:它可以捕获节点的属性和其邻域结构信息、聚合节点、节点连接的信息。如图 2 所示,如下:
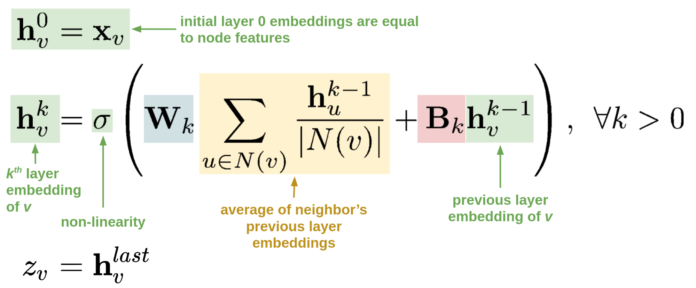
图 2:这些方程表示图 1 所示的计算图
然后,我们使用节点表示来预测两个节点之间存在连接的概率,并优化损失,使图中实际连接的两个节点的概率最大化,使断开节点的概率最小化。
GNN 只需要固定数量的参数,而这些参数不依赖于图的大小,这使得学习可扩展到大型图,特别是如果在获取特定节点的表示时,将相邻节点采样为一定的固定数量。此外,还可以通过新添加节点的基本特征和连接来对其进行表示。GNNs 的这些功能支持 Uber Eats 上的大规模推荐,即便每天增加新用户、餐厅和菜肴也可应对自如。
Uber 的菜品和餐厅推荐图学习应用
Uber Eats 应用中有几个推荐页面,如下图 3 所示:
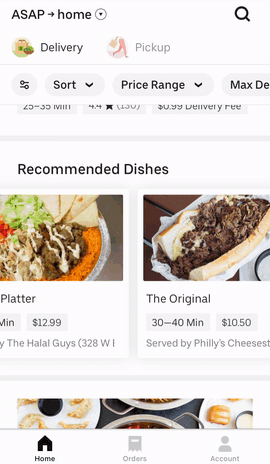
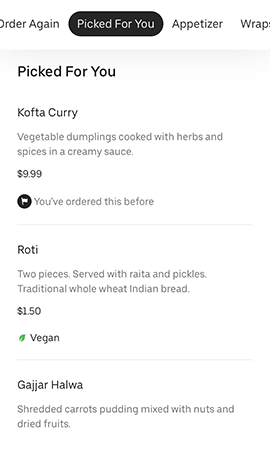
图 3:通过历史订单和之前指定的用户偏好,Uber Eats UI 可以为用户提供丰富的选择
在主页上,我们根据用户偏好为餐厅和菜品生成轮播推荐。在浏览餐馆的菜单时,我们还会生成餐馆内的个性化推荐,以适应用户的口味。这些建议是由根据历史订单和用户偏好训练的推荐系统给出的。
Uber Eats 推荐系统可以分为两大组成部分:候选商品生成和个性化排名。
候选商品生成部分以可伸缩的方式生成相关的候选对象,换句话说,就是生成可推荐的菜肴和餐馆。我们需要使这个阶段具有高度的可伸缩性,以便能够对平台上数量巨大且不断增长的菜肴和餐馆选项进行预过滤。预过滤可以基于地理位置等因素,所以我们不会向超出其送货范围的用户推荐餐厅。候选菜品和餐厅还需要与特定用户相关,以确保我们不会过滤掉他们想要的菜品。
系统的第二个组成部分是进行个性化的推荐,它是一个成熟的 ML 模型,基于附加的上下文信息对预过滤的候选菜品和餐厅进行排名,例如,时间、用户打开应用时的当前位置等。 该模型可以学习捕获循环订单模式,包括在一周的特定日期订购特定类型的食物,也可以在午餐和晚餐订购不同类型的菜肴。
为了使用 GNN 改进 Uber Eats 的推荐功能,我们创建两个由两部分构成的图: 第一个图将用户和菜肴表示为节点,节点的边缘表示用户点某道菜的次数, 第二个图将用户和餐馆表示为节点,边表示用户从特定餐馆订购的次数。
我们选择GraphSAGE[4]作为建模起点,因为它具有强大的可伸缩性,这是 GNN 的一种特殊形式,其中聚合函数是经过投影后的最大池或平均池。在这个 GNN 中,节点信息和邻居信息的组合是通过拼接得到的。此外,GraphSAGE 还采用了一种采样策略,将采样节点的数量限制在与我们想要获得其表示的节点之间的一跳和两跳距离,使得将学习扩展到具有数十亿个节点的图数据成为可能,并提供了更好的建议方案。
为了将 GraphSAGE 应用于我们的二部图,我们必须用几种方式先做一些修改。首先,由于每个节点类型可能具有不同的特性,我们需要向 GNN 添加一个额外的投影层。这一层根据输入节点的类型(用户、餐馆或菜肴)将输入特性投射到相同大小的向量中。例如, 菜肴可以通过嵌入一个词来表示,嵌入的词来源于菜肴的描述或与之相关的图像的特征, 餐厅可以有与菜单和菜肴相关的基本功能,它们的功能大小不同,但投影层需要将它们投射到相同大小的空间中。
此外,GraphSAGE 只考虑图形与二进制边缘,但在我们的例子中,需要对边缘进行加权,以包含关于用户从一家餐厅或某道菜订购的次数和用户对某道菜的评级的信息,因为这些是非常重要的信号。对于这个问题,我们引入了一些新的概念来增加边缘的权重。最重要的变化是采用了铰链损失,相对于用户的排名这种损失比使用二进制边缘更适合项目。
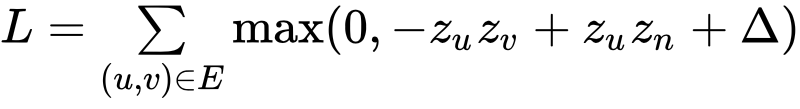
假设用户 u 至少一次点了菜 v,它们之间存在加权边。如果我们想要预测这双节点的分数,比我们预测相同的节点 u 和一个随机选择的不相关的节点 n 的分数要高,他们得分之间的差异应该大于利润率。
这种损失的问题在于,高权重和低权重的边缘是可以互换处理的,考虑到用户一次点的菜和用户十次点的菜的区别,这种做法效果并不好。为此,我们引入了损失的低排名积极因素概念。
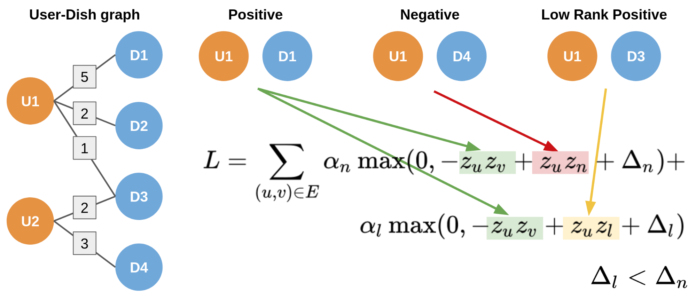
图 4:Uber Eats 推荐系统使用最大的利润率损失和低排名积极因素
上面的图 4 显示了我们的系统如何利用低排名的积极因素来修正我们的损失。给定一条正边<u, v>,低排名的积极因素是一条边<u, l>,其中节点 u 相同,但节点 l 与 v 不同,且<u,l>边的权重比在<u,n>边的权重小。我们在损失中增加了第二部分,以确保权重高的边的排名高于权重低的边的排名,而权重低的边有一个边距Δl,我们将边距设置为负样本的边距Δn。损失的两个部分都有一个乘数α,一个控制损失的负样本部分和损失的低排名积极因素部分相对重要性的超参数。
最后,我们还使用了聚合和采样函数中的权值。
一旦我们使用训练过的 GNN 获得节点的表示,我们就可以使用节点表示之间的距离来近似它们之间的相似性。具体来说,我们将用户和物品的点积和余弦相似度添加到我们的菜品和餐厅推荐系统中作为特征,并对它们进行离线和在线测试,以确定它们的准确性。
为了评估这种嵌入对于我们的推荐任务有多大用处,我们对模型进行了为期四个月的历史数据训练,到一个特定的分割日期才结束。然后,我们测试了推荐菜肴和餐厅的模型性能,测试数据使用的是来自拆分日期后 10 天的订单数据。具体来说,我们计算了用户与城市中所有菜式和餐馆嵌入的余弦相似度,并计算了用户点的菜式和餐馆的等级。在实验中,我们观察到,与现有的生产模型相比,在平均倒数排名、精确度和NDCG等指标上,该系统性能提高了约 20%。
通过图学习的训练,提高了嵌入式系统的性能,我们也就放心将它们加入到 Uber Eats 推荐系统的个性化排名模型中了。当我们使用图学习嵌入相似性特征训练个性化排名模型时,我们发现与现有的产品化基线模型相比,AUC提高了 12%,这也就改进了系统对用户的推荐体验。
此外,通过分析该特征对预测结果的影响,我们发现图数据学习相似特征是推荐模型中最具影响力的特征。在我们的系统中,与任何现有的特性相比,嵌入图学习可以捕获更多的信息,如下图 5 所示:
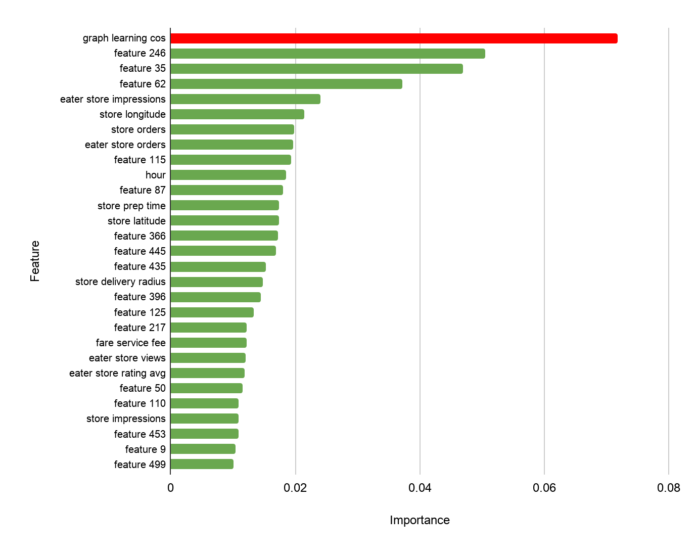
图 5:我们的新版图学习功能被证明是所有其他实现功能中最有价值的,它决定了我们的 Uber Eats 和餐厅推荐系统的质量和相关性
根据离线的测试结果,我们觉得在在线实验中推出新模型应该也会有很好的效果。我们在旧金山进行了A/B测试,发现与之前的产品模型相比,使用图形学习功能后,用户的参与度和点击率有了很大的提高,这表明我们的模型预测并推荐的菜肴对 Uber Eats 的用户很有吸引力。
数据和训练管道
在我们明确了图数据学习对推荐系统的积极影响后,我们就建立了一个可扩展的数据管道,既可以训练模型,又可以在实时生产环境中进行预测。
我们为每个城市训练独立的模型,因为它们的图形只是松散地连接在一起。
为了实现这一目标,我们使用了过去几个月的匿名、聚合的订单数据,并设计了一个四步数据管道来将数据转换成networkx图形格式,这是训练我们的模型所必需的。该管道还提取了原始订单数据中没有直接提供的聚合特性,比如用户订购菜肴的总次数,这决定了图的边缘权重。
此外,管道还能够为较早的时间帧创建图形,这些图形可用于离线分析。整个管道如图 6 所示:
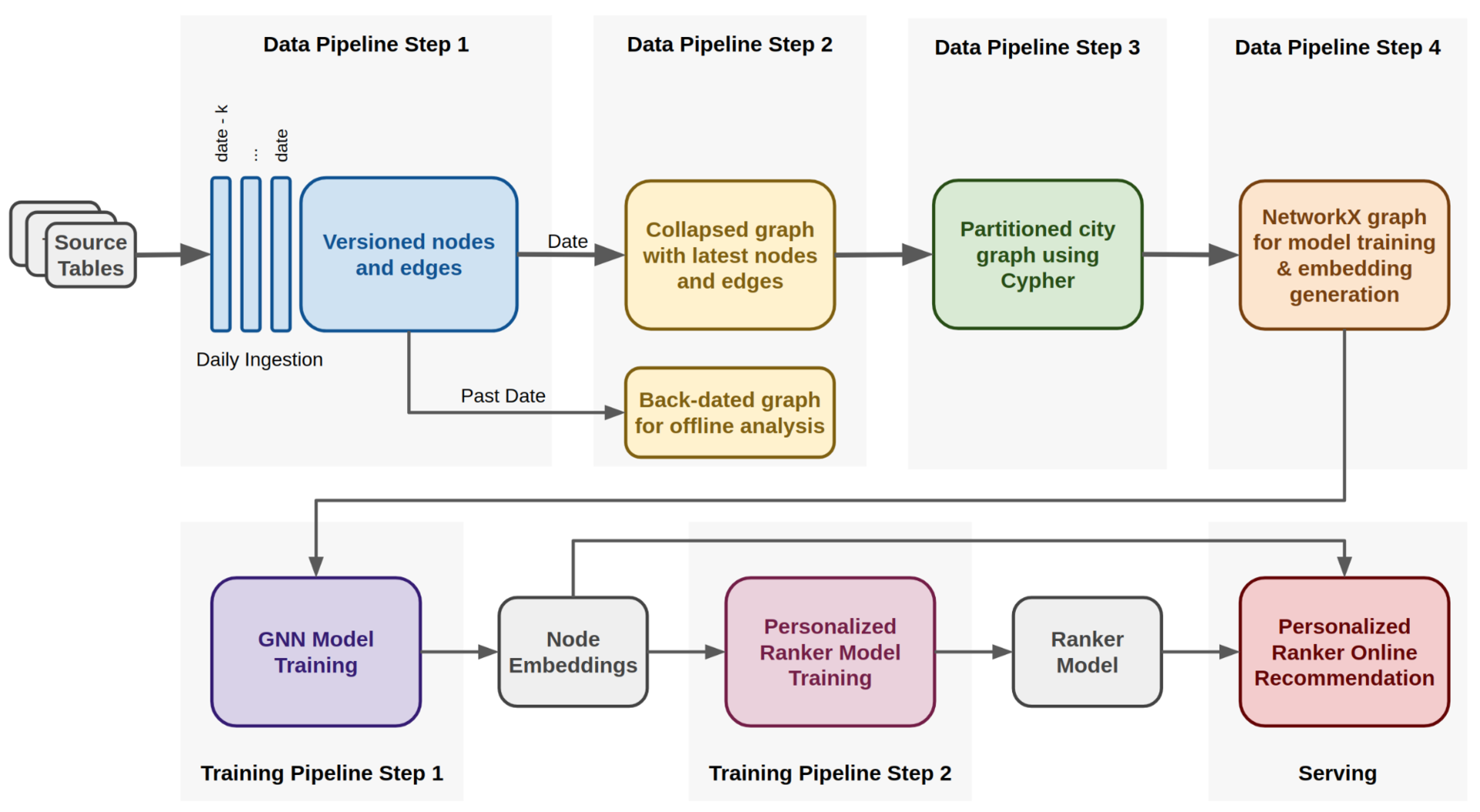
图 6:我们构建了一个数据管道(最上面一行)和训练管道(最底下一行),它可以帮助我们使用 GNN embeddings 训练 Uber Eats 推荐系统,以改进系统的菜品和餐厅推荐方案。
在管道的第一步中,多个作业从 Apache Hive 表中提取数据,分别将其作为包含节点和边缘信息的 Parquet 文件导入 HDFS。每个节点和边缘都具有由时间戳进行版本控制的属性,这是构建回溯图所必需的。
在第二步中,我们保留每个节点和给定日期的 edge 的最新属性,并使用 Cypher 格式将它们存储在 HDFS 中。在训练生产模型时,指定的日期是当前的日期,即便如果为了获得回溯的图形而指定了过去的日期,流程也是相同的。
第三步是在 Apache Spark 执行引擎中使用 Cypher 查询语言生成按城市分区的多个图。
最后,在第四步中,我们将城市图转换为 networkx 图格式,该格式在模型训练和嵌入生成过程中使用,作为 TensorFlow 过程实现,并在 GPU 上运行。
生成的嵌入项存储在一个查找表中,当应用程序打开并发出请求建议时,排名模型可以从中检索它们。
可视化学习嵌入
用示例可以很好地展示我们的图形学习算法所学习到的内容,下面示例展示了我们系统中用户的描述是如何随时间变化的。
假设我们在 Uber Eats 上有一个新用户,他点了一份鸡肉 Tandoori 和一份蔬菜 Biryani(两者都是印度菜),此时我们就可以获得该用户的一种描述。
同一位用户后来还点了其他几道菜,包括:半份 Pizza、Cobb Salad、半打 Dozen Donuts、麻婆豆腐(一道中国菜)、鸡肉 Tikka Masala 和 Garlic Naan(三道印度菜)。除了可以获得这些订单之外,我们还可以得到关于该用户的一个描述,并计算这两个描述与来自不同烹饪类型的最受欢迎的菜肴之间的距离,然后使用视差中引入的显式轴技术显示在下面的图7中:
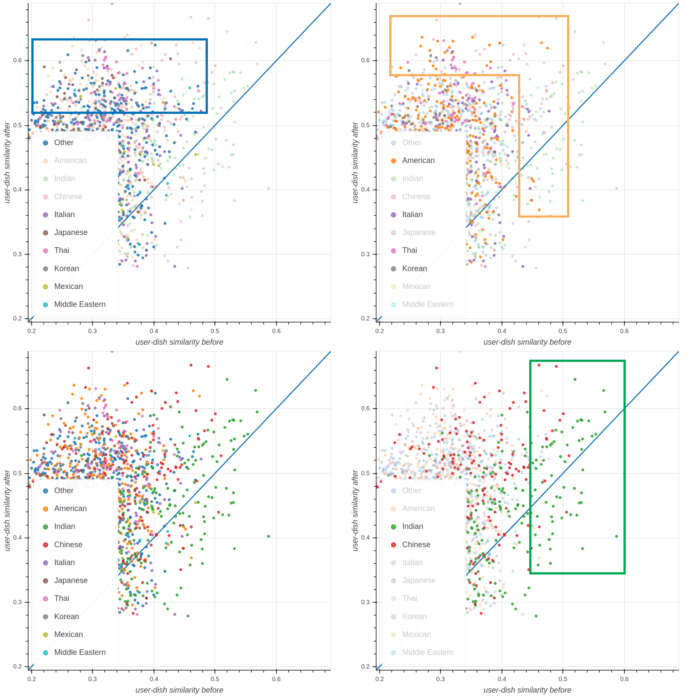
图 7:我们比较了一个假想的用户在点餐之前和之后的表现,并将他们与来自不同菜系的流行菜肴进行了比较。四个坐标突出了属于四个不同菜系子集的菜肴。x 轴表示在点其他菜之前,某道菜与用户描述的相似程度,而 y 轴表示在点其他菜之后,某道菜与用户描述的相似程度。
在图 7 的左下角部分,出现了清晰的模式。 第一个模式在右下角的绿色方框中高亮显示:
由于最初的订单都是印度菜,所以在追加订单之前最接近用户描述的菜品几乎都是印度菜(绿点), 但也有一些中国菜在 x 轴上排名靠前,表明了这些烹饪类型之间的二级相关性(点了很多印度菜的用户也点了中国菜)。中国菜在 y 轴上的排名也相当靠前,这表明点麻婆豆腐对模型产生了影响,使其推荐了更多的中国菜。
在图 7 的右上角部分,橙色框中突出显示了第二个模式:用户选择了美国、意大利、泰国和韩国菜,显示了在用户订购了其他菜式之后,系统是如何更准确描述用户的。这不仅是由于点了 Pizza、Doughnuts 和 Cobb Salad,也是由于对中国菜建议的增加带来的二阶效应,因为点中国菜的用户也更有可能点泰国菜和韩国菜。
最后,在图像的左上部分, 第三个模式在蓝色框中突出显示:与这两种用户描述最接近的前三名之外的所有菜系,在它们后续订单中,它们的相似度都大幅增加,这表明该模型意识到,这个特定的用户可能希望获得新的烹饪建议。
未来的发展方向
如前所述,图形学习不仅是一个引人注目的研究方向,而且已经成为大规模部署推荐系统的一个不错的选择。
虽然图数据学习已经在推荐质量和相关性方面带来了显著的改进,但是我们仍然需要做更多的工作来增强我们部署的系统。特别是,我们正在探索合并我们的菜肴和餐厅推荐任务的方法,这两个任务目前是分开的,因为之前我们认为它们可以相互促进。随着时间的推移,我们计划从两个二部图转移到一个包含所有实体节点的图。这将需要对丢失和聚合函数进行额外的优化才能正常工作,但是我们相信它将为利用公共信息的两个任务提供更多有价值的信息。
我们想要解决的另一个缺陷是,即使在数据稀缺的情况下,也要向用户推荐合适的商品,比如在 Uber Eats 平台刚刚推出的城市。我们正在通过使用元图学习[5]进行这方面的研究,并取得了令人兴奋的结果。
假如你对 Uber 如何利用人工智能进行个性化推荐点餐建议感兴趣,通过 Uber Eats 的食物挖掘系列文章,可以更加深入的了解我们的 Uber Eats 推荐系统:
致谢
非常感谢 Jimin Jia、Alex Danilychev、Long Tao、Santosh Golecha、Nathan Barrebbi、Xiaoting Yin、Jan Pedersen、Ramit Hora 对系统研究的贡献。
参考文献
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton and Jure Leskovec: Graph Convolutional Neural Networks for Web-Scale Recommender Systems. KDD 2018.
Alessandro Sperduti and Antonina Starita: Supervised neural networks for the classification of structures. IEEE Transactions on Neural Networks, 1997.
Marco Gori, Gabriele Monfardini and Franco Scarselli: A new model for learning in graph domains. IJCNN 2005.
William L. Hamilton, Rex Ying and Jure Leskovec: Inductive Representation Learning on Large Graphs. NIPS 2017.
Joey Bose, Ankit Jain, Piero Molino and William L. Hamilton: Meta-Graph: Few shot Link Prediction via Meta-Learning. Graph Representation Learning Workshop @ NeurIPS 2019.
Thomas N. Kipf and Max Welling: Semi Supervised Classification With Graph Convolutional Networks. ICLR 2017.
Bing Yu, Haoteng Yin and Zhanxing Zhu: Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. IJCAI 2018.
X. Geng, Y. Li, L. Wang, L. Zhang, Q. Yang, J. Ye, and Y. Liu, Spatiotemporal multi-graph convolution network for ride-hailing demand forecasting. AAAI 2019.
原文链接:
Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations

InfoQ主编

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论