博文如何使用 Amazon Aurora PostgreSQL 设置单个读写 pgpool 终端节点介绍了使用 Amazon Aurora PostgreSQL 终端节点的读写分离功能的一种架构。这种架构非常适合 Aurora PostgreSQL 集群,但如果您使用 Amazon Aurora MySQL 集群,应该如何进行? 本文对原始博文进行了补充,通过引入 ProxySQL,作为 Aurora MySQL 终端节点读写分离的中间层。
Amazon Aurora 为主数据库实例(集群终端节点)和只读副本(读取终端节点)提供 终端节点。Aurora 自动更新集群终端节点,以便能够始终指向主实例。它使用读取终端节点对所有可用只读副本间的读取操作连接进行 DNS 轮询调度。此外,您还可以使用 Amazon Aurora 自定义终端节点进一步划分您的应用程序流量。
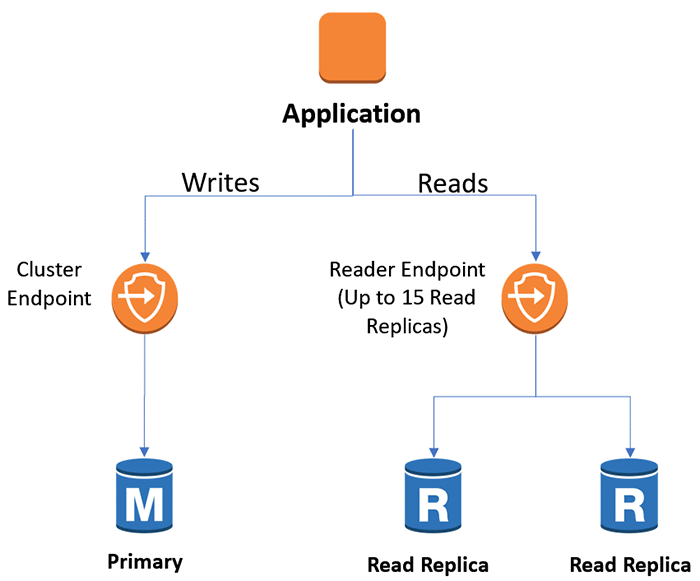
Amazon Aurora 只读副本通常有不到 100 ms 的复制延迟。因此,如果您的应用程序可以忍受此延迟,可以通过同时使用集群和读取终端节点来水平扩展数据库,如下所示。
上述图示显示的架构,描述了应用程序如何抉择使用哪种终端节点。然而,管理两个数据库终端节点(一个用于读取,一个用于写入)增加了应用程序的复杂性。虽然有些第三方驱动程序能对范围有限的应用场景提供支持,但您仍可以将本文中的架构方法更广泛地应用于读写分离的应用场景中。
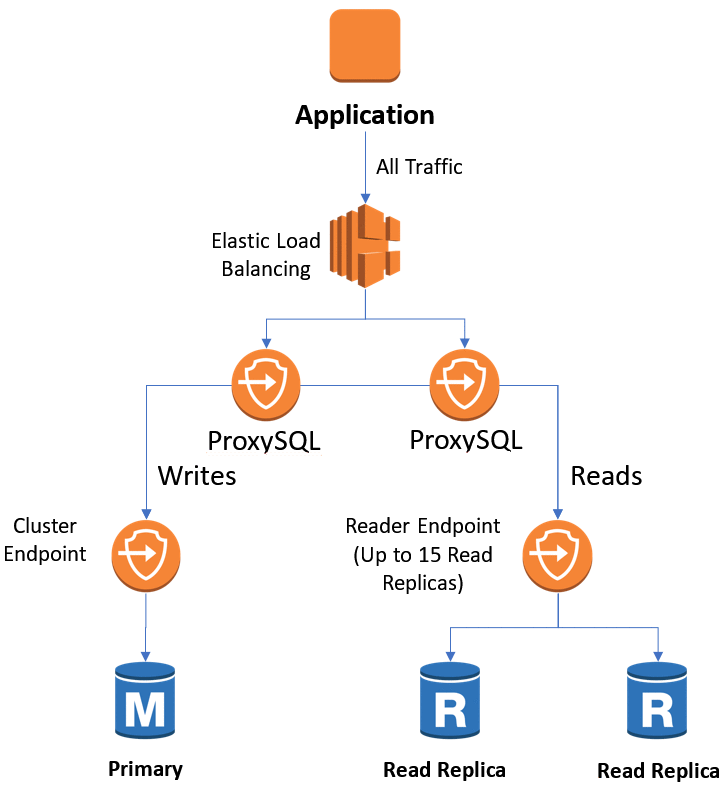
在本文中,我们将向您演示如何使用 ProxySQL 提供兼容 MySQL 的单一 Aurora 终端节点,从而将写入流量自动导向集群终端节点,将读取流量自动导向读取终端节点。下述图示显示了基于 ProxySQL 中间件的解决方案。
架构
ProxySQL 是一种基于 GNU 通用公共许可证 (GPL) 并位于 MySQL 数据库与数据库客户端之间的数据库访问代理中间件。在本示例中,我们使用下图中的架构进行部署。
上述图示显示了如何将 ProxySQL 用作中间件来向兼容 MySQL 的 Aurora 集群提供单一终端节点。Aurora 集群包括一个主要实例和两个 Aurora 只读副本,它们部署在两个可用区和两个私有子网中。该集群有一个安全组,该安全组只允许来自 ProxySQL 实例的传入数据。
ProxySQL 部署在 Auto Scaling 组中的网络负载均衡器之后,其中包括一个用于故障转移的活动实例(在此博文中用于演示目的)。您可以按下面所示更新 master.yaml 文件(在 Resources.ProxySQLStack.Properties.Parameters 下),以更改此配置:
MinSize: 2MaxSize: 4DesiredCapacity: 2
复制代码
此配置更改将预置两个 ProxySQL 实例用于常规负载,并且在峰值负载期间最多可以有四个实例。同时,这能在其中一个 ProxySQL 节点发生中断时提高数据库的可用性。
ProxySQL 还被隔离在具有一个安全组的私有子网中,只允许从允许的无类别域际路由 (CIDR) 数据块中访问。
访问子网托管了一个为 ProxySQL 提供一致性终端节点的网络负载均衡器。因此,如果 ProxySQL 实例故障且 Auto Scaling 组创建了一个新实例,您的数据库终端节点不会改变。
使用 AWS CloudFormation 进行部署
本示例中使用的 AWS CloudFormation 模板位于此 GitHub 存储库中。该示例使用几个嵌套 AWS CloudFormation 模板部署 Virtual Private Cloud (VPC) 基础设施、安全组、Aurora 集群和 ProxySQL 中间件。使用嵌套堆栈可使您将大型堆栈分解为几个可重复使用的组件。如果您不熟悉 AWS CloudFormation,请查看 AWS CloudFormation 文档。
有关部署模板的完整说明,请参阅 GitHub 上的 README 文件。下面的章节包含一些重点内容。
创建 Amazon Aurora 集群
下面的 AWS CloudFormation 代码段演示了如何在 VPC 基础设施和安全组准备就绪时创建三个节点的 Amazon Aurora 集群。Amazon Aurora 将一个节点设为主要节点,另两个节点设为只读副本。
DBAuroraCluster: Type: "AWS::RDS::DBCluster" Properties: DatabaseName: !Ref DatabaseName Engine: aurora-mysql MasterUsername: !Ref DatabaseUser MasterUserPassword: !Ref DatabasePassword VpcSecurityGroupIds: - !Ref DBFirewall Tags: - Key: Project Value: !Ref ProjectTag DBAuroraOne: Type : "AWS::RDS::DBInstance" Properties: DBClusterIdentifier: !Ref DBAuroraCluster Engine: aurora-mysql DBInstanceClass: !Ref DbInstanceSize Tags: - Key: Project Value: !Ref ProjectTag DBAuroraTwo: Type : "AWS::RDS::DBInstance" Properties: DBClusterIdentifier: !Ref DBAuroraCluster Engine: aurora-mysql DBInstanceClass: !Ref DbInstanceSize Tags: - Key: Project Value: !Ref ProjectTag DBAuroraThree: Type : "AWS::RDS::DBInstance" Properties: DBClusterIdentifier: !Ref DBAuroraCluster Engine: aurora-mysql DBInstanceClass: !Ref DbInstanceSize Tags: - Key: Project Value: !Ref ProjectTag
复制代码
部署 ProxySQL
在部署 ProxySQL 的 AWS CloudFormation 模板中,设置一个 ELB 负载均衡器和一个 Auto Scaling 组。Auto Scaling 组的启动配置使用 AWS CloudFormation cfn-init 工具部署和配置 ProxySQL。
在此解决方案中,我们为每个 Amazon EC2 实例使用 Amazon Linux AMI。Amazon Linux AMI 包括提供与 AWS 的无缝集成的软件包和配置。存储库在所有 AWS 区域可用,您可以使用 yum 访问它们。在每个区域中托管存储库可使您快速部署更新,且无需支付任何数据传输费用。如果您希望详细了解更新 EC2 实例软件的信息,请参阅 Amazon Elastic Compute Cloud 用户指南中的更新实例软件。
首先,您需要安装 MySQL 客户端:
sudo yum install -y mysql
复制代码
接下来,下载 ProxySQL:
wget -P /tmp/ https://github.com/sysown/proxysql/releases/download/v2.0.0-rc2/proxysql-rc2-2.0.0-1-centos7.x86_64.rpm
复制代码
然后,安装 ProxySQL:
#Install proxysqlsudo yum install -y /tmp/proxysql-rc2-2.0.0-1-centos7.x86_64.rpm
复制代码
最后,启动 ProxySQL:
sudo service proxysql start
复制代码
配置 ProxySQL
通过使用管理员凭证进行本地连接,您可以用 MySQL 客户端执行大多数 ProxySQL 配置。ProxySQL 的默认用户名和密码如下:
“admin”和“admin”
我们强烈建议您在初始配置后更改这些凭证。
下面的命令用于在 ProxySQL 中配置初始的读写拆分选项:
mysql -u admin -padmin -h 127.0.0.1 -P6032 main < proxysql.sql
复制代码
虽然 proxysql.sql 文件中包含的选项适合快速拆分读写流量,但您还可以在 ProxySQL 中配置更复杂的查询路由规则。下面对 proxysql.sql 文件的内容进行说明。
首先,确保 mysql_servers 和 mysql_replication_hostgroups 表清理干净,便于您进行配置。mysql_servers 表包含将由 ProxySQL 代理的所有后端终端节点的条目。mysql_replication_hostgroups 表包含自己识别和划分只读终端节点的配置。
在版本 2 之前,ProxySQL 检查“read_only”变量以从写入终端节点确定读取终端节点,而 Amazon Aurora 则是基于“innodb_read_only”变量来定义读取与写入。ProxySQL 版本 2.0 使用 mysql_replication_hotgroups 表中的 check_type列增加了对变量定义自定义规范的支持。
delete from mysql_servers where hostgroup_id in (10,20);delete from mysql_replication_hostgroups where writer_hostgroup=10;
复制代码
接下来,在 mysql_servers 表中配置您的终端节点:
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('${ClusterEndpoint}',10,3306,1000,2000);INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('${ReaderEndpoint}',20,3306,1000,2000);
复制代码
然后,配置 mysql_replication_hostgroups 表以使用“innodb_read_only”的 check_type 值定义写入和读取托管组:
INSERT INTO mysql_replication_hostgroups (writer_hostgroup,reader_hostgroup,comment,check_type) VALUES (10,20,'aws-aurora','innodb_read_only');
复制代码
在此将配置写回磁盘中,以便它在 ProxySQL 服务重启时仍然存在:
LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;
复制代码
接下来,确保 mysql_query_rules 表清理干净,可供您配置:
delete from mysql_query_rules where rule_id in (50,51);
复制代码
然后,根据您的需求定义查询路由规则。您可以定义规则,以支持各种使用案例,包括分区、基于摘要或基于读/写拆分。本示例所示为基本的读/写拆分场景配置:
INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (50,1,'^SELECT.*FOR UPDATE$',10,1), (51,1,'^SELECT',20,1);
复制代码
前面两个规则配置将进入写入器主机组的所有写入流量及将进入读取器的所有读取流量。
再次将配置写回磁盘中,以便它在 ProxySQL 服务重启时仍然存在:
LOAD MYSQL QUERY RULES TO RUNTIME; SAVE MYSQL QUERY RULES TO DISK;
复制代码
接下来,确保 mysql_users 表清理干净,可供您配置:
delete from mysql_users where username='${DatabaseUser}';
复制代码
接下来,在 ProxySQL 配置中定义您的后端用户:
insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('${DatabaseUser}','${DatabasePassword}',1,10,'${DatabaseName}',1);
复制代码
再次将配置写回磁盘中,以便它在 ProxySQL 服务重启时仍然存在:
LOAD MYSQL USERS TO RUNTIME; SAVE MYSQL USERS TO DISK;
复制代码
接下来,在 ProxySQL 中配置监测用户。此用户用于后端监测,且需要使用和复制客户端权限:
UPDATE global_variables SET variable_value='${DatabaseUser}' WHERE variable_name='mysql-monitor_username';UPDATE global_variables SET variable_value='${DatabasePassword}' WHERE variable_name='mysql-monitor_password';
复制代码
然后,配置后端 MySQL 版本并调整一些监测间隔:
UPDATE global_variables SET variable_value='${BackendMySQLVersion}' WHERE variable_name='mysql-server_version';UPDATE global_variables SET variable_value='2000' WHERE variable_name IN ('mysql-monitor_connect_interval','mysql-monitor_ping_interval','mysql-monitor_read_only_interval');
复制代码
再次将配置写回磁盘中,以便它在 ProxySQL 服务重启时仍然存在:
LOAD MYSQL VARIABLES TO RUNTIME;SAVE MYSQL VARIABLES TO DISK;
复制代码
您应提供以下变量到 proxysql.sql 文件中进行设置:
| 变量 | 值 | 注释 |
|---|
| ClusterEndpoint | Aurora 集群终端节点 | 它也是 ProxySQL 写入器主机。 |
| ReaderEndpoint | Aurora 读取终端节点 | 它也是 ProxySQL 读取器主机。 |
| DatabaseUser | Aurora 数据库用户 | 它也被用作集群的监测用户。您可以用自定义用户替代它。如果您创建自定义用户进行监测,请务必更新 proxysql.sql 配置文件。 |
| DatabasePassword | Aurora 数据库密码 | 它也被用作集群监测用户的密码。如果您创建自定义用户进行监测,请务必更新 proxysql.sql 配置文件中的相应密码。 |
| DatabaseName | Aurora 数据库名称 | |
| BackendMySQLVersion | Amazon Aurora 数据库 MySQL 版本 | 它是 ProxySQL 返回到您的消费应用程序的版本。确保将此设置为与后端相同的版本。ProxySQL 版本 2.0 的默认设置为 5.5.30。 |
另请注意,ProxySQL 提供的用于客户端连接的默认端口和接口如下:
0.0.0.0:6033 # 如果更改,需要重新启动服务。
复制代码
下面的 ProxySQL 的管理的默认设置:
测试配置
现在,您可以发布几个 SQL 语句,并确认 ProxySQL 正在按预期引导流量。
首先创建一个表并插入几行内容:
CREATE TABLE Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255));
INSERT INTO Persons (PersonID, LastName, FirstName, Address, City)VALUES (1, 'Doe', 'John', '123 Main Street', 'North York');INSERT INTO Persons (PersonID, LastName, FirstName, Address, City)VALUES (2, 'Doe', 'Jane', '456 Second Street', 'Toronto');INSERT INTO Persons (PersonID, LastName, FirstName, Address, City)VALUES (3, 'Smith', 'Robert', '789 Third Street', 'Vaughan');
复制代码
在 ProxySQL 统计数据架构中进行检查时,您可以看到,这些语句被导向至 Amazon Aurora 主要主机组(主机组 10):
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "select hostgroup, schemaname, username, digest, digest_text, count_star from stats_mysql_query_digest;"
复制代码
| hostgroup | schemaname | username | digest | digest_text | count_star |
|---|
| 10 | proxysqlexample | proxysqluser | 0xCF52DCD38A9B9942 | CREATE TABLE Persons ( PersonID int, LastName varchar(?), FirstName varchar(?), Address varchar(?), City varchar(?) ) | 1 |
| 10 | proxysqlexample | proxysqluser | 0xE7B5E8C714313F56 | INSERT INTO Persons (PersonID, LastName, FirstName, Address, City) VALUES (?, ?, ?, ?, ?) | 3 |
接下来,发布查询:
在 ProxySQL 统计数据架构中进行检查时,您可以看到,该语句被导向至 Amazon Aurora 读取终端节点(主机组 20):
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "select hostgroup, schemaname, username, digest, digest_text, count_star from stats_mysql_query_digest;"
复制代码
| hostgroup | schemaname | username | digest | digest_text | count_star |
|---|
| 10 | proxysqlexample | proxysqluser | 0xCF52DCD38A9B9942 | CREATE TABLE Persons ( PersonID int, LastName varchar(?), FirstName varchar(?), Address varchar(?), City varchar(?) ) | 1 |
| 10 | proxysqlexample | proxysqluser | 0xE7B5E8C714313F56 | INSERT INTO Persons (PersonID, LastName, FirstName, Address, City) VALUES (?, ?, ?, ?, ?) | 3 |
| 20 | proxysqlexample | proxysqluser | 0xDEB542EDC426A35F | select * from Persons | 1 |
在最终测试中,确认 ProxySQL 可处理嵌入在事务中的 SELECT 语句:
BEGIN; INSERT INTO Persons (PersonID, LastName, FirstName, Address, City)VALUES (4, 'Garg', 'Raj', '234 Fourth Street', 'North York');
INSERT INTO Persons (PersonID, LastName, FirstName, Address, City)VALUES (5, 'Doe', 'John', '373 Fifth Street', 'Brampton'); SELECT * from Persons where PersonID > 3;COMMIT;
复制代码
当嵌入的 SELECT 查询写入到事务中的各行时,这些语句全部都应触及主节点。您可以从日志中再次看到,一切都如期进行。
mysql -u admin -padmin -h 127.0.0.1 -P6032 -e "select hostgroup, schemaname, username, digest, digest_text, count_star from stats_mysql_query_digest;"
复制代码
| hostgroup | schemaname | username | digest | digest_text | count_star |
|---|
| 10 | proxysqlexample | proxysqluser | 0xCF52DCD38A9B9942 | CREATE TABLE Persons ( PersonID int, LastName varchar(?), FirstName varchar(?), Address varchar(?), City varchar(?) ) | 1 |
| 10 | proxysqlexample | proxysqluser | 0xE7B5E8C714313F56 | INSERT INTO Persons (PersonID, LastName, FirstName, Address, City) VALUES (?, ?, ?, ?, ?) | 5 |
| 20 | proxysqlexample | proxysqluser | 0xDEB542EDC426A35F | select * from Persons | 1 |
| 10 | proxysqlexample | proxysqluser | 0xFAD1519E4760CBDE | BEGIN | 1 |
| 10 | proxysqlexample | proxysqluser | 0x379FAD0823D3FF7B | SELECT * from Persons where PersonID > ? | 1 |
我们建议您在将此配置用于生产时使用您自己的数据库客户端执行完整的回归测试。如果 ProxySQL 中间件的可扩展性让您感到担忧,请考虑使用 ProxySQL 集群实例,Auto Scaling 组允许该实例中存在多个实例并且会根据负载进行扩展。
摘要:追求简单
在此博文中,您已了解如何使用 ProxySQL 为 Amazon Aurora 集群提供单一终端节点,以将读取流量自动导向至读取终端节点。您可以使用此方法简化您的应用程序处理至 Amazon Aurora 的连接的方法。
如果您需要更多高级路由选项,如基于自定义逻辑路由数据库连接的能力,您可以进一步详细了解 ProxySQL 的查询路由功能。使用自定义逻辑,您可以处理更高级的路由,如发送一小部分查询到更新的架构中进行金丝雀测试或基于权重的路由。
未来,请关注 Amazon Aurora Serverless,该服务可自动扩展数据库后端,无需配置只读副本。
作译者简介
Tulsi Garg 是 AWS 全球公共部门加拿大团队的高级解决方案架构师。他与加拿大公共部门客户(政府、非盈利组织、初创公司和教育机构)合作,帮助加快他们的云迁移之旅。他对 IoT 充满热情,常以女儿而接口购买科技玩具。
https://aws.amazon.com/cn/blogs/china/tag/Diego Magalhaes/">Diego Magalhaes
Diego Magalhães 是 AWS 全球公共部门的高级解决方案架构师,他与全加拿大的教育客户展开合作。他总是在寻找新的挑战,最近一次的挑战是以巴西清朗的天气换得多伦多寒冷的冬天。☃️
陈昊
AWS 合作伙伴解决方案架构师,致力于帮助合作伙伴构建更高效的 AWS 云服务解决方案。加入 AWS 之前曾就职于 Oracle,在企业应用架构设计及建设方面具有丰富的经验。
本文转载自 AWS 技术博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/how-to-use-proxysql-with-open-source-platforms-to-split-sql-reads-and-writes-on-amazon-aurora-clusters/


















评论