

前言
Lucene 是一个基于 Java 的全文信息检索工具包,目前主流的搜索系统 Elasticsearch 和 solr 都是基于 lucene 的索引和搜索能力进行。想要理解搜索系统的实现原理,就需要深入 lucene 这一层,看看 lucene 是如何存储需要检索的数据,以及如何完成高效的数据检索。
在数据库中因为有索引的存在,也可以支持很多高效的查询操作。不过对比 lucene,数据库的查询能力还是会弱很多,本文就将探索下 lucene 支持哪些查询,并会重点选取几类查询分析 lucene 内部是如何实现的。为了方便大家理解,我们会先简单介绍下 lucene 里面的一些基本概念,然后展开 lucene 中的几种数据存储结构,理解了他们的存储原理后就可以方便知道如何基于这些存储结构来实现高效的搜索。本文重点关注是 lucene 如何做到传统数据库较难做到的查询,对于分词,打分等功能不会展开介绍。
本文具体会分以下几部分:
介绍 lucene 的数据模型,细节可以参阅 lucene 数据模型一文。
介绍 lucene 中如何存储需要搜索的 term。
介绍 lucene 的倒排链的如何存储以及如何实现 docid 的快速查找。
介绍 lucene 如何实现倒排链合并。
介绍 lucene 如何做范围查询和前缀匹配。
介绍 lucene 如何优化数值类范围查询。
Lucene 数据模型
Lucene 中包含了四种基本数据类型,分别是:
Index:索引,由很多的 Document 组成。
Document:由很多的 Field 组成,是 Index 和 Search 的最小单位。
Field:由很多的 Term 组成,包括 Field Name 和 Field Value。
Term:由很多的字节组成。一般将 Text 类型的 Field Value 分词之后的每个最小单元叫做 Term。
在 lucene 中,读写路径是分离的。写入的时候创建一个 IndexWriter,而读的时候会创建一个 IndexSearcher。
IndexWriter
先看下 Lucene 中如何使用 IndexWriter 来写入数据,上面是一段精简的调用示例代码,整个过程主要有三个步骤:
初始化:初始化 IndexWriter 必要的两个元素是 Directory 和 IndexWriterConfig,Directory 是 Lucene 中数据持久层的抽象接口,通过这层接口可以实现很多不同类型的数据持久层,例如本地文件系统、网络文件系统、数据库或者是分布式文件系统。IndexWriterConfig 内提供了很多可配置的高级参数,提供给高级玩家进行性能调优和功能定制,它提供的几个关键参数后面会细说。
构造文档:Lucene 中文档由 Document 表示,Document 由 Field 构成。Lucene 提供多种不同类型的 Field,其 FiledType 决定了它所支持的索引模式,当然也支持自定义 Field,具体方式可参考上一篇文章。
写入文档:通过 IndexWriter 的 addDocument 函数写入文档,写入时同时根据 FieldType 创建不同的索引。文档写入完成后,还不可被搜索,最后需要调用 IndexWriter 的 commit,在 commit 完后 Lucene 才保证文档被持久化并且是 searchable 的。
以上就是 Lucene 的一个简明的数据写入流程,核心是 IndexWriter,整个过程被抽象的非常简洁明了。一个设计优良的库的最大特点,就是可以让普通玩家以非常小的代价学习和使用,同时又照顾高级玩家能够提供可调节的性能参数和功能定制能力。
IndexWriterConfig
IndexWriterConfig 内提供了一些供高级玩家做性能调优和功能定制的核心参数,我们列几个主要的看下:
IndexDeletionPolicy:Lucene 开放对 commit point 的管理,通过对 commit point 的管理可以实现例如 snapshot 等功能。Lucene 默认配置的 DeletionPolicy,只会保留最新的一个 commit point。
Similarity:搜索的核心是相关性,Similarity 是相关性算法的抽象接口,Lucene 默认实现了 TF-IDF 和 BM25 算法。相关性计算在数据写入和搜索时都会发生,数据写入时的相关性计算称为 Index-time boosting,计算 Normalizaiton 并写入索引,搜索时的相关性计算称为 query-time boosting。
MergePolicy:Lucene 内部数据写入会产生很多 Segment,查询时会对多个 Segment 查询并合并结果。所以 Segment 的数量一定程度上会影响查询的效率,所以需要对 Segment 进行合并,合并的过程就称为 Merge,而何时触发 Merge 由 MergePolicy 决定。
MergeScheduler:当 MergePolicy 触发 Merge 后,执行 Merge 会由 MergeScheduler 来管理。Merge 通常是比较耗 CPU 和 IO 的过程,MergeScheduler 提供了对 Merge 过程定制管理的能力。
Codec:Codec 可以说是 Lucene 中最核心的部分,定义了 Lucene 内部所有类型索引的 Encoder 和 Decoder。Lucene 在 Config 这一层将 Codec 配置化,主要目的是提供对不同版本数据的处理能力。对于 Lucene 用户来说,这一层的定制需求通常较少,能玩 Codec 的通常都是顶级玩家了。
IndexerThreadPool:管理 IndexWriter 内部索引线程(DocumentsWriterPerThread)池,这也是 Lucene 内部定制资源管理的一部分。
FlushPolicy:FlushPolicy 决定了 In-memory buffer 何时被 flush,默认的实现会根据 RAM 大小和文档个数来判断 Flush 的时机,FlushPolicy 会在每次文档 add/update/delete 时调用判定。
MaxBufferedDoc:Lucene 提供的默认 FlushPolicy 的实现 FlushByRamOrCountsPolicy 中允许 DocumentsWriterPerThread 使用的最大文档数上限,超过则触发 Flush。
RAMBufferSizeMB:Lucene 提供的默认 FlushPolicy 的实现 FlushByRamOrCountsPolicy 中允许 DocumentsWriterPerThread 使用的最大内存上限,超过则触发 flush。
RAMPerThreadHardLimitMB:除了 FlushPolicy 能决定 Flush 外,Lucene 还会有一个指标强制限制 DocumentsWriterPerThread 占用的内存大小,当超过阈值则强制 flush。
Analyzer:即分词器,这个通常是定制化最多的,特别是针对不同的语言。
核心操作
IndexWriter 提供很简单的几种操作接口,这一章节会做一个简单的功能和用途解释,下一个章节会对其内部实现做一个详细的剖析。IndexWrite 的提供的核心 API 如下:
addDocument:比较纯粹的一个 API,就是向 Lucene 内新增一个文档。Lucene 内部没有主键索引,所有新增文档都会被认为一个新的文档,分配一个独立的 docId。
updateDocuments:更新文档,但是和数据库的更新不太一样。数据库的更新是查询后更新,Lucene 的更新是查询后删除再新增。流程是先 delete by term,后 add document。但是这个流程又和直接先调用 delete 后调用 add 效果不一样,只有 update 能够保证在 Thread 内部删除和新增保证原子性,详细流程在下一章节会细说。
deleteDocument:删除文档,支持两种类型删除,by term 和 by query。在 IndexWriter 内部这两种删除的流程不太一样,在下一章节再细说。
flush:触发强制 flush,将所有 Thread 的 In-memory buffer flush 成 segment 文件,这个动作可以清理内存,强制对数据做持久化。
prepareCommit/commit/rollback:commit 后数据才可被搜索,commit 是一个二阶段操作,prepareCommit 是二阶段操作的第一个阶段,也可以通过调用 commit 一步完成,rollback 提供了回滚到 last commit 的操作。
maybeMerge/forceMerge:maybeMerge 触发一次 MergePolicy 的判定,而 forceMerge 则触发一次强制 merge。
数据路径
上面几个章节介绍了 IndexWriter 的基本流程、配置和核心接口,非常简单和易理解。这一章节,我们将深入 IndexWriter 内部,来探索其内核实现。
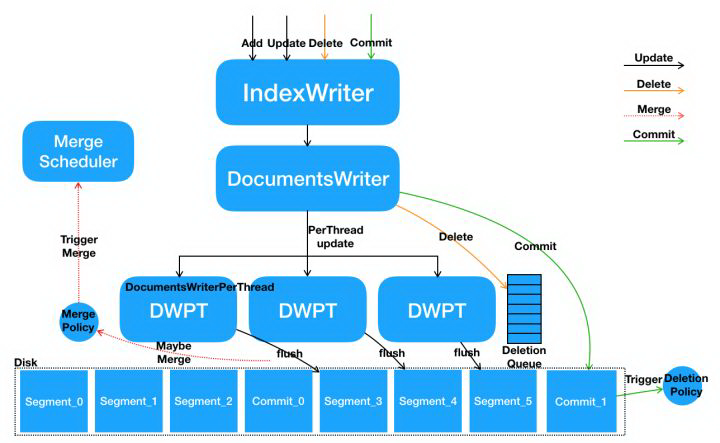
如上是 IndexWriter 内部核心流程架构图,接下来我们将以 add/update/delete/commit 这些主要操作来讲解 IndexWriter 内部的数据路径。
并发模型
IndexWriter 提供的核心接口都是线程安全的,并且内部做了特殊的并发优化来优化多线程写入的性能。IndexWriter 内部为每个线程都会单独开辟一个空间来写入,这块空间由 DocumentsWriterPerThread 来控制。整个多线程数据处理流程为:
多线程并发调用 IndexWriter 的写接口,在 IndexWriter 内部具体请求会由 DocumentsWriter 来执行。DocumentsWriter 内部在处理请求之前,会先根据当前执行操作的 Thread 来分配 DocumentsWriterPerThread。
每个线程在其独立的 DocumentsWriterPerThread 空间内部进行数据处理,包括分词、相关性计算、索引构建等。
数据处理完毕后,在 DocumentsWriter 层面执行一些后续动作,例如触发 FlushPolicy 的判定等。
引入了 DocumentsWriterPerThread(后续简称为 DWPT)后,Lucene 内部在处理数据时,整个处理步骤只需要对以上第一步和第三步进行加锁,第二步完全不用加锁,每个线程都在自己独立的空间内处理数据。而通常来说,第一步和第三步都是非常轻量级的,而第二步是对计算和内存资源消耗最大的。所以这样做之后,能够将加锁的时间大大缩短,提高并发的效率。每个 DWPT 内单独包含一个 In-memory buffer,这个 buffer 最终会 flush 成不同的独立的 segment 文件。
这种方案下,对多线程并发写入性能有很大的提升。特别是针对纯新增文档的场景,所有数据写入都不会有冲突,所以非常适合这种空间隔离式的数据写入方式。但对于删除文档的场景,一次删除动作可能会涉及删除不同线程空间内的数据,这里 Lucene 也采取了一种特殊的交互方式来降低锁的开销,在剖析 delete 操作时会细说。
在搜索场景中,全量构建索引的阶段,基本是纯新增文档式的写入,而在后续增量索引阶段(特别是数据源是数据库时),会涉及大量的 update 和 delete 操作。从原理上来分析,一个最佳实践是包含相同唯一主键 Term 的文档分配相同的线程来处理,使数据更新发生在一个独立线程空间内,避免跨线程。
add & update
add 接口用于新增文档,update 接口用于更新文档。但 Lucene 的 update 和数据库的 update 不太一样。数据库的更新是查询后更新,Lucene 的更新是查询后删除再新增,不支持更新文档内部分列。流程是先 delete by term,后 add document。
IndexWriter 提供的 add 和 update 接口,都会映射到 DocumentsWriter 的 udpate 接口,看下接口定义:
这个函数内的处理流程是:
根据 Thread 分配 DWPT
在 DWPT 内执行 delete
在 DWPT 内执行 add
关于 delete 操作的细节在下一小结详细说,add 操作会直接将文档写入 DWPT 内的 In-memory buffer。
delete
delete 相对 add 和 update 来说,是完全不同的一个数据路径。而且 update 和 delete 虽然内部都会执行数据删除,但这两者又是不同的数据路径。文档删除不会直接影响 In-memory buffer 内的数据,而是会有另外的方式来达到删除的目的。
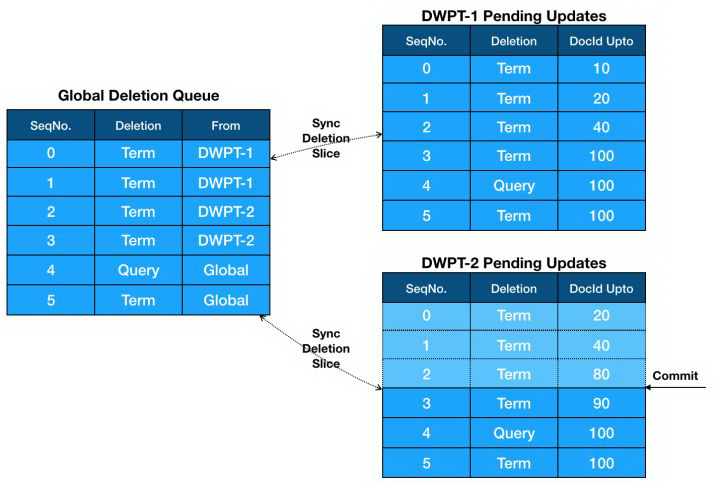
在 Delete 路径上关键的数据结构就是 Deletion queue,在 IndexWriter 内部会有一个全局的 Deletion Queue,称为 Global Deletion Queue,而在每个 DWPT 内部,还会有一个独立的 Deletion Queue,称为 Pending Updates。DWPT Pending Updates 会与 Global Deletion Queue 进行双向同步,因为文档删除是全局范围的,不应该只发生在 DWPT 范围内。
Pending Updates 内部会按发生顺序记录每个删除动作,并且标记该删除影响的文档范围,文档影响范围通过记录当前已写入的最大 DocId(DocId Upto)来标记,即代表这个删除动作只删除小于等于该 DocId 的文档。
update 接口和 delete 接口都可以进行文档删除,但是有一些差异:
update 只能进行 by term 的文档删除,而 delete 除了 by term,还支持 by query。
update 的删除会先作用于 DWPT 内部,后作用于 Global,再由 Global 同步到其他 DWPT。
delete 的删除会作用在 Global 级别,后异步同步到 DWPT 级别。
update 和 delete 流程上的差异也决定了他们行为上的一些差异,update 的删除操作会先发生在 DWPT 内部,并且是和 add 同时发生,所以能够保证该 DWPT 内部的 delete 和 add 的原子性,即保证在 add 之前的所有符合条件的文档一定被删除。
DWPT Pending Updates 里的删除操作什么时候会真正作用于数据呢?在 Lucene Segment 内部,数据实际上并不会被真正删除。Segment 中有一个特殊的文件叫 live docs,内部是一个位图的数据结构,记录了这个 Segment 内部哪些 DocId 是存活的,哪些 DocId 是被删除的。所以删除的过程就是构建 live docs 标记位图的过程,数据实际上不会被真正删除,只是在 live docs 里会被标记删除。Term 删除和 Query 删除会在不同阶段构建 live docs,Term 删除要求先根据 Term 查询出它关联的所有 doc,所以很明显这个会发生在倒排索引构建时。而 Query 删除要求执行一次完整的查询后才能拿到其对应的 docId,所以会发生在 segment 被 flush 完成后,基于 flush 后的索引文件构建 IndexReader 后执行搜索才能完成。
还有一点要注意的是,live docs 只影响倒排,所以在 live docs 里被标记删除的文档没有办法通过倒排索引检索出,但是还能够通过 doc id 查询到 store fields。当然文档数据最终是会被真正物理删除,这个过程会发生在 merge 时。
flush
flush 是将 DWPT 内 In-memory buffer 里的数据持久化到文件的过程,flush 会在每次新增文档后由 FlushPolicy 判定自动触发,也可以通过 IndexWriter 的 flush 接口手动触发。
每个 DWPT 会 flush 成一个 segment 文件,flush 完成后这个 segment 文件是不可被搜索的,只有在 commit 之后,所有 commit 之前 flush 的文件才可被搜索。
commit
commit 时会触发数据的一次强制 flush,commit 完成后再此之前 flush 的数据才可被搜索。commit 动作会触发生成一个 commit point,commit point 是一个文件。Commit point 会由 IndexDeletionPolicy 管理,lucene 默认配置的策略只会保留 last commit point,当然 lucene 提供其他多种不同的策略供选择。
merge
merge 是对 segment 文件合并的动作,合并的好处是能够提高查询的效率以及回收一些被删除的文档。Merge 会在 segment 文件 flush 时触发 MergePolicy 来判定自动触发,也可通过 IndexWriter 进行一次 force merge。
IndexingChain
前面几个章节主要介绍了 IndexWriter 内部各个关键操作的流程,本小节会介绍最核心的 DWPT 内部对文档进行索引构建的流程。Lucene 内部索引构建最关键的概念是 IndexingChain,顾名思义,链式的索引构建。为啥是链式的?这个和 Lucene 的整个索引体系结构有关系,Lucene 提供了各种不同类型的索引类型,例如倒排、正排(列存)、StoreField、DocValues 等。每个不同的索引类型对应不同的索引算法、数据结构以及文件存储,有些是列级别的,有些是文档级别的。所以一个文档写入后,需要被这么多种不同索引处理,有些索引会共享 memory-buffer,有些则是完全独立的。基于这个架构,理论上 Lucene 是提供了扩展其他类型索引的可能性,顶级玩家也可以去尝试。
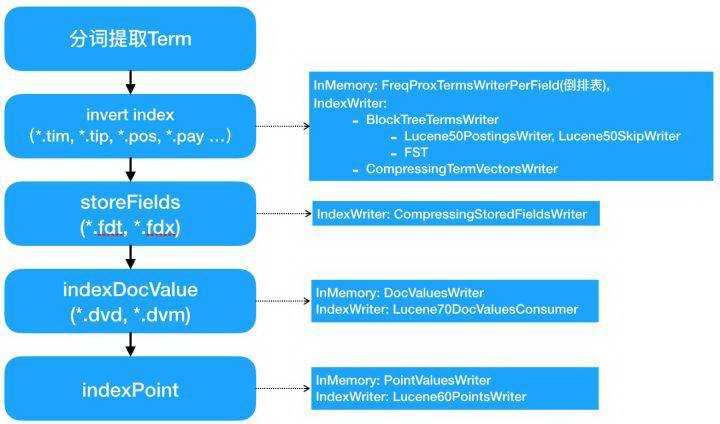
在 IndexWriter 内部,indexing chain 上索引构建顺序是 invert index、store fields、doc values 和 point values。有些索引类型处理文档后会将索引内容直接写入文件(主要是 store field 和 term vector),而有些索引类型会先将文档内容写入 memory buffer,最后在 flush 的时候再写入文件。能直接写入文件的索引,通常是文档级的索引,索引构建可以文档级的增量构建。而不能写入文件的索引,例如倒排,则必须等 Segment 内所有文档全部写入完毕后,会先对 Term 进行一个全排序,之后才能构建索引,所以必须要有一个 memory-buffer 先缓存所有文档。
前面提到,IndexWriterConfig 支持配置 Codec,Codec 就是对应每种类型索引的 Encoder 和 Decoder。在上图可以看到,在 Lucene 7.2.1 版本中,主要有这么几种 Codec:
BlockTreeTermsWriter:倒排索引对应的 Codec,其中倒排表部分使用 Lucene50PostingsWriter(Block 方式写入倒排链)和 Lucene50SkipWriter(对 Block 的 SkipList 索引),词典部分则是使用 FST(针对倒排表 Block 级的词典索引)。
CompressingTermVectorsWriter:对应 Term vector 索引的 Writer,底层是压缩 Block 格式。
CompressingStoredFieldsWriter:对应 Store fields 索引的 Writer,底层是压缩 Block 格式。
Lucene70DocValuesConsumer:对应 Doc values 索引的 Writer。
Lucene60PointsWriter:对应 Point values 索引的 Writer。
这一章节主要了解 IndexingChain 内部的文档索引处理流程,核心是链式分阶段的索引,并且不同类型索引支持 Codec 可配置。
总结
以上内容主要从一个全局视角来讲解 IndexWriter 的配置、接口、并发模型、核心操作的数据路径以及索引链。
下面是一个简单的代码示例,如何使用 lucene 的 IndexWriter 建索引以及如何使用 indexSearch 进行搜索查询。
从这个示例中可以看出,lucene 的读写有各自的操作类。本文重点关注读逻辑,在使用 IndexSearcher 类的时候,需要一个 DirectoryReader 和 QueryParser,其中 DirectoryReader 需要对应写入时候的 Directory 实现。QueryParser 主要用来解析你的查询语句,例如你想查 “A and B",lucene 内部会有机制解析出是 term A 和 term B 的交集查询。在具体执行 Search 的时候指定一个最大返回的文档数目,因为可能会有过多命中,我们可以限制单词返回的最大文档数,以及做分页返回。
下面会详细介绍一个索引查询会经过几步,每一步 lucene 分别做了哪些优化实现。
Lucene 查询过程
在 lucene 中查询是基于 segment。每个 segment 可以看做是一个独立的 subindex,在建立索引的过程中,lucene 会不断的 flush 内存中的数据持久化形成新的 segment。多个 segment 也会不断的被 merge 成一个大的 segment,在老的 segment 还有查询在读取的时候,不会被删除,没有被读取且被 merge 的 segement 会被删除。这个过程类似于 LSM 数据库的 merge 过程。下面我们主要看在一个 segment 内部如何实现高效的查询。
为了方便大家理解,我们以人名字,年龄,学号为例,如何实现查某个名字(有重名)的列表。
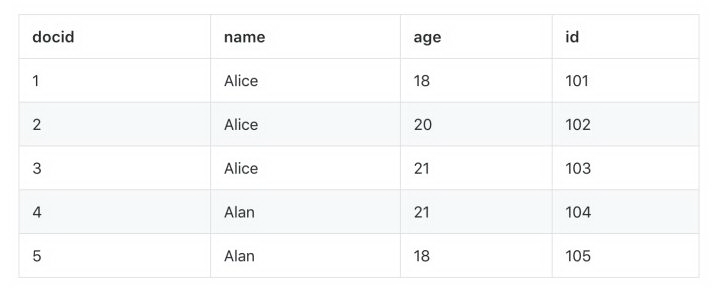
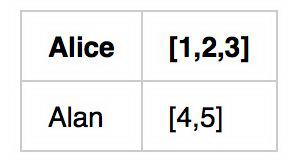
在 lucene 中为了查询 name=XXX 的这样一个条件,会建立基于 name 的倒排链。以上面的数据为例,倒排链如下:
姓名
如果我们还希望按照年龄查询,例如想查年龄=18 的列表,我们还可以建立另一个倒排链:
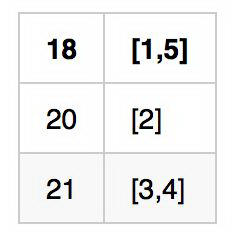
在这里,Alice,Alan,18,这些都是 term。所以倒排本质上就是基于 term 的反向列表,方便进行属性查找。到这里我们有个很自然的问题,如果 term 非常多,如何快速拿到这个倒排链呢?在 lucene 里面就引入了 term dictonary 的概念,也就是 term 的字典。term 字典里我们可以按照 term 进行排序,那么用一个二分查找就可以定为这个 term 所在的地址。这样的复杂度是 logN,在 term 很多,内存放不下的时候,效率还是需要进一步提升。可以用一个 hashmap,当有一个 term 进入,hash 继续查找倒排链。这里 hashmap 的方式可以看做是 term dictionary 的一个 index。 从 lucene4 开始,为了方便实现 rangequery 或者前缀,后缀等复杂的查询语句,lucene 使用 FST 数据结构来存储 term 字典,下面就详细介绍下 FST 的存储结构。
FST
我们就用 Alice 和 Alan 这两个单词为例,来看下 FST 的构造过程。首先对所有的单词做一下排序为“Alice”,“Alan”。
插入“Alan”

插入“Alice”

这样你就得到了一个有向无环图,有这样一个数据结构,就可以很快查找某个人名是否存在。FST 在单 term 查询上可能相比 hashmap 并没有明显优势,甚至会慢一些。但是在范围,前缀搜索以及压缩率上都有明显的优势。
在通过 FST 定位到倒排链后,有一件事情需要做,就是倒排链的合并。因为查询条件可能不止一个,例如上面我们想找 name=“alan” and age="18"的列表。lucene 是如何实现倒排链的合并呢。这里就需要看一下倒排链存储的数据结构
SkipList
为了能够快速查找 docid,lucene 采用了 SkipList 这一数据结构。SkipList 有以下几个特征:
元素排序的,对应到我们的倒排链,lucene 是按照 docid 进行排序,从小到大。
跳跃有一个固定的间隔,这个是需要建立 SkipList 的时候指定好,例如下图以间隔是 3
SkipList 的层次,这个是指整个 SkipList 有几层
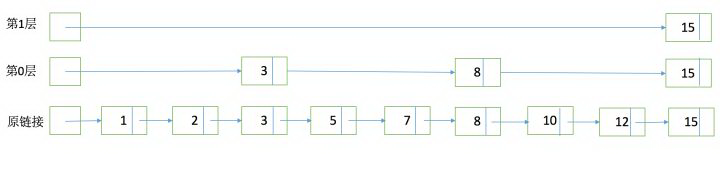
有了这个 SkipList 以后比如我们要查找 docid=12,原来可能需要一个个扫原始链表,1,2,3,5,7,8,10,12。有了 SkipList 以后先访问第一层看到是然后大于 12,进入第 0 层走到 3,8,发现 15 大于 12,然后进入原链表的 8 继续向下经过 10 和 12。
有了 FST 和 SkipList 的介绍以后,我们大体上可以画一个下面的图来说明 lucene 是如何实现整个倒排结构的:
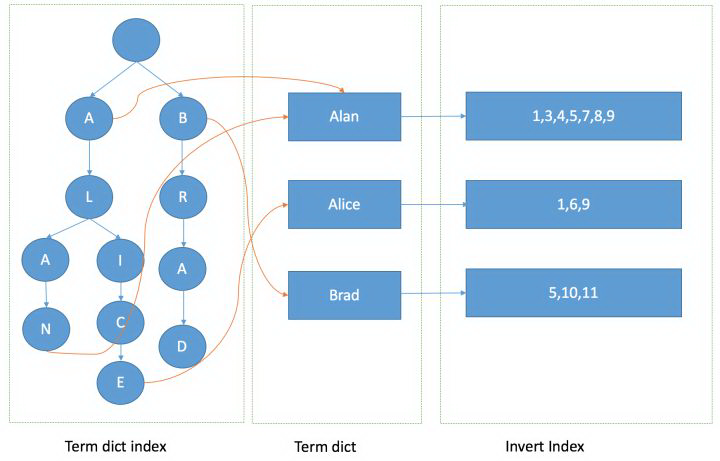
有了这张图,我们可以理解为什么基于 lucene 可以快速进行倒排链的查找和 docid 查找,下面就来看一下有了这些后如何进行倒排链合并返回最后的结果。
倒排合并
假如我们的查询条件是 name = “Alice”,那么按照之前的介绍,首先在 term 字典中定位是否存在这个 term,如果存在的话进入这个 term 的倒排链,并根据参数设定返回分页返回结果即可。这类查询,在数据库中使用二级索引也是可以满足,那 lucene 的优势在哪呢。假如我们有多个条件,例如我们需要按名字或者年龄单独查询,也需要进行组合 name = “Alice” and age = "18"的查询,那么使用传统二级索引方案,你可能需要建立两张索引表,然后分别查询结果后进行合并,这样如果 age = 18 的结果过多的话,查询合并会很耗时。那么在 lucene 这两个倒排链是怎么合并呢。
假如我们有下面三个倒排链需要进行合并。
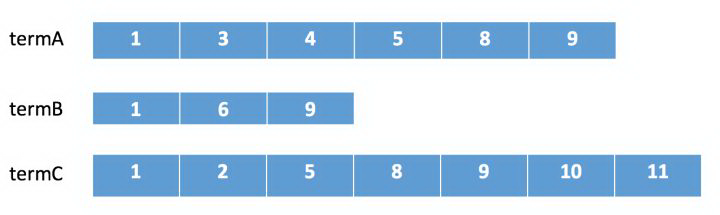
在 lucene 中会采用下列顺序进行合并:
在 termA 开始遍历,得到第一个元素 docId=1
Set currentDocId=1
在 termB 中 search(currentDocId) = 1 (返回大于等于 currentDocId 的一个 doc),
因为 currentDocId ==1,继续
如果 currentDocId 和返回的不相等,执行 2,然后继续
到 termC 后依然符合,返回结果
currentDocId = termC 的 nextItem
然后继续步骤 3 依次循环。直到某个倒排链到末尾。
整个合并步骤我可以发现,如果某个链很短,会大幅减少比对次数,并且由于 SkipList 结构的存在,在某个倒排中定位某个 docid 的速度会比较快不需要一个个遍历。可以很快的返回最终的结果。从倒排的定位,查询,合并整个流程组成了 lucene 的查询过程,和传统数据库的索引相比,lucene 合并过程中的优化减少了读取数据的 IO,倒排合并的灵活性也解决了传统索引较难支持多条件查询的问题。
BKDTree
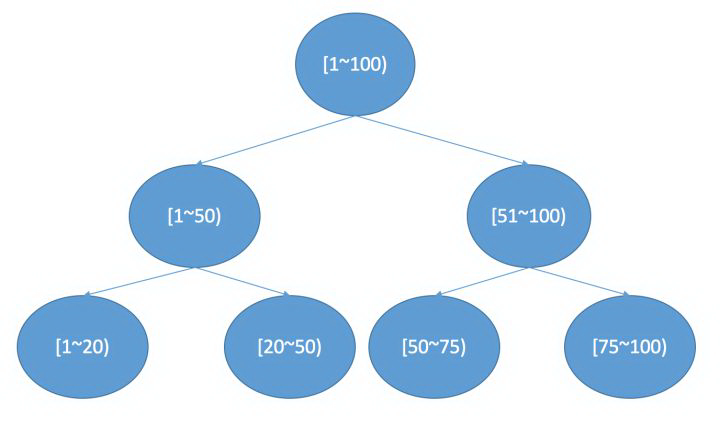
在 lucene 中如果想做范围查找,根据上面的 FST 模型可以看出来,需要遍历 FST 找到包含这个 range 的一个点然后进入对应的倒排链,然后进行求并集操作。但是如果是数值类型,比如是浮点数,那么潜在的 term 可能会非常多,这样查询起来效率会很低。所以为了支持高效的数值类或者多维度查询,lucene 引入类 BKDTree。BKDTree 是基于 KDTree,对数据进行按照维度划分建立一棵二叉树确保树两边节点数目平衡。在一维的场景下,KDTree 就会退化成一个二叉搜索树,在二叉搜索树中如果我们想查找一个区间,logN 的复杂度就会访问到叶子结点得到对应的倒排链。如下图所示:
如果是多维,kdtree 的建立流程会发生一些变化。
比如我们以二维为例,建立过程如下:
确定切分维度,这里维度的选取顺序是数据在这个维度方法最大的维度优先。一个直接的理解就是,数据分散越开的维度,我们优先切分。
切分点的选这个维度最中间的点。
递归进行步骤 1,2,我们可以设置一个阈值,点的数目少于多少后就不再切分,直到所有的点都切分好停止。
下图是一个建立例子:
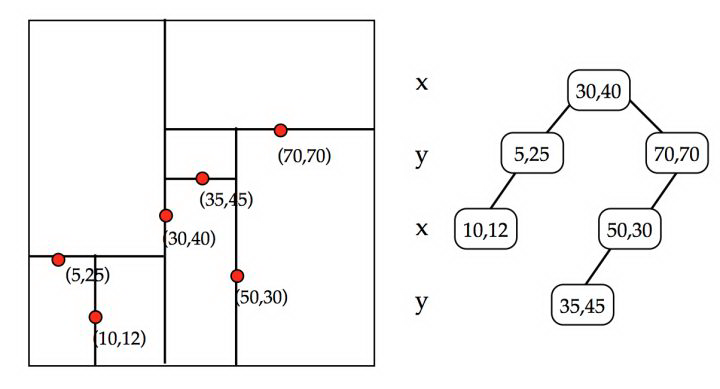
BKDTree 是 KDTree 的变种,因为可以看出来,KDTree 如果有新的节点加入,或者节点修改起来,消耗还是比较大。类似于 LSM 的 merge 思路,BKD 也是多个 KDTREE,然后持续 merge 最终合并成一个。不过我们可以看到如果你某个 term 类型使用了 BKDTree 的索引类型,那么在和普通倒排链 merge 的时候就没那么高效了所以这里要做一个平衡,一种思路是把另一类 term 也作为一个维度加入 BKDTree 索引中。
如何实现返回结果进行排序聚合
通过之前介绍可以看出 lucene 通过倒排的存储模型实现 term 的搜索,那对于有时候我们需要拿到另一个属性的值进行聚合,或者希望返回结果按照另一个属性进行排序。在 lucene4 之前需要把结果全部拿到再读取原文进行排序,这样效率较低,还比较占用内存,为了加速 lucene 实现了 fieldcache,把读过的 field 放进内存中。这样可以减少重复的 IO,但是也会带来新的问题,就是占用较多内存。新版本的 lucene 中引入了 DocValues,DocValues 是一个基于 docid 的列式存储。当我们拿到一系列的 docid 后,进行排序就可以使用这个列式存储,结合一个堆排序进行。当然额外的列式存储会占用额外的空间,lucene 在建索引的时候可以自行选择是否需要 DocValue 存储和哪些字段需要存储。
Lucene 的代码目录结构
介绍了 lucene 中几个主要的数据结构和查找原理后,我们在来看下 lucene 的代码结构,后续可以深入代码理解细节。lucene 的主要有下面几个目录:
analysis 模块主要负责词法分析及语言处理而形成 Term。
codecs 模块主要负责之前提到的一些数据结构的实现,和一些编码压缩算法。包括 skiplist,docvalue 等。
document 模块主要包括了 lucene 各类数据类型的定义实现。
index 模块主要负责索引的创建,里面有 IndexWriter。
store 模块主要负责索引的读写。
search 模块主要负责对索引的搜索。
geo 模块主要为 geo 查询相关的类实现
util 模块是 bkd,fst 等数据结构实现。
最后
本文介绍了 lucene 中的一些主要数据结构,以及如何利用这些数据结构实现高效的查找。我们希望通过这些介绍可以加深理解倒排索引和传统数据库索引的区别,数据库有时候也可以借助于搜索引擎实现更丰富的查询语意。除此之外,做为一个搜索库,如何进行打分,query 语句如何进行 parse 这些我们没有展开介绍,有兴趣的同学可以深入 lucene 的源码进一步了解。
知乎原文链接:
https://zhuanlan.zhihu.com/p/35814539
https://zhuanlan.zhihu.com/p/35795070

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 2 条评论