
用户行为分析是企业了解用户的重要方式之一,可以从点击、登录、观看、跳出、下单购买等多维角度还原用户动态使用场景和用户体验,通过对用户行为埋点数据进行分析,可以详细、清楚地了解用户的行为习惯,从中发现用户使用产品的规律,以用于精确营销、产品优化,从而驱动业务实现增长。
随着数字化转型进程的不断推进,用户行为分析平台在企业内部扮演的角色愈发重要,如何进一步挖掘用户行为数据价值,也成为了当下各企业不断努力探索的方向。而系统平台建设过程中所遭遇的挑战,也成了制约企业实现精细化运营过程中的重要因素。因此本文将从某社交 APP 的实际业务场景出发,与大家分享 Apache Doris 如何助力企业构建高效的用户行为分析平台,实现数据驱动业务发展。
从一个业务场景说起
在此以某社交 APP 为例,如果想要更好地提升用户使用体验并进一步实现转化率的增长,基于用户行为数据进行分析并调整业务相应策略是其中的关键,而各个业务团队对用户行为数据往往诉求存在一定差异:
算法团队想知道该 APP 最近一段时间的用户活跃数据,来判断是否需要调整推荐算法;
商业部门想知道多少人观看广告后进行了点击,以分析广告带来的用户体验如何;
运营部门想知道多少人通过落地页参与活动以及其转化率,以判断活动 ROI;
产品部门想知道不同功能用户访问数据的差异,通过 A/B 实验指导正确的产品优化路径;
......
为了承接以上需求,过去该公司使用了基于 Hive 的离线数据仓库,整体数据平台架构如下:
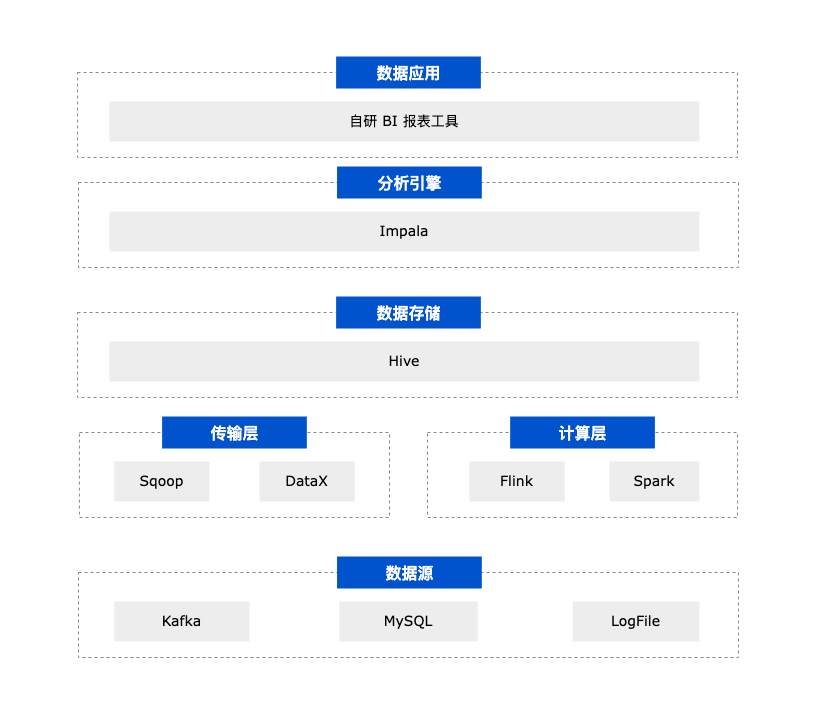
原始数据主要来自关系型数据库 MySQL 、消息队列 Kafka 以及采集到的日志数据;
利用 Sqoop 和 DataX 进行数据同步,通过 Flink 和 Spark 进行 ETL 以及 Yarn 和 Airflow 进行作业和任务调度;
处理完成的数据落入 Hive ,Impala 作为分析引擎,为上层自研的 BI 产品提供交互式分析服务;
在这样的平台架构下,留存着一系列挑战有待解决:
数据时效性较差:原有架构数据链路比较长,数据时效性差,T+1 的数据生产模式严重影响业务分析的效率;
运维成本高:数据链路较长,维护数据流转的成本高,一旦出现问题则需要排查上下游多个系统;且 Impala 本身不具备存储数据的能力,不得不引入 Hadoop 体系,而组件的繁多冗杂也大幅提升了企业运维的成本投入;
数据分析难度高:对于数据分析人员来说,没有合适的分析函数将会带来很多额外的工作量,比如编写 SQL 逻辑冗长、执行 SQL 耗时耗力等,严重影响数据分析的效率。
以该公司数据为例,我们将 APP 数据简化抽象出来,以一个常见需求来看数据分析的成本:
-- APP用户表 CREATE TABLE app ( id int, -- 用户id a_time datetime, -- 动作的时间 act varchar(20) -- 动作(登录、观看、点击等等) ) unique key (id, a_time, act) COMMENT 'OLAP' DISTRIBUTED BY HASH(`id`) BUCKETS 8 以背景介绍中的需求为例,算法部门想知道该 APP 最近一段时间的用户活跃及留存数据,来判断是否需要进行推荐算法和展示页的调整。上述其实就是一个求留存率的需求,实现逻辑并不复杂,我们可以很容易写出如下 SQL:
select dt, activ_2 / activ_1 as retentionfrom( select to_date(aa.o_time) as dt, count(distinct a.id) as activ_1, count(distinct b.id) as activ_2 from app a left join app b on a.id = b.id and to_date(a.a_time) = days_add(to_date(b.a_time), 1) where to_date(a.a_time) = 'xxxx' group by to_date(aa.a_time)) as aa但其中不能忽视的问题出现了,我们每查询一个留存比例就需要 Join APP 表自身一次,查询多个比例则需要 Join 该表自身多次,SQL 语句变得无比冗长;同时当执行该 SQL 时,多表 Join 带来的耗时也会变得很长。由此可知,没有合适的行为分析函数,会降低分析过程的效率。
全新的用户行为分析平台
经过慎重选型和对比,该公司决定使用 Apache Doris 来作为分析和计算引擎,主要考虑到如下优势:
数据集成简易:提供无缝接入 Kafka 和 MySQL 的能力,可复用已有架构并减少对接工作量;
架构简单:只有 FE 和 BE 两种角色,无需引入第三方组件,维护成本极低;
性能优异:列式存储引擎、MPP 查询框架、全向量化执行,在实际测试中性能表现突出;
功能丰富:支持丰富的用户分析函数,分析结果即查即出;
....
在引入 Apahce Doris 后,整体数据架构得到简化,数据处理链路得到大幅缩短,以下是新的架构:

数据导入更便捷
首先,Apache Doris 数据生态丰富,提供了多种数据导入方式,与已有数据源无缝对接:
通过 Routine Load 可以直接订阅 Kafka 数据;
通过 INSERT INTO SELECT
可以导入外部表的数据,目前已支持 MySQL、Oracle、PostgreSQL、SQL Server 等多个数据源;
通过 Stream Load 可以直接导入本地数据文件;
......
用户可以针对不同的数据源选择不同的数据导入方式,以快速集成来自不同数据源的数据。文档参考:https://doris.apache.org/zh-CN/docs/dev/data-operate/import/load-manual
其次,Apache Doris 1.2 版本中增加了 Multi-Catalog 功能,可实现无缝对接外部异构数据源,用户无需进行数据导入,即可直接通过创建 CREATE CATALOG 来查询底层数据。相对外部表, Multi-Catalog 无需创建表与表之间的映射关系,可以实现元数据层的对接,进一步加强联邦数据分析能力。
-- 我们以mysql为例,来详细讲解读取和写入的具体实现-- 创建catalogCREATE CATALOG jdbc PROPERTIES ( "type"="jdbc", "jdbc.user"="root", "jdbc.password"="123456", "jdbc.jdbc_url" = "jdbc:mysql://127.0.0.1:13396/demo", "jdbc.driver_url" = "file:/path/to/mysql-connector-java-5.1.47.jar", "jdbc.driver_class" = "com.mysql.jdbc.Driver");其中jdbc.driver_url可以是远程jar包:CREATE CATALOG jdbc PROPERTIES ( "type"="jdbc", "jdbc.user"="root", "jdbc.password"="123456", "jdbc.jdbc_url" = "jdbc:mysql://127.0.0.1:13396/demo", "jdbc.driver_url" = "https://path/jdbc_driver/mysql-connector-java-8.0.25.jar", "jdbc.driver_class" = "com.mysql.cj.jdbc.Driver");-- 创建catalog后,可以通过 SHOW CATALOGS 命令查看 catalog:MySQL [(none)]> show catalogs;+-----------+-------------+----------+| CatalogId | CatalogName | Type |+-----------+-------------+----------+| 0 | internal | internal || 10480 | jdbc | jdbc |+-----------+-------------+----------+-- 通过 SWITCH 命令切换到 jdbc catalog,并查看其中的数据库MySQL [(none)]> switch jdbc;Query OK, 0 rows affected (0.02 sec)MySQL [(none)]> show databases;+--------------------+| Database |+--------------------+| __db1 || _db1 || db1 || demo || information_schema || mysql || mysql_db_test || performance_schema || sys |+--------------------+MySQL [demo]> use db1;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedMySQL [db1]> show tables;+---------------+| Tables_in_db1 |+---------------+| tbl1 |+---------------+-- 使用catalog查询外部数据源MySQL [db1]> select * from tbl1;+------+| k1 |+------+| 1 || 2 || 3 || 4 |+------+-- 创建doris表,注意schema与mysql一致CREATE TABLE IF NOT EXISTS test.test ( k1 int)DUPLICATE KEY(`col1`)DISTRIBUTED BY HASH(col1) BUCKETS 1properties("replication_num"="1");-- 使用catalog直接将mysql中的数据导入doris-- 我们只用三级元数据层级,catalog.db.table的方式insert into internal.test.test select k1 from jdbc.db1.tbl1;数据时效性提升
数据架构简洁有力,引入 Apache Doris 后,数据架构缩减到 3 层,有效避免了过长数据处理链路带来的时延,整体数据时效性从天级降至分钟级;
用户查询耗时更低,SQL 查询耗时从过去的分钟降低至秒级甚至毫秒级,极大提升了业务分析人员的分析效率。
数据分析效率进一步提升
前文中有提到,没有合适的分析函数会使得分析工作变得艰难;而 Apache Doris 为用户行为分析提供了丰富的分析函数,使得数据分析难度大幅降低,这些函数包括但不限于:
intersect_count
sequence_count
sequence_match
retention
window_funnel
Array 类函数
......
丰富的用户行为分析函数
数据准备
在此以上述 APP 表为例,前期需要完成建表以及数据导入等准备工作:
-- 建表 CREATE TABLE app ( id int, -- 用户id a_time datetime, -- 动作的时间 act varchar(20) -- 动作(登录、观看、点击等等) ) unique key (id, a_time, act) COMMENT 'OLAP' DISTRIBUTED BY HASH(`id`) BUCKETS 8 PROPERTIES ("replication_allocation" = "tag.location.default: 1"); -- 插入数据insert into app values (111, '2022-01-01 10:00:00', 'login'), (111, '2022-01-01 10:01:00', 'view'),(111, '2022-01-01 10:02:00', 'click'), (111, '2022-01-02 10:00:00', 'login'), (111, '2022-01-02 10:01:00', 'view'), (222, '2022-01-01 11:00:00', 'login'),(222, '2022-01-01 11:01:00', 'view'), (333, '2022-01-01 12:00:00', 'login'),(333, '2022-01-01 12:01:00', 'view'),(444, '2022-01-01 13:00:00', 'login'); -- 查看数据select * from app order by a_time;+------+---------------------+-------+| id | a_time | act |+------+---------------------+-------+| 111 | 2022-01-01 10:00:00 | login || 111 | 2022-01-01 10:01:00 | view || 111 | 2022-01-01 10:02:00 | click || 222 | 2022-01-01 11:00:00 | login || 222 | 2022-01-01 11:01:00 | view || 333 | 2022-01-01 12:00:00 | login || 333 | 2022-01-01 12:01:00 | view || 444 | 2022-01-01 13:00:00 | login || 111 | 2022-01-02 10:00:00 | login || 111 | 2022-01-02 10:01:00 | view |+------+---------------------+-------+留存分析
算法部门想知道该 APP 最近一段时间的用户活跃及留存数据,来判断是否需要进行推荐算法和展示页的调整。该需求可以理解为留存率,主要是指注册后在一定时间内或者一段时间后有登录行为且仍在继续使用该产品的留存用户,在当时总的新增用户中所占比例。该需求为前文提到的第一个需求,接下来我们看看使用 Doris 提供的分析函数如何实现呢?
正交 Bitmap 函数计算留存率

-- 求第N天登录的用户select intersect_count(to_bitmap(id), to_date(a_time), '2022-01-01') as first from app;+-------+| first |+-------+| 4 |+-------+-- 求第N天和N+1天都登录的用户select intersect_count(to_bitmap(id), to_date(a_time), '2022-01-01', '2022-01-02') as second from app;+-------+| second |+-------+| 1 |+-------+-- 二者的比例即为所求select intersect_count(to_bitmap(id), to_date(a_time), '2022-01-01', '2022-01-02') / intersect_count(to_bitmap(id), to_date(a_time), '2022-01-01') as rate from app;+------+| rate |+------+| 0.25 |+------+Retention 函数计算留存率

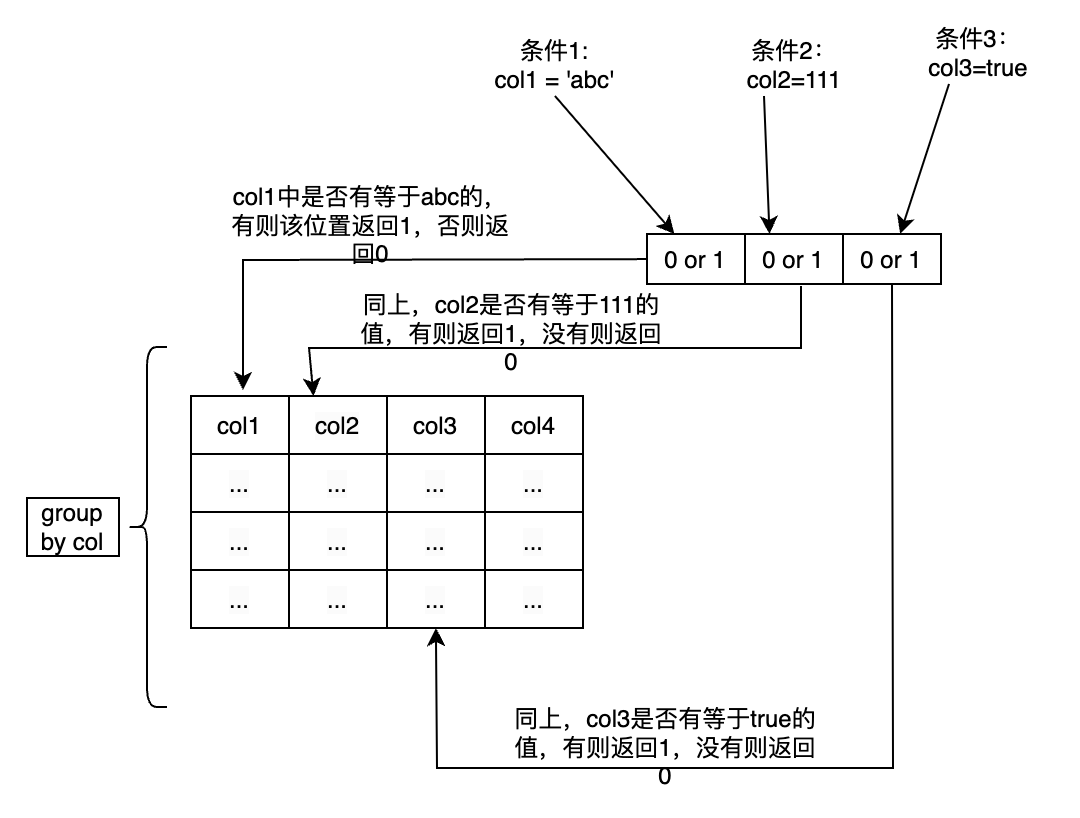
Retention 通常需要跟group by联合使用,以获取group by列匹配的条件。而输入的参数是可变长参数,Retention 会返回跟输入参数长度相等的数组。数组取值则要看匹配条件能否满足,如下图所示:
-- 求第N天登录的用户select id, retention(to_date(a_time)='2022-01-01') as first from app group by id;+------+-------+| id | first |+------+-------+| 222 | [1] || 111 | [1] || 444 | [1] || 333 | [1] |+------+-------+-- 求第N天和N+1天都登录的用户select id, retention(to_date(a_time)='2022-01-01', to_date(a_time)='2022-01-02') as second from app group by id;+------+--------+| id | second |+------+--------+| 222 | [1, 0] || 111 | [1, 1] || 444 | [1, 0] || 333 | [1, 0] |+------+--------+-- 二者的比例即为所求select sum(re[2]) / sum(re[1]) as rate from (select id, retention(to_date(a_time)='2022-01-01', to_date(a_time)='2022-01-02') as re from app group by id) as a;+------+| rate |+------+| 0.25 |+------+路径分析
商业部门想知道多少人观看广告后进行了点击,以分析广告带来的用户体验是否合适。该需求可以理解为行为分析中的路径分析,而路径分析是一种基于行为顺序、行为偏好、关键节点、转化效率的探索型模型。依据路径分析可以直观掌握用户行为扩展路线,以供优化节点内容、提升整体转化效率。
sequence_count 路径分析

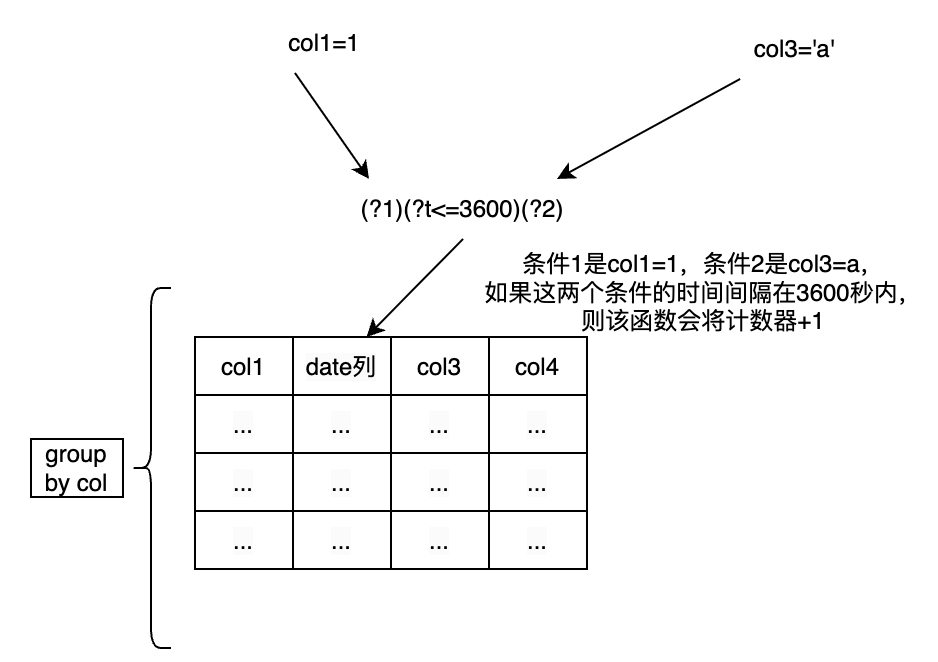
sequence_count通常需要跟group by一起使用,以获取group by列匹配的条件。函数使用方法为:sequence_count((?1)(?t<3600)(?2), date, col1=1, col3='a'),表明当前 col1=1 是第一个条件;此时如果有 col2=a,并且 col2 的时间与 col1 的时间在 3600 秒之内(col2 的时间减去 col1 的时间),则sequence_count对这样一组匹配结果记一个数。其工作逻辑如下图所示:
-- 哪些用户在登录后2分钟内观看了广告select id, sequence_count('(?1)(?t<=120)(?2)', a_time, act = 'login', act = 'view') as result from app group by id;+------+--------+| id | result |+------+--------+| 111 | 2 || 444 | 0 || 222 | 1 || 333 | 1 |+------+--------+-- 上述SQL可以看到,先观看广告再点击广告的用户有3人;而111这个用户有两次都是登录后观看了广告。pattern中的(?1)对应act = 'login',(?2)对应act = 'view',时间间隔为120秒-- 哪些用户在登录后2分钟内观看了广告,并在2分钟内点击了广告select id, sequence_count('(?1)(?t<=120)(?2)(?t<=120)(?3)', a_time, act = 'login', act = 'view', act = 'click') as result from app group by id;+------+--------+| id | result |+------+--------+| 333 | 0 || 111 | 1 || 444 | 0 || 222 | 0 |+------+--------+漏斗分析
运营部门想知道多少人通过落地页参与活动以及其转化率,以判断活动 ROI 以及确定策略带来的价值是否符合预期。该需求可以理解为转化率,而转化率主要是指是指用户进行了相应目标行动的次数与总次数的比率;转化率可以衡量一个产品用户需求强弱、评价产品设计好坏、对比流程和渠道权重等。
window_funnel 漏斗转化分析

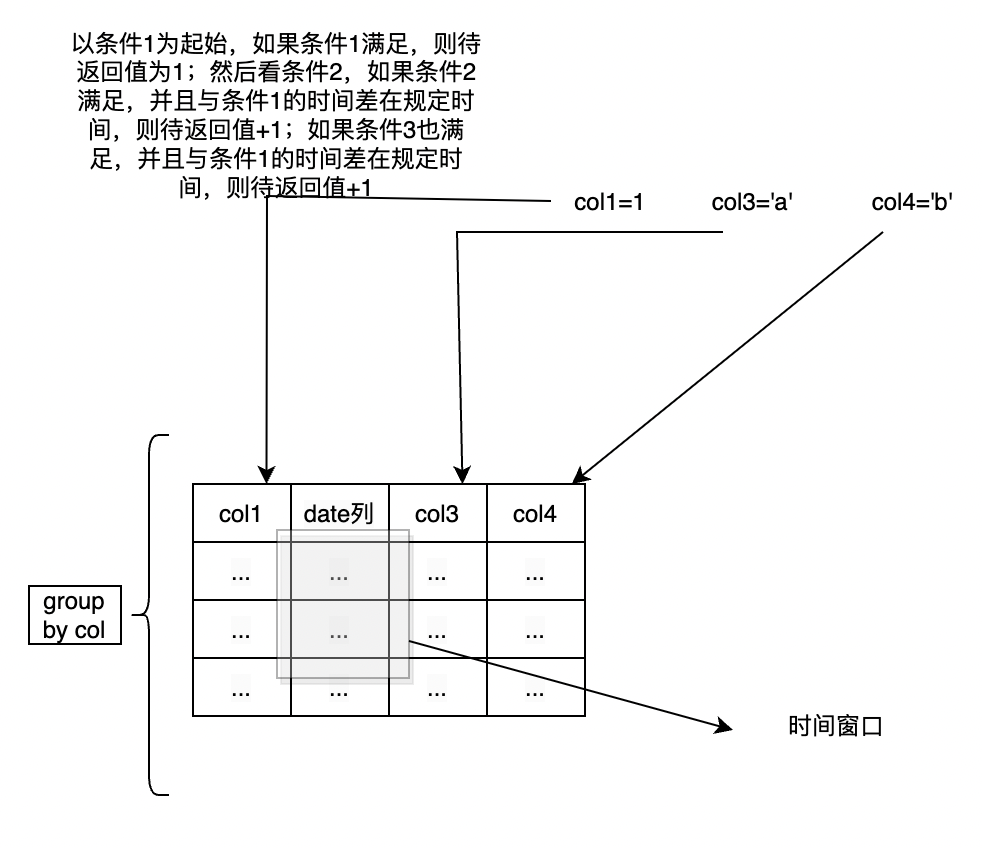
window_funnel也是有可变参数,并且需要指定时间窗口列和窗口大小。假设窗口大小为 3600 秒,并且datetime列为时间列,则窗口就是沿着datetime列滑动。首先匹配条件 1 ,如果有一列满足则待返回值变成 1;然后去匹配条件 2,如果条件 2 匹配,并且跟条件 1 相差时间在 3600 秒内,则待返回值加一;接着匹配条件 3,过程与条件 2 相同。最后返回一个计数值,该值表明这些可变条件满足多少个。
-- 哪些用户在登录后2分钟内观看了广告select id, window_funnel(120, 'default', a_time, act = 'login', act = 'view') as w from app group by id;+------+------+| id | w |+------+------+| 333 | 2 || 222 | 2 || 111 | 2 || 444 | 1 |+------+------+-- 从上述SQL可以看出,第一个参数120秒指定了滑动窗口的大小,并且窗口是按a_time这一列滑动的。act = 'login', act = 'view'是两个条件,显然用户111,222,333均满足这两个条件,即一小时内,先登录再观看广告;但是444这位用户就不满足先登录再观看广告,因为他只有登录操作,所以window_funnel对他返回了1,因为他只满足第一个条件-- 根据上述结果进行筛选,哪些用户在登录后2分钟内观看了广告select id, window_funnel(120, 'default', a_time, act = 'login', act = 'view') as w from app group by id having w = 2;+------+------+| id | w |+------+------+| 111 | 2 || 333 | 2 || 222 | 2 |+------+------+-- 哪些用户在一小时内,登录、观看、点击都执行了select id, window_funnel(3600, 'default', a_time, act = 'login', act = 'view', act = 'click') as w from app group by id having w = 3;+------+------+| id | w |+------+------+| 111 | 3 |+------+------+其他
Array 类函数
熟悉行为分析的同学都知道,固然丰富的分析函数有助于帮助我们提高分析效率,但是分析函数无法覆盖所有的场景,一些特殊的需求还是依赖特殊或者复杂的 SQL 来实现,而这些 SQL 很多都需要借助数组来实现。鉴于篇幅所限,该部分不会展示纷繁复杂的需求,而是会通过几个浅显的例子来展示 Apache Doris 丰富的数组类函数。
// split_by_string函数:指定分隔符切分字符串,得到切分后的数组:select split_by_string('a#b#c#d','#');+---------------------------------+| split_by_string('a#b#c#d', '1') |+---------------------------------+| ['a', 'b', 'c', 'd'] |+---------------------------------+// array_sort函数:对数组进行升序排序。下表的k1是数组类型:select k1, array_sort(k1) from test;+-----------------------------+-----------------------------+| k1 | array_sort(`k1`) |+------+-----------------------------+----------------------+| NULL | NULL || [1, 2, 3, 4, 5, 4, 3, 2, 1] | [1, 1, 2, 2, 3, 3, 4, 4, 5] |+-----------------------------+-----------------------------+// array_size函数:获取数组大小。下表的k1是数组类型:select k1,size(k1) from test;+-----------+------------+| k1 | size(`k1`) |+-----------+------------+| [1, 2, 3] | 3 || [] | 0 || NULL | NULL |+-----------+------------+// array_remove函数:返回移除所有的指定元素后的数组。下表k1是数组类型:select k1, array_remove(k1, 1) from test;+--------------------+-----------------------+| k1 | array_remove(k1, 1) |+--------------------+-----------------------+| [1, 2, 3] | [2, 3] || [1, 3] | [3] || NULL | NULL || [1, 3] | [3] || [NULL, 1, NULL, 2] | [NULL, NULL, 2] |+--------------------+-----------------------+// array_slice函数:返回一个子数组,包含所有从指定位置开始的指定长度的元素。下表k1是数组类型。从1开始从左至右计数;位置可以为负数,负数从-1开始从右到左开始计数select k1, array_slice(k1, 2, 2) from array_type_table_nullable;+-----------------+-------------------------+| k1 | array_slice(`k1`, 2, 2) |+-----------------+-------------------------+| [1, 2, 3] | [2, 3] || [1, NULL, 3] | [NULL, 3] || [2, 3] | [3] || NULL | NULL |+-----------------+-------------------------+select k1, array_slice(k1, -2, 1) from test;+-----------+--------------------------+| k1 | array_slice(`k1`, -2, 1) |+-----------+--------------------------+| [1, 2, 3] | [2] || [1, 2, 3] | [2] || [2, 3] | [2] || [2, 3] | [2] |+-----------+--------------------------+// array_distinct函数:去除数组中的重复元素。下表k1是数组类型select k1, array_distinct(k1) from test;+-----------------------------+---------------------------+| k1 | array_distinct(k1) |+-----------------------------+---------------------------+| [1, 2, 3, 4, 5] | [1, 2, 3, 4, 5] || [6, 7, 8] | [6, 7, 8] || [] | [] || NULL | NULL || [1, 2, 3, 4, 5, 4, 3, 2, 1] | [1, 2, 3, 4, 5] || [1, 2, 3, NULL] | [1, 2, 3, NULL] || [1, 2, 3, NULL, NULL] | [1, 2, 3, NULL] |+-----------------------------+---------------------------+// 配合array使用较多的explode函数,可以轻松实现列转行:select e1 from (select 1 k1) as t lateral view explode([1,2,3]) tmp1 as e1;+------+| e1 |+------+| 1 || 2 || 3 |+------+// explode_split函数:按分隔符分割字符串,并将结果打散,实现列转行:select * from example1;+---------+| k1 |+---------+| a, b, c |+---------+select e1 from example1 lateral view explode_split(k1, ',') tmp1 as e1;+------+| e1 |+------+| b || c || a |+------+总结
通过 Apache Doris 系统自身的优异能力和丰富的行为分析函数,已经有越来越多的企业选择基于 Apache Doris 构建高效的用户行为分析平台。后续我们仍会持续加强这方面的能力,包括提供更丰富的数据类型以及行为分析函数,如果您在搭建用户行为分析平台过程中遇到任何问题,欢迎联系社区进行支持。同时也欢迎加入 Apache Doris 社区,一起将 Apache Doris 建设地更加强大!
作者介绍:
李仕杨,SelectDB 生态研发工程师,Apache Doris Contributor




