

背景和介绍
现在深度学习已经广泛应用到了各种 CTR 预估模型中,但是大都数模型的输入只是 concat 不同的特征,而忽视了用户历史行为本身的序列特征。比如一个用户很有可能买了苹果手机后,会买手机套,买了裤子之后会选择继续买个配套的鞋子。而之前一些模型比如 wide&deep,就没有利用用户行为历史序列中的 order information。DIN 模型使用注意力机制来捕获目标商品与用户先前行为序列中商品之间的相似性,但仍然未考虑用户行为序列背后的序列性质。
因此为了解决上述问题,本文尝试将 NLP 领域中大放异彩的 Transformer 模型来做推荐任务。具体:使用 self-attention 模块来学习用户行为历史序列中各个 item 的序列信息。
模型
问题建模:给定一个用户 u 的行为序列:S(u) = {v1,v2, …,vn },学习一个函数 F 用于预测用户 u 点击 item vt 的概率。其它特征包括:user profile, context, item 和 cross features,如下图所示

模型结构:
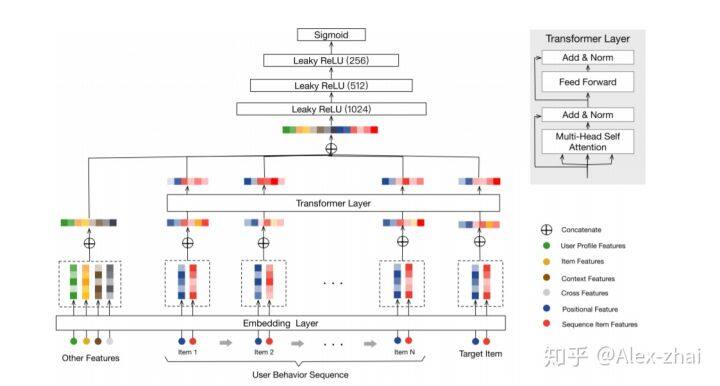
1.Embedding Layer:左侧部分通过 embedding 层将所有的 other features 映射成固定维度的向量,然后 concat 起来。另外,该模型也将行为序列中的每个 Item(包括目标 Item)通过相同的 embedding 层映射成低维度的向量。这里需要注意的是,每个 Item 通过两部分来表示:“序列 item 特征”(红色部分)和“位置特征”(深蓝色),其中,“序列 item 特征”包括 item_id 和 category_id(item 通过包括上百个特征,但是 item-id 和 category_id 两个特征对于 performance 来说就已经够了)。位置特征用来刻画用户历史行为序列中的顺序信息,文中将“位置”作为中每个 item 的另一个输入特征,然后将其投射为低维向量。第 i 个位置的位置特征计算方式为 pos(vi)=t(vt)-t(vi),其中,t(vt) 表示推荐的时间戳,t(vi) 表示用户点击商品 vi 时的时间戳。
2.Transformer layer:对于每个 item 抽取了一个更深层次的 representation,用于捕捉该 item 和历史行为序列中的其他 item 的关系。
Self-attention:Transformer 层中的 multi-head attention 模块输出:
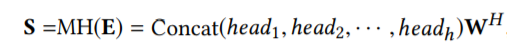
其中 headi 为:
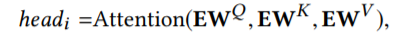
self-attention 的计算公式为:
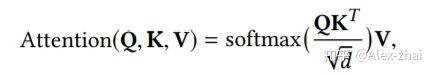
Point-wise Feed-Forward Network:目的是增加非线性。在 self-attention 和 FFN 中都使用了 dropout 和 LeakyReLU,最终 self-attention 和 FFN 的输出为:
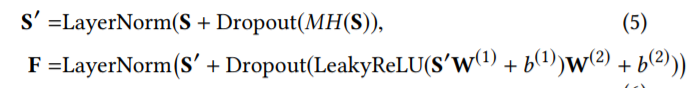
Stacking the self-attention block:上面的两步操作被称为一个 self-attention 单元。为了抽取出 item 序列中更加复杂的潜在关联特征,该模型堆叠了几层 self-attention 单元:
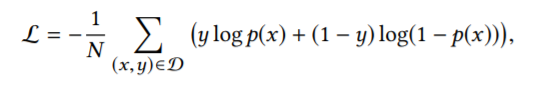
MLP layers and Loss function: 将所有的 embedding 进行拼接,输入到三层的神经网络中,并最终通过 sigmoid 函数转换为 0-1 之间的值,代表用户点击目标商品的概率。loss 函数:
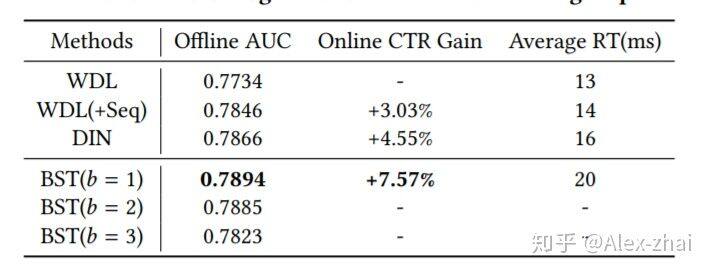
实验结果
其中,b 表示 Transformer 的 block 堆叠的层数,论文里实验了 1 层、2 层和 3 层的效果,最终 1 层的效果最好。
总结
DIN、DIEN、DSIN 和本文 BST 模型的区别和联系
DIN 模型使用注意力机制来捕获目标商品与用户先前行为序列中商品之间的相似性,但是未考虑用户行为序列背后的序列性质,并且未捕捉用户兴趣的动态变化性。
DIEN 主要解决 DIN 无法捕捉用户兴趣的动态变化性的缺点,提出了兴趣抽取层 Interest Extractor Layer、兴趣进化层 Interest Evolution Layer。
DSIN 针对 DIN 和 DIEN 没考虑用户历史行为中的会话信息,因为在每个会话中的行为是相近的,而在不同会话之间差别是很大的。DSIN 主要是在 session 层面上来利用用户的历史行为序列信息。
BST 模型通过 Transformer 模型来捕捉用户历史序列中各个 item 的关联特征,并且通过加入待推荐的商品 item,也可抽取出行为序列中商品与待推荐商品之间的相关性。
参考文献:
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
https://www.jianshu.com/p/caa2d87cb78c
Deep Interest Network for Click-Through Rate Prediction
Deep Interest Evolution Network for Click-Through Rate Prediction
Deep Session Interest Network for Click-Through Rate Prediction
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/72018969

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论