

TensorFlow 和 Apache Spark 的互操作问题是现实世界机器学习场景中常见的挑战。可以说,TensorFlow 是市场上最流行的深度学习框架,而 Apache Spark 仍然是被广泛采用的数据计算平台之一,从大型企业到初创公司都能见到它们的身影。很自然会有公司尝试将这两者结合起来。虽然有一些框架能够让 TensorFlow 适应 Spark,但互操作性挑战的根源性往往在于数据级别上。TFRecord 是 TensorFlow 的原生数据结构,在 Apache Spark 中并不完全受支持。最近,LinkedIn 工程师开源了 Spark-TFRecord,这是一个基于 TensorFlow TFRecord 的 Spark 新的原生数据源。
LinkedIn 决定着手解决这一问题,并不令人感到惊讶。这家互联网巨头长期以来一直是 Spark 技术的广泛采用者,并且也一直是 TensorFlow 和机器学习开源社区的积极贡献者。在内部,LinkedIn 工程团队经常尝试在 TensorFlow 的原生 TFRecord 格式和 Spark 的内部格式(如 Avro 或 Parquet)之间实现转换。Spark-TFRecord 项目的目标就是在 Spark 管道中提供 TFRecord 结构的原生功能。
先前的尝试
Spark-TFRecord 并非第一个尝试解决 Spark 和 TensorFlow 之间的数据互操作性挑战的项目。这一方面最受欢迎的项目是 Spark 的创建者 Databricks 推广的 Spark-Tensorflow-Connector。我们已经多次使用过 Spark-TensorFlow-Connector,并取得了不同程度的成功。从架构上讲,连接器是 TFRecord 格式到 Spark SQL DataFrames 的一种改编。了解了这一点,Spark-TensorFlow-Connector 在关系数据访问场景中工作非常有效,但在其他用例中却仍然非常有限,也就不足为奇了。
如果你仔细想想,TensorFlow 工作流的一个重要部分与磁盘 I/O 操作相关,而不是与数据库访问相关。在这些场景中,开发人员在使用 Spark-TensorFlow-Connector 时仍然需要编写相当多的代码。此外,当前版本的 Spark-TensorFlow-Connector 仍然缺少一些重要的功能,比如在 TensorFlow 计算中经常用到的 PartitionBy。最后,这个连接器更像是处理 Spark SQL Data Frames 中的 TensorFlow 记录的桥梁,而不是原生文件格式。
考虑到这些限制,LinkedIn 工程团队决定从一个略微不同的角度来解决 Spark-TensorFlow 的互操作性挑战。
Spark-TFRecord
Spark-TFRecord 是 Apache Spark 的原生 TensorFlow TFRecord。具体来说,Spark-TFRecord 提供了从 Apache Spark 读取 TFRecord 数据或向 Apache Spark 写入 TFRecord 数据的例程。与构建连接器来处理 TFRecord 结构不同的是,Spark-TFRecord 构建为原生 Spark 数据集,就像 Avro、JSON 或者 Parquet 一样。这意味着在 Spark-TFRecord 中,Spark 所有的 DataSet 和 DataFrame I/O 例程都是自动可用的。
一个值得探讨的明显问题是,为什么要构建一个新的数据结构,而不是简单地对开源 Spark-TensorFlow-Connector 进行版本控制呢?嗯,看起来,要使连接器适应磁盘 I/O 操作,需要从根本上进行重新设计。
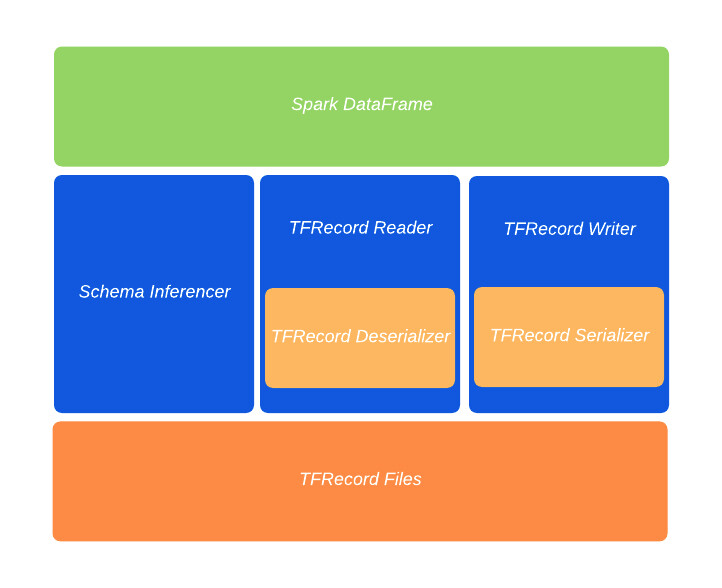
LinkedIn 工程团队没有遵循这条路线,而是决定实现一个新的 Spark FileFormat 接口,该接口从根本上来说,是为了支持磁盘 I/O 操作而设计的。新街口将使 TFRecord 原生操作适应任何 Spark DataFrame。从架构上看,Spark-TFRecord 由一系列基本构建块组成,这些构建块抽象出了读/写和序列化/反序列化例程:
Schema Inferencer:这是离 Spark-TensorFlow-Connector 最近的组件。
TFRecord Reader:该组件读取 TFRecord 结构并将其传递给 TFRecord Deserializer。
TFRecord Writer:该组件从 TFRecord Serializer 接收 TFRecord 结构并将其写入磁盘。
TFRecord Deserializer:该组件将 TFRecord 转换为 Spark InternalRow 结构。
使用 LinkedIn 的 Spark-TFRecord 与其他 Spark 远程数据集并没有什么不同。开发人员只需包含 spark-tfrecord jar 库,并使用传统的 DataFrame API 读写 TFRecord 即可,如下代码所示:
对大多数组织来说,Spark 和 TensorFlow 这样的深度学习框架之间的互操作性可能仍然是一个具有挑战性的领域。然而,像 LinkedIn 的 Spark-TFRecord 这样经过大规模测试的项目,无疑有助于简化这两种技术之间的桥梁,而这两种技术对现代机器学习架构来说都是必不可少的。
作者介绍:
Jesus Rodriguez,Invector Labs 首席科学家、执行合伙人,在 IntoTheBlock 任 CTO。同时也是天使投资人、作家、多家软件公司董事会成员。
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论