

文中内容并非是从理论上去探讨哪些问题可以通过机器学习解决,而是意在帮助那些没有数据科学家的团队理解应用机器学习是否真的有效。
机器学习当前处境微妙。
机器学习的可行性已得到充分证明,几乎所有最受欢迎的移动应用都或多或少使用了该项技术,从中可见一斑。但这一生态系统尚未完全成熟到任何一位初学者都可以迅速应用自如的程度。
对于团队而言,决定何时引入机器学习技术并非易事,尤其是对于缺少数据科学家的团队。尽管软件工程人员通常对机器学习具有更高层次的理解,但他们一般缺少领域知识,难以判定自己所面对的问题是否适用机器学习解决。
文中内容并非从理论上去探讨讲哪些问题可以通过机器学习解决,而是意在帮助那些没有数据科学家的团队理解应用机器学习是否会有效。
是否有其他人使用机器学习解决了类似的问题?
如果团队中没有任何经验丰富的机器学习工程师或数据科学家,那么是很难回答“是否有可能通过机器学习来解决某个问题?”
如果团队中缺少数据科学家,应该怎么办?
自身成为机器学习专家。这样你可以自己分析问题,判定机器学习解决方案的可行性。
聘用机器学习专家,完成上述工作。
调研是否有其他人用机器学习解决了类似的问题。
前两个选项耗精力耗财力,而后者可能只需花一天时间搜索一下。
相关调研的好处,就是有助于确定工作的着手点。鉴于团队中没有数据科学家,不太可能针对问题设计出适用的模型架构。例如,如果需要构建一个客户支持代理,那么可以去了解一下其他公司的做法。当然,你一定会涉及到 Rasa 和 Google Meena。
了解使用哪些模型和方法解决了类似的问题,有助于团队明确工作的着手点。例如,工程师 Robert Lucian 构建了一款得到广泛使用的个性化车牌读取器。Lucian 的解决方案就是依赖于一些已有的目标检测和文本提取模型。
Lucian 在在文章中提及,他只是调研了其他人在类似领域中正在使用的方法,进而着手实现了自己项目中的机器学习部分。他最终找到了那些专门针对车牌而调优的模型,及用于文本提取的有效模型。这样,他很快将两者加入到生产环境中。
是否具有相关的数据来源(无需考虑数据是否是自己的)?
除非你的问题使用原始预训练模型解决了,否则模型都需要使用相关数据进行训练。
例如,构建一个推荐系统引擎,需要用户资料属性以及浏览习惯等数据。而构建一款客户支持代理,则需要文档手册进行训练。为使模型适用于特定领域,需要使用相应领域数据进行训练。
但是,训练数据不必是自己具有的。即便并没有做复杂的用户数据收集,也可借助于一些公开可用的数据。
例如,数月前开始流行的文本类冒险游戏“AI Dungeon”,就是基于机器学习构建的。
尽管游戏开发工程师 Nick Walton 只通过从 choiceyourstory.com 上抓取 50 MB 的文本做模型调优,但该游戏仍可以与当前最先进的模型相媲美。其成功应归功于迁移学习,该技术将模型的“知识”(该游戏中使用了 OpenAI 的 GPT-2)迁移到新的模型,并使用很小的数据集对更特定领域做了调优,例如游戏中的地牢探索者的故事情景。
相对于其他解决方案而言,使用机器学习的成效是否显著?
在很多情况下,机器学习只是一种可工作的工具,但并非最优的工具。如果机器学习并不能提供比其它解决方案明显的优点,那么就不值得为此付出额外的开销。
对此问题的分析,可借助于下列几个基本考量:
首先,除机器学习外,是否还有其它解决方案?
对于语音识别、计算机视觉等许多应用,机器学习目前是最适用的解决方案。
其次, 其它解决方案是否能复现机器学习的预测质量?
例如,在建立一个推荐系统中,如果收集的用户数据不多,并且只有 100 条博客帖子可供推荐,那么使用基本的标签系统就完全可以。如果用户喜欢 Javascript,那么就向用户展示所有具有“Javascript”标签的文章:
但是,如果策划构建一个庞大的内容库,并且其中管理了大量的用户数据,那么机器学习对于实现个性化推荐的作用是独一无二的。
第三,其他解决方法是否具有机器学习那样的可扩展性?
机器学习的主要承诺之一,就是其灵活性足以消除那些传统上需要人工干预的流程中的人力参与。例如,库存管理是一个非常繁杂的工作,产品通常信息不完整,列出方式也不一致,导致经常需要手动处理。
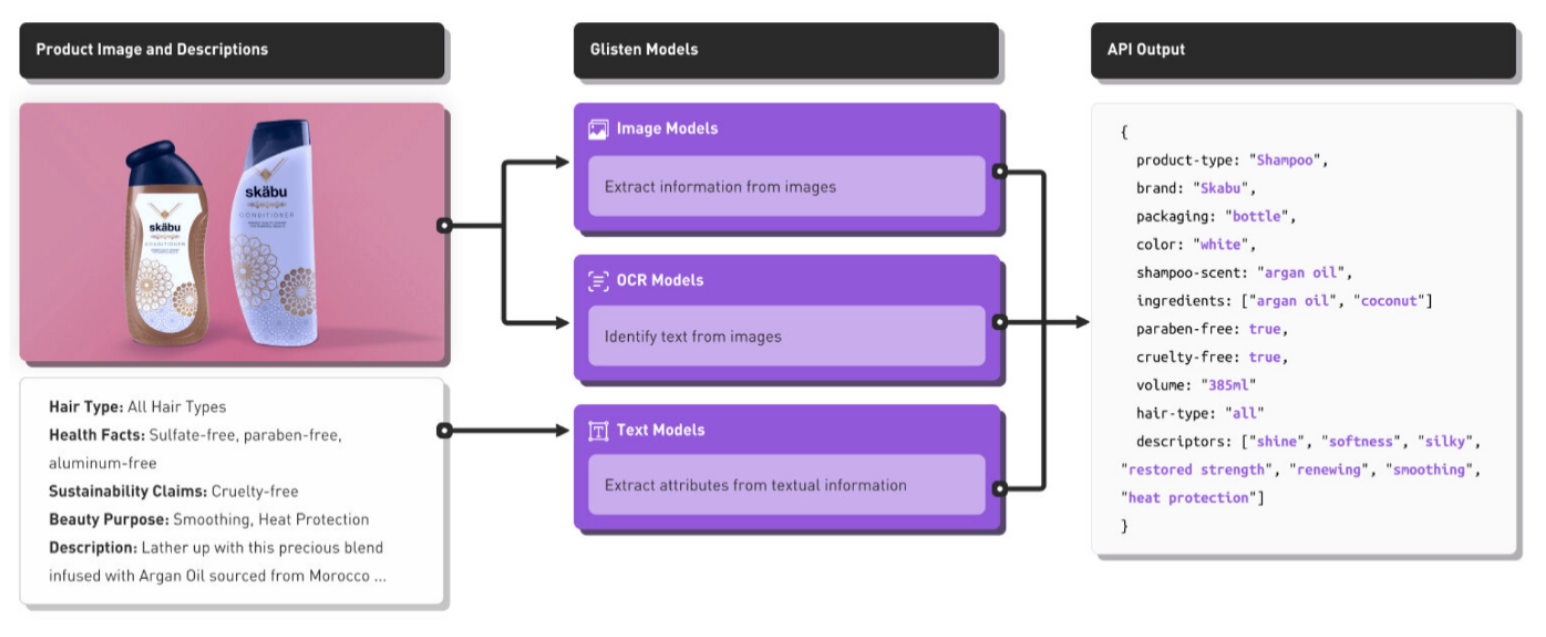
在产品数量不多的情况下,人工处理完全可以取代机器学习。但是对于大量的产品,人工做比对是不现实的。例如,处理一百万种产品,需要很多人花费大量时间。而 Glisten 等产品使用机器学习分析产品数据,可快速完成此类工作:
何时何处适用机器学习
事实上,尽管机器学习有着诸多优越性,但却往往应用在许多毫无意义的场景中。这导致许多人普遍对机器学习持怀疑态度,“不过又是一轮炒作而已”。
现实情况是,就像其它所有广为使用的技术一样,机器学习只是在某些情况下的理想解决方案,而并不适用于所有情况。项目上手时,最难的就是判定该项目是否需要使用机器学习,尤其是对于缺乏该领域经验的团队,希望本文能对正处于迷茫中的团队有所助益。
如果读者对如何在生产环境中使用机器学习感兴趣,欢迎访问 Cortex 示例代码库。
Cortex 项目地址:
https://github.com/cortexlabs/cortex/tree/master/examples
声明:本文内容基于作者本人对机器学习团队的观察,而非对整个行业的学术综述。作者背景是 Cortex 的贡献者之一。Cortex 是一款用于机器学习模型在生产环境部署的开源平台。
原文链接:
https://towardsdatascience.com/should-you-really-use-machine-learning-for-that-d781a80aa0fb

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论