
近日,Meta 在 GitHub 上开源了一款全新的 AI 语言模型—— Massively Multilingual Speech ( MMS,大规模多语种语音) ,它与 ChatGPT 有着很大的不同,这款新的语言模型可以识别 4000 多种口语并生成 1100 多种语音(文本到语音)。发布短短几天,该项目已经在 GitHub 库收获了 25.4k Star,Fork 数量高达 5.7k。
论文地址:https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
博客地址:https://ai.facebook.com/blog/multilingual-model-speech-recognition/
代码/模型:https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Meta 开源能识别 4000 多种语言的语音大模型
与大多数已公开发布的 AI 项目一样,Meta这次也毫无意外地将 MMS 项目开源出来,希望保护语言多样性并鼓励研究人员在此基础之上构建其他成果。Meta 公司写道,“我们公开分享这套模型和相关代码,以便研究领域的其他参与者能在我们的工作基础上进行构建。通过这项工作,我们希望为保护令人惊叹全球语言多样性做出一点贡献。”
语音识别和文本转语音模型往往需要使用数千小时的音频素材进行训练,同时附带转录标签。(标签对机器学习至关重要,使得算法能够正确分类并“理解”数据。)但对于那些在工业化国家并未广泛使用的语言——其中许多语言在未来几十年内甚至有消失的风险——Meta 提醒称“根本就不存在这样的数据”。
Meta AI 团队称,MMS项目最大的一个难点在于很多语言数据是缺失的。Meta AI 团队通过结合 wav2vec 2.0(该公司的“自监督语音表示学习”模型)和一个新数据集来克服其中一些挑战。其中一些语言,例如 Tatuyo 语言,只有几百人使用,而且对于其中的大多数语言,之前不存在语音技术。
Meta表示:“收集数千种语言的音频数据是我们的第一个挑战,因为现有最大的语音数据集最多涵盖 100 种语言。为了克服它,我们求助于圣经等宗教文本,这些文本已被翻译成多种不同的语言,并且其翻译已被广泛研究用于基于文本的语言翻译研究。这些翻译有公开的录音,记录了人们用不同语言阅读这些文本的情况。作为该项目的一部分,我们创建了 1100 多种语言的新约读物数据集,每种语言平均提供 32 小时的数据”。
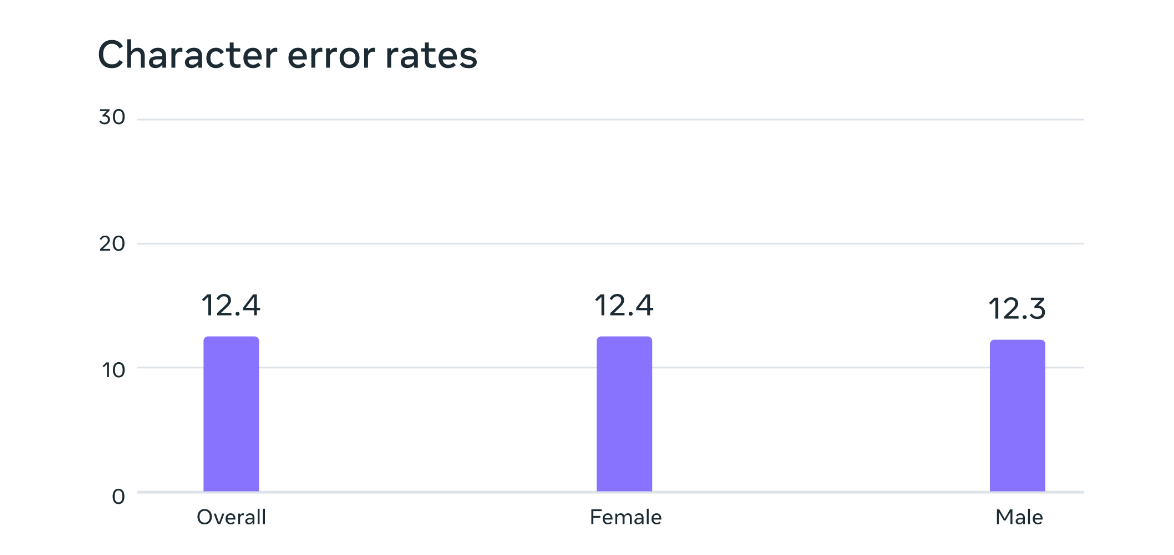
潜在的性别偏见分析。在 FLEURS 基准测试中,基于大规模多语言语音数据训练的自动语音识别模型对于男性和女性说话者具有相似的错误率。
乍看之下这种方法大有问题,因为此类训练思路似乎严重偏向宗教的世界观。但 Meta 表示情况并非如此,“虽然录音内容涉及宗教,但我们的分析表明,产出的模型并不会生成更多宗教语言。猜测这是因为我们使用了连接主义时间分类(CTC)方法,与语音识别类大语言模型(LLM)或序列到序列模型相比,前者受到的限制要大得多。”此外,尽管大多数宗教录音都是由男性朗读,但也不会引入男性偏见——模型在女性和男性单色中同样表现出色。
相比同类模型,MMS 单词错误率更低
在训练出能够使用这些数据的对齐模型之后,Meta 又引入 wav2vec 2.0,可通过未标注的数据进行训练。非常规数据源和自监督语音模型相结合,最终带来了令人印象深刻 的结果。“我们的结果表明,与现有模型相比,大规模多语言语音模型表现良好,覆盖的语言数量是现有模型的 10 倍。”具体来看,Meta 将 MMS 与 OpenAI 的 Whisper 进行比较,实际结果超出预期。“我们发现在 MMS 数据上训练的模型将单词错误降低了一半,而 MMS 涵盖的语种数量则增长至 11 倍。”
Meta 公司警告称,这套新模型并不完美。“例如,语音转文本模型在特定的单词或短语上可能存在一定的错误转录风险。根据输出结果,这可能会导致攻击性和/或不准确的表述。我们仍然相信,整个 AI 社区的协作对于负责任开发 AI 技术至关重要。”
考虑到 Meta 已经发布了这套开源研究的 MMS 模型,希望它能扭转因科技巨头的支持习惯而逐渐将全球使用语言缩减至 100 种以下的趋势。以此为契机,辅助技术、文本转语音(TTS)甚至 VR/AR 技术,也许将给每个人都塑造出能用母语表达和学习的世界。Meta 表示,“我们设想一个依靠技术带来相反效果的世界,鼓励人们保持自己母语的活力,通过自己最熟悉的语言获取信息、使用技术。”
Meta 的结果表明,大规模多语言语音模型优于现有模型,覆盖的语言数量是现有模型的 10 倍。Meta 通常专注于多语言:对于文本,NLLB 项目将多语言翻译扩展到 200 种语言,而 Massively Multilingual Speech 项目将语音技术扩展到更多语言。
Meta 表示该款大模型相比于 OpenAI 的同类产品单词错误率少了一半。
在与 OpenAI 的 Whisper 的同类比较中,我们发现在 Massively Multilingual Speech 数据上训练的模型实现了一半的单词错误率,但 Massively Multilingual Speech 涵盖的语言是其 11 倍。这表明与当前最好的语音模型相比,我们的模型可以表现得非常好。
Meta AI 在大语言模型路上越走越远
在硅谷这场愈演愈烈的 AI 大战中,一直 All in 元宇宙的 Meta 正在加速追赶OpenAI、谷歌、微软等大模型先行者们。
今年 2 月 24 日,在火遍全球的 ChatGPT 发布 3 个月后,Meta 在官网公布了一款新的人工智能大型语言模型LLaMA,从参数规模来看,Meta 提供有 70 亿、130 亿、330 亿和 650 亿四种参数规模的 LLaMA 模型,并用 20 种语言进行训练。
Meta 首席执行官马克·扎克伯格表示,LLaMA 模型旨在帮助研究人员推进工作,在生成文本、对话、总结书面材料、证明数学定理或预测蛋白质结构等更复杂的任务方面有很大的前景。
Meta 首席 AI 科学家杨立昆(Yann LeCun)表示,在一些基准测试中,LLaMA 130 亿参数规模的模型性能优于 OpenAI 推出的 GPT3,且能跑在单个 GPU 上;650 亿参数的 LLaMA 模型能够和 DeepMind 700 亿参数的 Chinchilla 模型、谷歌 5400 亿参数的 PaLM 模型竞争。
4 月 19 日,Meta 宣布开源DINOv2视觉大模型。据悉,DINOv2 是一最先进的计算机视觉自监督模型,可以在深度估计、语义分割和图像相似性比较等任务中实现 SOTA 级别的性能。该模型可以借助卫星图像生成不同大洲的森林高度,在医学成像和作物产量估算等领域具有潜在应用。
5 月 10 日,Meta 宣布开源可跨越六种感官的大模型ImageBind,新的 ImageBind 模型结合了文本、音频、视觉、运动、热和深度数据。该模型目前只是一个研究项目,展示了未来的人工智能模型如何能够生成多感官内容。通过利用多种类型的图像配对数据来学习单个共享表示空间。该研究不需要所有模态相互同时出现的数据集,相反利用到了图像的绑定属性,只要将每个模态的嵌入与图像嵌入对齐,就会实现所有模态的迅速对齐。
Meta 力求通过这样密集的发布向外界证明自己还一直跑在 AI 赛道中。
然而,在烧光了几十亿美元义无反顾押注元宇宙后,Meta 在 AI 方面的能力还是受到了外界的质疑。
在 Meta 公司今年 4 月的季度财报电话会议上,公司 CEO 扎克伯格明显相当被动。砸下数十亿美元、被寄予延续帝国辉煌厚望的元宇宙愿景还没来得及初试啼声,就被围绕人工智能(AI)掀起的汹涌狂潮抢了风头,刹那沦为明日黄花。
批评者们注意到就连 Meta 自己的底气也有所减弱,扎克伯格去年 11 月和今年 3 月两份声明间的口吻大为改变。之前扎克伯格强调这个项目属于“高优先级的增长领域”,而今年 3 月则转而表示“推进 AI”才是公司的“最大单一投资方向”。
但扎克伯格本人还是做出了澄清,表示“有人认为我们正以某种方式放弃对元宇宙愿景的关注,我想提前强调,这样的判断并不准确。”
“多年以来,我们一直专注于 AI 和元宇宙技术,未来也将继续双管齐下……构建元宇宙是个长期项目,但我们的基本思路将保持不变、努力方向也不会动摇。”
参考链接:
https://ai.facebook.com/blog/multilingual-model-speech-recognition/




