

简介
近年来,短视频领域一直广受关注,且发展迅速。每天有大量 UGC 短视频被生产、分发和消费,为生产系统带来了巨大的压力,其中的难点之一就是为每个短视频快速、准确地打上标签。为了解决人工编辑的时效和积压问题,自动化标签技术成为各大内容领域公司都非常关注的关键课题。短视频大规模层次分类作为内容理解技术的一个重要方向,为爱奇艺的短视频智能分发业务提供着强力支持,其输出被称为“类型标签”。
以下是我们对一条爱奇艺短视频的分类效果:

算法结果:游戏-题材-角色扮演,与人工结果一致。其实“漫威”、“蜘蛛侠”这类 IP 的作品既可能是“影视”也可能是“游戏”,或者其他周边,如果缺乏背景知识,人工也不容易做出准确的分类,但是模型由于见到了足够多的样本,反而比单个人工有更大概率做出正确判断,在一定程度上体现了集体智慧和算法的优势。
类型标签在爱奇艺内部有着广泛的应用。
在短视频生产领域,类型标签从视频的生成、准入、审核、标注等多个方面发挥着重要作用。
标签自动化:部分标签的准确率已经达到 95%以上,这部分标签已经用算法结果替代人工标注,减少了大量标注人力,提高了视频生产效率;
频道自动化:目前的频道由上传者填写,上传者会投机取巧乱填频道导致频道混乱,影响用户的使用体验,使用类型标签替换频道,提升了频道的分类准确率。
由于准确率很高,短视频生产系统乐高已经部分将自动化标签代替人工标签,并推送到各个业务线,支持着大量业务的智能运营策略。
在个性化推荐领域,已使用算法生成的类型标签全面替代人工标注的频道,成为推荐系统最重要的基础数据之一,在以下的策略中发挥了重要作用。
多样性控制:使用标签完成多样性控制,减少相似内容对用户带来的疲劳,提升播放时长等关键业务指标和多样性等生态指标;
用户画像:基于标签完善用户的长期兴趣和短期兴趣,提升用户画像的完整性、准确性和可解释性;
召回:增强无用户行为的新视频的分发能力,提升用户兴趣探索阶段的泛化性,提升用户的负向兴趣过滤的泛化性,从而提升用户体验;
排序:基于画像的用户兴趣和视频类型标签作为模型的特征,增强排序模型的排序效果。
本文将详细介绍爱奇艺短视频大规模层次分类算法。
技术难点
分类体系复杂
短视频分类体系是一棵人工精心制定的层次结构,体系和规则都比较复杂:层级最少有 3 级,最多有 5 级,总计近 800 个有效类别,类别间有互斥和共同出现的需求。
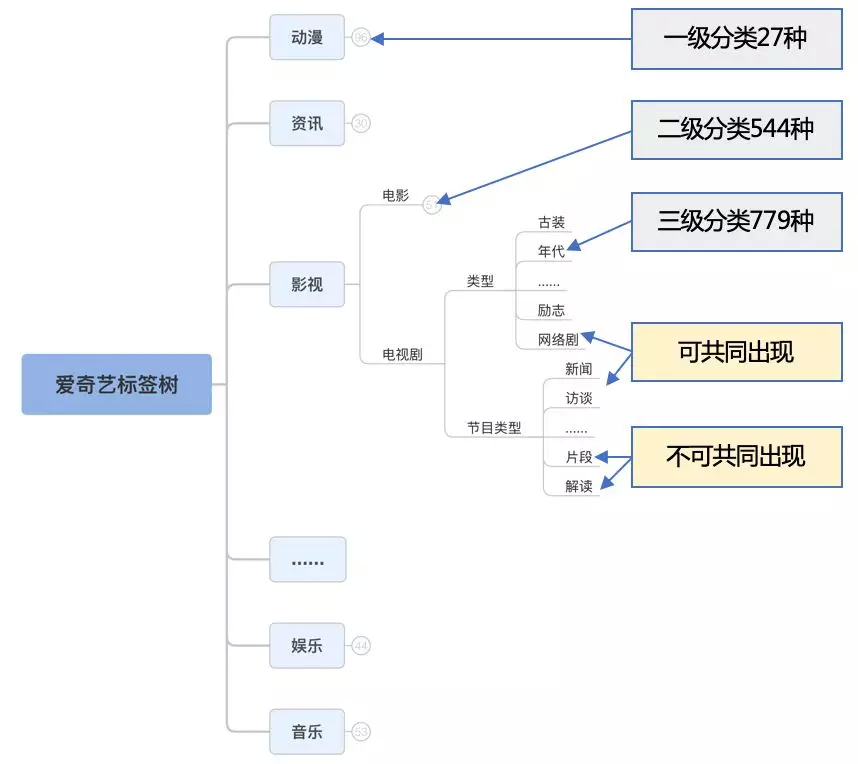
需要文本、图像、生态信息等多模态特征综合判断
短视频具有标题、描述、封面图、视频、音频等媒体信息。同时,一个短视频也不一定是独立存在的,它可能来自一个影视、综艺片段,它的上传者可能是一个垂直领域的内容贡献者,所以,关联正片、视频来源、上传者等信息对分类也可能有帮助。
解决方案
短视频分类可以分为特征表示(Feature Representation) 和层次分类(Hierarchical Classification) 两个模块,前者基于多模态特征建模短视频的整体表达(在我们的模型中通过 Feature Representation 和 Representation Fusion 两个子网络级联建模完成),后者基于前者完成分类任务。我们模型的整体结构如下图:
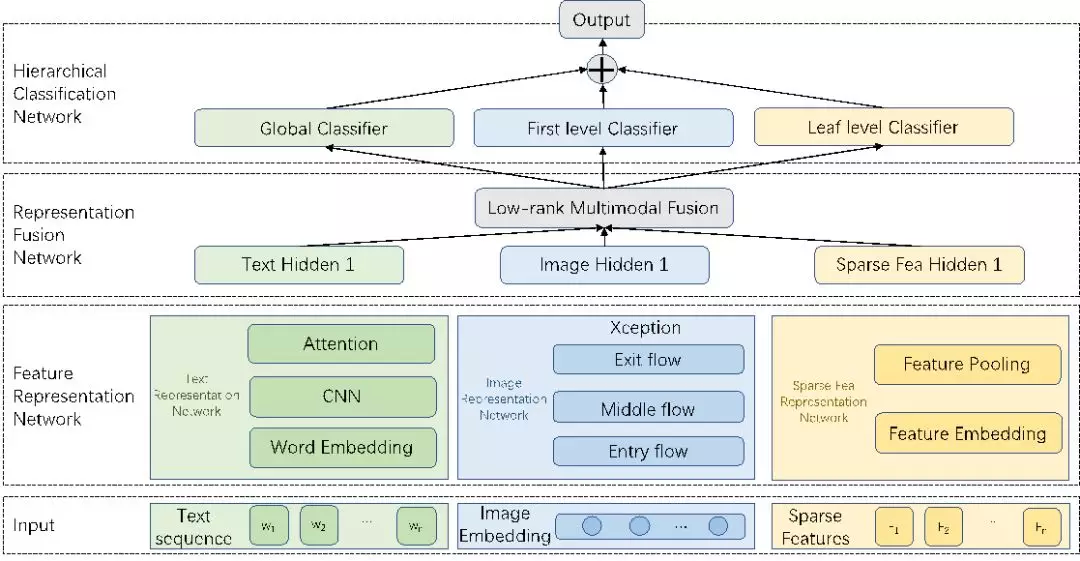
下文将分别介绍这两个模块。
特征表示模块
短视频的特征种类和形态各异,只有正确使用这些信息才能提升模型效果的天花板,下文将介绍各种特征表示的建模方式以及融合方式。
01 文本表示
短视频一般都有一个代表其视频意义的简短标题和更为详细的描述信息,通过对这些人工抽象出的文本信息进行分类会比直接从视频学习出分类更容易。下文将首先介绍业界常见的文本表建模方式,然后分享在我们任务中采用的方案。
业界常见建模方式:
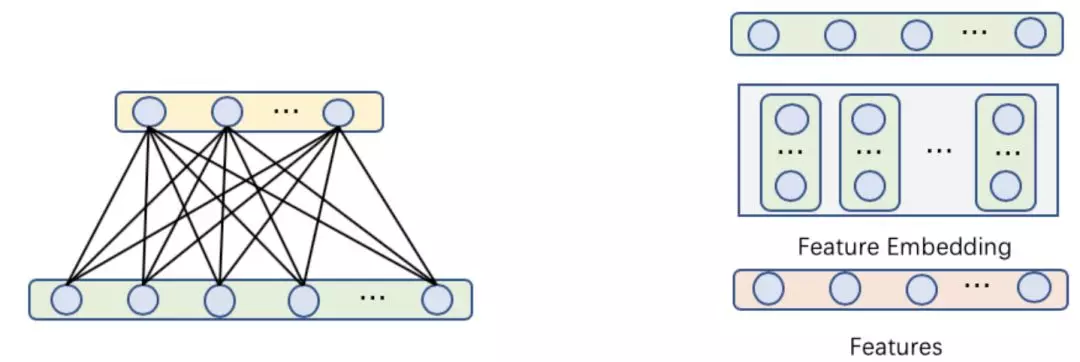
1.BOW
Bag-of-words model 忽略掉文档的语法和语序等要素,将其仅仅看作是若干个词汇的集合,每个单词的出现都是独立的,由一组无序的单词(words)来表达。实际操作上可以直接使用线性分类(单层 NN,下左图)或者嵌入到一个词向量空间中进行 AVG 等操作后再进行分类(CBOW,多层 NN,下右图)。由于模型假设文档是一个词袋,忽略了出现的顺序和组合,所以在构建特征时,可以考虑将表示了词组的 ngram 和词共现的组合特征放入模型中,提高模型的效果。
优点:建模容易,性能好,在使用了大量人工构造的特征后也可以达到极佳的效果。
缺点:过渡依赖人工特征的构造,构造的人工特征可能因为过大,在模型训练上带来困难。
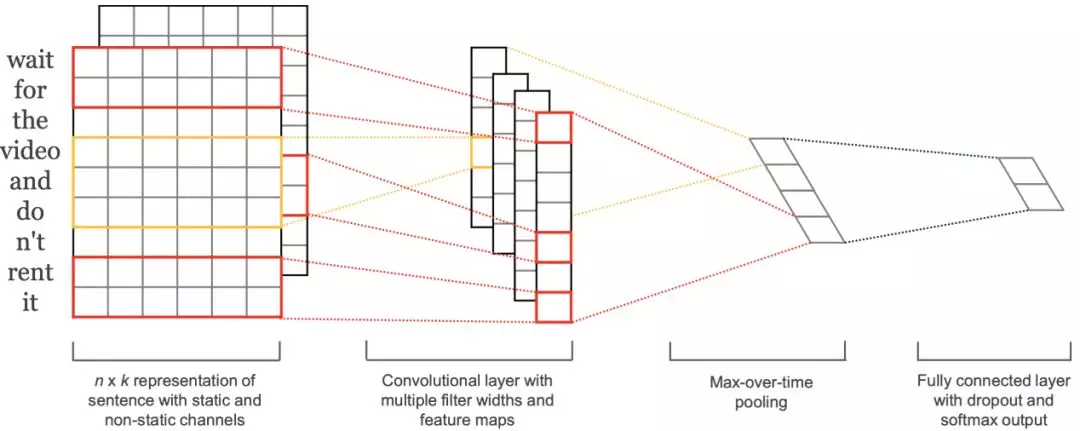
2.CNN
利用 CNN 对文本建模表示进行分类是源自图像领域 CNN 取得的巨大成功,但是在文本领域仅用 CNN 进行文本建模效果并不突出。CNN 通过不同大小的 filter 对有序的词向量进行卷积操作,以期望模型能够从中学到不同大小的 ngram 信息,并且通过 pooling 操作(一般是 max-pooling),找到最强的信号,作为该文本的表示。
优点:建模比较容易,性能不差。
缺点:模型效果上限较低,对长距离共现信息建模较差。
3.RNN
利用 RNN(GRU/LSTM)进行文本建模,理论上具有最高的天花板,在实操上效果也介于 CNN 和精选了人工特征的 BOW,以 LSTM 为例,其不仅对词序敏感,并且具有长短记忆功能,能够将短距离的 ngram 信息和长距离的共现信息学习到。
优点:模型效果上限高,效果较好。
缺点:建模和训练较难,运行时间慢,在大数据集训练实用性不高。
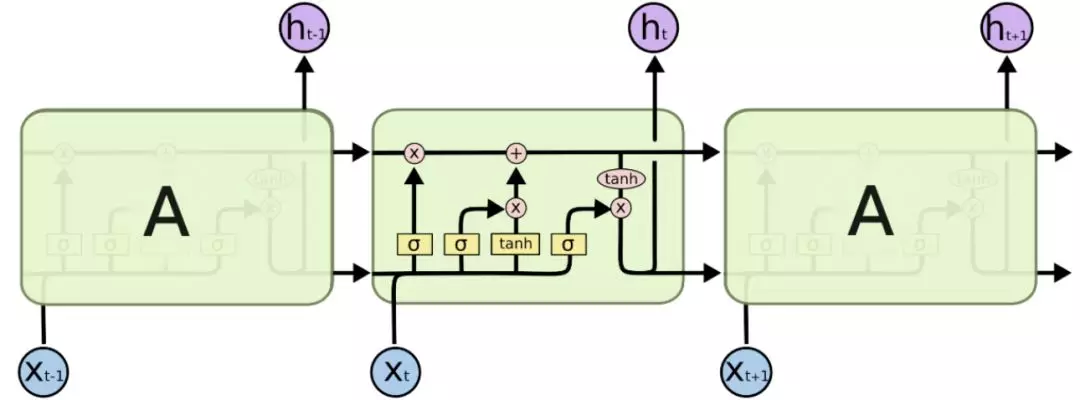
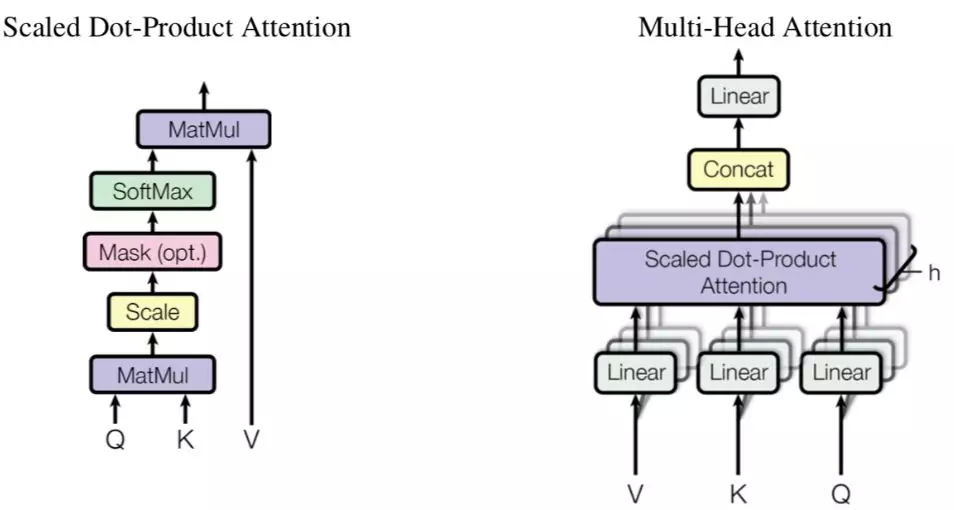
4.Attention
使用 Attention 可以对长距离的共现信息进行建模,并且能够识别整个序列中最为关注的部分,该技术可以和上述的 CNN 和 RNN 这种与序列有关的技术配合使用,能够取得更好的效果,下图是典型的基于点积的(多头)注意力机制。
优点:建模难度一般(Attention 实现方式多种多样),几乎总是能够提升模型效果。
缺点:无明显缺点,可以和其他模型共用。
我们的建模方式:
权衡模型的执行效率和效果,最终类型标签采用的是 BOW 和 CNN+Attention 方式完成文本表示的建模。
1.CBOW 与人工特征构造
前面已经提到 BOW 在使用了大量人工构造的特征后也可以达到极佳的效果,所以我们也尝试了很多人工/机器构造的特征:
(1) 字、词特征,用以提高模型的泛化能力
(2) Ngram 特征,提供片段特征
(3) 词对特征,提供远距离组合特征
(4) 经过 gbdt 学习到的组合特征,更高维的组合特征
(5) 一些 ID 类的离散特征我们也一起和字和词组合到一起
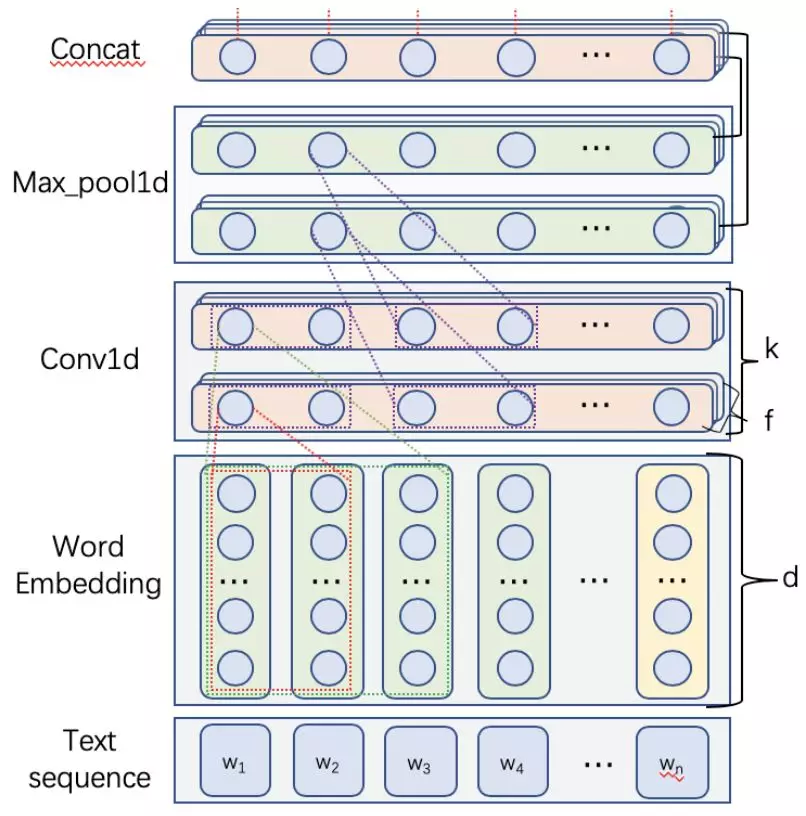
2.带位置信息的 CNN
普通的 TextCNN 使用的 Max Pooling 是全文进行,忽略了文本表达的顺序信息,我们将 Max Pooling 以一定步长进行,提取出每个位置上的文本表示。
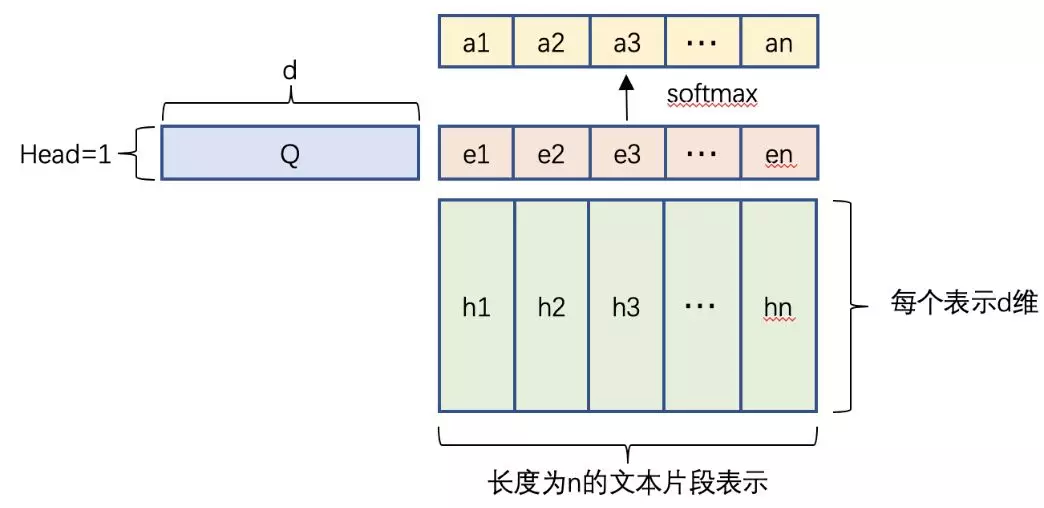
3.Self-Attention
基于 CNN 提取出的带位置信息的文本表示,我们加入 Attention 结构,组合不同位置的文本表示,并且让模型识别应该关注哪个部分。
02 图像表示
短视频数据存在的文不对题、标题描述类型区分力弱的问题,这些问题都对模型的学习带来较大的困难。封面图作为从短视频中精选的一帧,能够在一定程度上代表短视频主题的意义,并且与文本具有互补性,如果能够从其中识别图像表征,补充到类型标签分类任务,应该能够提升模型的分类效果。
表达融合方式:
对图像进行表征,并融合到分类模型中,目前业界非常流行的做法是基于预训练的 ImageNet 模型在训练数据较少的目标任务上进行迁移学习,有 3 种方式:
特征抽取
实现方式:把 ImageNet 预训练的模型作为特征抽取器,将模型的某一层或者某几层特征作为类型标签模型特征提取源。
优点:预训练模型容易获取,不需要训练模型,只需要进行特征抽取,上线速度快。
缺点:模型效果差,需要选择抽取那一层的输出作为抽取的特征,需要保留的特征如果很多的话,特征保存的开销会很大。
FineTune+特征抽取
实现方式:把 ImageNet 预训练的模型以类型标签为目标进行 FineTune,然后将模型的某一层或者某几层特征作为类型标签模型特征提取源(因训练目标一致,一般选择最后一层即可达到较好的效果)。
优点:模型效果好,输出的特征维度低,容易储存。
缺点:FineTune 耗时较大。
模型融合
实现方式:把 ImageNet 预训练的模型嵌入到类型标签的模型当中,让图像的表示和其他特征的表示同时进行训练。
优点:效果最好,End2End 完成最终的上线模型。
缺点:模型训练调参困难,并且耗时巨大。
基于上述 3 种方式的介绍和分析,我们尝试了 1、2 两种方式,最终采纳了第 2 种方式。
模型选择:
图像模型的好坏直接影响到最终提取的图像特征的效果,需要选择一个效果与效率都很高的模型来完成我们的任务,在项目中我们尝试了 ResNet50 和 Xception 两个模型,并且最终选择后者,后者在我们的场景中训练、预测耗时接近,Accuracy 高 3%。
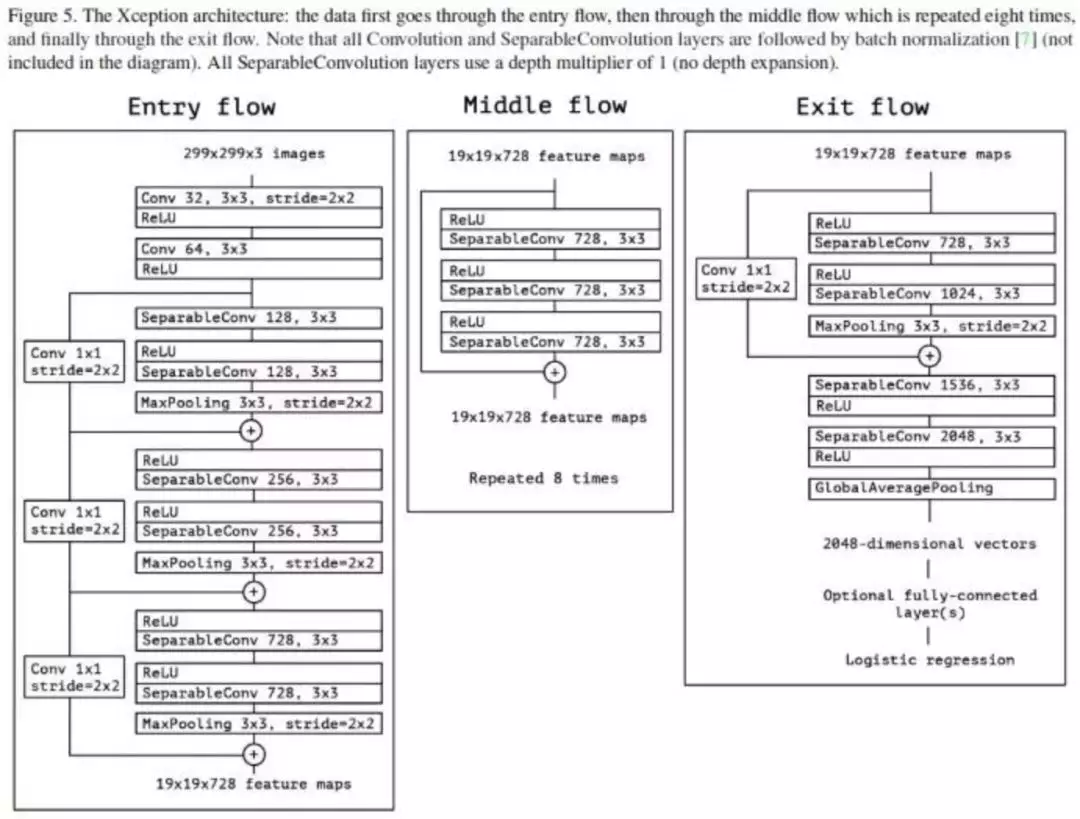
特征融合:
通过上述不同的特征表达方式,每一种特征都被映射为了一个向量,一种好的特征融合方式可以提升表示的整体效果,为此我们尝试了 3 种方案,并最终采用了 LMF 模型。
1.Concatenate
顾名思义,这种方式就是将每种表达连接到一起后连接全连接学习整体的表达,这种方式简单,并且能够提供一个不错的基线。

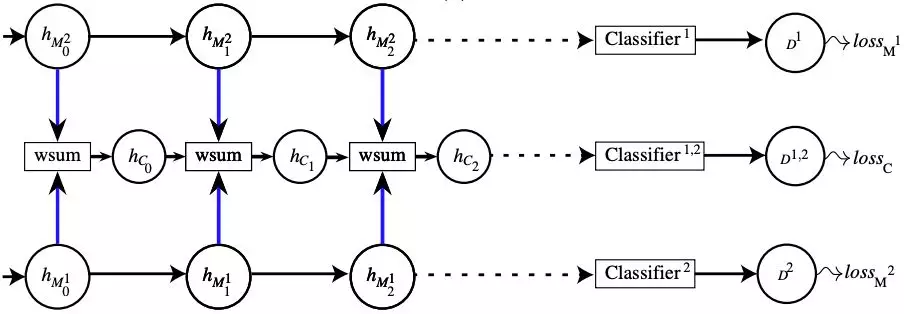
2.CentralNet[6]
该模型借助多任务对每个模态的表达进行约束,以期 Fusion 后的表达能够获取更好的泛化能力,相对于 Concatenate 有 1%的效果提升,模型示例如下:
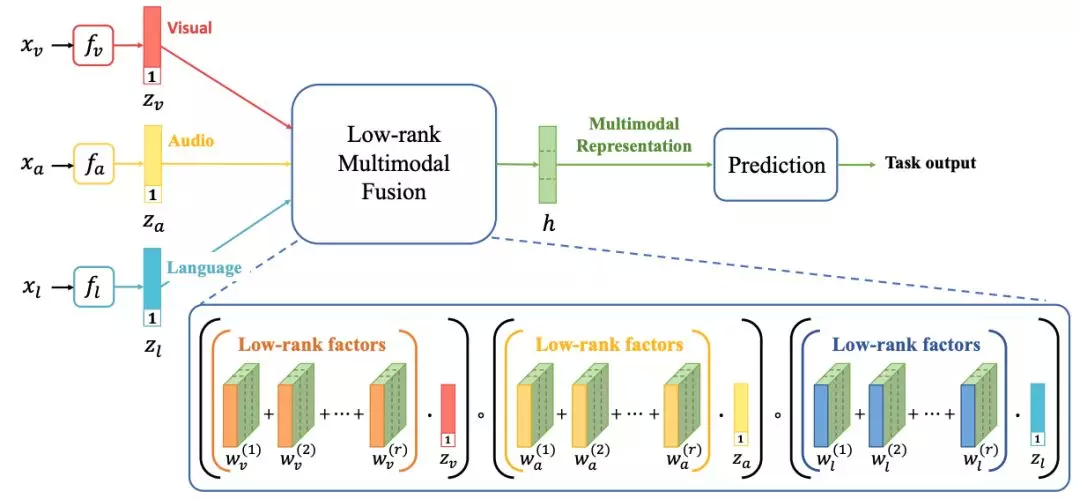
3.LMF[7]
LMF(Low-rank Multimodal Fusion)通过将 N 个模态的外积运算近似等价为内积和按位相乘的运算实现特征的全组合,相对于 CentralNet 有 0.2%的效果提升,模型示例如下:
层次分类模块
下文将首先介绍业界常见层次分类建模方式,然后分享在我们任务中采用的方案。
业界常见建模方式:
对于层次分类,业界常见的有 4 大类方法。
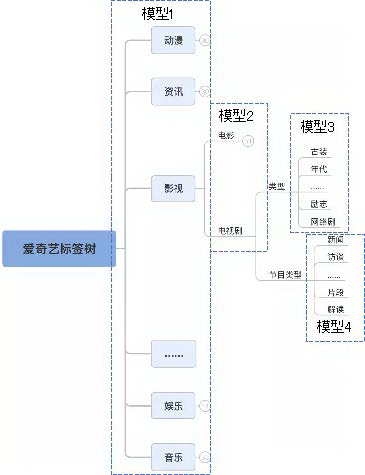
1.弹珠机模型
分类树的每个非叶子节点都有一个独立的模型,利用分类信息做数据的划分。优点是扩展性好,但是由于仅从样本维度使用层次信息,未能共享特征表达,而且模型数量和层次结构体系对应,在我们的应用场景中,需要数量巨大的独立模型,代表论文[1]。以下图为例,预测过程为:
(1) 模型 1 预测为影视
(2) 模型 2 预测为电视剧
(3) 模型 3、模型 4 分别预测为古装和解读
2.级联策略
低层级模型的输出作为高层级模型的特征,仅从分类结果维度使用层次信息,信息利用率低,实验效果不佳。代表论文[2],[3]。
3.正则化约束
通过正则化约束,通过让有上下级关系的分类模型的参数具有符合该正则化约束的相似性,正则化方式通过人工先验知识确定,无法让模型学习,正则化罚项超参也需要人工调整,实验代价大,效果不佳。代表论文[4]。
4.多任务
将各层级分类的多个任务合并,以共享模型参数方式学习模型的层次结构,共享样本信息和模型参数,使用合并的 Loss 驱动模型调整参数,完成层次结构信息的使用。代表论文[5]。
我们的解决方案:DHMCN
(Dense Hierarchical Multilabel Classification Network)
结合实际应用场景,经过多次迭代升级,形成了最终的解决方案。
V1:上文提到的多任务模型(HMC):其核心思想可以简化为采用多任务来分别学习一级、叶子的 global 和 local 表示。
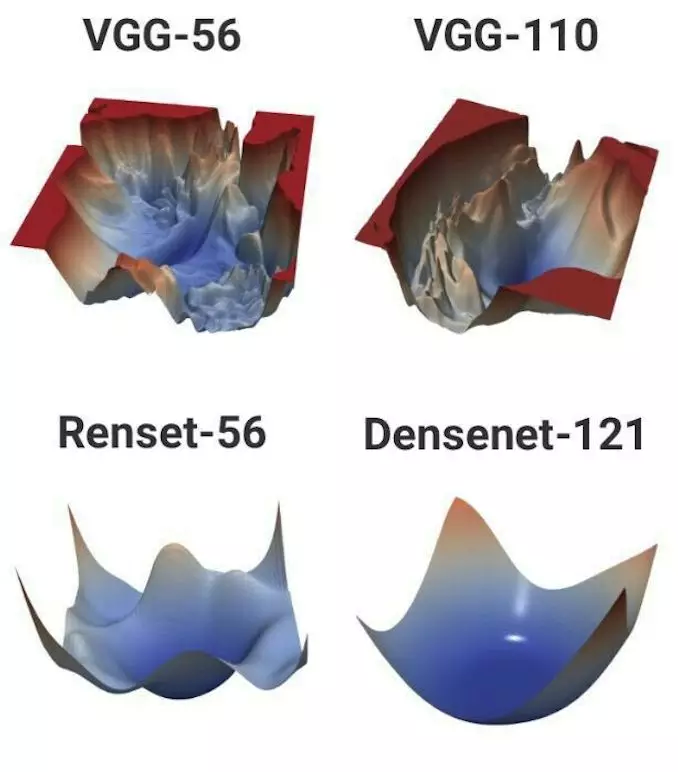
V2:借鉴 DenseNet 的思想,尝试让层级间的连接更加的丰富,让模型更加容易收敛,而不会陷入局部最优解。下图是一个可视化的解释:
下图为我们构建的基于多任务的层次分类网络:
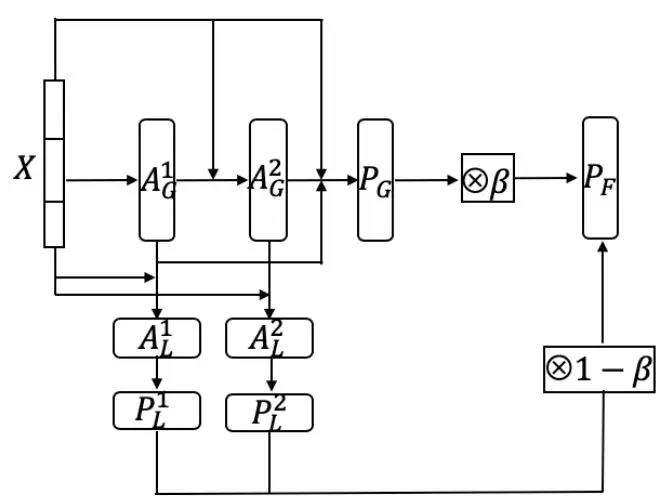
其中:
X 是短视频的表达,具体构建方式前文已经介绍
AG1和 AG2分别表示 Global 的 1 级和末级分类的隐层表达,PG表示 Global(所有)的分类概率
AL1和 AL2分别表示 Local 的 1 级和末级的分类的隐层表达,PL1和 PL2分别表示 1 级和末级分类的概率
训练的 Loss 由 PG,PL1和 PL2三者与 GroundTruth 计算交叉熵得出
PF表示合并了 Local 和 Global 的最终分类概率
V3:借鉴级联策略,用一级表示形成权重去指导叶子节点的分类,这样叶子节点就只用专注在某一级的内部去分类,相当于把其他无关的分类全 mask 掉。
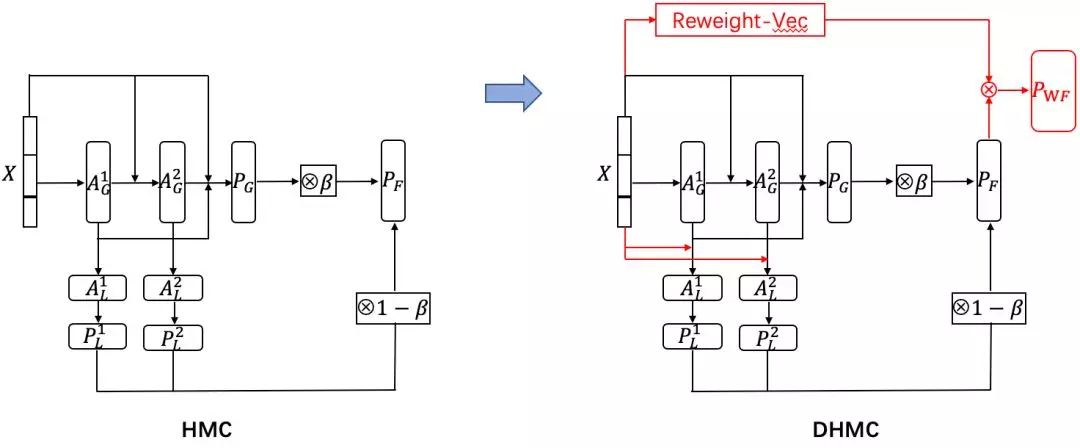
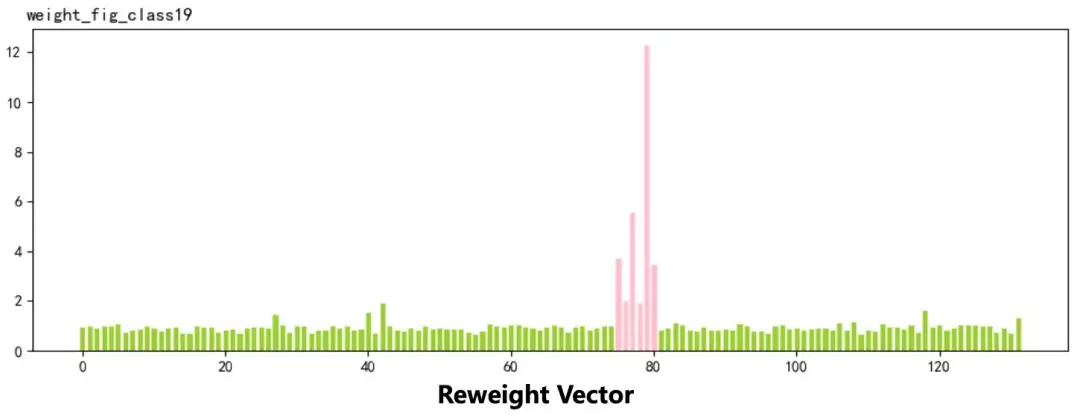
这是一个端到端的自动学习,我们通过可视化权重,发现学习到的 Reweight Vector 符合我们的预期:模型在预测出一级分类为 19 号分类时发现应该提升该分类对应的叶子分类的置信度(如下图)。
后续工作
对于长度较短的短视频,将引入视频和音频特征,保证线上服务性能的情况下提升分类效果
对于样本较少的分类,将引入用户搜索、推荐 Session 行为进行训练获取初始化的短视频表达,然后基于该表达继续训练
更加充分的使用视频之间的关系进行训练(同一专辑、剧集、综艺、UP 主等)
参考文献
[1] S. Dumais and H. Chen. Hierarchical classification of web content. In ACM SIGIR, 2000.
[2] P.N. Bennett and N. Nguyen. Refined experts: improving classification in large taxonomies. In SIGIR, 2009.
[3] Tengke Xiong and Putra Manggala. Hierarchical Classification with Hierarchical Attention Networks. In KDD, 2018.
[4] Siddharth Gopal and Yiming Yang. 2013. Recursive regularization for large-scale classification with hierarchical and graphical dependencies. In KDD. 257–265.
[5] J. Wehrmann, R. Cerri, and R. C. Barros. Hierarchical multi-label classification networks. Proceedings of the 35th International Conference on Machine Learning (ICML), pages 5075–5084, 2018.
[6] V. Vielzeuf, A. Lechervy, S. Pateux, and F. Jurie. Centralnet: a multilayer approach for multimodal fusion. In ECCV Workshop, 2018.
[7] Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, AmirAli Bagher Zadeh, and Louis-Philippe Morency. 2018. Efficient lowrank multimodal fusion with modality-specific factors. In Proceedings of the 56th Annual Meeting of the Associatio
本文转载自公众号爱奇艺技术产品团队(ID:iQIYI-TP)。
原文链接:
https://mp.weixin.qq.com/s/t801Q3OO_DBrgI60fKSJxQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论