

1 背景
随着互联网和人工智能技术的不断发展,智能营销已经慢慢渗透到各个行业,相对应的智能营销手段也越来越普及,在贝壳平台有多种触达消费者的渠道:比如,通过 DMP 人群标签圈定目标人群,然后对目标人群通过短信或者 IM 发送市场行情或用户关注房源信息(价格)变化,增加用户粘性;也可以通过定向发送优惠券引导用户向成交转化;在站外可以通过贝壳 DSP 平台进行广告推送,为平台拓展新用户。
目前贝壳平台智能营销覆盖的群体中,其中有一部分自然转化率就很高,很明显这部分人是不需要投入运营成本的。那么如何通过技术来衡量和预测营销干预带来的“增量提升”,而不把营销预算浪费在“本来就会转化”的那部分人群身上,成为智能营销算法最大的挑战。
无论是广告还是优惠券,我们都称为营销的干预手段,这些手段都需要花费成本。营销的目标就是:在成本有限的情况下最大化营销的总产出,这其中最关键的一点就是我们能否准确找到真正能被营销打动的用户,我们称之为营销敏感人群,在营销活动中,对用户进行干预成为 treatment,例如发放优惠券就是一次 treatment,对人群进行四象限划分,我们可以将用户分为以下四类:
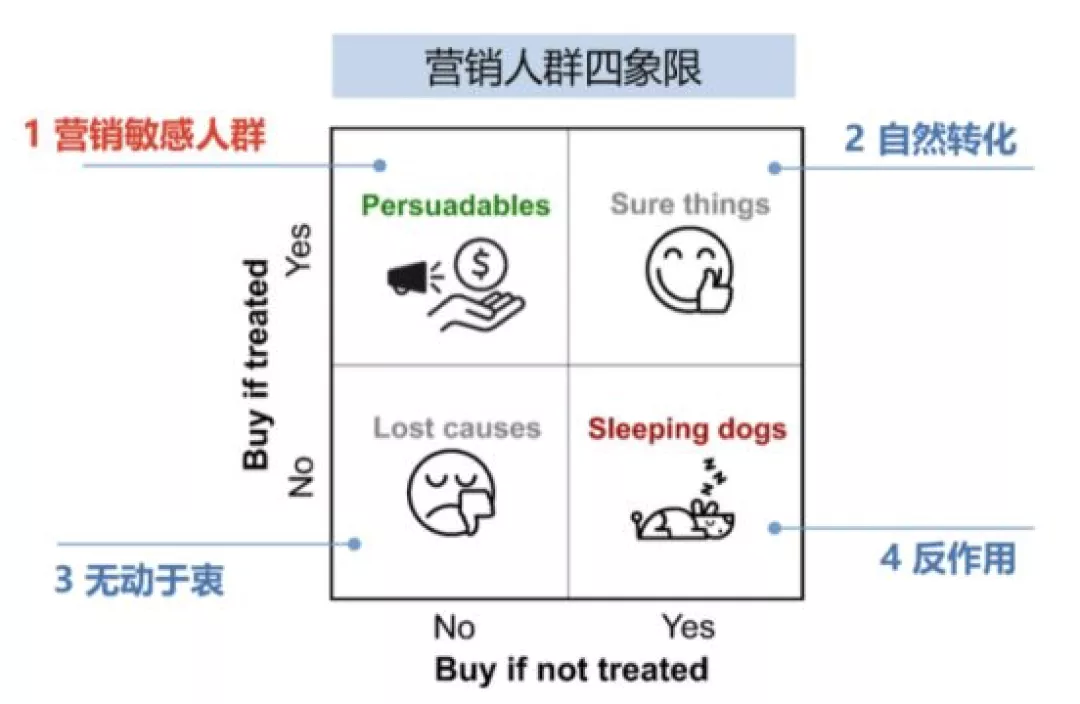
图 1 营销人群四象限划分图
其中,横纵坐标分别是用户在有干预和无干预情况下的购买情况。
Persuadables:
不发券不购买,发券才会购买的人群,即优惠券敏感人群
Sure thing:
无论是否发券,都会购买,也就是自然转化人群
Lost cause:
无论是否发券都不会购买,难以触达,可以选择放弃
Sleeping dogs:
与 Persuadables 恰好相反,对营销活动比较反感,不发券的时候有购买行为,发券后不再购买
很明显在营销中我们需要触达的是 Persuadables,而对于 Sleeping dogs 需要尽量避免。
2 增益模型在智能营销中的价值
在营销这个场景中很容易想到套用点击率预测模型,在这里我们称为响应模型(response model),即预测用户看到优惠券后购买商品的概率。但是这其中有一个问题就是:用户是本来就有购买意愿,还是因为发放了优惠券诱使用户购买?可以看到使用 response model,很难区分上面提到的四类人群,因为模型只预测是否购买,但人群的群分需要明确是否因为发放优惠券才导致了购买行为,这就转化成一个因果推断问题(casual inference)。
在营销活动中,我们要预测的是某种干预(treatment)带来的增量,这种模型称为增益模型(uplift model)。设 G 表示模型干预策略(如是否推送广告),X 表示用户特征,Y = 1 表示用户输出的正向结果(如下单或者点击):
Response model:
P(Y = 1 | X),看过广告后购买的概率
Uplift model:
P(Y = 1 | G, X),因为广告而购买的概率
为了更好的理解 response model 和 uplift model 的差异,我们可以具体看一个栗子:
有两类人群:User1 和 User2,这两类人群对于广告的 CVR 分别为 0.8%和 2.0%。假如只有一次广告曝光的机会,应该像哪一类用户投放广告呢?
按照以往的直直觉和经验,可能会选择第二类,因为其转化率最高,但这个结论是正确的么?
假如我们可以知道这两部分人群无广告触达下的转化率,如表 1:
表 1 User1 和 User2 人群转化信息表
从上面的表不难看出,第一类用户的广告转化率虽然低,但是在没有广告触达的情况下更低,因此广告带来的增量(uplift)反而比第二类更高,从全局的角度考虑我们要最大化总体的转化率其实等价于最大化广告带来的增量,按照这个逻辑我们应该向第一类用户投送广告。可以看出使用 response model 很可能会误导我们做出错误的决策,response model 和 uplift model 最主要的差异主要是预测目标上的差异:
response model 的目标是估计用户看过广告后的转化率,这本身是一个相关性分析问题,而这会导致我们无法区分自然转化人群
uplift model 是估计用户因为广告购买的概率,即时一个因果推断问题,帮助精准寻找营销敏感人群。所以 uplift model 是整个智能营销中的关键技术,预知每个用户的营销敏感程度,从而帮助我们制定营销策略,促成整个营销的效用最大化。
3 增益模型的表示
Uplift model 是一个增量模型,其目标是预测某种干预对于个体转态或行为的因果效应(ITE, individual treatment effect),那么如何表示这个增益模型呢?
假设有 N 个用户,Y_i(1)表示对用户干预后用户输出的结果,比如给用户 i 发放优惠券(干预)后用户下单(结果),Y_i(0)表示没有对用户干预情况下的输出结果。用户 i 的因果效应的计算方式如下:
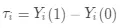
(1)
训练增益模型目标就是最大化增量τ_i,即有干预策略相对于无干预策略的提升,更简单的解释就是干预前后用户输出结果的差值。在实际使用时会采用所有用户的因果效应期望来衡量该用户群的整体表现,称为条件平均因果效应(CATE, Conditional Average Treatment Effect):
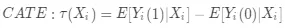
(2)
上式中 X_i 是用户 i 的特征,所谓的 conditional 是指的基于用户的特征。
在实际场景中,对于任意一个用户我们是不可能看到其同时受到干预策略(treatment)和不干预策略(control)时的反应的,所以式(2)是 uplift 的理想计算公式,我们对其进行修正:
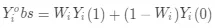
(3)
其中 Y_i^obs 是用户 i 可以观察到的输出结果,W_i 为二值变量,如果用户 i 被干预则 W_i = 1,否则 W_i = 0。当用户特征和干预策略满足条件独立假设(CIA,Conditional Independence Assumption)时,条件平均因果效应的期望估计值可以写作:
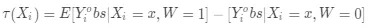
(4)
其中用户特征和干预策略相互独立即:{Y_i (1),Y_i (0)⊥W_i |X_i。
4 增益模型建模
那么如何进行建模呢?
在建模前我们需要注意一个很重要的问题:Uplift Model 对样本要求很高,需要用户特征和干预策略相互独立。
那么什么样的样本用户这样的特征,这样的样本又该如何获取?
最简单直接的方式就是随机 A/B 实验,A 组采用干预策略,B 组不进行任何干预,经过 A 组和 B 组的流量得到的两组样本在特征分布上基本一致(即满足 CIA),可以通过模拟两组人群的τ(X_i)进而得到个人用户的τ(X_i)。因此随机 A/B 实验在 Uplift Model 建模过程中至关重要,在训练样本高度无偏情况下,模型才能表现出更好的效果。
4.1 差分响应模型(Two-Model Approach)
最简单粗暴的建模方法是基于 Two Model 的差分响应模型,对 A 组和 B 组数据进行单独建模:
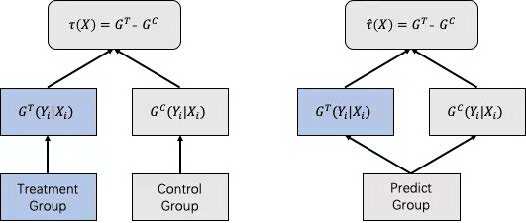
图 2 Two-Model 差分响应模型流程图
其中模型 G^T 用来学习用户在有干预策略影响下的响应,另外一个模型 G^C 用来学习用户在没有干预策略下的响应,对于预测组数据,分别过两个模型,将得到的模型预测分数做差,就得到 uplift score。
在实际中以 uplift score 进行排序,由其高低决定是否进行干预。虽然两个模型单独训练容易累计误差传递到 uplift score,但是考虑到实现简单迅速,可以将其作为 baseline。
4.2 差分响应模型升级版(One-Model Approach)
基于 Two Model 的差分响应模型,训练数据和模型都是相互独立,那么是否可以进行模型统一和数据共享呢?答案是肯定的,那就是基于 One Model 的差分响应模型,那么问题来了,数据共享、模型统一,怎么学习干预组合非干预组样本的差异呢?在阿里文娱中提到一种方法:在特征维度进行扩展,引入干预信号相关特征 T(T 为 0 代表干预组,否则为非干预组,T 同样可以扩展为 0-N,建模 multiple-treatment 问题,比如优惠券的不同额度,广告的不同素材)。
4.3 标签转换模型(Class Transformation Method)
即使基于 One Model 的差分响应模型在训练数据和模型层面上打通,但其本质还是对于 uplift 的间接建模,更为严谨的一种实现实验组和对照组数据和模型打通的方法是:标签转换方法(Class Transformation Method),可以直接对τ(X_i)进行建模。
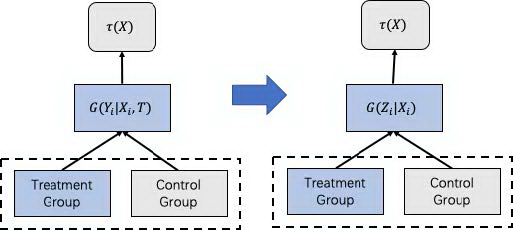
图 3 One-Model 标签转换模型流程图
标签转换是在二分类的情境下提出的,这种方法的目标函数形式为:
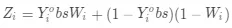
(5)
其中 Z_i∈{0,1}是转化后的标签,其转换的规则如下:
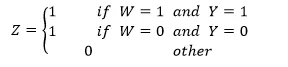
(6)
可以看到当用户处于实验组且转化和处于对照组未转化的用户对应的标签为 1,其余对应标签为 0,那这样优化目标就变成 P(Z=1|X),这与之前的优化目标之间存在什么关系呢?下面我们来证明一下。在证明前需要说明两个假设:
用户特征和干预策略相互独立
用户被分到实验组和对照组的概率一致 P(T)=P©=0.5
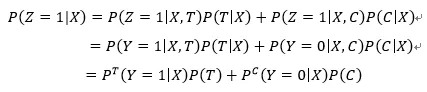
(7)
根据上面两个假设,上式可以改写为:
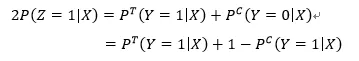
(8)
进而可得:
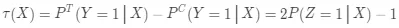
(9)
(9)式对应的就是 uplift score,此时只有一个变量,因此优化 P(Z=1|X)就相当于优化τ(X),而不再需要对实验组和对照组进行单独建模,这种方法之所以流行是因为它同样也是原理简单,并且效果优于差分响应模型,可以采用任何你想使用的分类模型进行训练,但是其需要满足上面提到的两个假设。
第一个假设一直是我们强调的很好理解,第二个假设(个体对对照组和实验组的倾向必须一样)看似非常严格,幸运的是,可以通过一些转换操作来解决实验组和对照组的个人倾向不同的问题。
最简单的方式就是对数据进行重采样使得数据满足假设,即使不满足也可以通过引入用户倾向分来进行调整,调整后对于 CATE 的估计值转化为:
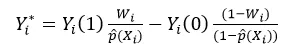
(10)
其中 p(X_i)=P(W_i |X_i)表示个人倾向分,其代表在 X_i 条件下进入实验组概率,这种转换必须是在 CIA 假设条件,在 X_i 的条件下等同于 CATE 即 E[Y_i^* |X_i ]=τ(X_i)。
当实验组和对照组的样本比例不相同时,这时对应的 Y_i^*是一个连续值,因此我们可以采用任意一种回归模型进行求解。
4.4 直接建模(Modeling Uplift Directly)
对于 uplift 直接建模的方式除了上述标签转换的方式外,还有一种就是通过修改已有的学习学习器结构直接对 uplift 进行建模,比如修改 LR、k-nearest neighbors、SVM,比较流行的就是修改树模型的特征分裂方法。
传统树模型的分裂过程中,主要参照指标是信息增益,其本质是希望通过特征分裂后下游正负样本的分布更加悬殊,即代表类别纯度变得更高。同理这种思想也可以引入到 Uplift Model 建模过程,我们希望通过特征分裂后能够把 uplift 更高和更低的两群人更好地区分开。
传统信息增益表示为:
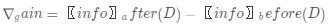
,可以直接修改为:
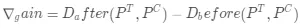
其中 D_before (P^T,P^C )和 D_after (P^T,P^C)分别表示分裂前后实验组合对照的样本分布,如何从数学角度来衡量这种分布之间的差异呢?最直观的方法就是采用距离度量,比如 KL 散度(KL divergence)、欧氏距离、卡方距离等等。
这种模型的优点就是可以直接量化 uplift,对 uplift 的量化更加灵敏更加精准,在理论上精度相较其他模型会更高,但实际应用时除了修改分裂规则外,还需要修改 loss 函数、剪枝等一系列的操作,模型收敛性和泛化能力也很难去保证,所以落地成本较高。
5 增益模型的评估
前面我们已经介绍了三种常见的 uplift 建模方法,那么我们如何对训练好的 uplift 模型进行评估呢?响应模型可以通过观察模型在测试集上的 AUC、Precision、Recall 等指标来评价模型好坏,但在增益模型中我们并不能得到一个用户 uplift 的 ground truth,因此无法直接计算上述指标。
不能直接那还不能间接么?一个思路是通过构造特征相似的镜像人群的方式来间接计算 uplift 的 ground truth,而不是在一个测试集上直接评估。将训练好的模型分别预测实验组和对照组的测试集数据,得到这两群人的 uplift score,然后按照 uplift score 进行降序排列,通过分数这一桥梁,把两组人群进行镜像拉齐。
分别截取 top10%,top20%…top100%的用户,计算每一分位下两组人群的转化率差异,这个差异可以近似的认为是该分位下对应人群的真实 uplift 值,将这些分为差异值连接起来就得到 uplift cure 也成为 Qini curve,其具体计算公式如下:
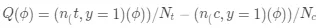
(11)
其中,ϕ是按照 uplift score 由高到低排序的用户数量占实验组或对照组用户数量的比例,比如ϕ = 0.1 表示实验组或者对照组 top10%的用户。n_(t,y=1) (ϕ)表示在ϕ下,实验组中转化(下单)的用户数;同理 n_(c,y=1) (ϕ)表示在同样分位数下,对照组中转化(下单)的用户数。N_t 和 N_c 分别表示实验组和对照组的总用户数。
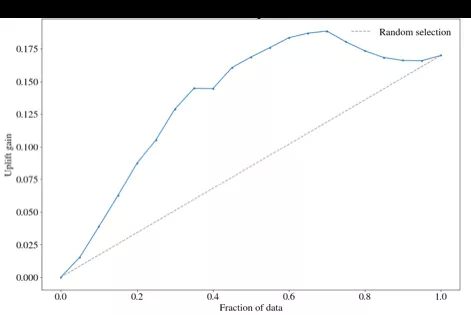
图 4 Qini 曲线图
图中灰色虚线是随机的 base 曲线,可以通过计算 Qini curve 和随机 base 曲线之间的面积作为模型的评估指标,其与响应模型的 AUC 类似,称为 AUUC(Area Under Uplift Curve)面积越大越好,表示模型结果远超随机选择结果。
注意到在计算 Qini 值时,分母是实验组和对照组的全部用户数,如果实验组和对照组用户数差别较大,结果容易失真,因此可以通过计算累计增益来避免这个问题,其计算公式如下:
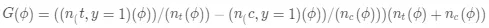
(12)
其中各符号与 Qini 值计算公式中含义相同,不同的为 n_t (ϕ)和 n_c (ϕ)代表百分比ϕ下的实验组和对照组人数(不是全部的了哦),以 n_t (ϕ)+n_c (ϕ)作为全局调整系数,避免因实验组和对照组用户人数差异过大而产生的指标失真问题。
图 5 累积增益曲线图
同样可以计算累计增益曲线和随机曲线下的面积作为模型评估的指标。
6 业务应用
在贝壳新房业务场景下,我们希望当用户进入新房频道首页时,为用户发放带看券或者成交券,在保证 ROI 大于 0 的前提下,提升用户带看率和成交率,进而提升平台 GMV。
我们将问题进行抽象,在进入到新房频道首页的用户中,精准识别出那些对于优惠券敏感的人群,进行优惠券发放。也就是我们需要对用户进行优惠券敏感度建模,这正是 uplift model 做的事情。
6.1 样本构造
目前新房业务场景下,已经做过很多优惠券相关的活动,但这些活动的运营对象时全部用户,也就是所有用户多会发,需要用户主动进行领取,这显然是不满足 uplift model 对于训练样本的要求的。
我们选择新房业务下最近的一个活动“618 惠住季”来构建训练样本,为了更好的模拟随机 A/B 实验,按照是否浏览过活动领券页面将用户分为实验组用户和对照组用户(在这里我们认为用户没有浏览过活动领券页面,就可以认为对其没有发券)。
在房产交易场景中,用户决策周期很长,如果拿成交和带看来作为转化的目标可能对导致转化样本数过低,因此我们加入了委托,我们认为只要用户在领券后的未来 7 天内,发生委托或带看或成交任一种重行为的转化,即将其标定成为一条正样本,标定后的正负样本分布如下表:
表 2 实验组和对照组正负样本分布表
可以看到实验组和对照组总人数数量之间差异巨大,为了后续可以使用标签转换方式训练模型,我们对对照组进行欠采样,最终实现对照组人数和实验组人数基本一致。
6.2 特征工程
在特征工程层面我们主要选取了用户行为特征、城市特征、偏好特征、时序特征等。
表 3 样本特征信息表
我们分别将实验组和对照组各 80%的数据作为训练集,20%数据为测试集来评估模型表现。为了方便起见,将对照组和实验组的测试集合并用来观测训练过程,在真正预测时在将其分开。
6.3 模型训练与评估
在模型选择上,我们以 XGBoost 模型作为基学习器,分别在 Two Model 差分响应模型、One Model 差分响应模型(无标签转化+引入 T/C 特征)、One Model 差分响应模型(引入标签转化)和 One Model 差分响应模型(引入个人倾向分)上进行了尝试。One Model 差分响应模型(无标签转化+引入 T/C 特征)训练流程如下:
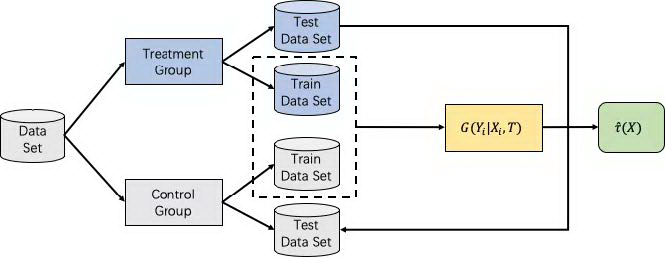
图 6 One Model 差分响应模型(无标签转化+引入 T/C 特征)流程图
在实验组和对照组分别取 80%的用户合并成训练样本,然后引入干预策略相关特征进行模型训练,在实验组和对照组各 20%的用户样本上将每个用户干预策略特征分别置 1 和 0,预测两次,然后将预测结果相减即为 uplift 值。
在全部模型试验中,Two Model 差分响应模型表现最差,One Model 差分响应模型(无标签转化+引入 T/C 特征)和引入倾向分后的回归模型表现较好。
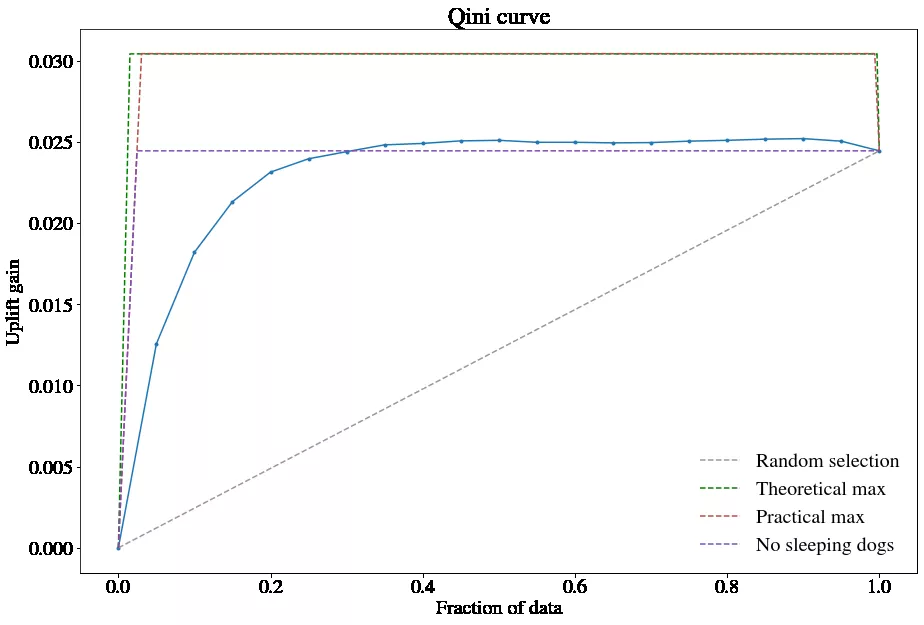
图 7 two-model 差分响应模型(无标签转化+引入 T/C 特征)Qini 曲线
Two Model 模型会导致误差累计,在具体实验中也得到了同样结论;标签转化方法在逻辑上推导可行,实验结果显示并不尽如人意,分析其主要原因还是对于样本的要求太高,目前构造的数据虽然保证了实验组和对照组用户数量基本一致,但是完全随机基本无法保证。相反,引入个人倾向分后,将其转化为回归问题,在一定程度上解决了这个问题,标签转化虽然逻辑上可以,但是还是需要一定解释成本。
在实验中表现最好的 One Model 差分响应模型(无标签转化+引入 T/C 特征),在结果输出上解释成本也是最低的,在对于每个用户预测时,分别加入 T 和 C 干预信号特征,然后预测值相减即得到用户的 uplift score。
7 写在最后
本文主要从基础概念、表示方式、构建方法、评估方式以及应用方案等几方面对增益模型进行介绍,让各位读者对增益模型有了一个更全面的认识。由于增益模型对于样本数据质量要求极高,因此在真正业务场景中落地还是具有一定难度的。
目前增益模型在贝壳平台上已经得到了实践与应用,并取得了不错的效果。但随着营销手段越来越复杂,treatment 维度会剧烈增加,这样对于模型升级和无偏样本规模提出更高的要求。后续可以考虑强化学习多智能学习的思路,进行多任务学习,联合多场景建模,进而缓解样本压力。
【引用资料】
Causal Inference and Uplift Modeling: A review of the literature
Uplift modeling for clinical trial data
Pylift: A Fast Python Package for Uplift Modeling
阿里文娱智能营销增益模型技术实践
本文转载自公众号贝壳产品技术(ID:beikeTC)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论