

什么是存储引擎
存储引擎位于文件系统(各种数据,二进制形式)之上,各种管理工具(连接池、语义分析器、优化器、缓存区、SQL 接口)之下。
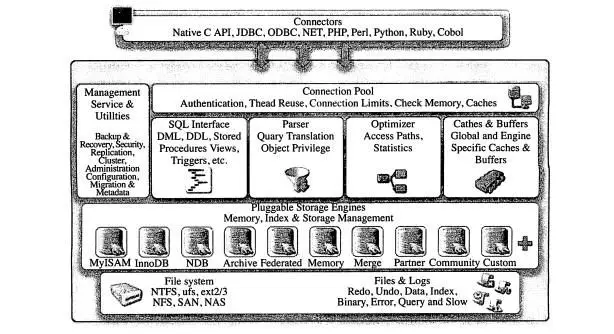
存储引擎功能设计
功能丰富性(或者 SQL 语义支持):
事务(和文件系统的最大区别),锁的粒度(行或者表),全文索引,簇索引,外键(这是什么)
事务:
事务的隔离性由锁实现,其他 ACD 由 redo log 和 undo logo 实现。redo log 保证事务原子性(怎么理解?由于数据库设计是先写 redo,再执行真正修改数据页。所以 redo 一定是个完整的事务,才会修改数据页)和持久性(怎么理解?持久化到硬盘)。undo log 保证事务一致性(数据冲突时的恢复)。
redo 写法是数据库一直顺序写,无需读。由于没有使用 O_DIRECT 裸写盘,所以每次写 redo 必须 fsync 到硬盘。
另外这里还有提到的是 binlog,区分的是 binlog 是数据库容灾的范筹(记录的是 sql 语句,在事务提交的时候才会写)。而 redo 是 innodb 产生的(修改页的物理二进制日志,随事务进行而并发写)。而且在写 redo 是以日志块大小和磁盘扇区一样。都是 512 字节。所以重写日志写入具有原子性。redo 的物理二进制日志,以不记录 sql 语句执行过程,而记录 sql 执行后的页结果。由此具有幂等性(执行多次等同于执行一次,分布式网络的不可靠 由于多次重新调用接口,必须保证幂等性)。
一个问题是,基于硬盘的数据库会把数据写在内存中,同时对数据库的修改最初也是改在内存上,怎么落地呢(checkpoint 检查点机制)。事务数据库为了保证 ACID 的 D 一般会使用先写 redo log,在修改页。
undo 帮助事务回滚和 MVCC 功能。
表锁、行锁:
锁机制分为 latch(轻量级的锁,分为 mutex 和 rwlock。这个是内部锁机制,保证并发线程操作临界资源的正确性,通常没有死锁检测机制, 比如查看 mutex 的方法是 show engine innodb mutex;)和 lock(粒度为事务,可以是表、页、行,有死锁检测机制)。
死锁检测机制有:顺序获取多个锁(latch 只有这个机制),waits-for graph(图死锁检测),过期机制。
MVCC 机制(解决锁带来争用的分布式并发访问问题)
自增长锁:给每个插入赋予一个唯一增加的 id,每个插入获取到这个 id,就可以释放表锁。通过减少锁的持有时间,提高并发插入效率。
查看当前事务隔离级别:
幻读和脏读:脏读都不好吗?在 slave 节点可以修改 innodb 的默认事务隔离级别 REPEATEDLY READ 为 READ UNCONMITTED,允许读到不那么准确的数据。
不可重复读:一般不可重复读是可以接受的,因为他读到的是提交的数据,而脏读是读到未提交的数据。如 Oracle 和 SQL Server 设置的事务隔离级别是 READ CONMIITTED,则会出现不可重复读现象。
丢失更新:一个事务更新会被另一个事务更新所覆盖,从而产生数据不一致。基本数据库任何隔离级别,不会产生。
数据存储设计:
支持 B 树索引,支持 hash 索引,数据压缩存储,数据表缓存(或者只索引缓存),数据文件加密,存储效率,内存消耗,硬盘消耗,块插入速度,查询缓存,MVCC(解决并发数据一致性问题)。
B+树索引/自适应 hash 索引:
B 树(Blance 树或者平衡树):关系型数据库最常用拿来做索引的。从 AVL(平衡二叉树演化而来)。
B+树=B 树+索引顺序访问。包含树枝节点和叶子节点。所有的数据放在叶子节点。每一个叶子节点互相有序顺序连接。树根节点指引着查找到叶子节点的路径。由于不断的插入和删除,同时 B+树会通过旋转保持平衡。
B+索引本身并不是找到具体的一条记录,而是找到该记录所在的页。数据页把载入到内中,然后通过页目录在进行二叉查找。因为在内存查找很快。
聚集索引:按照表的主键构建的 B+树。
辅助缩影:叶子节点存放的不是数据,而是捷径,指引到找到所有数据的地方。
数据的区分度:Cardinality
自适应哈希索引:innodb 根据查找频度,创建 hash 索引。将 o(logn)的查找复杂度提高最快 o(0)(最慢 o(n))的速度。哈希索引不对范围查找有效。
压缩空间和加密安全:
记录在文件可以是普通模式或者 reduction 模式。
容灾机制:
备份机制,备份恢复(备份快照点记录)。热备,冷备,温备。
新上一台备机的备份顺序是记住当前主数据库的 LSN(log squence number),导出主数据库的当前数据库并在备机导入。设置 LSN 同步点。
innodb 特性
特性:
innodb 架构:多线程模型(Master,IO,Purge,Page Cleaner),数据刷新到硬盘才是 sql(事务)执行完的标志吗。purge 是完成事务提交后情况 undo log。
内存的消耗大(大在哪里?)。内存消耗在具体在缓冲区。缓冲区除了保护有数据页,索引页,还有 undo 页,插入缓冲。自适应 hash 索引、锁信息、字典信息。为什么 innodb 的内存会比其他的存储引擎大呢?
什么是数据库实例(类似于服务器的进程,数据库是数据文件)
缓冲区的基本管理思路是 LRU。37 为距离 LRU 追加尾部的 37%位置,并且只有在 mid 位置当超过 block_times 的时候才要可以会被移到 mid 的热点。当然用户预估自己的热点数据,适当得增加 mid 之前的热点区域。其中 page made young 和 page not made young 就表示了页从 old 移到 new 或者由于 block_time 的限制,old 没能移到 new。从 information_schema 数据库的 select * from innodb_buffer_pool_stats\G;可以获取到。可以看到这里还是很多 old 往 new 的迁移过程当中被 block 住。(我觉得这里 made yong 的过程中,是不是有很多热点数据,有没有必要把 mid 位置调长些)。第一个实例:缓冲区空间 size:8192*16K=128M。LRU 表项用 DATABASE_PAGES 表示。FREE_BUFFERS 是可利用的页。
主线程:每秒钟循环和每 10 秒钟循环
重做日志的 LSN(Log Sequeence Number)标记版本。
Sharp Checkpoint 和 Fuzzy Checkpoint(主线程定时的刷新,LRU 页不够必须删除尾巴页,重做日志不可用,脏页太多)
数据库的容灾:重做日志+LRU。LRU 溢出需要写磁盘。重做日志由于磁盘空间必须部分删除需要写磁盘
innodb 关键特性:
插入缓冲:针对非聚集索引的插入或者更新。针对非唯一辅助索引。
两次写:写的压力大不大,总共写内存多少 Innodb_dblwr_pages_written(真实反映数据库的),硬盘持久化多少次 Innodb_dblwr_writes
自适应 hash 索引:要求访问模式比较单一
AIO:AIO 的好处和坏处。:| innodb_flush_neighbors | 1 |
刷新邻接页(预读)。但是如果是本来 就是 iops 比较高的存储设备还需要这个吗,因为这个是对机械硬盘相邻数据写入做优化,或者有没有可能领接页写入刷新了 又很快变为脏页。
查看当前数据库运行性能
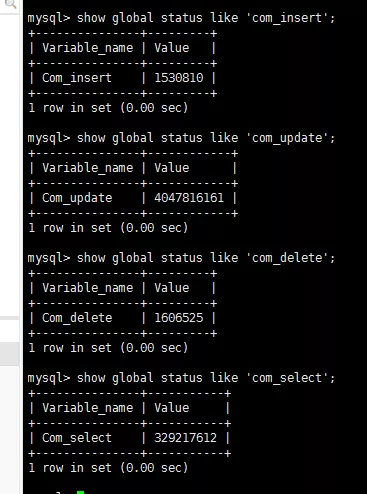
查看数据库的线程数据来窥探性能
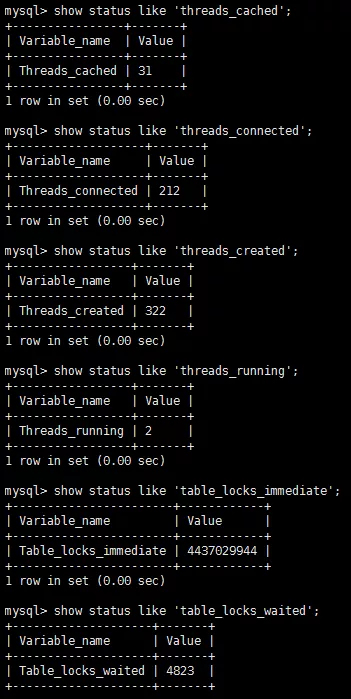
查看缓存区状态

LRU 查看
查看当前数据库的运行状态还有
备份相关
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/4MVojoTYit2t1XprTvxFbQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论