

AI 前线导读:在任务间迁移知识是人类与生具有的能力。通过完成某个任务所获得的知识,同样可用于解决其他相关的任务。传统机器学习和深度学习算法通常在设计上是独立工作的,这些算法训练用于解决特定的问题。一旦特征空间的分布发生变化,就需要从头开始重新构建模型。迁移学习设计用于解决这些相互隔离的学习方式,并使用从其它任务获取的知识去解决相关的问题。本文全面介绍了迁移学习的理念、范围和真实世界应用,并给出迁移学习在深度学习中的应用实例。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
应用实例:
如何驾驶骑摩托车 ⇒ 如何驾驶汽车;
弹奏古典钢琴 ⇒ 弹奏爵士乐钢琴;
掌握数学和统计学知识 ⇒ 掌握机器学习。

在上面列出的各个场景中,我们并非从零开始学习新的知识域,而是迁移并利用了我们过往学习到的知识!
目前为止,传统机器学习和深度学习算法通常在设计上是独立工作的,这些算法训练用于解决特定的问题。一旦特征空间的分布发生变化,就需要从头开始重新构建模型。迁移学习设计用于解决这类相互隔离的学习方式,并使用从其它任务获取的知识去解决相关的问题。在本文中,我们将全面覆盖迁移学习的理念、范围和真实世界应用,并给出一些动手实例。具体而言,本文的内容涉及:
迁移学习的提出动机;
理解迁移学习;
迁移学习策略;
在深度学习中使用迁移学习;
深度迁移学习策略;
深度迁移学习类型;
迁移学习的应用;
迁移学习的优点;
迁移学习面对的挑战;
结论和展望。
如果将迁移学习视为一种通用的高层概念,我们认为它是和机器学习、统计建模同一时代出现的。尽管如此,本文中我们将更加关注深度学习本身。
注意:文中所有的案例研究都给出了包括代码和输出的分步骤细节。这些案例研究和结果完全基于我们撰写的《Python 迁移学习实战》(Hands on Transfer Learning with Python ) 一书中的实际操作实验。该书实现和测试了这些模型,文末将详细介绍该书。
鉴于网络上存在信息过载的问题,本文旨在涵盖一些理论概念,一并给出深度学习应用的一些实际动手实例。所有实例均采用 Python 语言,使用基于 Tensorflow 后端的 Keras 实现。这对于机器学习新手或刚刚着手深度学习的人而言,无疑是很完美的匹配!如果读者对 PyTorch 感兴趣,尽可随意转换这些示例程序。我将在本文和 GitHub 上展示大家给出的可行工作!
迁移学习的动机
上面我们简单介绍了人们如何从零开始学习所有事情,并如何将他们的知识从已学习的领域利用和迁移到新的领域和任务上。在推动真实人工通用智能(AGI,True Artificial General Intelligence) 的热潮中,数据科学家和研究人员认为,迁移学习可以促进我们在 AGI 方面取得进步。事实上在近期的 NIPS 2016 上,吴恩达(Andrew Ng),一位与 Google Brain、百度、斯坦福大学和 Coursera 有密切联系的著名教授兼数据科学家,做了一个非常好的教程,名为“使用深度学习构建 AI 应用的具体细节”(Nuts and bolts of building AI applications using Deep Learning )。 其中提到:
继有监督学习之后,迁移学习将成为机器学习取得成功的下一个驱动因素。
对此教程感兴趣的读者,推荐阅读 NIPS 2016 提供的教程视频)。
事实上在 2010 年之前,迁移学习并未作为一个概念出现。NIPS 1995 的研讨会“Learning to Learn: Knowledge Consolidation and Transfer in Inductive Systems ”被认为是最初提出该领域的研究。此后,“学会学习”(Learning to Learn)、“知识整合”(Knowledge Consolidation)和“归纳迁移(”Inductive Transfer)等术语成为可以互换使用的概念。不同的研究人员和学术论文,总是会对迁移学习给出不同背景下的定义。在著名的《深度学习》一书中,Goodfellow 等著者基于泛化(generaliztion)定义了迁移学习。他们给出的定义如下:
从一个场景中学习到的条件,可通过改进泛化用于另一个场景。
因此迁移学习提出的主要动机,尤其是考虑到深度学习的背景,是大多数用于解决复杂问题的模型需要大量的数据。并且从标记数据点所需的时间和精力上看,为有监督模型提供大量的标记数据事实上非常困难。一个基本的例子是 ImageNet 数据集,它提供了具有多个类别的数百万图像,其中凝聚了斯坦福大学研究团队多年的辛勤工作!

图一 基于 ImageNet 数据集的 ImageNet 挑战受到了广泛的关注
但是,对每个领域都建立此类数据集是非常困难的。此外,大多数深度学习模型都非常专注于特定的领域,甚至是特定的任务。尽管深度学习可能给出了目前最先进的模型,具有非常高的准确性,并在全部基准测试上表现优异。但是这些模型仅适用于非常特定的数据集,当应用于新任务时会给出显著的性能损失,即便新任务与所训练的任务非常相似。这些问题是推动迁移学习发展的动力。迁移学习超越了特定的任务和域,它试图给出的方法可利用预训练的模型中的知识,并用于解决新域中的问题!
理解迁移学习
首先应指出,迁移学习并非一个特定专用于深度学习的新概念。迁移学习的方式,完全不同于使用传统方法构建和训练机器学习模型。
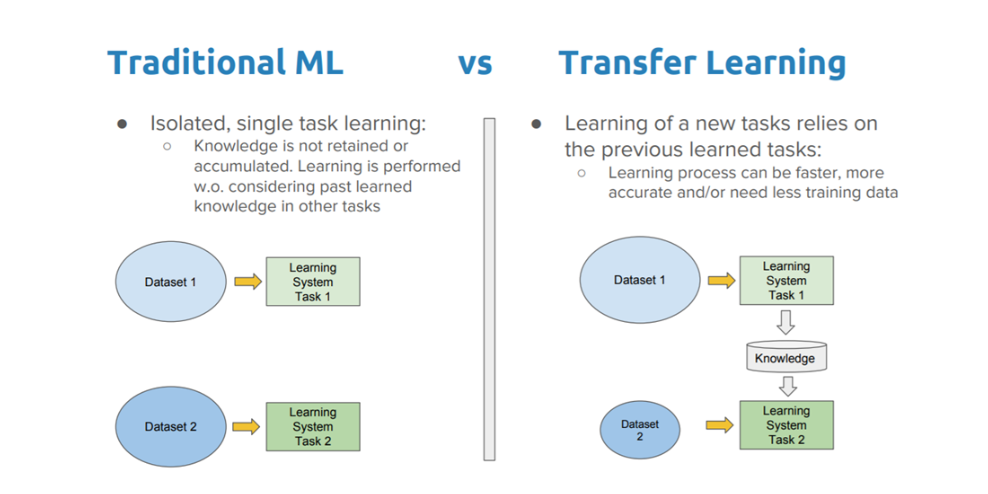
图二 传统学习方法与迁移学习的对比
传统的机器学习是孤立的,纯粹基于特定的任务和数据集训练各自孤立的模型,学习中并未保留任何可从一种模型迁移到另一种模型上的知识。在迁移学习中,使用者可以利用先前训练模型中的知识(即特征、权重等)训练新的模型,甚至可以解决诸如新任务具有较少数据等问题!
为理解上面的说法,我们给出一个例子。假设我们的任务是识别餐馆某片受限区域图像中的对象。我们将针对定义范围的任务标记为 T1。如果给定了该任务的数据集,那么我们可以训练并微调模型。该模型很好地适用来自同一域(即餐厅)的未见数据点,即泛化。如果我们不具有所需的足够训练样例可用于处理给定领域的任务,那么传统的有监督机器学习算法就会崩溃。假设我们现在必须从公园或咖啡馆的图像中检测物体,该任务称为 T2。在理想情况下,我们应该能够将针对 T1 训练的模型用于 T2。但实际上,我们会面临性能下降以及模型不能很好泛化的问题。导致问题的原因很多,可统称为模型对训练数据和领域存在偏差(bias)。
迁移学习使得我们能够利用前期学习任务中的知识,并将这些知识应用于新的相关任务。如果任务 T1 具有更多的数据,那么我们可以利用它所学习的模型(特征、权重等),泛化并应用于显著缺少数据的任务 T2。对于计算机视觉领域的一些问题,某些低层特征(如边缘、形状、边角和强度等)是可以跨任务共享的,从而实现任务间的知识转移!正如我们在前面给出的图中所描述的,来自现有任务的知识,可作为学习新目标任务时的额外输入。
形式化定义
为理解不同的迁移学习策略,下面我们给出迁移学习的形式化定义。在综述论文“A Survey on Transfer Learning”) 中,Sinno Jialin Pan 和杨强教授使用域、任务和边缘概率定义了一种用于理解迁移学习的框架。该框架的定义如下:
域 D 定义为由特征空间ꭕ和边缘概率 P(Χ)组成双元素元组。其中Χ是抽样数据点。域可以形式化表示为 D = {ꭕ, P(Χ)}。

上式中,xᵢ表示特定向量。而任务 T 可定义为标签空间γ和目标函数η的双元素元组。从概率角度看,目标函数可表示为 P(γ|Χ)。

Sebastian Ruder 撰写了一篇很好的文章, 他使用上述定义和表示将迁移学习定义如下:

场景(Scenario)
基于上面给出的定义,我们列出如下涉及迁移学习的典型场景:

为进一步澄清“域”(domain)和“任务”(task)二者间的差异,下图给出了一些例子:
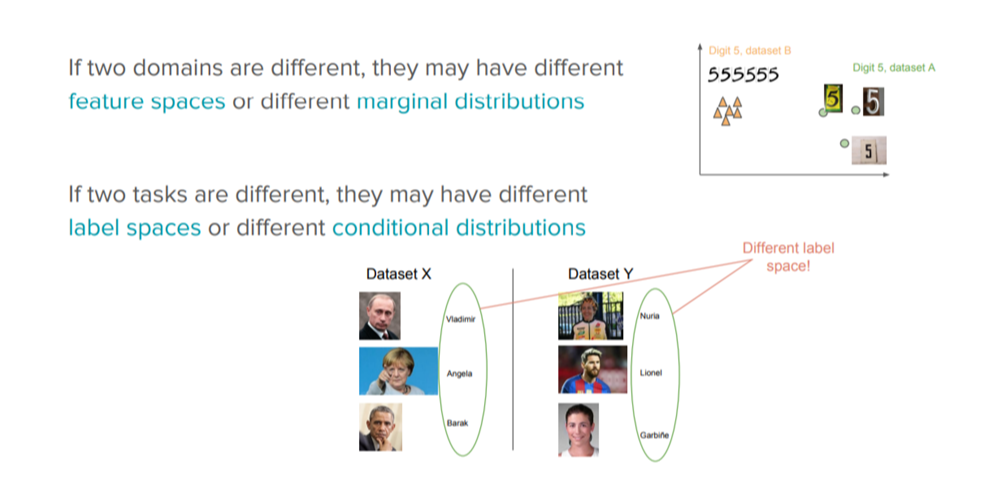
要点
正如我们已经介绍的,迁移学习能够利用源学习器对目标任务的现有知识。在迁移学习的过程中,必须回答如下三个重要的问题:
迁移什么?: 该问题是整个迁移学习过程中第一步,也是最重要的一步。为提高目标任务的性能,我们力图寻求哪些知识可以从源迁移到目标。在回答这个问题时,我们会试图确定哪些知识是特定于源的,哪些知识在源和目标之间的是共同的。
何时迁移?: 在某些场景中,迁移知识可能要比改进知识更糟糕(该问题也称为“负迁移”)。我们的目标是通过迁移学习改善目标任务的性能或结果,而不是降低它们。我们需要注意何时需要迁移,何时不需要迁移。
如何迁移?: 一旦回答了“迁移什么”和“何时迁移”的问题,我们就可以着手确定跨域或跨任务实现知识实际迁移的方法。该问题涉及如何改进现有的算法和各种技术,我们将在本文随后的章节中介绍。此外,为更好地理解如何迁移,文中还给出了具体的案例研究。
上述问题有助于我们定义可应用迁移学习的各种场景,以及可采用的技术。下一章将对此展开介绍。
迁移学习的策略
根据域、任务和数据的可用性不同,我们可以应用不同的迁移学习策略和技术。我个人特别推荐论文“A Survey on Transfer Learning”中给出的下图:
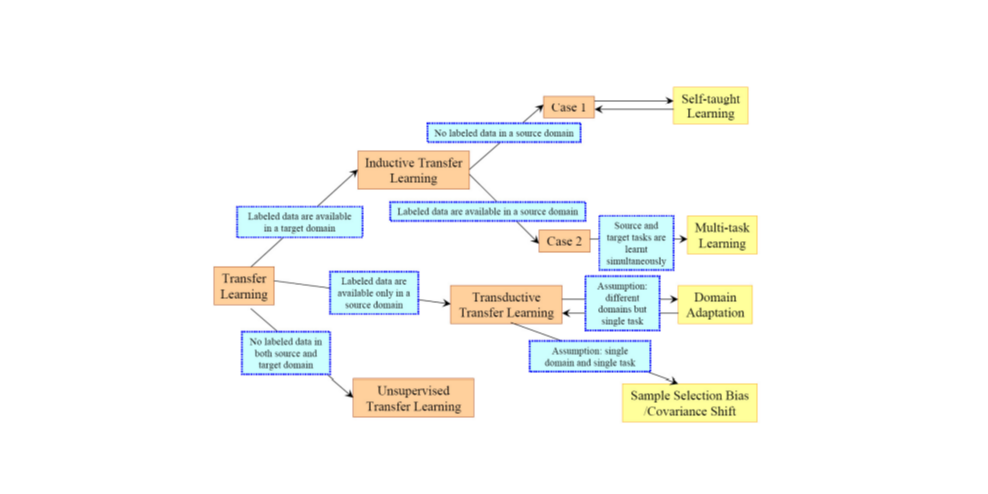
图三 迁移学习的策略
无监督迁移学习(Unsupervised Transfer Learning):该场景类似于归纳式迁移学习,重点关注目标域中的无监督任务。其中,源域和目标域类似,但是任务不同。在该场景中,任一域都没有可用的标记数据。
直推式迁移学习(Transductive Transfer Learning):在该场景中,源任务和目标任务之间存在一些相似之处,但相应的域不同。源域具有大量标记数据,而目标域没有。根据特征空间或边缘概率的设置不同,直推式迁移学习可进一步分类为多个子类。
下表总结了上述技术的不同设置和场景。
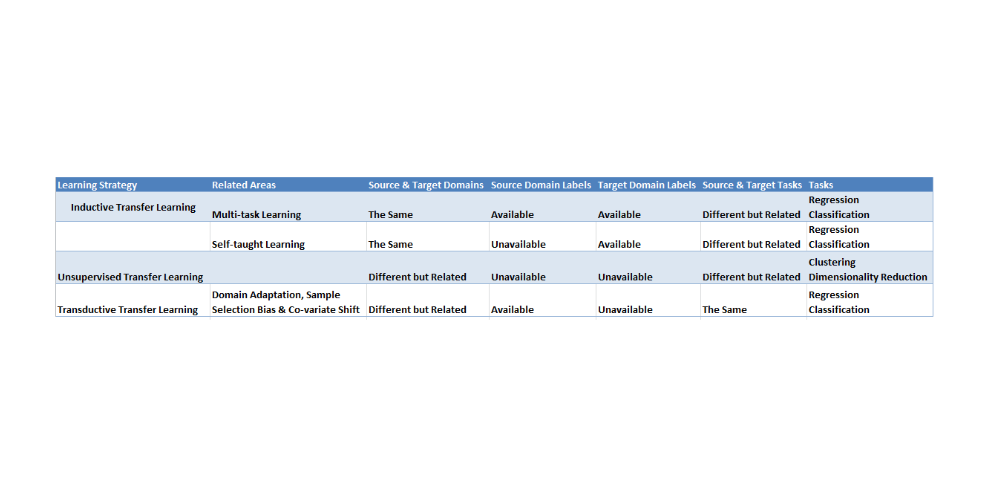
图四 迁移学习的策略类型和设置
上面介绍的三种迁移类别,详细列出了可应用和研究迁移学习的不同设置。下列方法可回答在类别间迁移什么的问题:
基于样本的迁移学习(Instance transfer):通常,理想场景是源域中的知识可重用到目标任务。但是在大多数情况下,源域数据是不能直接重用的。然而,源域中的某些实例是可以与目标数据一起重用,达到改善结果的目的。对于归纳式迁移,已有一些研究利用来自源域的训练实例来改进目标任务,例如 Dai 及其合作研究者对 AdaBoost 的改进工作。
基于特征表示的迁移学习(Feature-representation transfer): 该类方法旨在通过识别可以从源域应用于目标域的良好特征表示,实现域差异最小化,并降低错误率。根据标记数据的可用性情况,基于特征表示的迁移可采用有监督学习或无监督学习。
基于参数的迁移学习(Parameter transfer): 该类方法基于如下假设:针对相关任务的模型间共享部分参数,或超参数的先验分布。不同于同时学习源和目标任务的多任务学习,在迁移学习中我们可以对目标域应用额外的权重以提高整体性能。
基于关系知识的迁移学习(Relational-knowledge transfer): 与前面三类方法不同,基于关系知识的迁移意在处理非独立同分布(i.i.d)数据即每个数据点均与其他数据点存在关联。例如,社交网络数据就需要采用基于关系知识的迁移学习技术。
下表清晰地总结了不同迁移学习策略间的关系,以及迁移什么的问题。
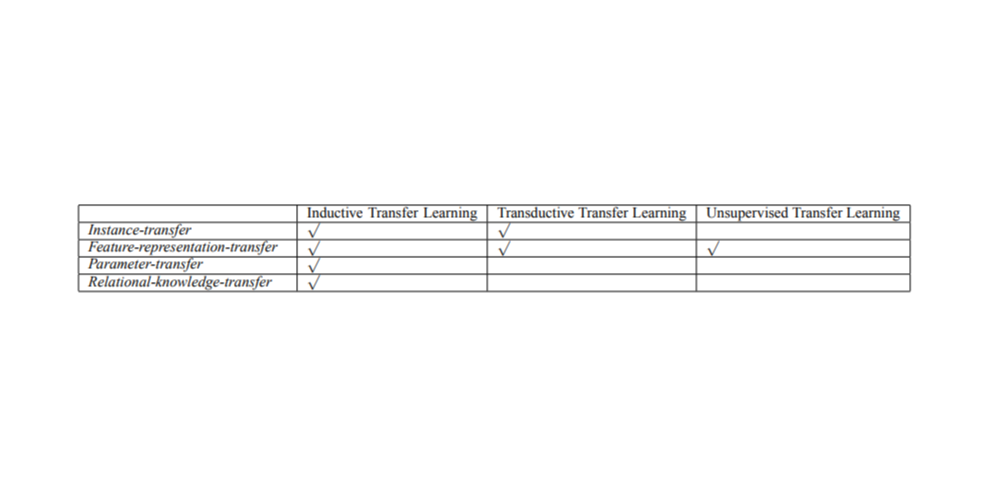
图五 迁移学习策略及可迁移组件类型
将迁移学习应用于深度学习
上一章中介绍的策略,是可应用于机器学习技术的一般方法。这为我们提出了一个问题,迁移学习是否的确可应用于深度学习的场景?

深度学习模型是所谓归纳学习(inductive learning)的一种代表性方法。归纳学习算法的目标是从一组训练样例中推理出映射。例如,对于分类问题,模型学习的是输入元素和类标签间的映射关系。为将学习器很好地泛化到未见数据上,学习算法使用了与训练数据分布相关的一组假设,我们称这些假设为“归纳偏差”(inductive bias)。归纳偏差或假设可使用多种因素表征,例如,限定偏差的假设空间,假设空间的搜索过程等。这些偏差会影响模型在特定任务和域中学习的方式以及学习的内容。
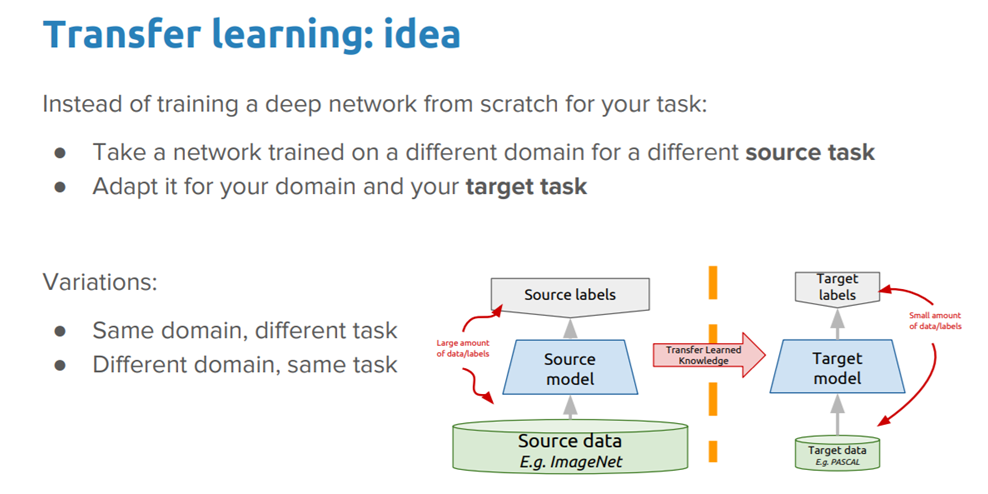
图六 深度迁移学习的理念
归纳迁移技术(Inductive transfer techniques)利用源任务的归纳偏差辅助目标任务。这可以通过多种不同方式实现。例如,通过限制模型空间和缩小假设空间调整目标任务的归纳偏差,或者借助源任务的知识对搜索过程本身进行调整。下图给出上述过程的可视化描述。
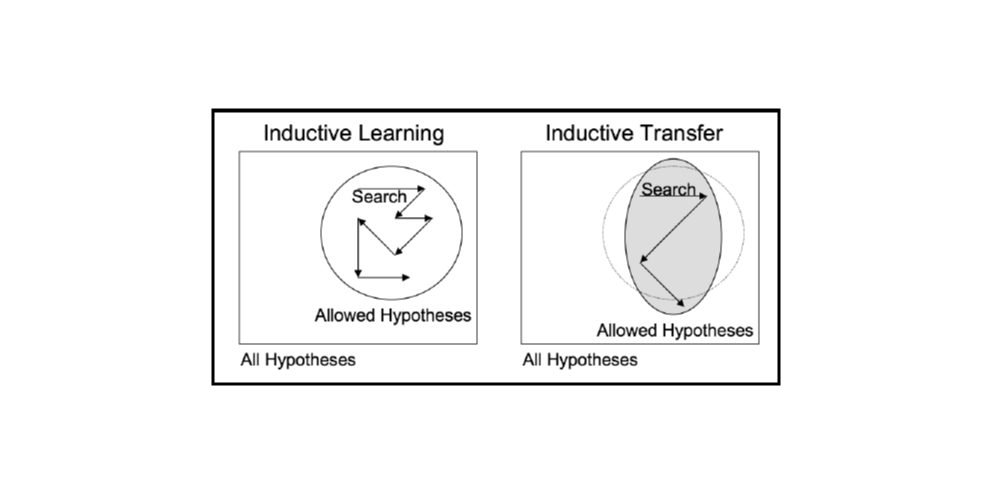
图六 归纳迁移(图片来自 Lisa Torrey 和 Jude Shavlik 合著的《迁移学习》一书)
为改进目标任务的学习和性能,除了使用归纳迁移技术之外,归纳学习算法还可使用贝叶斯和层次传递技术。
深度迁移学习策略
近年来,深度学习在可解决的复杂问题类型上取得了长足的进步,其成果令人惊讶。然而,深度学习系统所需的训练时间和训练数据的量级,要远大于传统的机器学习系统。目前人们已经提出了各种深度学习网络,它们具有最先进的性能,有时甚至优于人类的表现。一些深度网络已经在计算机视觉和自然语言处理等领域得到开发和测试,并且其中大多数网络已完全共享给团队和研究人员使用。这些预训练的网络和模型构成了在深度学习环境中迁移学习的基础,我称其为“深度迁移学习”的基础。下面给出两种广为使用的深度迁移学习策略。
以现成可用的预训练模型作为特性抽取器
深度学习的系统和模型采用了分层架构,在不同的层上学习不同的特征,即分层特征的层次表示。各层最终连接到最后一层(对于分类任务而言,通常是完全连接层),并给出最终输出。这种分层架构可不使用预训练网络(例如 Inception V3 或 VGG)的最终层,作为其他任务的固定特征抽取器。
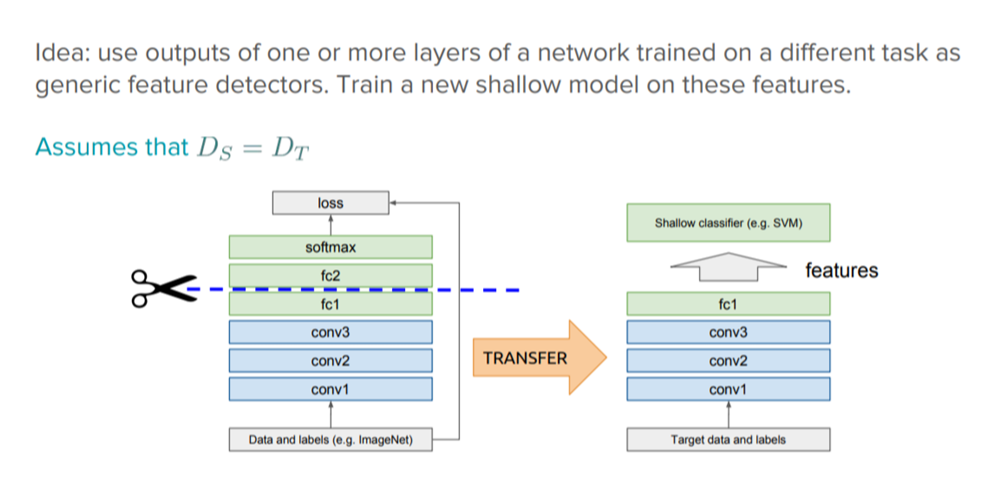
图七 使用预训练深度学习模型作为特征抽取器的迁移学习
这里的关键理念是,仅利用预训练模型的加权层提取特征,而不是在使用新数据训练新任务期间更新模型层的权重。
例如,使用不包括最终分类层的 AlexNet,可基于图像的隐藏状态将图像从一个新域任务转换为一个 4096 维的向量,从而能够利用来自于源域任务的知识从新域任务中提取特征。这是使用深度神经网络进行迁移学习中最广为使用的方法之一。
现在可能会出现一个问题,这些现成可用的预训练特性对现实中不同任务的运行情况如何?

从上图结果可见,该方法对于现实世界的任务的确运行得非常好。如果上图给出图表还不能清楚地说明问题,那么下图清晰地给出了该方法在基于计算机视觉的任务中的表现,结论十分清楚!
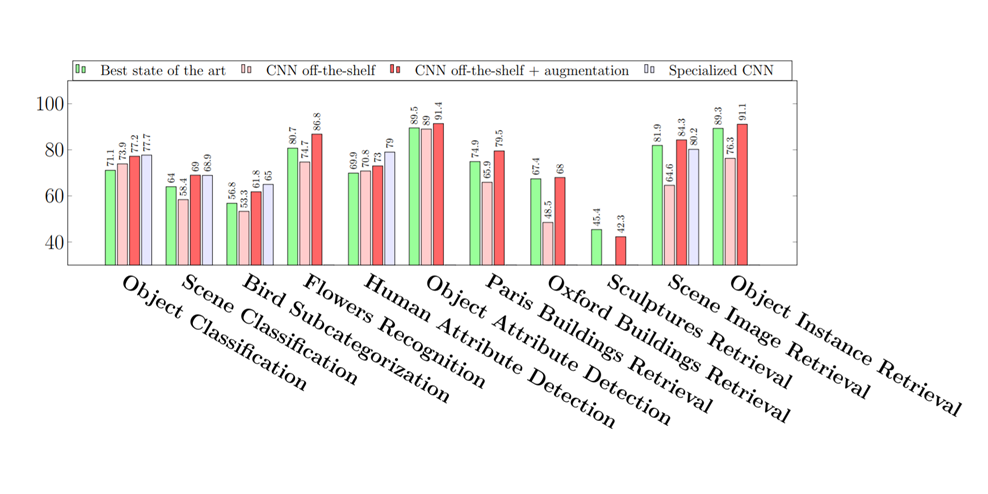
图八 现成可用的预训练模型和专用于深度学习的特定模型间的性能对比
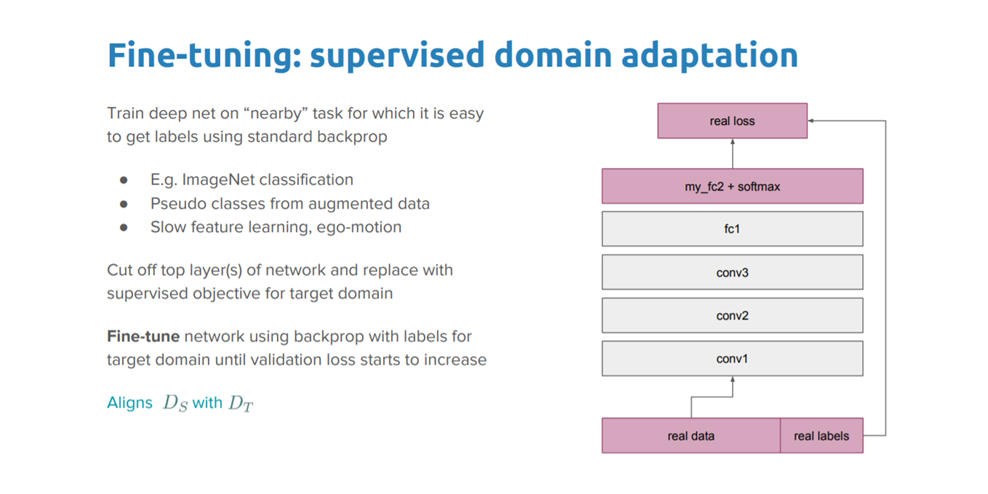
良好微调的现成可用预训练模型
这是一种更为复杂的技术,我们不仅要替换最后一层(用于分类或回归任务),而且还要有选择地重新训练一些先前的层。深度神经网络是一种具有多种超参数的高度可配置架构。如前所述,初始层可视为捕获通用特性,随后的层更多地关注所针对的特定任务。下图给出的是一个人脸识别问题的示例,其中网络初始的较低层学习非常通用的特征,而较高层则学习非常特定于任务的特征。

基于上述观察,我们可以在对某些层重新训练时冻结它们(即固定层的权重),或者对其余的层进行微调以满足我们的需要。这时,我们利用了网络整体架构上的知识,并以该状态作为重新训练步骤的出发点,进而有助于以更少的训练时间实现更好的性能。
冻结(Freezing),还是微调(Fine-tuning)?
这就引出了一个问题,我们是否应该冻结某些层以充当特征提取器,还是应该在此过程中对层做微调?
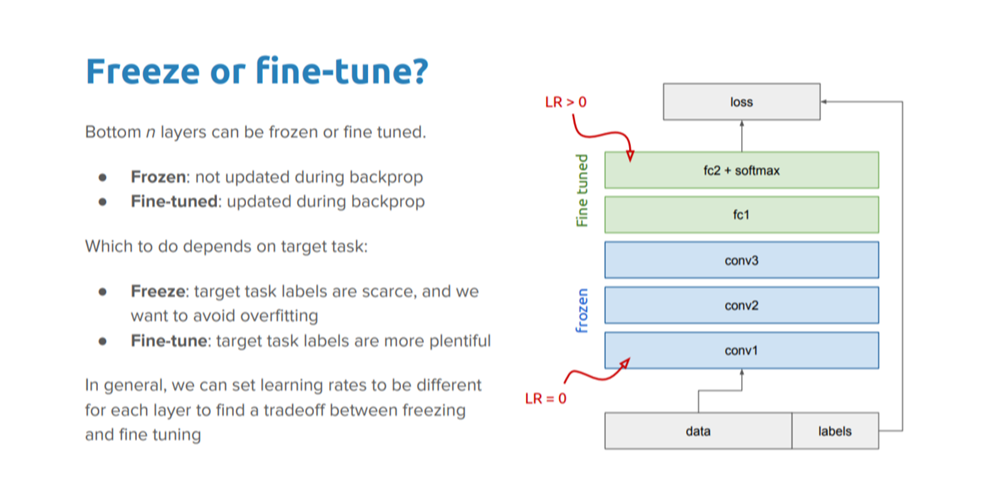
对于了解每个策略的具体内容,以及何种情况下应该使用这些策略,该问题给出了一个很好的视角。
预训练模型
给出在源任务上表现良好的模型,是迁移学习的基本要求之一。幸运的是,深度学习社区是乐于分享的。已有多个团队公开分享了许多最先进的深度学习框架,跨越了多个不同的领域。其中包括计算机视觉和自然语言处理,这是深度学习得到最广泛应用的两个领域。预训练模型通常是以训练达到稳定状态的数百万参数或权重的形式共享,可供研究人员以不同的方式使用。例如,著名的深度学习 Python 库 Keras 提供了下载界面,可下载一些广为使用的模型。人们还可以通过网络访问一些预训练的模型,因为大多数模型都是开源的。
对于计算机视觉,可使用下列广为使用的模型:
对于自然语言处理任务,因为自然语言处理任务本质上存在很大差异,事情则变得更为复杂。可使用的字嵌入模型包括:
稍等,这并非全部!最近,迁移学习在自然语言处理中的应用上取得了一些很好的进展。一些最
新研究成功包括:
这些研究具有很好的前景。我确信它们将很快在现实世界应用中得到广泛地使用。
深度迁移学习的类型
正如我们一开始就提到的,迁移学习的相关文献已经历了多轮迭代,相关的术语使用宽泛,并通常互换使用。因此,如何区分迁移学习、领域适应性和多任务学习时常会令人感到困惑。但我们大可放心,上述概念都是一脉相承的,它们试图解决类似的问题。一般说来,迁移学习应始终视为一种通用的概念或原则。其中,我们尝试使用源任务域的知识去解决目标任务。
域适用性(Domain Adaptation)
域适用性通常用于源域和目标域间的边缘概率不同的情况,即 P(Xₛ) ≠ P(Xₜ)。如果源域和目标域的数据分布存在固有的转变或漂移,那么需要做出微调才能做迁移学习。例如,标记为正向或负向的电影评论语料库,是不同于保存产品评论情感的语料库。如果将针对电影评论情感而训练的分类器用于对产品评论进行分类,那么我们将得到不同的分布。因此在这些场景中,需要将域适用性技术用于实现迁移学习。
域混淆(Domain Confusion)
上面我们已经介绍了不同的迁移学习策略,还讨论了从源到目标迁移什么、何时迁移、如何迁移知识这三个问题。特别是,我们介绍了特征表示迁移的有用之处。值得再次强调的是,深度学习网络的不同层捕获了不同的特征集。我们可以利用这一事实去学习域的不变特征,并提高跨域的可迁移性。我们不是让模型学习所有表示,而是要让两个域的表示尽可能地相似。这可以通过对表示本身直接应用某些预处理步骤实现。Baochen Sun、Jiashi Feng 和 Kate Saenko 在他们的论文“Return of Frustratingly Easy Domain Adaptation” 中,讨论了其中的一些问题。Ganin 等人也在论文“Domain-Adversarial Training of Neural Networks 中提出了一种推动表示上相似性的方法。该方法背后的基本思想是在源模型中添加另一个目标函数,通过混淆域本身来鼓励相似性,进而实现域混淆。
多任务学习(Multitask Learning)
迁移学习的另一类解决方法是多任务学习。多任务学习同时学习若干任务,并不区分源和目标。与迁移学习相比,多任务学习的学习器最初并不知道目标任务,它一次接收多个任务的相关信息,如下图所示。
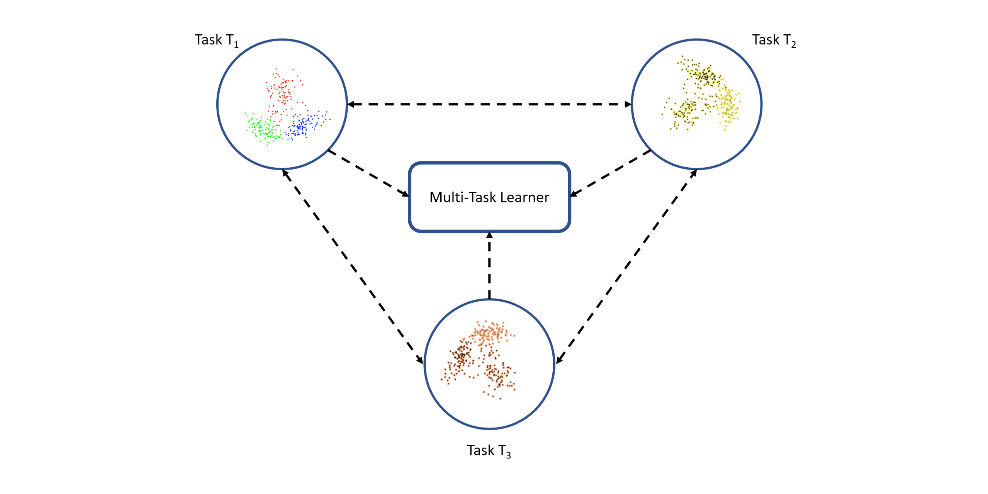
图九 多任务学习:学习器同时接收来自所有任务的信息
One-shot 学习(One-shot Learning)
深度学习系统本质上需要大量的数据,因此系统通过大量地训练样本学习权重。这是深度神经网络的一个局限性,尽管人类学习并非如此。例如,一旦一个孩子看到了苹果的样子,他就可以根据一个或数个训练样本很容易地识别出不同种类的苹果。但是机器学习和深度学习算法并非如此。One-shot 学习是迁移学习的一种变体,它试图仅根据一个或几个训练样本而推断所需的输出。这在实际场景中非常有用。在一些实际场景的分类任务中,不可能为每个可能的类和一些需要经常添加新类的场景提供标记数据。李飞飞及其合作研究者的标志性论文“One Shot Learning of Object Categories” 被认为创立了“One-shot 学习”这一术语以及该子领域的研究。该论文提出了一种贝叶斯框架的变异,用于对象分类的表征学习(representation learning)。此后该方法得到了进一步改进,并通过深度学习系统得以应用。
Zero-shot 学习(Zero-shot Learning)
Zero-shot 学习是迁移学习的另一种变体,它依赖于未标记的样本学习任务。这可能听上去令人难以置信,尤其是大多数有监督学习算法都是使用样本进行学习的。Zero-shot 学习(或称为 zero-short 学习)在训练阶段中设计了一些巧妙的调整,利用一些其他信息去理解未见数据。在《深度学习》一书中,Goodfellow 及其他和著者将 Zero-shot 学习描述为一种学习三个变量的场景,即传统的输入变量 x、传统的输出变量 y 和描述任务的额外随机变量 T。因此,模型的训练过程就是学习条件概率分布 P(y | x, T)。Zero-shot 学习十分适用于机器翻译等场景,我们甚至可能不需要标记的目标语言。
迁移学习的应用
深度学习绝对是能凸显迁移学习优点的一类特定算法。下面给出几个例子:
在自然语言学习中使用迁移学习:文本数据对机器学习和深度学习提出了各种各样的挑战。通常需要使用各种技术对文本做转换或矢量化。Word2vec 和 FastText 等嵌入需要使用不同的训练数据集给出。这些嵌入可通过从源任务传递知识而用于不同的任务,例如情感分析和文档分类等。此外,Universal Sentence Encoder 和 BERT 等新模型无疑为未来增添了多种可能。
在语音识别中使用迁移学习:和自然语言处理和计算机视觉等领域一样,深度学习已成功应用于许多基于音频数据的任务。例如,为英语开发的自动语音识别(ASR、Automatic Speech Recognition)模型已成功地用于提高对德语等语言的语音识别性能。此外,演讲者自动识别是迁移学习发挥很大作用的又一个例子。
在计算机视觉中使用迁移学习:深度学习已成功地用于各种计算机视觉任务,例如使用不同的 CNN 架构实现对象的检测和识别。Yosinski 及其合作研究者在他们的论文) 中,展示了他们对特征在深层神经网络中迁移方式上的发现。该研究结果表明了网络低层是如何充当传统的计算机视觉特征提取器(例如,作为边缘检测器),最终层是如何实现面向特定任务的功能。
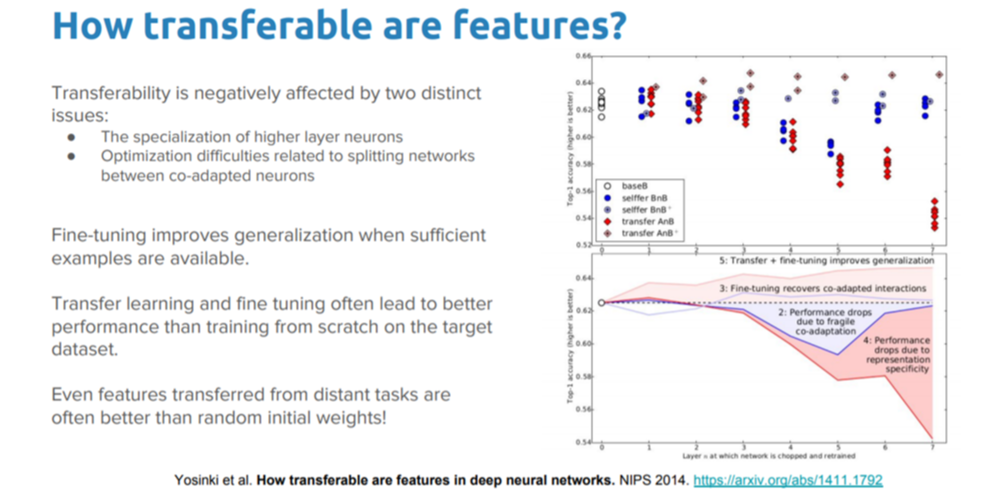
这些研究发现不同于一开始就针对特定任务而训练模型,有助于使用 VGG、AlexNet 和 Inceptions 等现有最先进模型实现风格迁移(style transfer)和面部检测等目标任务。
迁移学习的优点
我们已在前面几章中提及了迁移学习的几个优点。通常,迁移学习可使我们构建更强大的模型,支持我们执行各种各样的任务。其中包括:
有助于解决具有多个约束的复杂真实世界问题。
解决具有很少或几乎没有标注数据的问题。
易于实现模型间基于领域和任务的知识迁移。
为有朝一日实现 AGI 提供了一条途径!
迁移学习所面对的挑战
迁移学习是对现有学习算法所存在的一些普遍问题的增强,前景无量。 然而,迁移学习依然存在一些相关问题需要做进一步研究和探索。除了迁移什么、何时迁移以及如何迁移这三个问题依然难以回答之外,负迁移(negative transfer,也称干扰)和迁移界限(transfer bounds)也是主要的挑战。
负迁移(Negative Transfer):我们目前给出的案例,阐述了如何根据源任务的知识迁移去改进目标任务。在某些情况下,迁移学习会导致性能下降。负迁移就是从源到目标的知识迁移并不会导致任何改进,而是会导致目标任务的整体性能下降。导致负迁移可能存在多种原因,例如源任务与目标任务间并没有充分的关联关系,或者迁移方法无法很好地利用源任务和目标任务之间的关系。避免出现负迁移是非常重要的,我们需要做仔细的调查。Rosenstien 及其合作研究者在他们的研究工作中凭经验指出,蛮力迁移是如何在源和目标并太不相似的情况下降低了目标任务的性能。一些避免出现负迁移的研究工作正在开展中。例如 Bakker 及其合作研究者提出了一种贝叶斯方法,还有其它一些探索基于聚类的解决方案以识别相关性的技术。
迁移界限(Transfer Bounds): 对迁移学习中的迁移做量化分析是非常重要的,量化分析可给出迁移的质量,以及迁移的可行性。为了衡量迁移的总量,Hassan Mahmud 及其合作研究者使用 Kolmogorov 复杂度证明了一个理论界限,可用于分析迁移学习和衡量任务之间的相关性。Eaton 及其合作研究者提出了一种基于图表的新方法对知识迁移进行衡量。对这些技术的详细讨论超出了本文的范围,我们鼓励读者进一步阅读本章中介绍的一些公开发表论文,进而探索该主题的更多相关信息!
结论和展望
本文大概是我撰写的最长篇幅文章之一,文中全面涵盖了迁移学习的概念和策略,并重点介绍了深度迁移学习及其挑战与优势。为使读者更好地了解如何实现这些技术,文中还给出了两个真实案例研究。如果读到此节,感谢通读该长篇大论!
迁移学习必将成为机器学习和深度学习成功取得业界主流应用的关键驱动因素之一。我特别希望能看到使用该理念和方法的更多预训练模型和创新案例研究。我计划未来推出的文章中,有望介绍如下内容:
在自然语言识别中使用迁移学习;
在音频数据上使用迁移学习;
在生成深度学习中使用迁移学习;
处理图像描述(Image Captioning)等更复杂的计算机视觉问题。
希望能看到迁移学习和深度学习相关的更多成功案例。这些案例将推动建立更智能的系统,让世界变得更美好,并有助于实现每个人的个人目标!
查看英文原文:
会议推荐:
12月20-21,
暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论