
关键摘要
- 论文提出了单层循环神经网络 WaveRNN,以及双 softmax 层,合成音频质量可与最先进的 WaveNet 模型相媲美。网络的密集形式可以在 GPU 上产生比实时速度快 4 倍的 24kHz 16 位音频。
- 论文采用权重修剪方法减少了 WaveRNN 的权重数量。参数数量固定时,稀疏网络表现比小型密集网络更好,且稀疏度高达 96% 时也能保持该对比关系。由于权重数量减少,稀疏 WaveRNN 可以在移动 CPU 上生成高保真音频。
- 论文提出一种新的基于子尺度的生成方法,将长序列分成一批短序列,并可以同时生成多个样本。
研究背景介绍
序列生成模型在自然语言、自然图像、视频、音频等领域都取得了非常好的效果。但是有效的采样一直是该类模型难以解决的问题。论文通过对文本转语音的合成,使用一系列技术减少采样时间,同时保持输出的质量。
论文的目标是增加序列模型的采样效率,而不损失模型的性能。采样过程花费的时间 T(u) 是目标 u 包含的样例个数和产生每个样例所需的时间的乘积。后者可以分解为计算时间 c(opi) 和网络中每层所需的运行时间 d(opi)。


T(u) 受四个参数影响,可能会变得很大:
u:样本数量较多,例如高保真音频由每秒 24000 个 16 位的样例组成。
N:网络结构较深,如 WaveNet。
c(opi):参数较多。
d(opi):每层运行所需时间较多。
作者针对这 4 个参数,分别提出了提升采样速度的方法。在生成音频质量损失最低的情况下,通过减少这 4 个参数的值,从而降低整体的采样所需时间 T(u)。
WaveRNN
针对公式中的参数 N,作者设计了 WaveRNN,降低了序列模型中对每个样本的操作次数 N。
作者利用了循环神经网络(RNN)的核心特点:通过单循环层可以输出对文本的高非线性变换。WaveRNN 由单层 RNN 和双 softmax 层构成,softmax 层用于预测 16 位音频样本。

图 1 WaveRNN 结构图
作者将 RNN 的状态分成两部分,c代表粗(高 8 位)样本,f代表细(低八位)样本。每一个部分分别输入对应的 softmax 层,对 8 位细样本的预测是基于 8 位粗样本的。R 与粗样本和细样本同时相乘,门输出只用于估算粗样本,然后采样得到ct。从P(c)中采样得到c后,估算细样本,然后采样得到ft。


表 1 给定模型和 WaveRNN-896 模型之间的 A/B 对比测试
从 A/B 对比试验中可以看出,仅有 896 单元的 WaveRNN 与最大的 WaveNet 达到了相当的 NLL 评分,而且音频保真度之间也没有很大的差距,而且 MOS 评分均很高。WaveRNN 在产生每一个 16 位样本时,仅用了 N=5 次的矩阵矢量相乘,就达到了这样的表现性能。而 WaveNet 用了两层网络,每层 30 个残差块(residual block),即 N=30*2=60 次矩阵矢量相乘。
WaveRNN 采样在 GPU 的实现
即使 N 很小,用普通方法实现 WaveRNN 也无法直接生成实时或更快的音频。内存带宽限制和进行 N 次相乘需要的启动时间都是很严重的瓶颈。作者通过使用持久内核来实现采样过程。在采样开始阶段一次性加载参数,并且在整个过程中将参数保存在寄存器中,来避免内存带宽的限制。同时,由于一次说话间隔的整个采样过程由单次 GPU 操作完成,也避免了操作启动时间的限制。
稀疏 WaveRNN
WaveRNN 的结构大大减少了所需操作次数 N,并且将采样实现成单次 GPU 操作也减少了启动时间消耗 d(opi),下面介绍一下如何减少每次操作的计算时间消耗 c(opi)。
权重稀疏化与结构稀疏化
减少网络的参数数量可以减少采样所需的计算时间 c(opi)。基于此,作者的目标是在给定参数数量情况下最优化表现性能。作者使用二值 mask 来限定权重矩阵的稀疏模式,对 WaveRNN 的权重进行稀疏化。作者采用结构化稀疏(块稀疏)来减少内存负荷。稀疏 mask 的结构是非重叠的权重块,一起修剪或保持,基于块内权重的平均大小。在每块含有 m=16 个权重时,表现性能损失最小,同时减少了存储稀疏模式所需的空间。
在参数固定时,大型稀疏 WaveRNN 比小型密集 WaveRNN 表现性能要好,而且这一对比关系在稀疏程度高达 96% 时也能保持。
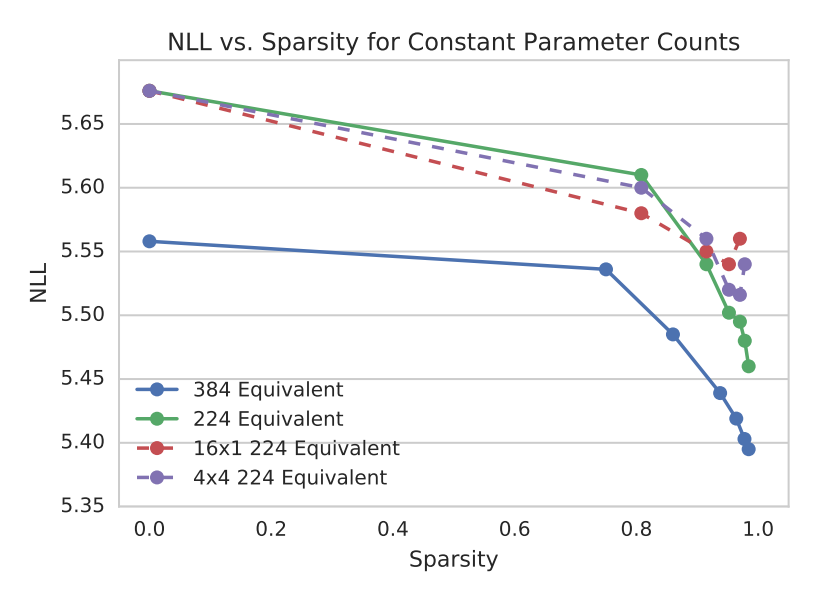

图 2 固定参数数量 NLL 与稀疏度变化曲线
从图中可以看出,稀疏结构为 16x1 和 4x4 在高稀疏度可以达到最优表现。
移动 CPU 上的稀疏 WaveRNN 采样
稀疏 WaveRNN 的高质量输出、参数较少和内存带宽低要求的特点使其很适合在低功耗移动平台上得到有效实现。作者在移动 CPU 上实现了稀疏矩阵矢量相乘和非线性单元,并进行了基准实验:


表 2 稀疏 WaveRNN 移动采样性能基准实验结果
上表是稀疏 WaveRNN 移动采样性能基准实验结果,实现平台为通用骁龙 808 和 835 移动 CPU。模型有 1024 个隐藏单元,95% 稀疏度和 4x4 稀疏结构。
作者用 softsign 非线性函数替代了门控循环单元(GRU)中标准的 tanh 和 sigmoid 函数,取得了更快的计算速度。


表 3 移动 CPU 内核非线性单元每秒评测次数和最大相关误差
尽管移动 CPU 的计算量和内存带宽比 GPU 小了 2-3 个数量级,在移动 CPU 上的实验表明这些资源足以让稀疏 WaveRNN 在低功耗设备上实时生成高保真度的音频。这是目前第一个能够在各种计算平台,包括移动 CPU 上进行实时音频合成的序列神经网络模型。
子尺度(Subscale)WaveRNN
最后,针对采样时间 T(u) 公式中的 u 参数(目标中的样本数量),作者提出了 subscale WaveRNN。
子尺度依赖方法
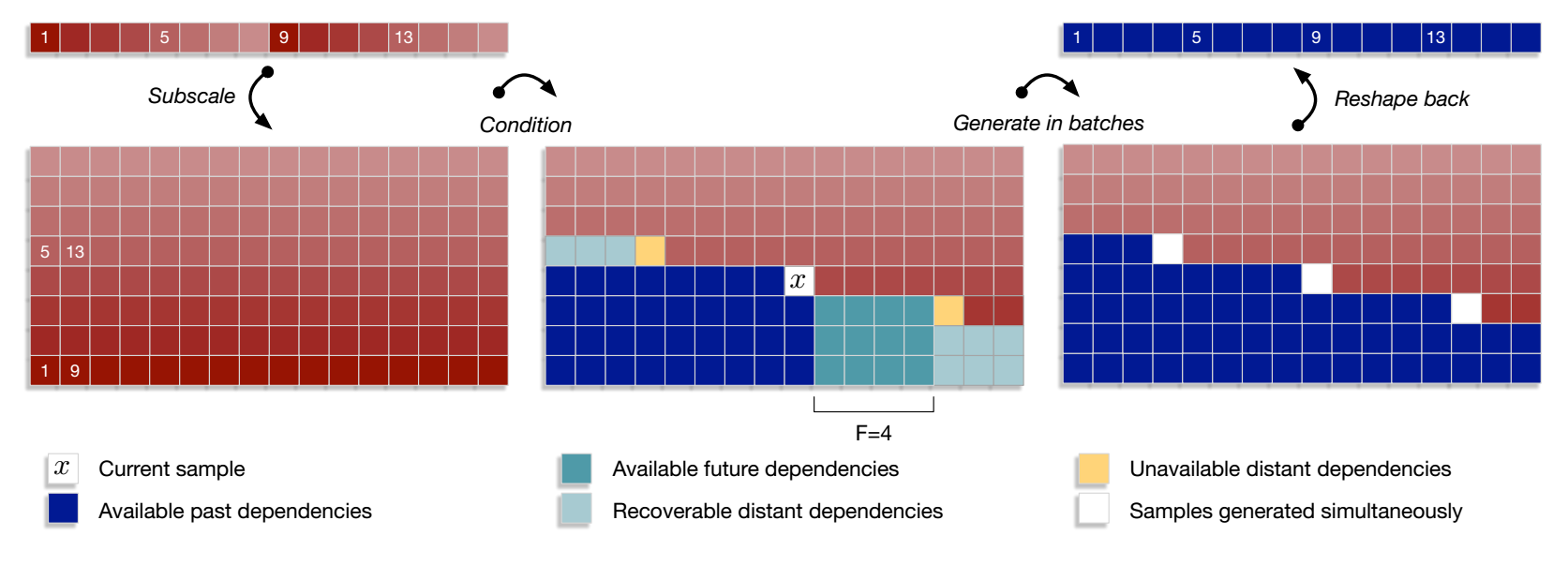

图 3 Subscale WaveRNN 依赖机制
图中每一个方块对应一个 16 位的样本。子尺度方法首先将张量分割成 B 个交错样本的子张量。每个子张量基于之前生成的子张量的过去和未来样本生成。过去范围不受限制,而未来范围为 F,根据条件网络的接受野而定,然后应用批采样。最后的张量由生成的子张量重组而成。
批采样(Batched Sampling)
一个尺度为 L 的 tensor 折叠成 B 个 sub-tensor,每一个尺度为 L/B。Subscale 的方法可以在一个 batch 中一次生成多个样本。由于每个子张量的生成基于前一个子张量,在实际中只需要相对较小的未来状态视野(future horizon F)。下一个子张量的生成可以在前一个子张量的前 F 个样本生成后立刻开始。实验证明,Subscale WaveRNN 能够每一步产生 B=16 的样本,同时不损失音频保真度。
实验
作者在单人北美英语文字转语音数据库上进行测试,输入是语言特征向量,输出是 24kHz,16 位的波形。在验证集上进行三项评估:负 log 似然函数(NLL),人为评价的平均主观意见分(MOS),以及人为评价模型之间的 A/B 对比测试(分数在 -3 非常差和 +3 非常好之间)。
WaveRNN 质量评测
下表给出了不同大小的 WaveRNN 的评测结果。较大的 WaveRNN 的 NLL 分数接近 60 层的 WaveNet 的评分。人为打分的 WaveRNN-896 和 WaveNet 之间的 A/B 对比试验表明在生成语音质量方面没有明显差别。
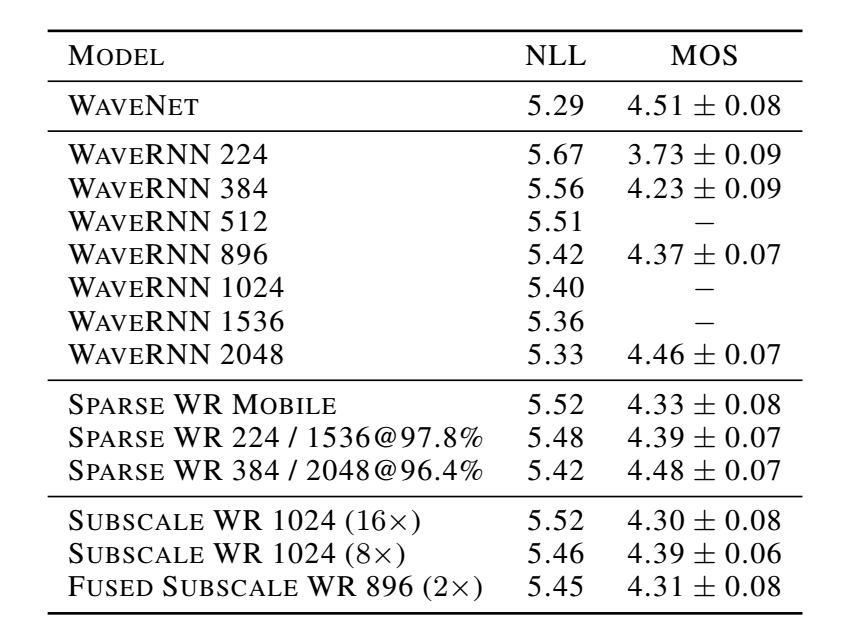

表 4 WaveRNN NLL 和 MOS 在文本转语音基准实验上的评测结果
WaveRNN 采样速度评测
WaveRNN-896 实现的持久 GPU 操作采样效率最高。下表给出了不同批尺寸的采样速度,随着批尺寸增加,计算吞吐量也随之增加。

表 5 WaveRNN GPU 核速度(样本 / 秒)
WaveRNN-896 采样过程的 GPU 核速度达到了 96000 样本 / 秒,大概是实时高保真 24kHz 16 位音频的 4 倍,而对应的 WaveNet 只有 8000 样本 / 秒。
稀疏 WaveRNN 质量评价
下表给出了不同模型尺寸和稀疏程度的稀疏 WaveRNN NLL 分数。

表 6 不同模型尺寸和稀疏程度的稀疏 WaveRNN NLL 分数。
从表中可以看出,随模型大小增加,网络性能随之增加。随稀疏度增加,网络性能有所下降。WaveRNN-2048 在稀疏度为 99% 时,仅含有 167k 个参数,也能产生高保真度的音频。
稀疏 WaveRNN 采样速度评测

表 7 每秒 ARM 矩阵向量相乘(MVM)和对应的 Gflops,低功耗处理器使用骁龙 808 和 835。
Softsign GRU 评测

图 4 标准非线性单元和 softsign 非线性单元验证曲线
上图给出了标准非线性单元和 softsign 非线性单元在 WaveRNN 和 Subscale WaveRNN 模型的验证曲线。实验表明,softsign GRU 与标准 GRU 单元表现性能无差,且具有更快的计算速度。
Subscale WaveRNN 质量评测
从表 4 中可以看出,Subscale WaveRNN 8x 与基准 WaveRNN-896 取得了同样的 MOS 评分,证明在修改了依赖机制后,Subscale WaveRNN 依然可以准确学习数据分布。从表 1 中可以看出,Subscale WaveRNN 16x 的音频保真度与 WaveRNN-896 基本没有差别。用序列模型进行音频生成对于丢失依赖是十分敏感的,尤其是局部依赖。而作者的实验成功证明了 subscale 依赖机制能够有效保存对序列模型高性能有关键作用的局部依赖。
论文原文: Efficient Neural Audio Synthesis
感谢蔡芳芳对本文的审校。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论