
1. 导读
POI 是“Point of interest”的缩写,中文可以翻译为“兴趣点”。在地图上,一个 POI 可以是一栋房子、一个商铺、一个公交站、一个湖泊、一条道路等。在地图搜索场景,POI 是检索对象,等同于网页搜索中的网页。在地图客户端上,用户选中一个 POI,会有一个悬浮的气球指向这个 POI。
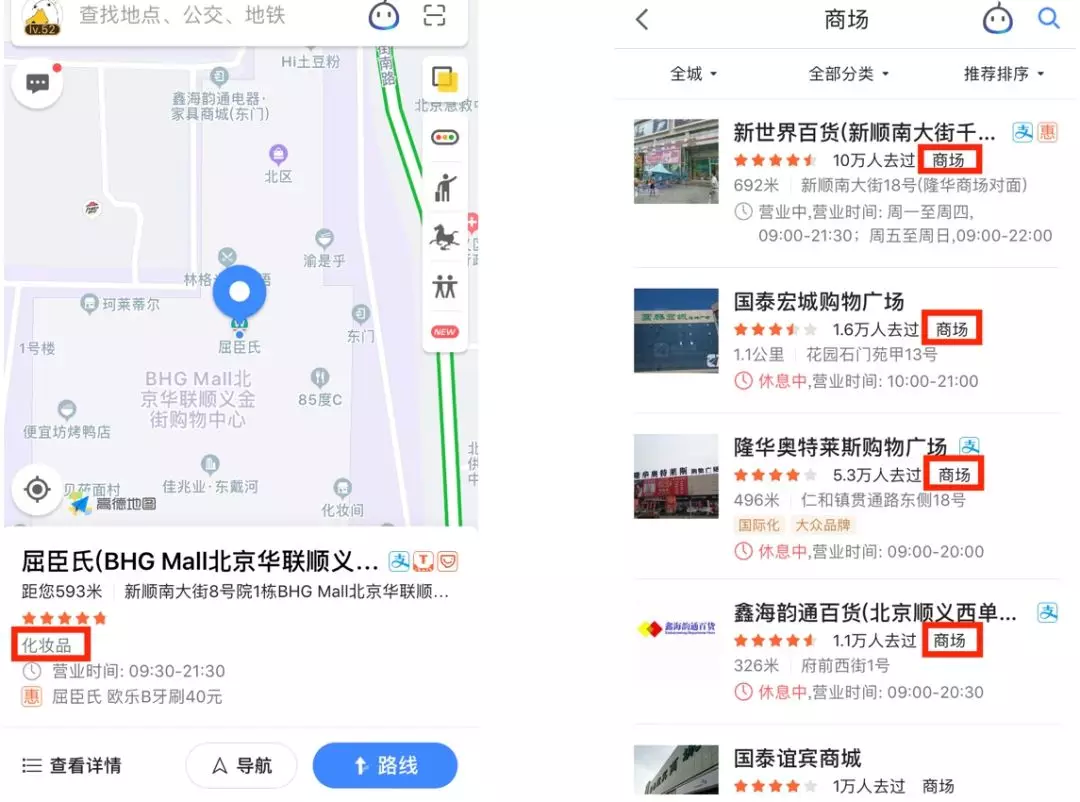
如上图左边,这家商场内的屈臣氏是一个 POI;而所谓类别标签,就是在类别维度对 POI 属性的一种概括,比如,屈臣氏的类别标签化妆品,而屈臣氏所坐落的凯德 mall,类别标签是商场;右侧则是商场 query 搜索召回的一系列 POI,都具有和 query 相匹配的类别属性。
上图也展示了类别标签的两种主要使用场景:为用户提供丰富信息和支持决策,一方面在前端为用户显示更丰富的信息,另一方面支持搜索的类别搜索需求,主要是在地图场景 query 和 POI 双方都具有丰富的多义表达,通过传统的文本匹配引擎或者简单的同义词泛化是难以达到目的的,因此挖掘标签作为召回和排序依据。
我们的类目体系建设主要依据以下几点:
用户实际的 query 表达,主要为了支持用户的搜索需求;
真实世界的客观类目分布,以及 pm 对该分布的认知;
不同标签间的从属、并列关系。
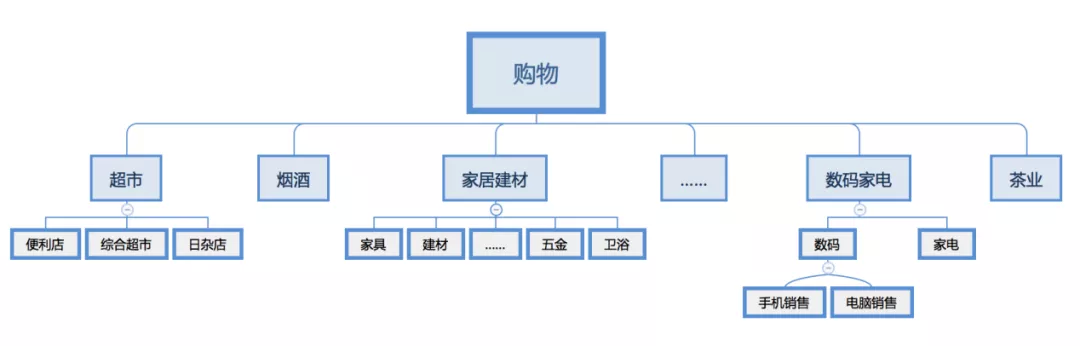
最终每个大类将构建一个多层的多叉树体系,比如购物类别的划分:
2. 类别标签建设的难点
我们的目标是打标,就是将 POI 映射到上面类目树体系的各个节点上,很显然这是一个分类问题,但又不是一个单纯的分类问题:
多标签问题:屈臣氏打上化妆品的标签,是一个一对一的映射;而部分 POI,可能同时具有多个标签,比如汤泉良子,可以洗浴、按摩、足疗;xx 家具店,打上家具店标签同时,必须打上其父节点家居建材标签。整体上,这是一个多标签问题,而不是多分类问题;
文本相关问题:大多数的 POI 具有比较直观的文本标题,比如小牛电动车、海尔专卖店、东英茗茶、熙妍精衣、新生贵族,通过名称文本分析,可以预测出比较正确的结果。另一方面,又不是纯文本问题,比如苹果专卖,仅从文本无法确认是一个手机店,还是一个水果店;还有一些表达,比如老五批发,低频表达或者不含类别信息,则需要引入其他特征来进行解决;
综合性问题:算法可能解决主要问题,但现实世界的复杂,通过单纯的算法是难以完全覆盖的,比如酒吧中夜店和清吧的区分,三甲医院、汽车 4S 店的打标,低频品牌的识别等,通过受限的样本和特征无法尽数解决,但又无法置之不理。
此外,应用方对于标签的准召和产出速率也有较高的要求:打标准确率低,则可能导致用户搜索时召回错误 POI;覆盖率低,则可能导致用户期待的结果被漏掉;而待建设的大分类有 20+,同时每个大分类有数十个子标签,大小标签总量上千。则必须使用高速高效、准召均有保障的方法进行打标,才能有效落地收益。
综上,我们要解决的类别标签打标的主要问题,是一个多标签分类问题,主要使用文本进行识别,但有必要引入其他非文本特征或手段,才能比较完满的解决。
3. 技术方案
3.1 整体方案设计
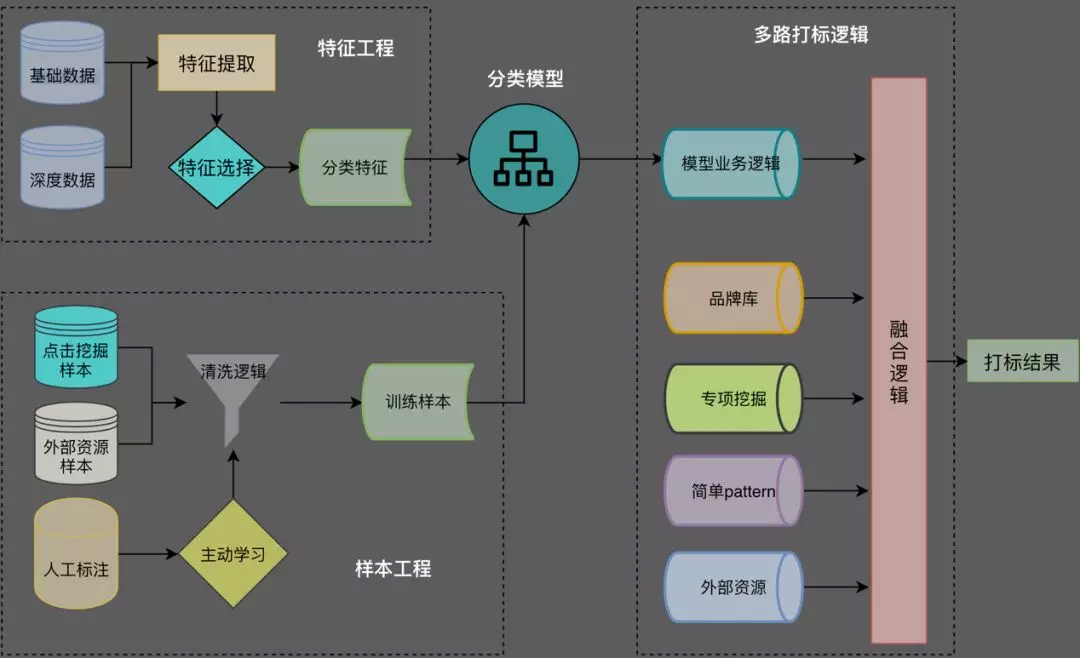
如图,为了高效完成打标,我们设计了主要的流程模块,具体描述如下:
特征工程:文本特征解决最主要的打标问题,但同时地图场景下 POI 文本偏短,长尾分布广泛,具有较多的低频文本或者完全不含类目信息的低频品牌等,而评论、简介等长文本描述往往偏于高频,而难点在于解决低频。因此特征设计上,尽可能使用一些通用特征,比如 POI 名称、typecode(生产方维护的另一套分类体系)、来源类别(数据提供方的原始零件类别)、品牌等通用特征;对于高频专有特征或数据,一般不在通用模型中进行识别;
样本工程:样本的挖掘和清洗、以及模型的设计也是旨在解决通用性的打标问题,POI 表达的多样性,而同时标签数量极多,导致需要的样本量也极大,标注成本较高时,必须考虑人工标注之外的样本来源;
分类模型:单纯的文本分类模型,不能解决非文本的问题,同时多标签的问题,也不能单纯使用多分类模型来解决;我们设计了多种贴合业务的模型改造工作;
多路融合:分类模型能解决主要的问题,但不是全部问题。在地图场景下,总有些算法之外的待解问题,如 5A 景点、三甲医院,以及各类品牌,模型难以尽数处理。我们设计多路打标,如品牌库对品牌效果进行兜底,引入外部资源批量解决非算法问题,引入专项挖掘解决非通用的打标类别等等……总体上对模型之外的问题引入外部知识辅助进行打标,从整体上收敛问题。
后面将重点介绍业务的主要难点,在样本和模型上的主要工作。
3.2 样本工程
3.2.1 样本来源 &清洗
样本方面,经过一些实验论证,标签数量多,每个标签需要的样本量大,人工标注几乎不可能满足要求,因此考虑主要使用点击日志和一些现成的外部资源:
点击日志数据量大,能够循环产生,同时反映了用户最直接的意图;缺点是含有的噪声大,同时用户点击往往偏向于高频,低频表达较为稀缺;
外部资源数据量小,但多样性较好,能够弥补点击数据在低频表达不足的问题。
通过引入这两方面的样本,我们很快得到了数百万的原始样本,这么大量级的样本,即使清洗依然是一个及其巨大的工作量,为了高效地清洗样本,我们设计了结合主动学习的两级模式:
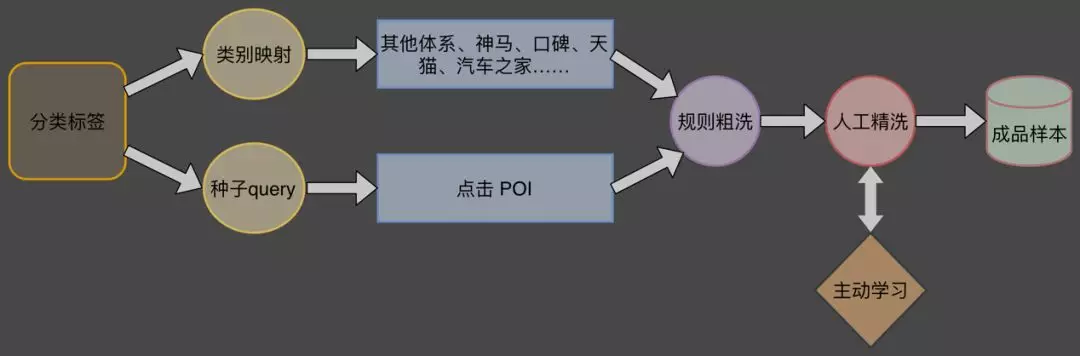
在两方面的初始样本引入后:
首先对数据进行抽样清洗,并将清洗过程抽象为业务规则,进行全局清洗和迭代;
当整体系统且明显的噪声趋于收敛后,我们通过对剩余数据进行划分,每次抽取部分数据建模,对另一部分数据进行识别,然后对识别不好的一部分数据进行人工标注;如此反复迭代多轮。
通过一种类似主动学习的方式,使人工标注的价值最大化,避免低信息量重复样本的反复标注造成人力浪费。下面具体介绍点击样本的挖掘思路。
3.2.2 点击样本挖掘
搜索点击日志凝聚了无数用户的需求与智慧,大多数的搜索业务都能从中挖掘最原始的训练样本。具体到当前的挖掘业务,首先要解决的问题是样本表达形式的不一致问题。具体描述为:
如下图,要挖掘内衣的样本集,人工定义了该标签的映射的 query 集合 seed query,再通过这个 query 集合去召回对应的 click 样本,就可以直接作为标签内衣的样本。
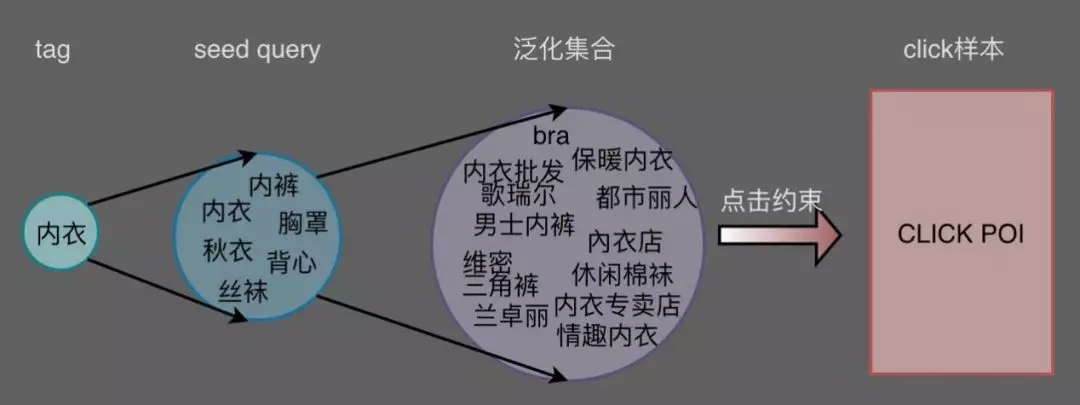
在实际操作中,我们增加了 seed query 到泛化集合的映射,即由人工定义的高频 query 集合泛化到一个更大的同义集合后,再由同义集合进行 click 样本的召回,其出发点在于:
高频的 query 主要点击集中于高频的样本,要解决的问题难点在于低频表达的挖掘,因此对 query 进行从高频到低频的泛化,以期通过低频 query 召回低频的样本表达,比如丝袜到休闲棉袜,内衣到维密、都市丽人等方面的扩展。
query 泛化过程:
query 的泛化,需要通过高频集合获得近义的低频表达,同时又要保证不会过度的语义扩散,导致泛化集合偏离了标签原本的语义。我们主要尝试了以下方案:
word2vec:通过对点击或外部语料学习 word 粒度的向量表达,对 query 中的多个 word 进行 maxpooling,得到 query 的向量表达,再通过 query 向量去全量集合中搜索向量距离近的其他 query。该方法的主要问题是通过 word 粒度的 embedding 刻画的 query 表达,在泛化过程中不太受控,容易引入大量的噪声,清洗难度大,同时存在显著 case 的漏召。
同义词:该方法召回非常受限,且得到的 query 不一定符合用户的自然表达。
Session 上下文:地图场景的 session 普遍较短,召回受限且语义有偏离,准召均不高。
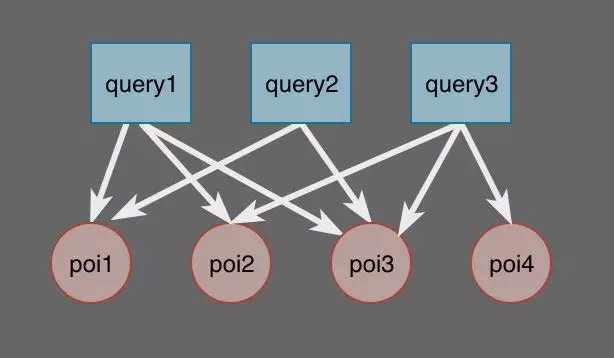
推荐方法:继续考虑点击日志的挖掘,将各个 query 比作 user,点击的 POI 作为 item,考虑引入推荐的思想进行相似 query 挖掘——即点击相同或相似 POI 的 query 具有某种程度上的相似性,而 query 和 POI 点击关系天然构成一个社交网络,由此参考了两种基于图的推荐方式:
SimRank,通过 query 与 POI 间的点击关系形成二部图,两个节点间的相似度由他们共同关联的其他所有点加权平均得到,通过反复迭代多轮后,相似度趋于稳定,得到两两 query 间相似度;
a、b 表示图中的两个节点,定义自相关度为 1,即 s(a, a)=1,I(a)、I(b)表示与 ab 相连的节点集合,对于不同的 a、b,其相似度描述为:
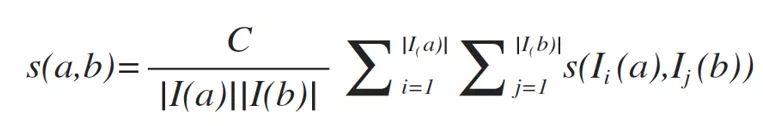
DeepWalk,是一种学习网络中节点的表示的新的方法,是把 language modeling 的方法用在了网络结构上,从而使用深度学习方式学习网络中节点间的关系表示。类似 simrank 方式,通过 query 与 POI 间的点击关系构成点击网络,在点击网络上进行随机游走,通过对游走片段的学习,得到 query 的向量表达,再通过向量表达计算 query 的相似召回。
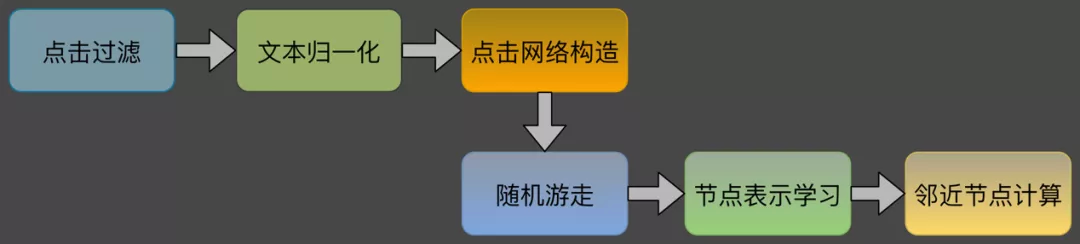
推荐方法的两种方案中,simrank 计算量极大,在小数据量上实验经过了较长时间的迭代,而数千万点击数据计算资源和计算时间都将变得极大,成本上不合算;而 DeepWalk 随机游走方式在实际测试中取得了较好的效果:

比如,原始 query 为涂料,泛化得到其子分类、品牌等,ETC 可以得到一些地方性的命名表达。
不同于将 query 分词后学习其 word 粒度 embedding 表达,DeepWalk 在这里直接学习整个 query,即 Sentence 的表达,避免了将 query 分词为多个 word 再 pooling 过程中语义偏移;而且直接 query 粒度的表示学习,得到的挖掘结果更加符合线上的实际表达,便于我们后续召回点击 POI 样本的操作;同时粗粒度的学习对网络节点间社会关系会有更优的保留。
整体上,通过 query 泛化步骤,样本集合的低频表达比例明显提升。
3.3 模型设计与迭代
使用分类的方式解决打标问题,是业类相似场景的通用做法。具体到业务角度,我们需要模型解决的打标数据范畴主要分为四类:
高频后缀识别
低频后缀识别
品牌识别
非文本识别(typecode、来源类别等)
前三类可以使用纯文本分类模型,但非文本特征无法直接用文本模型进行整合;同时,样本数据在前期具有噪声大、分布不均衡的特点,都需要兼顾。
3.3.1 分层多分类
前期使用多分类模型解决分类问题,对于每一个非叶节点构建一个多分类器,从根部开始构建,分到最后一级输出为叶节点。其特点是直观,和标签体系比较匹配。
这种方式有比较明显的缺陷:方案结构复杂不稳定,维护难,样本组织相当繁杂;上级分类模型的错漏,将层层影响下级的分类效果。
3.3.2 每个标签二分类
业务前期受限于优化前的搜索效果,样本集有一定量的噪声,同时体系在调研期间也会时常迭代,不断优化,需要一个解释性强、兼容变化,同时又能直接支持多标签的模型。
因此,我们尝试了对每个标签训练二分类模型,待识别的 POI 经过所有的二分类模型预测后结果合并使用,再进行后续的业务逻辑建设,该方式较好地解决了业务多标签的场景,避免同一 POI 多个标签间的冲突。
在样本方面,使用 ovr 方式组织样本,样本比例可调整(正负例比例、负例来源比例等),兼容了业务样本不均衡问题。
3.3.3 统一模型
单标签的二分类模型具有良好的解释性,以及每个标签建模带来的灵活性,很好匹配了业务的前期需求,迅速推进标签效果落地,线上恶劣 case 大量收敛,同时较原来的人工专家规则方式,召回明显提升的同时,效率也提升十倍以上。
前期为了短平快地推进业务,使用简单二分类模型迅速解决了主要问题,随着搜索效果的不断提升,业务上也有了更高的质量要求,而 LR 二分类模型依然存在一些问题:
使用词袋特征,维度膨胀
特征选择造成低频特征损失
泛化性能一般,需要大量建设业务规则
独立建模,标签间的关系识别不充分(父子、共现、互斥)
负样本大量降采样,浪费样本
模型数量极多,维护成本高
为了达到更好的效果,深度模型的升级有了必要,深度文本分类,常用的模型有 cnn、rnn 以及基于 attention 的各种模型,而 attention 模型主要解决的是长文本的深层语义理解问题,我们业务场景需要解决的是短文本简单语义的泛化问题,同时考虑到需要和非文本特征结合,以及分类效率方面的考虑,我们选择 textCNN 模型。
而 textCNN 是一个纯文本的多分类模型,不能解决多标签情况,也无法兼容非文本特征,同时样本不均衡问题也导致小样本类别学习不充分。为了匹配实际的业务,我们对原始的 textCNN 进行了业务改造,如图:
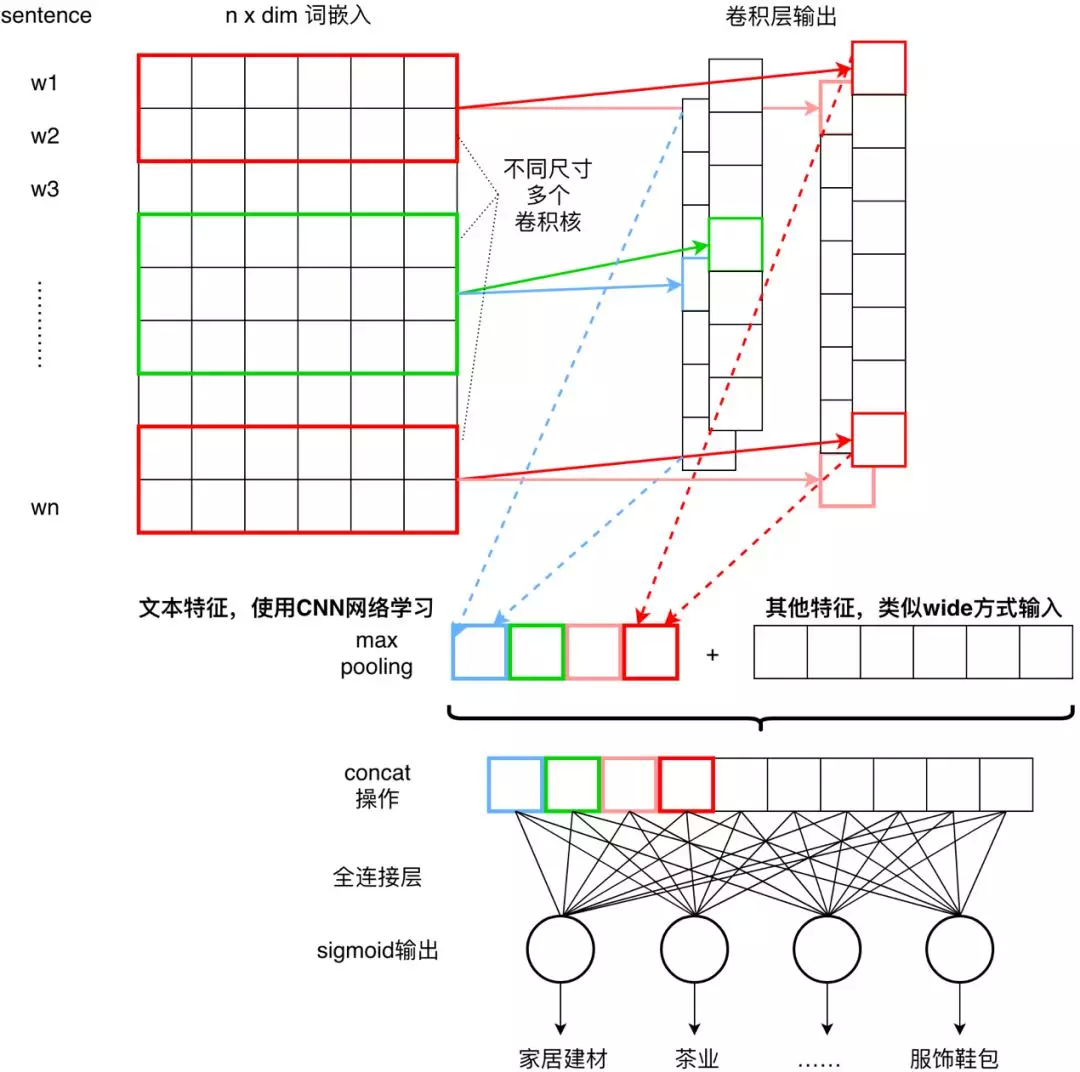
原始 textCNN 对文本进行词嵌入、卷积核池化后,直接进行 softmax 多分类,而在当前业务下:
将文本表示经过池化后,拼接了外部的其他非文本特征,对文本使用深度的特征提取与表示,而简单的非文本特征使用类似 wide&deep 的方式接入,共同参与预测;
softmax 只能输出归一化的预测结果,不适用与多标签场景;通过改造输出层,使用多路的 sigmoid 输出,每一路输出对应一个标签的预测结果;
对同一样本多标签的情况进行了压缩,多个 label 合并为一个向量;
重新设计损失函数,多分类交叉熵不适用于多个二分类输出未归一化的场景。
如此,解决了多标签场景 &非文本特征接入的问题,同时使用深度模型取得更好的泛化效果。
另一方面,所有样本在同一模型中训练,原本样本不均衡问题造成了一些负面影响。比如大类家居建材、服饰鞋包有数十万的样本,而劳保用品、美容美发用品等标签只有几千样本,在训练时很容易直接丢弃对整体准确率影响较小的小样本集。因此对每个样本集计算权重:
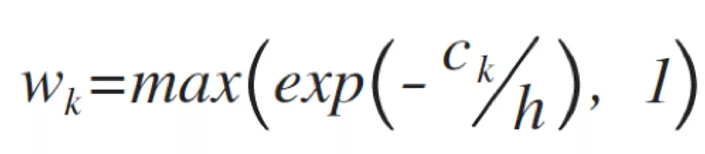
ck 为 k 类别的样本数,h 为平滑超参,效果上类别样本数量越少,权重越大。将类别权重加入到损失函数:
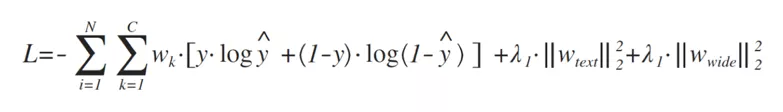
λ1、λ2 分别代表对文本特征和非文本特征的正则化约束比重因子。
经过改造和优化后:
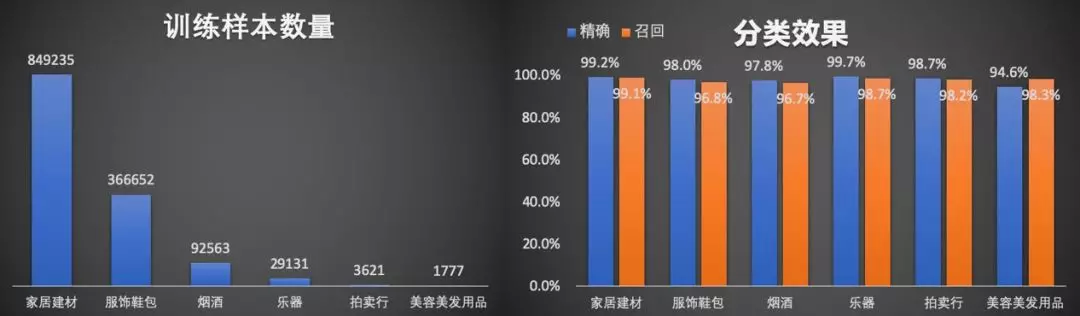
以上几个标签间样本数量差距极大,但分类效果都维持在一个比较高的准召率上。此外,我们还根据改造后的模型,开发了模型解释工具。对于一些不符合预期的 case,通过解释工具,可以直接观察:
分类时起主要作用的因子,是文本特征,还是非文本特征,以及具体是哪个特征及其 value 显示;
如果是文本特征,显示权重最大的若干个卷积窗口位置,以及具体窗口中每个 term 的权重
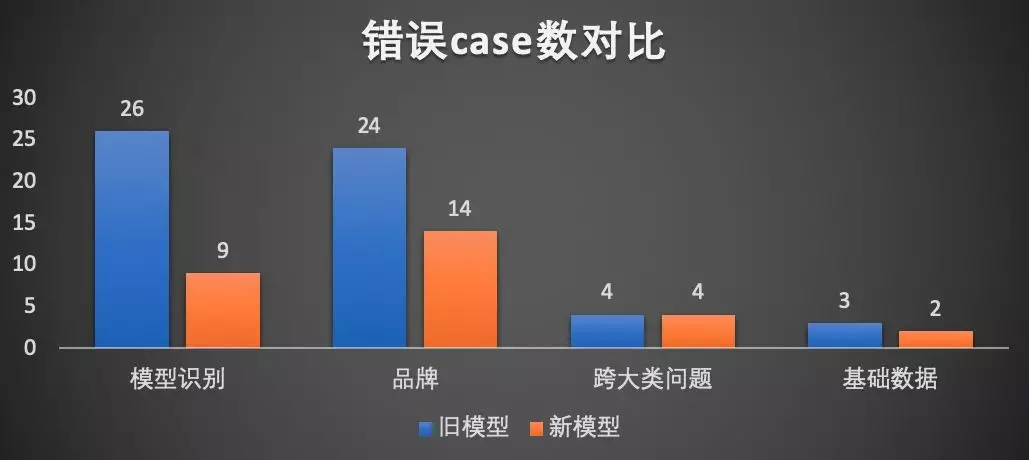
通过该工具可以在使用深度模型预测时,保持如同 LR 一般的解释性,方便定位与迭代。总体上经过以上 textCNN 的业务改造与迭代,随机数据准确率提升 5%以上,同时业务规则减少 66%,同时在长尾 case(低频文本、品牌)上取得比较明显的效果。
3.4 相关工作
前面主要介绍了我们在类别标签建设方面的一些工作。
在另一方面,类别标签在地图搜索中生效,则需要识别哪些 query 需要使用标签进行召回。在前期,我们人工标注了高德地图搜索头部 query 和标签的对应关系。但人工的标注方式始终覆盖有限:
不能取得中低频 query 的标签召回收益,从而标签利用率不够高;
对于应该使用标签召回的 query,如果因为未能识别而使用文本召回,也影响了线上的效果,降低用户体验,造成 badcase。
因此,在完成体系建设后,我们另外建模,主要使用文本语义和点击方面的特征,识别 query 和标签的对应召回关系,即识别哪些 query 可以使用类别标签召回,通过这一系列的工作,对中低频的标签召回进行了深挖,高德地图中类别搜索流量中使用标签召回比例高达 94%。
4. 收益
标签数据产出后,需要进行两方面的评估:
从输出数据的质量上,即本身标签的准确率和覆盖率:
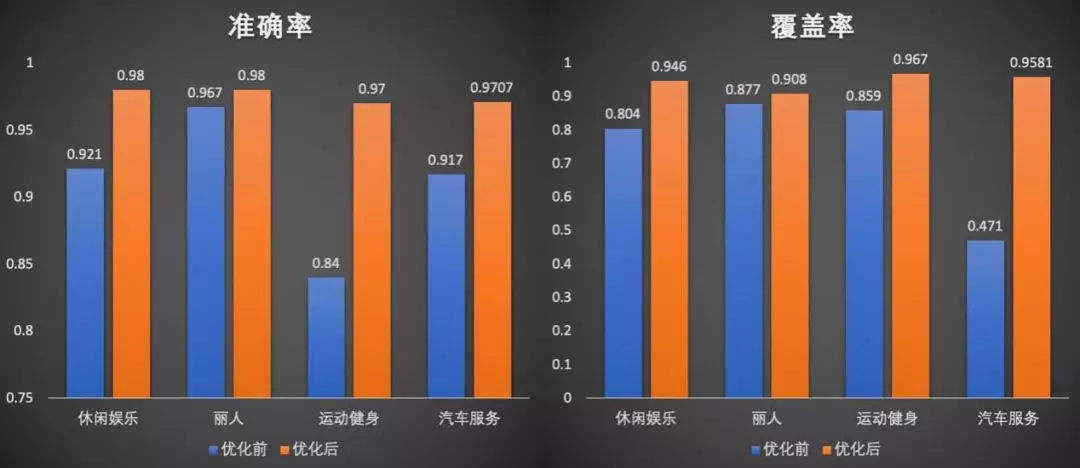
高质量的数据,不光利于搜索的业务支撑,还利于我们的类别标签体系在整个 BU 的推广和落地。
上线后对线上泛搜实际 query 的搜索效果提升评估:
除了数据质量的评估,还会结合新的标签数据对搜索效果进行评估,即对新标签体系和旧标签体系的对照效果评估。在人工效果评估中,gsb 效果上,每个大类的数据上线,都带来了非常明显的类别搜索质量提升,从而让搜索更准确、更全面的辅助用户决策。
5. 小结
当前工作的重点在于使用通用特征解决了主体的类别打标问题,对于通用特征不可解的问题,往往通过外部知识、资源的建设方式解决,如品牌库建设、A 级景区资源收集等方式。
而实际上,使用通用特征外,不通用特征对于部分数据的分类效果提升应用并不充分,后续应该安排一系列的专项优化,比如:
评论、简介等特征,应用一些 Attention 方法,可能取得比较好的补充效果;
POI 图片中往往隐含一些类别相关信息,对图片识别可以充分利用这些信息;
外部百科、知识图谱等知识的引入,辅助中低频品牌库的建设等。
在业务闭环建设上还要持续,比如恶劣 case 的流转与自动修复机制建设,新品牌、新标签的发现等问题,以避免打标系统长期运行后的效果退化等。
无论机器学习还是外部资源辅助的方式,对于海量的长尾数据往往乏力,实际线上很多的 POI 特征相当匮乏,只有一个简单的名称,从中很难准确预测其类别。如何引导用户自己提交类别信息,或者众包方式完成类别标签的标注,也是我们后续需要着重考虑的解决方案。
本文转载自公众号高德技术(ID:amap_tech)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论