

导读:随着 AI 科技的发展,智能语音交互技术正在被国内外巨头公司逐步落地和规模化应用。滴滴出行作为移动出行领域的一家领先的移动互联网企业,也正积极布局和利用智能语音交互相关技术,如语音识别、语音对话理解、语音合成等,以便更好的为司机和乘客提供高质量服务,具体地,包含有司机智能助手和滴滴智能客服系统等应用产品。
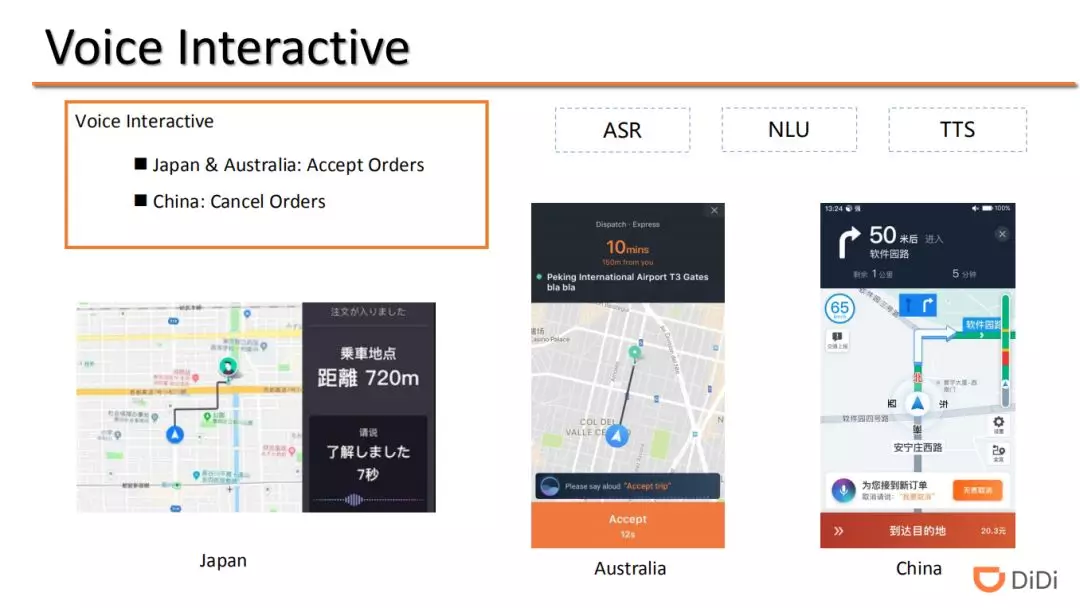
滴滴正在尝试推出司机智能助手,为司机提供语音提供服务。目前,部分地区的司机可以通过与 APP 语音交互方式方便快捷地实现信息查询、接受订单、取消订单等,无需手动操作手机,积极响应了部分地区对驾驶过程中使用手机的限制政策和司机的安全诉求。
滴滴的智能客服系统,能利用语音识别、NLP、知识图谱等技术辅助人工客服,提高人工客服处理问题的效率,并减少人工客服在重复、简单问题上的处理量。比如在用户进线的时候,会请用户通过语音先描述他的问题,智能系统可以自动识别并且基于信息去预测用户大概的需求并为人工客服提供一些决策信息,等电话流转至人工客服,人工客服一接起来的时候,他已经能大概知道用户的问题从而能帮助用户更好地解决;智能系统还会自动化地生成工单摘要,帮助人工客服提高效率。不仅如此,智能系统还可以学习人工客服的处理方式,从而使机器越来越接近人的复杂决策水平。
语音识别 ( Automatic Speech Recognition, ASR ) 技术是智能语音交互领域中发展最快,同时是语音相关任务中最有挑战也是最重要的技术之一,所以今天重点围绕语音识别进行介绍。
本文主要包括以下几个部分:
① 语音识别的基本概念
② 语音识别深度学习方法
③ 基于 attention 的语音识别相关方法
④ 语音识别相关的任务
语音识别的基本概念
1. 基本概念
语音识别的任务主要是将语音转成对应的文字,其输入信号是一段音频信号,输出是对应的文字序列。

语音识别可以认为是一个搜索的过程,给定输入特征 X 的情况下,搜索出最有可能的词序列 , 如下经典公式表示:
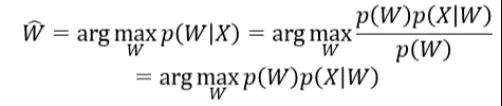
从公式中可以看出,在输入特征的情况下搜索最大可能的词序列转换成了两部分 P(W)和 p(X|W),分别对应语言模型和声学模型。
语音识别过程一般包括三个部分:
① 声学模型:P(X|W)描述在给定词的情况下,对应声学信号的概率。
② 语言模型:P(W)描述语言序列关系的模型,关注序列产生的概率。
③ 解码器:根据声学模型和语言模型,搜索出最有可能的词序列,其本质是一个动态规划算法。
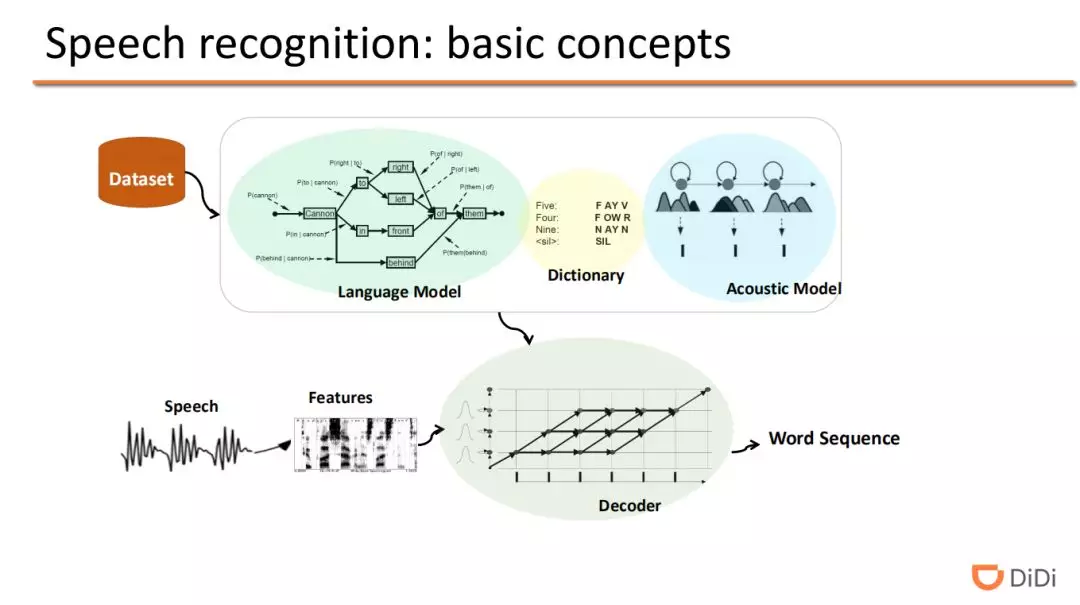
语音识别的一般流程如上图所示,根据输入的语音信号,提取语音特征,通过解码器融合训练好的语言模型和声学模型,得到最终的词序列结果。字典的作用根据声学模型识别出来的音素(汉语中一般为声韵母),来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。
2. 语音识别的经典方法
1. 语言模型
在语音识别的语言模型中,最常用的是序列语言模型,换句话说就是要计算一个序列(句子)出现的概率。语言模型主要用来决定哪个词序列可能性更大,或者根据前一个或几个词的情况下预测最有可能的下一个词,可以排除掉一些不可能的词,减少了词的搜索范围。最经典语言模型是 N-gram 模型,该模型基于 Markov 假设来计算 P(W)。N-gram 是一个统计模型,在海量的文本语料库中统计的模型效果和计算性能优于其他模型。在工业实际训练 N-gram 模型时,有时候会使用到的语料库达到 100Tb 甚至以上的数据。

2. 解码器
采用 Viterbi 算法,综合声学模型与语言模型的结果,给定输入特征序列,找出最有可能的词序列,也就是把整体概率分数最高的词序列当做识别词序列结果。
3. 声学模型
① 多样性问题
声学模型是语音识别中最重要的一个模型,同时所有的声学模型也都面临各种着多样性的挑战。
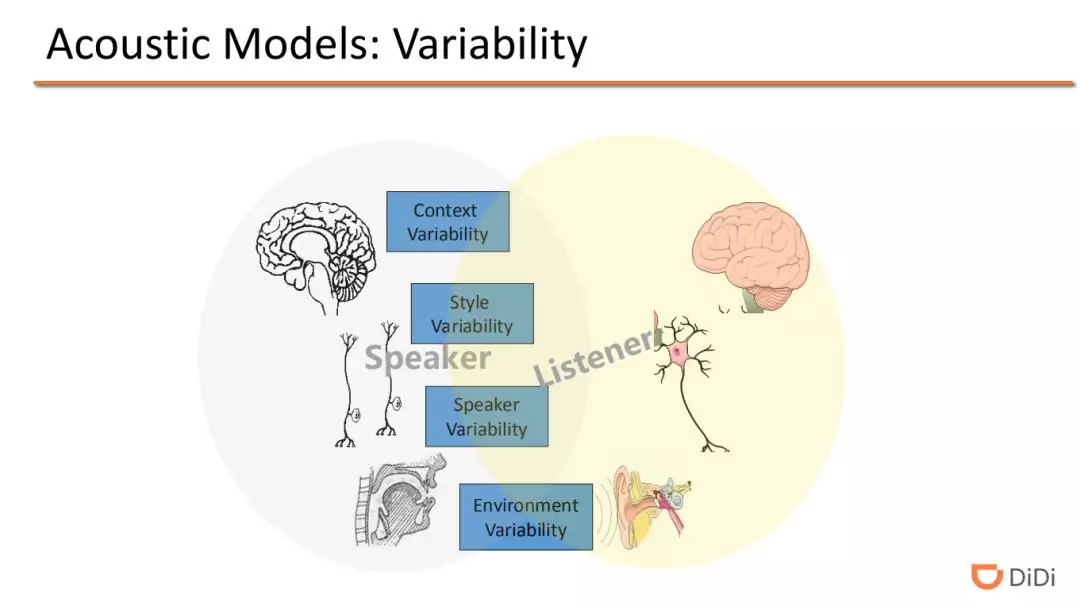
❶ 上下文的多样性:比如同一个词,放到不同的上下文中表现出不同的含义。
❷ 风格多样性:同一个说话人,说话风格有时也会有所差异,如演讲时和与朋友聊天时的风格就有所差异。
❸ 说话人多样性:在语音识别任务中,一种任务是不管说话人是谁,说了同样的文字内容,我们都要把说具体内容识别出来;反过来的一种任务是说话人识别,就是不管说话人说什么内容,我们都要把说话人识别出来。所以相同的语音信号包含了很多不同的信息,也导致了声学信号的不同。
❹ 环境多样性:我们知道同样的说话内容通过不同语音设备(如手机,音响,麦克风等)表现也各不相同,同时设备质量的不同也会引入很多的噪音,导致声学信号也不相同。
这些多样性问题都增加了声学模型处理的难度和挑战
② 最经典的声学模型:GMM-HMM

神经网络发展起来之前,语音识别通常采用经典模型 GMM-HMM 作为声学模型。 GMM 是统计模型,描述声学信号的分布;HMM 是记录一些状态跳转,描述声学信号内部状态的关系。
③ 语音识别任务的评测
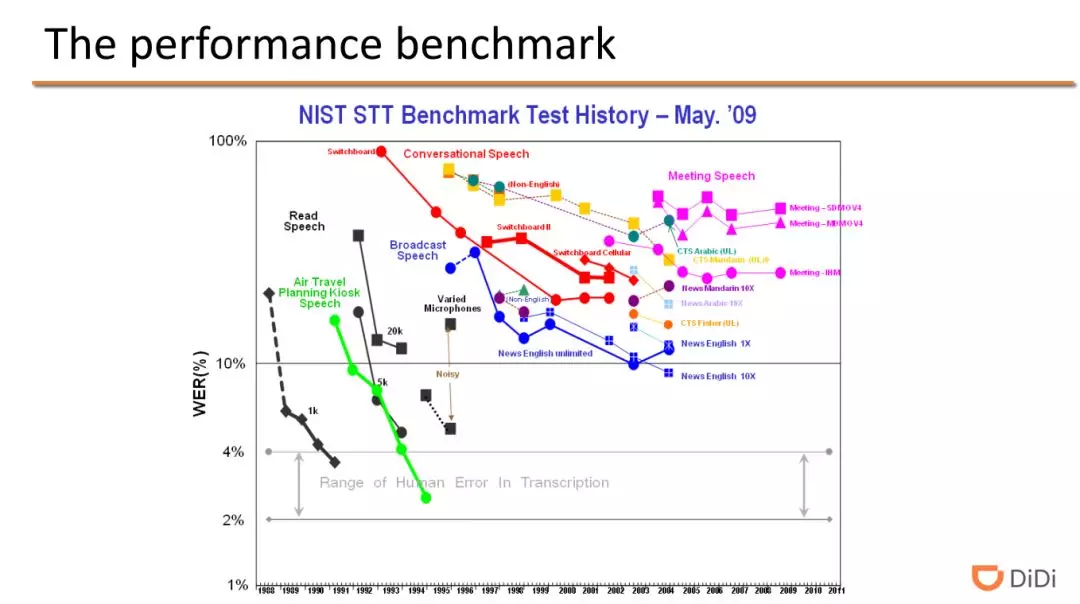
在以前,NIST 会组织一些语音识别任务的评测,在 2009 年深度学习出现之前,评测任务包含从相对简单的任务(1000 个数字的识别)到一些复杂场景的识别任务(比如开会录音)。对于简单的任务识别的错误率很快便达到了 4%以下,但是对于复杂场景下的识别任务,当时错误率在 50%左右。
此外,从这里也可以看出,通常情况下,谈到语音识别准确率(或错误率)都需要与其对应的任务联系起来的。
语音识别的深度学习方法
1. DNN-HMM 模型
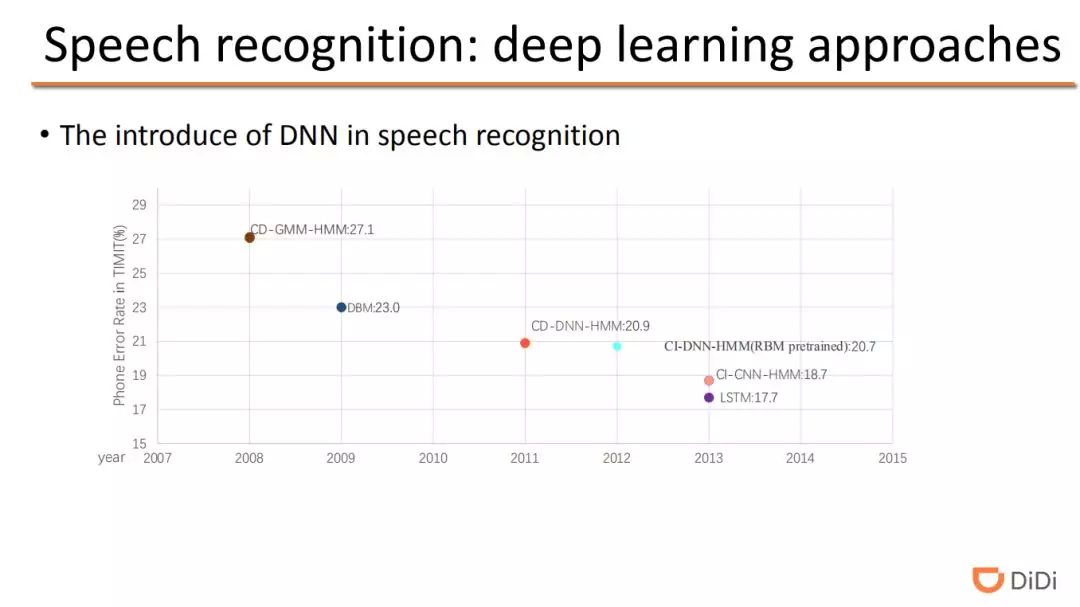
但是随着深度学习的兴起,将深度学习模型应用于语音识别中,其性能得到显著提升。在这里,以经典的 TIMIT 音子识别任务为例,2013 年使用深度学习模型将错误率从之前的 27.1%降低到 17.7%。
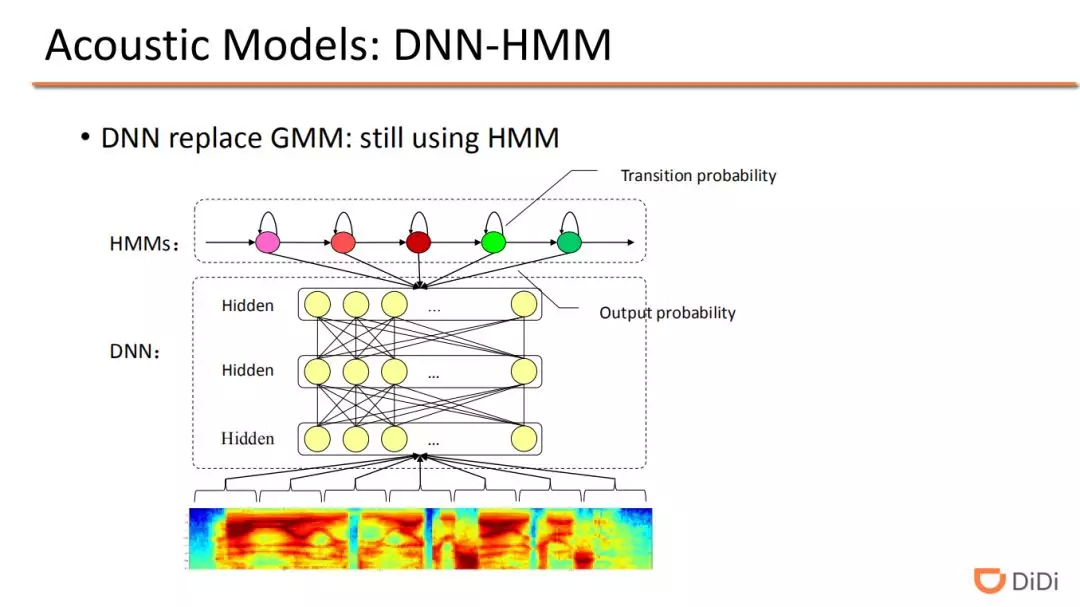
深度学习模型兴起后,语音识别模型最初引入深度学习模型时是将 DNN 替换了之前经典模型中的 GMM 模型,HMM 模型保持不变。在这里的 DNN 的学习,会依赖声学特征和对应的文字内容标记信息的强制对齐。换句话来说,就是给定一段语音的输入特征,标注好这些特征对应的文字内容相关的信息,比如其中一段音频标注了声母“h”,另一段音频标注为韵母“ao”,标注好之后直接使用 DNN 去做分类任务的训练。DNN 替代 GMM 后取得了更好的效果。
2. 端到端模型的兴起
自 2009 年开始就有研究者将深度学习技术应用到语音识别中,并且取得了显著的效果。在 DNN 框架之后,语音识别技术的发展一直伴随着深度学习技术的发展,由最初的前馈神经网络,到卷积神经网络(CNN),然后再迭代到循环神经网络(RNN,LSTM,GRU 等),都应用到了语音识别任务中。在深度学习的语音识别领域中也开始探索 end-to-end 的训练方式,即用更原始的语音信号作为输入特征。先前的模型包括了特征提取、声学模型,语言模型等模块,是一个 pipeline 的系统,而 end-to-end 从输入到输出只用一个算法模型,输入是语音信号,输出就是最终的词序列的结果。常用的端到端的语音识别模型为基于 CTC ( Connectionist Temporal Classification ) 和基于 attention 机制的模型。这里先介绍第一个基于 CTC 的端到端语音识别模型。
语音识别模型属于有监督训练模型,需要输入特征与输出的标记信息一一对应。在 DNN-HMM 中,训练时需要知道语音信号每一帧对应的 label,所以特征处理过程中需要做对齐处理。而 CTC 模型不需要做对齐处理,而是通过改变内部的拓扑结构,放宽了一一对应的限制,给定一个输入语音特征序列,和它对应的输出标记序列就可以直接训练。CTC 的做法通过引入 blank 符号。
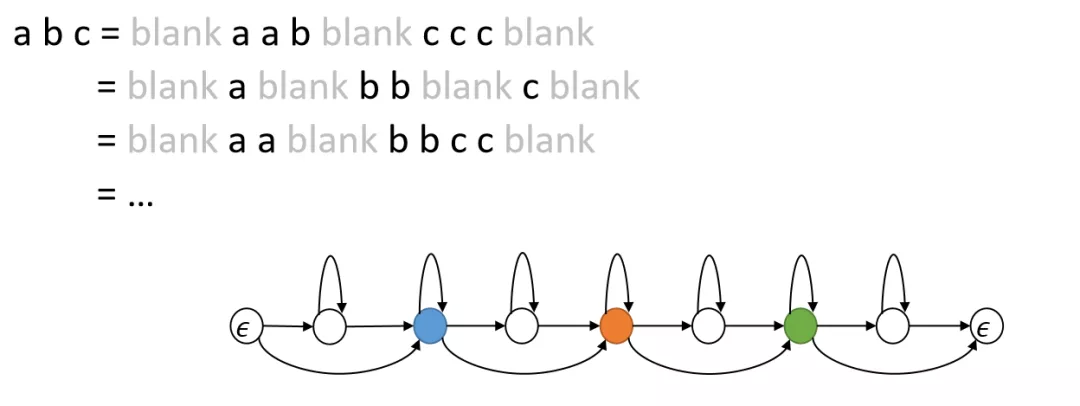
CTC 最后只关注一段语音信号中尖峰位置的输出序列。损失函数如下:

CTC 模型整体框架类似于 DNN-HMM 模型,但是通过改变了内部拓扑结构实现了端到端的训练方式。2016 年深度学习语音识别框架 DEEPSPEECH 就是一个基于 CTC 的语音识别的典型例子。
基于 attention 的语音识别方法
1. Attentional ASR 模型
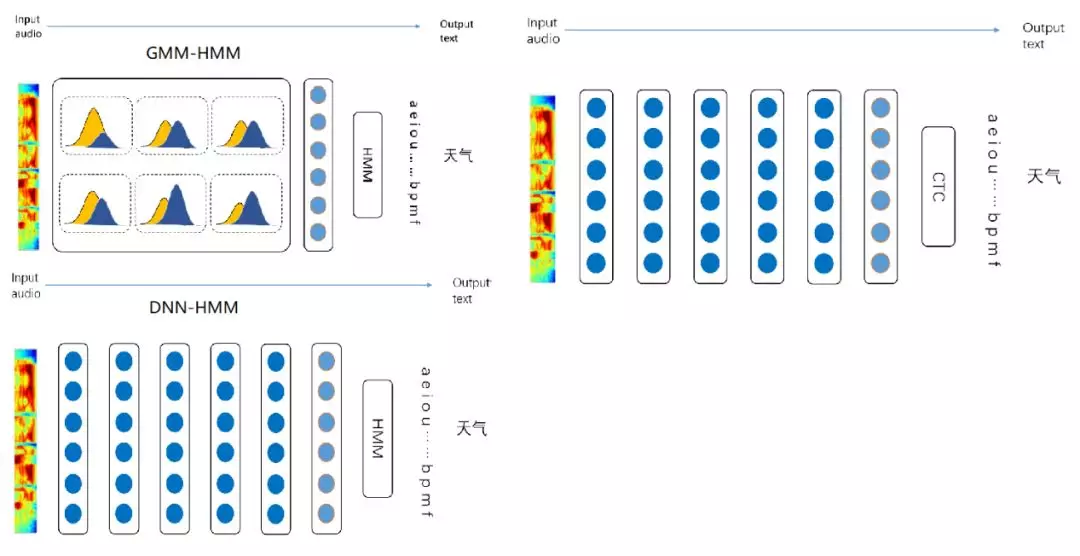
语音识别模型从最初的 GMM-HMM 模型,到 DNN-HMM 模型(声学模型使用神经网络替换),再到基于 CTC 的模型。近些年来,基于 attention 机制的端到端训练语音识别模型也逐渐成为了主流。
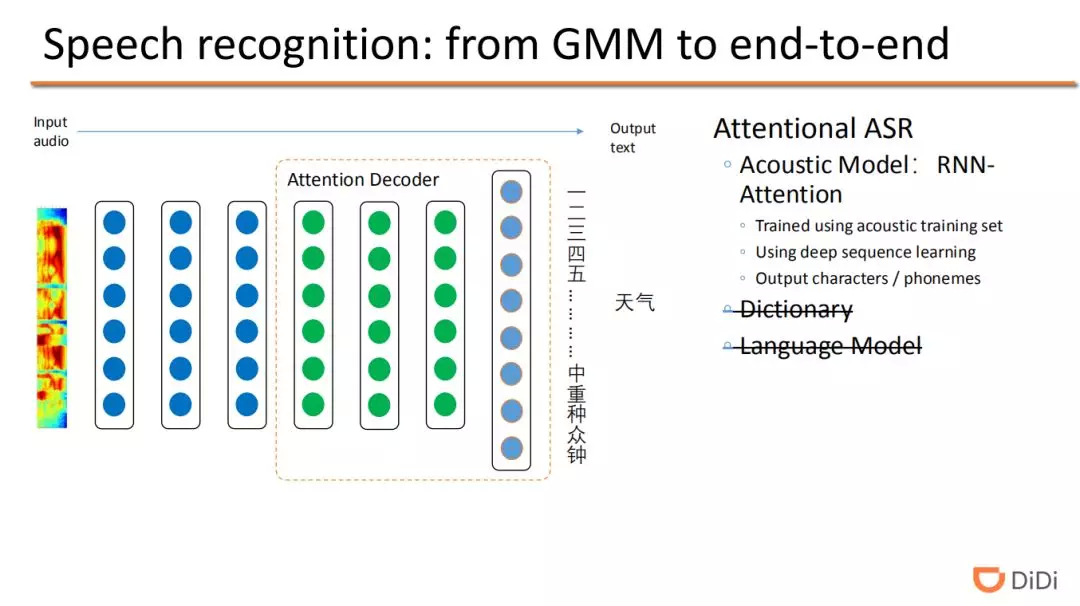
Attention 机制最早的应用是在机器翻译领域,实现了从一种语言序列变化到另一种语言序列。而语音识别领域和机器识别领域非常相似,前者是从语音信号的序列到输出文字的序列,而后者是从一种语言的文字序列到另一种语言文字的序列。随后研究人员开始探索将 attention 机制应用到语音识别领域,Bengio 团队将机器翻译模型类似的架构应用到语音识别中,并将结果发表在了论文[1]中。Attention 采用一个模型实现从语音信号直接输出文字序列结果,从而该框架中将不再需要词典和 N-gram 语言模型。当然在实际应用中,通过某种方式(一遍或者二遍解码中)融合 N-gram 一般也会带来一定性能的提升。
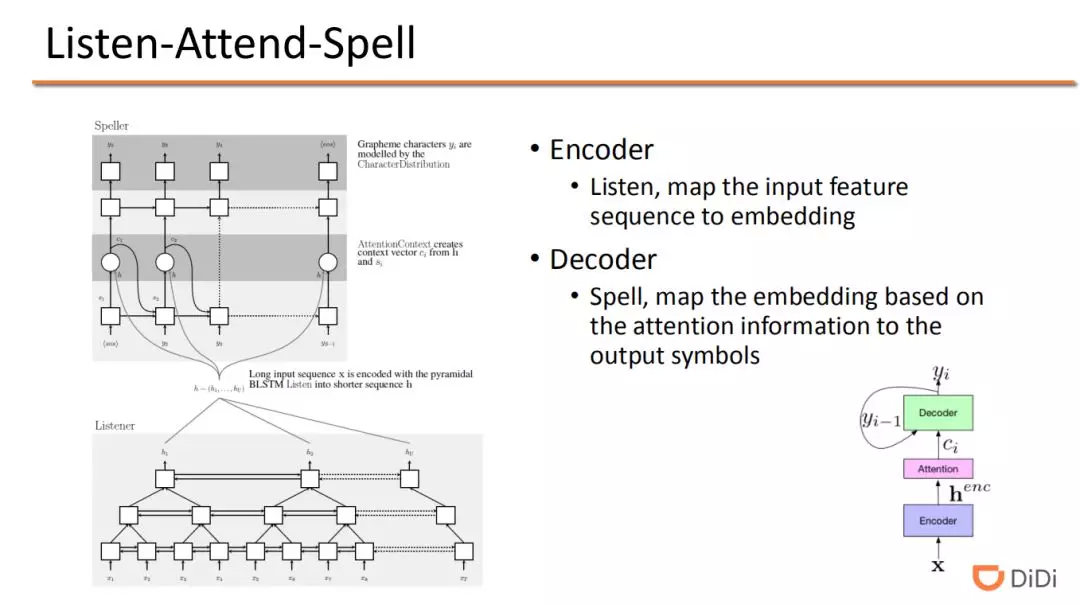
通常语音识别中使用 attention 机制的算法模型被称为 Listen-Attend-Spell(LAS)模型。Listen 部分是一个 encoder,把声学信号转换成 embedding 向量, Attend 为转换后向量的权重,Spell 部分是一个 decoder,把向量转换成对应的文字序列。
2. Attention 和 CTC 的比较

Attention 模型和 CTC 模型最主要的区别是,基于神经网络对输出序列的历史信息做了显式的建模。
虽然基于 attention 的语音识别模型,简化了之前的系统框架,实现了端对端的训练方式,但是在实际工业中应用中依然有很多挑战,这是因为 attention 的语音识别模型想要得到好的训练结果,需要加很多的“tricks”,随着近几年应用的经验总结出以下“tricks”。
Schedule Sampling:计划采样;
Label Smoothing(2016):在 label 标注里加入一些噪声;
Multi-Task Learning (2017):加入 CTC 模型收敛更快,可以加快 attention 的收敛速度;
Multi-headed Attention (2018):源于 transformer 模型,学习到更细粒度的特征;
SpecAugment (2019):在语音信号方面加强多样性,特征更丰富。
3 基于 transfomer 的语音识别模型
在 NLP 领域,输入是一段文字,通常的做法会把输入的文字通过 embedding 的方式转换成连续的向量。但是对于语音,输入本身语音信号就是一个向量,但是语音的信息密度要比文字的信息密度大很多,比如一句话的内容可能有 10 个文字,对应 10 个符号,但是对应的语音信号大概有 2 秒左右,每 10 毫秒作为一帧特征,2 秒钟就有 200 帧特征,即有 200 个特征向量,如何把 200 个特征向量对应到 10 个文字的序列是语音识别中面临的一个挑战。
在语音识别中,如果引入 Transformer 模型,通过会使用几个卷积层来实现 downsampling,然后通过 transformer 模型映射到输出的文字序列,从而加入模型的收敛。
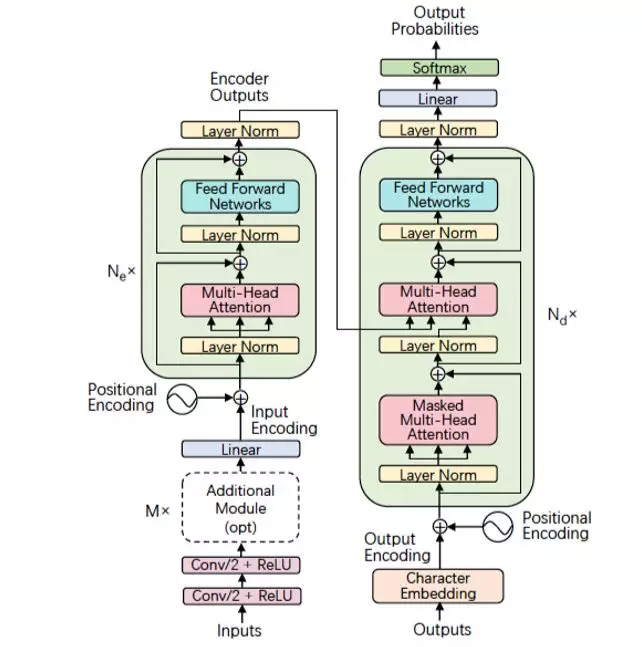
近两年来,BERT 无监督预训练的出现,让 transformer 模型的性能得到了提升。工业界中存在大量的没有标注的数据。深度学习模型高度依赖于大量高质量的标注数据,但是人工标注成本非常高并且数量有限。通过 BERT 这种预训练的方式,让大量的无监督数据得以利用。
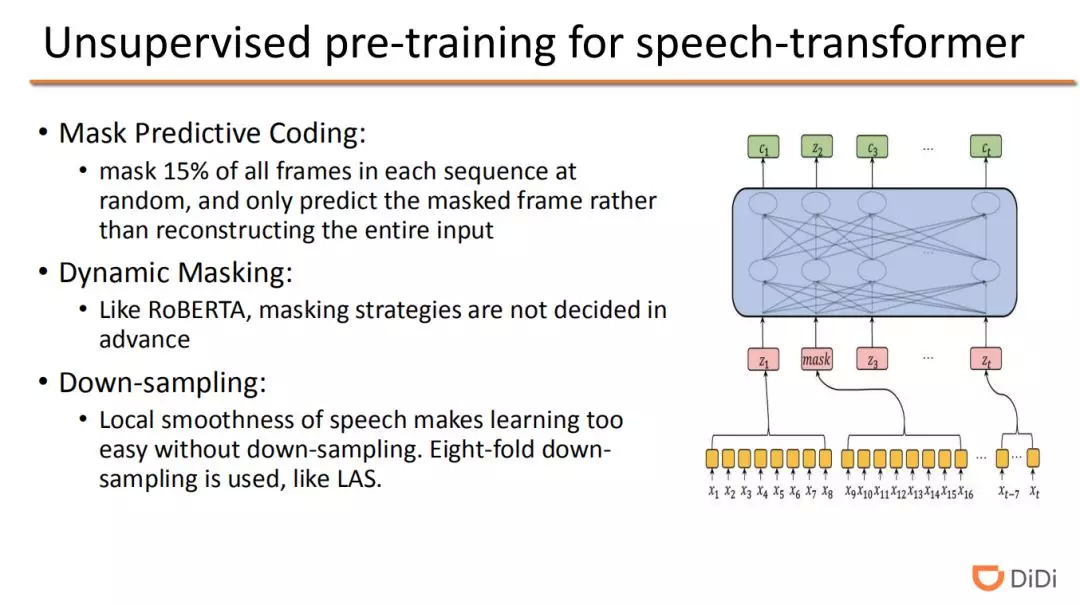
由于语音识别任务和 NLP 任务的相似性,BERT 的思想也可以对应应用到语音识别中,其中一个例子就是 MPC 预训练算法。MPC 使用的是类似于 Masked-LM(MLM)的架构。和 BERT 相似,研究者随机对每段语音特征的 15% 的帧也进行了 mask 操作,根据上下文只预测 masked 的部分而不需要重构整个输入特征。研究中还采用了动态掩码,无需预先设定 mask 策略,即在每次一个序列被输入进模型的时候对其进行掩码。
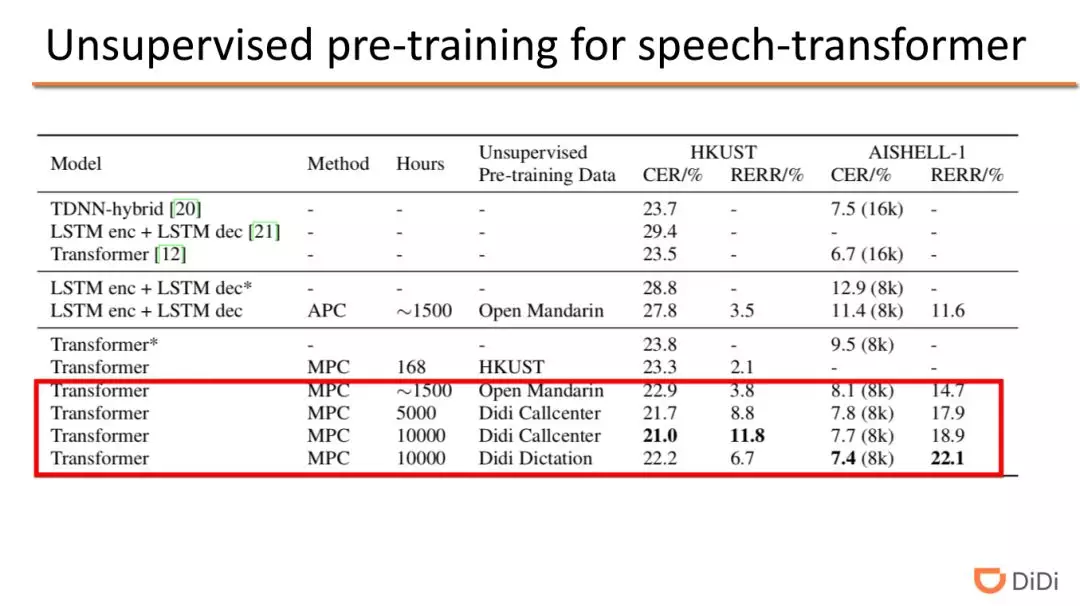
根据实验数据可知,通过使用预训练 MPC 的 transformer 模型比没有使用预训练方式的 transformer 模型在 HKUST 数据集效果更好,错误率由 23.5%降低到 21%。
语音识别发展的趋势基本上与 NLP 类似,本质上都是处理序列到序列的问题,所以语音识别中可以借鉴很多 NLP 的经验。
语音识别相关的任务
1. 信号的处理
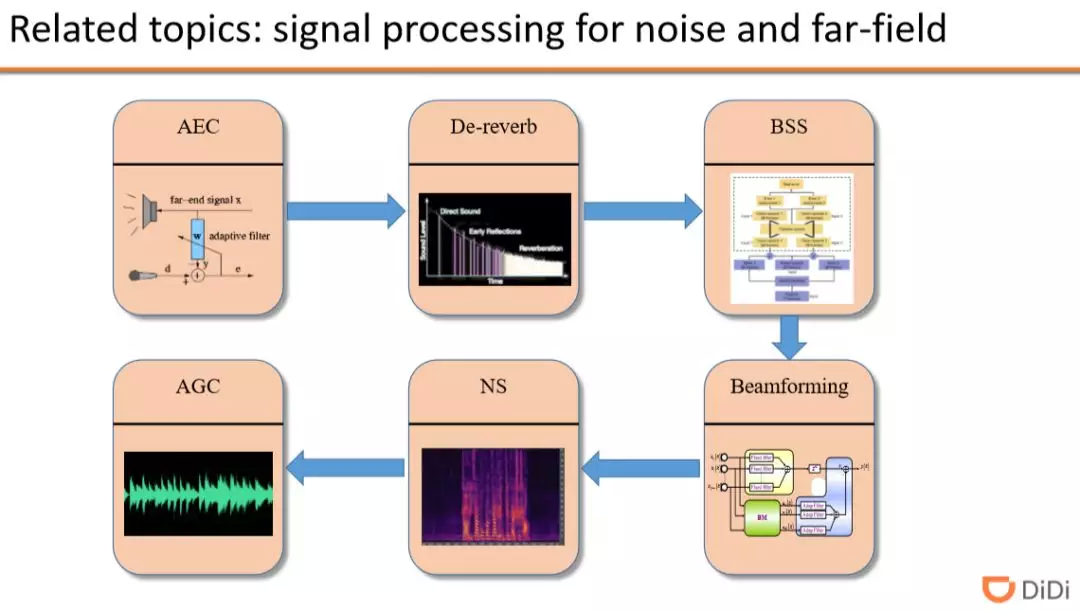
虽然深度学习神经网络模型能够实现端对端的训练方式,但在主流语音系统中,依然离不开一个完整的语音信号处理系统。
通常语音信号处理通常包含:
AEC(回声消除):如果用于识别的设备,在识别语音时本身在播放音乐或者音频,此时对于识别的语音输入就有回声的存在,需要使用回声消除,得到纯净的输入语音
De-reverb(去混响):在相对小一点的房间中录音,会有混响的存在,混响严重时会影响语音识别的效果
Beamforming:多通道信号合并
NS:降噪
AGC:声音信号幅度的自动变化,如声音远近的不同

在做远场语音信号处理的时候,经过以上的几个步骤之后,再通过数学的模拟,把其他场景的音频适配到对应场景的任务,从而增加模型的鲁棒性。
2. 多模态
在语音识别中,语音和文本的多模态是最常用的多模态,被广泛应用到多个场景中。

滴滴最新论文[2]中提出的多模态模型,如上图所示,黄色部分是语音的 encoder 部分,先通过音频提取(MFCC)得到低维度基于帧的特征,然后利用 BiLSTM 得到基于帧进行高维特征表示;绿色部分是文本的 encoder 部分,先通过预训练方式获取文本的 embedding 向量表示,然后通过 BiLSTM 对识别的文本基于单词进行高维特征表示;蓝色部分是多模态融合网络,包括 attention 网层和用于序列分类的 LSTM 网络,attention 机制可以动态学出语音帧和文本特征之间的对齐权重,得到单词对应的语音特征向量,然后将对齐的特征向量和文本隐含状态拼接在一起形成组合多模态特征向量,并用 BiLSTM 进行融合,之后进入最大池化和全连接层进行分类。
本次分享就到这里,谢谢大家!
参考资料
[1] End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results
[2] Learning Alignment for Multimodal Emotion Recognition from Speech
问答环节
Q:老师,根据您刚才介绍的这种端到端的模型,比如 BERT,在后端部署时有没有遇到实时性的问题呢?
A:这个要根据任务来分别处理,语音识别任务分为两类,一类是流式任务(streaming),这类任务要求用户在说话的同时快速的给出对应的文字,这种任务的延迟要求一般在 300~500ms 以内,否则用户会感觉很慢,这种情况下根据 CPU 设置并发线程,即使没有用户说话也不会开太多线程,就是为了保证实时性;第二种任务是离线任务,比如有一段音频,只要在限定时间内分析出来就可以。在客服录音质检任务中,只要在整个电话结束时识别出结果就可以满足要求。这种任务后台部署会相对容易一些,比如收到一个请求任务,只要由空闲的机器就直接分配过去执行语音识别的操作就可以了。
作者介绍:
李先刚
滴滴出行 | 首席算法工程师
本文来自 DataFunTalk
原文链接:
https://mp.weixin.qq.com/s/NoKaBQssgd3uvgKzDvXnNg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论