随着深度学习的发展,基于神经网络的个性化和推荐模型已经成为在生产环境中(包括 Facebook)构建推荐系统的重要工具。然而,这些模型与其他深度学习模型有显著区别,它们必须能够处理用于描述高级属性的类别数据(categorical data)。对于神经网络而言,高效处理这类稀疏数据是很有挑战性的,而且由于缺乏公开可用的代表性模型和数据集,也拖慢了该领域科学研究的进展。为了加深对这一子领域的理解,Facebook 开源了当前最先进的深度学习推荐模型 DLRM。
DLRM 模型使用 Facebook 的开源框架 PyTorch 和 Caffe2 实现。DLRM 通过结合协同过滤和基于预测分析方法的原理,相比于其他模型有所提升,从而使其能够有效地处理生产规模的数据,并得到目前最佳结果。
Facebook 开源该模型并且公布相关论文,旨在帮助该领域的研究人员解决这类模型所面临的独特挑战。Facebook 希望鼓励进一步的算法实验、建模、系统协同设计和基准测试。这有助于发掘新的模型和更高效的系统,从而为使用各种数字服务的人们提供更具相关性的内容。
了解 DLRM 模型
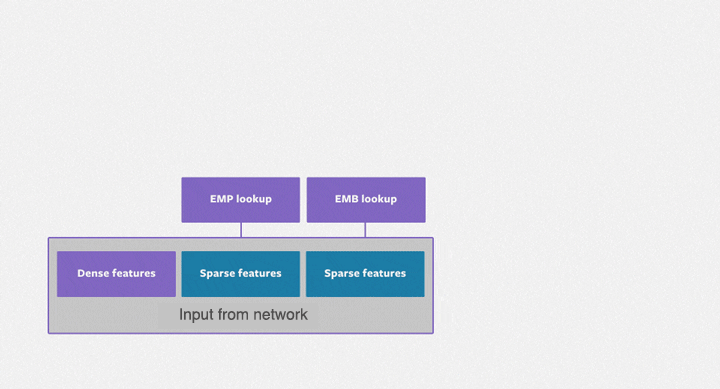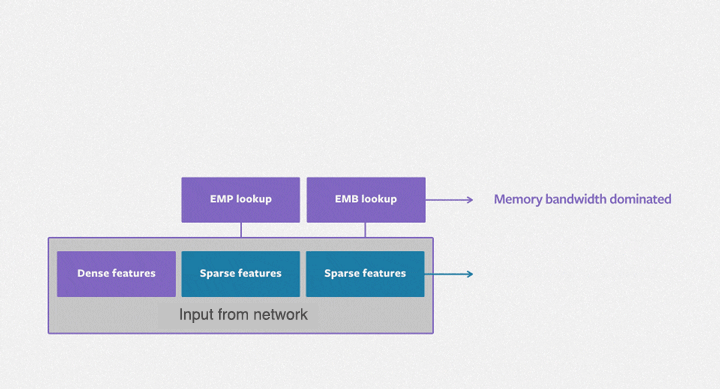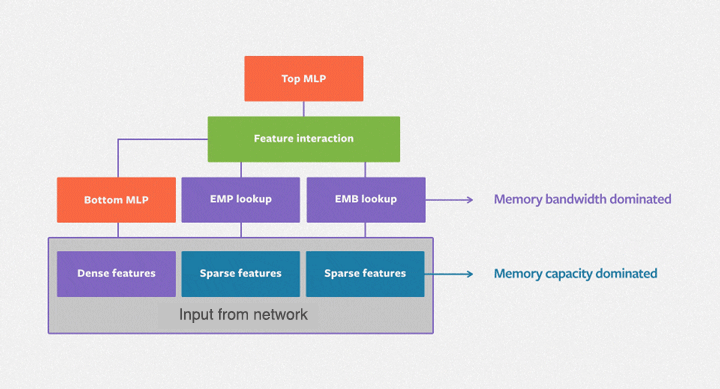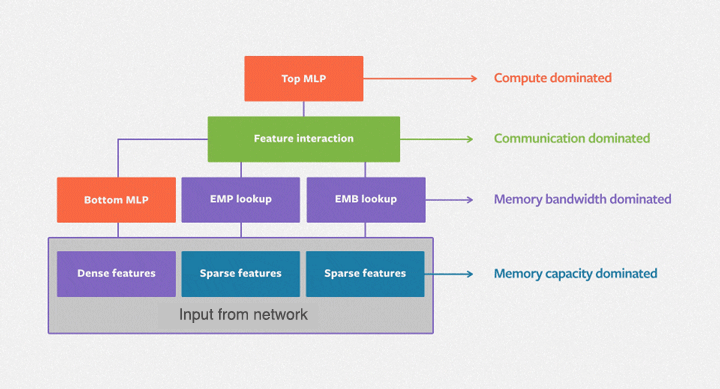
DLRM 模型使用嵌入表示处理类别特征,而使用底部的多层感知器(MLP)处理连续特征。然后计算不同特征的二阶交互作用(second-order interaction)。最后,使用顶部的 MLP 对结果进行处理,并输入到 sigmoid 函数中,得到某次点击的概率。
图 1 DLRM 模型处理描述用户和产品的连续(密集)特征和类别(稀疏)特征,如图所示。该模型使用了各类硬件和软件组件,如内存容量和带宽,以及通信和计算资源。
基准与系统协同设计
DLRM 的开源实现可以用作基准,衡量以下各项指标:
模型(及其相关算子)的执行速度。
不同数值技术对精度的影响。
这可以在不同的硬件平台上完成,如BigBasin人工智能平台。
DLRM 基准提供了两个版本的代码,分别使用 PyTorch 和 Caffe2。此外,还有另一个使用Glow C++算子实现的版本。(为了适应每个框架的具体情况,各框架的代码略有不同,但总体结构是相似的。)这些实现允许我们将 Caffe2 框架与 PyTorch 框架,以及当前专注于加速器的 Glow 进行对比。也许我们可以提取每个框架中的最佳特征,未来将其整合到一个框架中。
DLRM 基准支持生成随机输入和合成输入。同时支持模型自定义生成与类别特征对应的索引,这有许多原因:例如,如果某个应用程序使用了一个特定的数据集,但出于隐私考虑我们不能共享数据,那么我们可以选择通过分布表示类别特征。另外,如果我们想利用系统组件,如研究记忆行为,我们可能需要捕捉合成轨迹(synthetic trace)内原始轨迹的基本位置。
此外,Facebook 根据用户场景的不同,使用了多种个性化的推荐模型。例如,为了在一定规模上实现高性能服务,可以在单个机器上对输入进行批处理并分配多个模型,从而并行执行推理过程。此外,Facebook 数据中心的大量服务器具有架构异构性,从不同的 SIMD 宽度到不同的缓存结构的实现。架构异质性为软硬件协同设计和优化提供了额外机会。(参见论文:《The Architectural Implications of Facebook’s DNN-based Personalized Recommendation》该文对 Facebook 神经推荐系统的体系结构进行了深入分析。)
并行计算
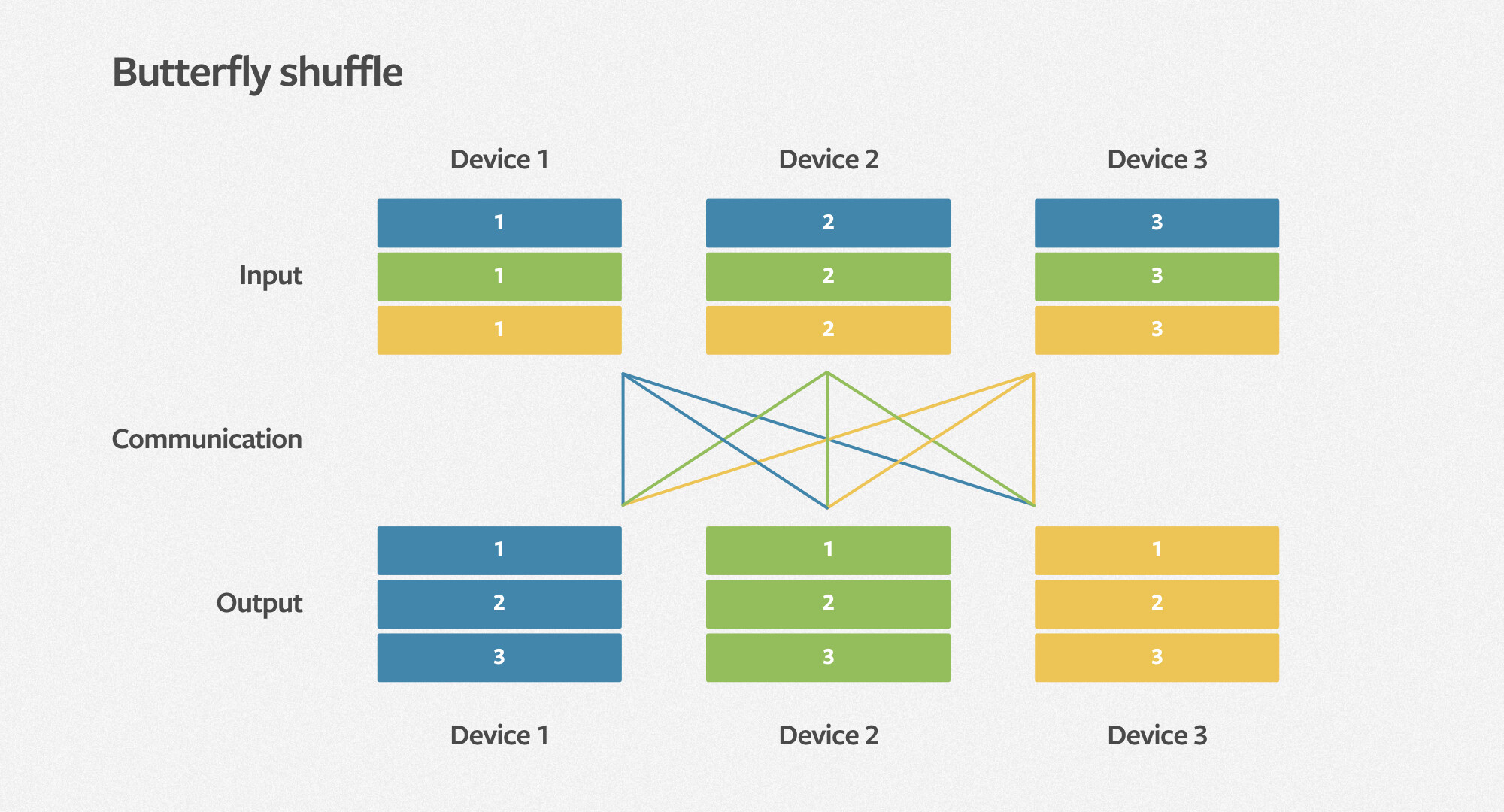
如图 1 所示,DLRM 基准由计算主导的 MLP 和内存容量有限的嵌入组成。因此,它自然需要依靠数据并行性来提升 MLP 的性能,并且依赖模型并行化来满足内嵌对内存容量的需求。DLRM 基准测试提供了一个遵循此方法的并行实现。在交互过程中,DLRM 需要一个高效的全通信原语,我们称之为蝴蝶式洗牌(butterfly shuffle)。它将每个设备上 minibatch 的嵌入查找结果重新洗牌,分配到所有设备上,成为 minibatch 嵌入查找的一部分。如下图所示,每种颜色表示 minibatch 的不同元素,每个数字表示设备及其分配的嵌入。我们计划优化系统,并在以后的博客中公布性能研究细节。
图 3 DLRM butterfly shuffle 示意图
建模与算法实验
DLRM 基准测试使用 Python 编写,支持灵活实现,模型结构、数据集和其他参数由命令行定义。DLRM 可用于推理和训练。在训练阶段,DLRM 将反向传播算子添加到计算图中,允许参数更新。
该代码是完整的,可以使用公开数据集,包括 Kaggle display advertising challenge 数据集。该数据集包含 13 种连续特征和 26 种类别特征,这些特征定义了 MLP 输入层的大小以及模型中使用的嵌入数量,而其他参数可以通过命令行定义。例如,根据如下命令行运行 DLRM 模型:
python dlrm_s_pytorch.py --arch-sparse-feature-size=16 --arch-mlp-bot="13-512-256-64-16" --arch-mlp-top="512-256-1" --data-generation=dataset --data-set=kaggle --processed-data-file=./input/kaggle_processed.npz --loss-function=bce --round-targets=True --learning-rate=0.1 --mini-batch-size=128 --print-freq=1024 --print-time
复制代码
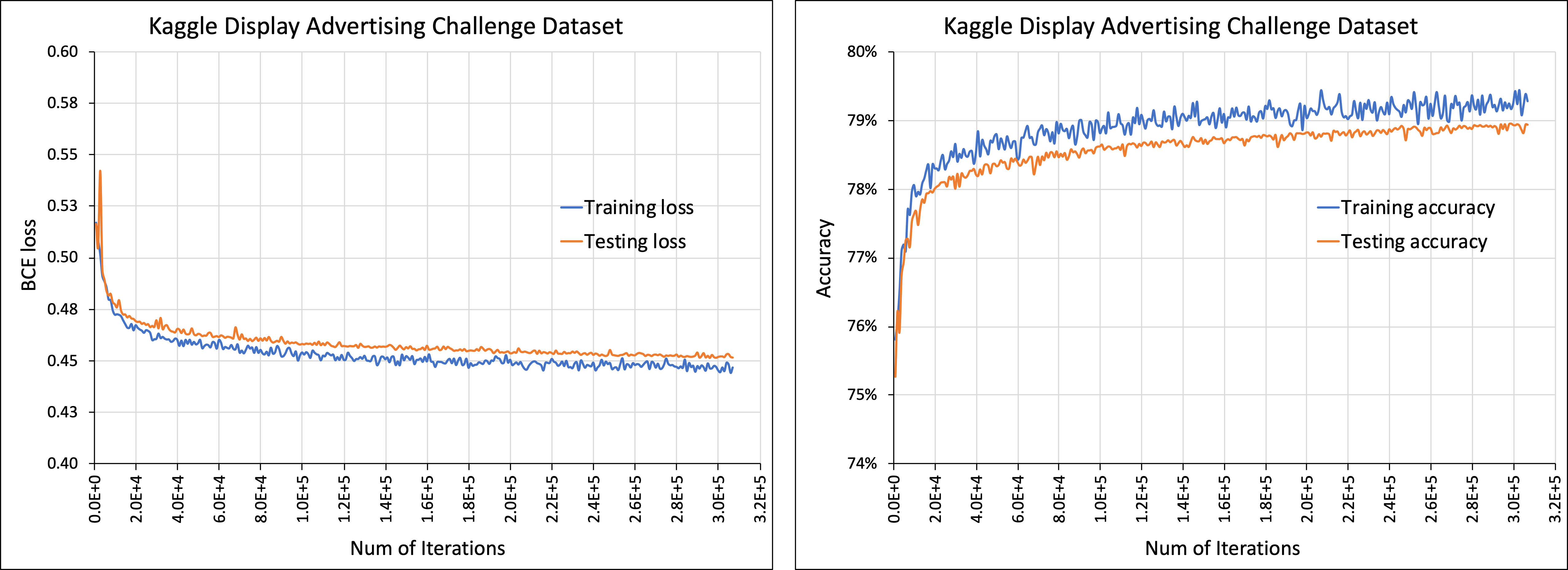
训练结果如下图所示 :
图 4 左图展示了在训练阶段和测试阶段的二值交叉熵损失,右图为训练阶段和测试阶段准确率
DLRM 模型可以在真实数据集上运行,可以帮助我们测量模型的准确率,这对于使用不同的数值技术和其他模型进行试验时尤其有用。我们计划在接下来的工作中对量化和算法实验对该模型的影响进行更深入的分析。
从长远来看,开发新的、更好的方法,将深度学习用于推荐和个性化工具(并提高模型的效率和性能),能够带来将人们与相关的内容联系起来的新方法。
DLRM 模型开源代码
DLRM 模型输入由稠密特征和稀疏特征组成。稠密特征为浮点数矢量,稀疏特征为嵌入表的稀疏索引。选择的矢量传入 MLP 网络(图中三角形),某些情况下矢量通过算子进行交互。
DLRM 实现
DLRM 模型有两个实现版本:
DLRM 数据生成和加载:
dlrm_data_pytorch.py, dlrm_data_caffe2.py, data_utils.py
复制代码
DLRM 测试命令(./test 路径下):
DLRM 基准模型(./bench 路径下):
dlrm_s_benchmark.sh, dlrm_s_criteo_kaggle.sh
复制代码
###训练
训练一个较小模型:
$ python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6time/loss/accuracy (if enabled):Finished training it 1/3 of epoch 0, -1.00 ms/it, loss 0.451893, accuracy 0.000%Finished training it 2/3 of epoch 0, -1.00 ms/it, loss 0.402002, accuracy 0.000%Finished training it 3/3 of epoch 0, -1.00 ms/it, loss 0.275460, accuracy 0.000%
复制代码
使用 Debug 模式训练:
$ python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6 --debug-modemodel arch:mlp top arch 3 layers, with input to output dimensions:[8 4 2 1]# of interactions8mlp bot arch 2 layers, with input to output dimensions:[4 3 2]# of features (sparse and dense)4dense feature size4sparse feature size2# of embeddings (= # of sparse features) 3, with dimensions 2x:[4 3 2]data (inputs and targets):mini-batch: 0[[0.69647 0.28614 0.22685 0.55131] [0.71947 0.42311 0.98076 0.68483]][[[1], [0, 1]], [[0], [1]], [[1], [0]]][[0.55679] [0.15896]]mini-batch: 1[[0.36179 0.22826 0.29371 0.63098] [0.0921 0.4337 0.43086 0.49369]][[[1], [0, 2, 3]], [[1], [1, 2]], [[1], [1]]][[0.15307] [0.69553]]mini-batch: 2[[0.60306 0.54507 0.34276 0.30412] [0.41702 0.6813 0.87546 0.51042]][[[2], [0, 1, 2]], [[1], [2]], [[1], [1]]][[0.31877] [0.69197]]initial parameters (weights and bias):[[ 0.05438 -0.11105] [ 0.42513 0.34167] [-0.1426 -0.45641] [-0.19523 -0.10181]][[ 0.23667 0.57199] [-0.16638 0.30316] [ 0.10759 0.22136]][[-0.49338 -0.14301] [-0.36649 -0.22139]][[0.51313 0.66662 0.10591 0.13089] [0.32198 0.66156 0.84651 0.55326] [0.85445 0.38484 0.31679 0.35426]][0.17108 0.82911 0.33867][[0.55237 0.57855 0.52153] [0.00269 0.98835 0.90534]][0.20764 0.29249][[0.52001 0.90191 0.98363 0.25754 0.56436 0.80697 0.39437 0.73107] [0.16107 0.6007 0.86586 0.98352 0.07937 0.42835 0.20454 0.45064] [0.54776 0.09333 0.29686 0.92758 0.569 0.45741 0.75353 0.74186] [0.04858 0.7087 0.83924 0.16594 0.781 0.28654 0.30647 0.66526]][0.11139 0.66487 0.88786 0.69631][[0.44033 0.43821 0.7651 0.56564] [0.0849 0.58267 0.81484 0.33707]][0.92758 0.75072][[0.57406 0.75164]][0.07915]DLRM_Net( (emb_l): ModuleList( (0): EmbeddingBag(4, 2, mode=sum) (1): EmbeddingBag(3, 2, mode=sum) (2): EmbeddingBag(2, 2, mode=sum) ) (bot_l): Sequential( (0): Linear(in_features=4, out_features=3, bias=True) (1): ReLU() (2): Linear(in_features=3, out_features=2, bias=True) (3): ReLU() ) (top_l): Sequential( (0): Linear(in_features=8, out_features=4, bias=True) (1): ReLU() (2): Linear(in_features=4, out_features=2, bias=True) (3): ReLU() (4): Linear(in_features=2, out_features=1, bias=True) (5): Sigmoid() ))time/loss/accuracy (if enabled):Finished training it 1/3 of epoch 0, -1.00 ms/it, loss 0.451893, accuracy 0.000%Finished training it 2/3 of epoch 0, -1.00 ms/it, loss 0.402002, accuracy 0.000%Finished training it 3/3 of epoch 0, -1.00 ms/it, loss 0.275460, accuracy 0.000%updated parameters (weights and bias):[[ 0.0543 -0.1112 ] [ 0.42513 0.34167] [-0.14283 -0.45679] [-0.19532 -0.10197]][[ 0.23667 0.57199] [-0.1666 0.30285] [ 0.10751 0.22124]][[-0.49338 -0.14301] [-0.36664 -0.22164]][[0.51313 0.66663 0.10591 0.1309 ] [0.32196 0.66154 0.84649 0.55324] [0.85444 0.38482 0.31677 0.35425]][0.17109 0.82907 0.33863][[0.55238 0.57857 0.52154] [0.00265 0.98825 0.90528]][0.20764 0.29244][[0.51996 0.90184 0.98368 0.25752 0.56436 0.807 0.39437 0.73107] [0.16096 0.60055 0.86596 0.98348 0.07938 0.42842 0.20453 0.45064] [0.5476 0.0931 0.29701 0.92752 0.56902 0.45752 0.75351 0.74187] [0.04849 0.70857 0.83933 0.1659 0.78101 0.2866 0.30646 0.66526]][0.11137 0.66482 0.88778 0.69627][[0.44029 0.43816 0.76502 0.56561] [0.08485 0.5826 0.81474 0.33702]][0.92754 0.75067][[0.57379 0.7514 ]][0.07908]
复制代码
测试
测试代码是否正常运行:
./test/dlrm_s_tests.shRunning commands ...python dlrm_s_pytorch.pypython dlrm_s_caffe2.pyChecking results ...diff test1 (no numeric values in the output = SUCCESS)diff test2 (no numeric values in the output = SUCCESS)diff test3 (no numeric values in the output = SUCCESS)diff test4 (no numeric values in the output = SUCCESS)
复制代码
基准模型
1.表现基准
./bench/dlrm_s_benchmark.sh
复制代码
2. 该模型支持 Kaggle 展示广告挑战数据集,数据集需完成如下准备工作:
指定原始数据文件: --raw-data-file=<path/train.txt>
预处理
处理数据存储在.npz 文件,路径为*<root_dir>/input/kaggle_data/*.npz
可以用处理文件运行:–processed-data-file=<path/.npz>
./bench/dlrm_s_criteo_kaggle.sh
复制代码
模型保存与加载
训练过程中模型保存:–save-model=<path/model.pt>。如果测试准确率有所提升,则保存模型。保存的模型可以通过–load-model=<path/model.pt>加载。模型加载后可以用于继续训练,也可以用于在测试数据集上测试,需要指定–inference-only。
环境要求
pytorch-nightly (6/10/19)
onnx (optional)
torchviz (optional)
查看博客原文:DLRM: An advanced, open source deep learning recommendation model
https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
DLRM 开源地址:https://github.com/facebookresearch/dlrm
DLRM 论文:Deep Learning Recommendation Model for Personalization and Recommendation Systems
https://arxiv.org/abs/1906.00091

















评论