

一、经典的语音增强深度学习算法
语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景中提取有用的语音信号,抑制、降低噪声干扰的技术。它的主要目标是从带噪语音中提取尽可能纯净的原始语音,提高语音质量和可懂度。比如希望对方即使在飞机驾驶舱噪音环境中说话,我们也能听清楚。
做语音增强会用到一些经典算法,我们之前自己的应用,以及竞品的应用中使用比较多也比较成熟的算法主要有下面几种。当然算法每家不一样,本质上都是一些估计的方式:
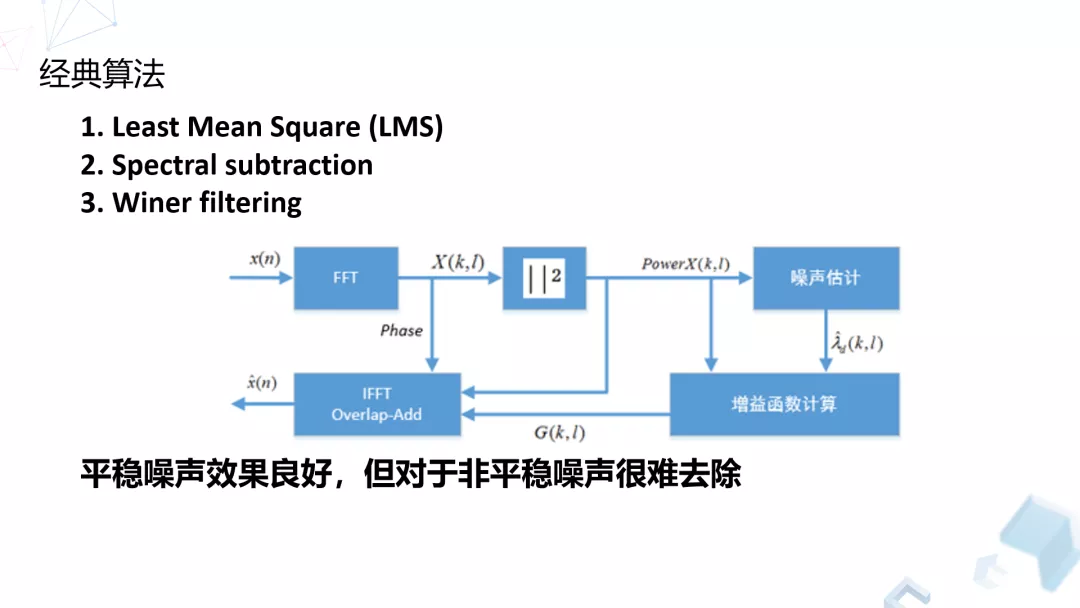
这些经典的算法,相对于其他比较激进的算法,其实大部分场景下效果都很好,特别对于音质的保留。因为自然界或者工作生活中的噪声非常多,各种各样,所以有时候我们利用经典算法,会达到满意的效果。还有一些常见的声音,比如键盘鼠标或者关门的声音,因为我们关注的比较多,研究的比较多,针对这些特定类型的噪声,特定类型的算法,我们可以做一些改进或者做新算法的研究,来提升我们现在的传统算法的效果。
经典算法也有一点问题,就是它的适应性还是不够强。另外,前面提到很多的开源算法在做对应算法的时候都有各种各样的问题,比如有部分的残留,或者可能需要一定的延迟。针对这些问题,我们主要利用我们的深度神经网络去做了一些算法的研究。
二、DNN/CNN/RNN,哪个模型最适合
我们想基于深度神经网络去做语音增强的话,最重要是两个部分,模型结构和算法选择。
模型结构法从 2015、2016 年开始用得比较多,到现在大家开始做 DNN 或者 RNN、CNN,甚至做一些新的研究结构也比较多。现在不同的考量会有很多不同的选择,比如第一个问题就是模型复杂度,神经网络如果想做好效果的话,它的复杂度要求比较高,第二个就是不同的网络计算量不一样,在移动端部署或者 PC 端部署的难度也不一样。还有一个最重要的问题,就是不同的网络架构对于语音的信号处理的应用网络效果也不一样,之前我们最早大部分做语音的时候都是用 RNN 比较多,后来从 CNN 图像里面用的比较多,后面我们再做一些新的研究的时候会发现,CNN 在处理语音信号时也能取得比较好的效果,特别在直接做时域信号处理上,也能做出来一个跟 RNN 效果相当甚至还是更好的程度。
在算法的选择方面,我们其实可以把大部分的算法分为两大类,基于 mapping 和基于 masking 的方法。基于 mapping 的方法,主要是通过网络学习直接预测输出的语音谱。基于 masking 的方法,主要是基于听觉掩蔽效应,在同一个时频点上语音和噪声的能量占比不同。如果语音为主,我们倾向保留,如果噪声能量为主我们倾向于把它去除。
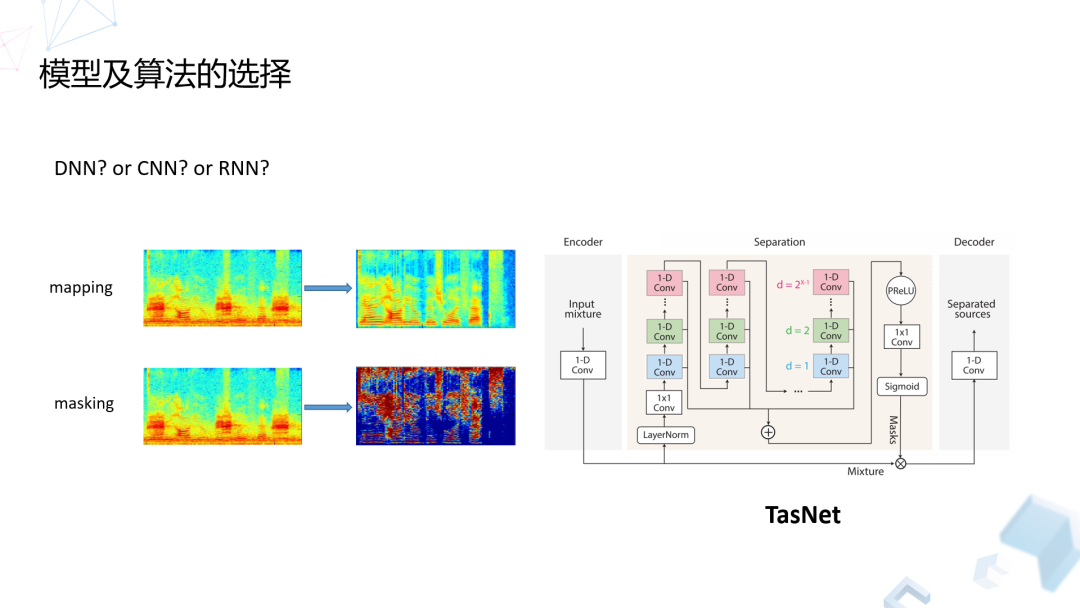
除了上述两类,还有一种方式是在时域上直接处理,这样就省略了频谱变换的过程。它的最大优点就是,首先会减小计算量,因为 FFT 变换还是有一定的计算量的。第二,它能够避免相位估计带来的损失,因为我们所有基于谱的方式,不管是 mapping 还是 masking,都需要做相位的估计,但是这个估计是非常难的,所以我们大部分情况下是直接从原始信号里取相位信息来做目标信号的相位。但是,这种情况下很不准,肯定是有误差的,现在也有很多方法去学习和改进相位的分布,但是效果离真实的值还是有差距。
这样的网络架构,它是直接从时域信号经过网络变化,再经过反变化,从本质上讲,相当于把相关的估计放到网络的学习过程中去了。这种方法主要是包含三大模块,一块是 Encoder,一块是 Decoder,当然中间还需要做一个 Separation 的过程。总体来说,我们在做研究过程中发现,不同网络中的效果,优点和缺点都不一样,当然现在算法还在迭代中,目前经过各种不同对比,包括线上模型的鲁棒性,包括整个效果的对比,我们选定还是基于 masking 的方式进行估计。
我们在做算法时面临的最大的一个问题就是语音损失,因为既然要做降噪,不可避免会把语音中的信号进行一些去除,这样就会带来一些语音的损失。如果说想尽量减少语音损失的话,就会导致降噪量不够,这实际上是一个比较两难的问题。针对这个过程我们在算法中做了很多工作,不管从数据上,从网络中丢包上都做了很多改动,一方面通过减少降噪量的方式改善语音损失,另一方面对不同的效果做了一些平衡。

另外一个比较重要的就是常见的鲁棒性问题。因为我们用 DNN 网络做算法的话,最大的一个问题就是数据的匹配。本质上是因为不同设备的问题,比如说用耳机、用平板、用手机,手机又有不同的型号,设备本身这样的麦克风采集的特性是不一样的,不同的频段也不一样,会导致我们最后拿到的语音信号会有不同的特点。而我们做这些网络的话,需要用一个算法在不同设备和不同的平台上都能取得比较好的效果,那么需要对模型做很多的改动,所以目前我们其实在不同的设备端采用不同的模型的参数。
但是考虑到比如说安卓手机的厂家和型号种类繁多,而且更新速度非常快,所以我们也做了一些取舍,在某些特定的平台上我们并没有做专门的机型的适配,只是针对一些比较宽泛的平台上做了一些适配。
三、客观更好才是真的好
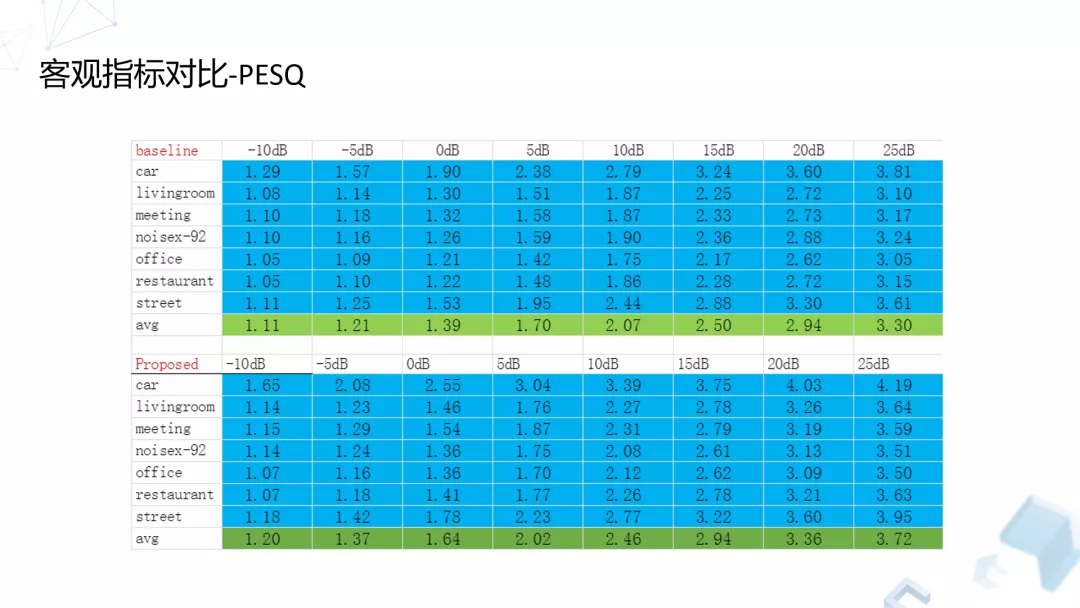
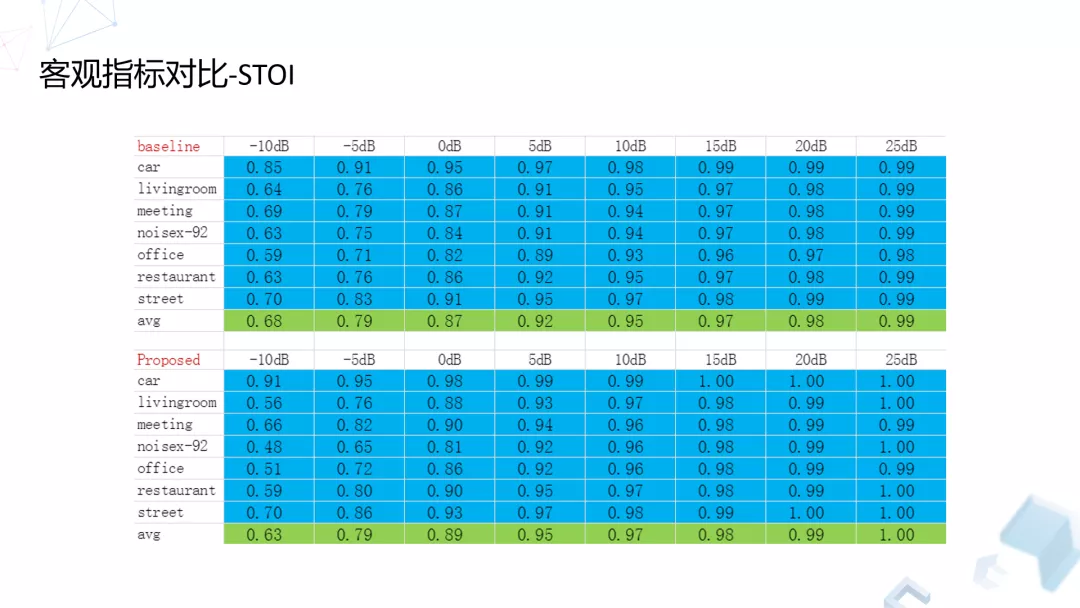
我们主要关注音质,所以这里列了两个指标,一个是 PESQ,一个是 STOI。我们选了目前用的比较多的开源算法,也是基于神经网络去做的,大概研究了六种常见的噪声场景,再加上一个开源的噪声场景,总共有七种,比如汽车、家庭、会议、办公室、餐厅、街道,我们关注的区间是-10dB 到 25dB。
我们发现,以 PESQ 衡量,在目前所有的情况下我们的提升基本上都有 0.1 到 0.3,甚至 0.4。
STOI 的话,除了在-10dB 的情况下有略微损失之外,其他情况下基本上是保持没有损失或者有一定的提升。
另外,我们也专门针对会议场景中常见的几种不同噪声类型,专门都做了一些采集和测试,包括键盘、咳嗽,桌子上摆放水杯的声音,还有会议室下雨打窗户的声音。当然效果还有不足,特别是在咳嗽和桌子放水杯下的情况,噪声的能量非常强,在低频还是有一点残留的,但是基本不可闻,大部分情况下还是能实现比较好的效果。
四、应对真实场景中的问题
针对真实场景中的问题,我们在商业上也做一些技术研究,比如去混响、回声消除、关键词检测、声音事件检测等。
1. 去混响
去混响的主要目的是去除直达信号之外的信号,提升可懂度,就是要听清楚他主要在说什么,同时又要避免对语音的损失。
用传统的算法做去混响要面对房间响应的估计问题,这是比较难估计的,特别是用户如果在不同的房间,响应的差异比较大,这跟房间的形状,材料以及物品布置都有关系。
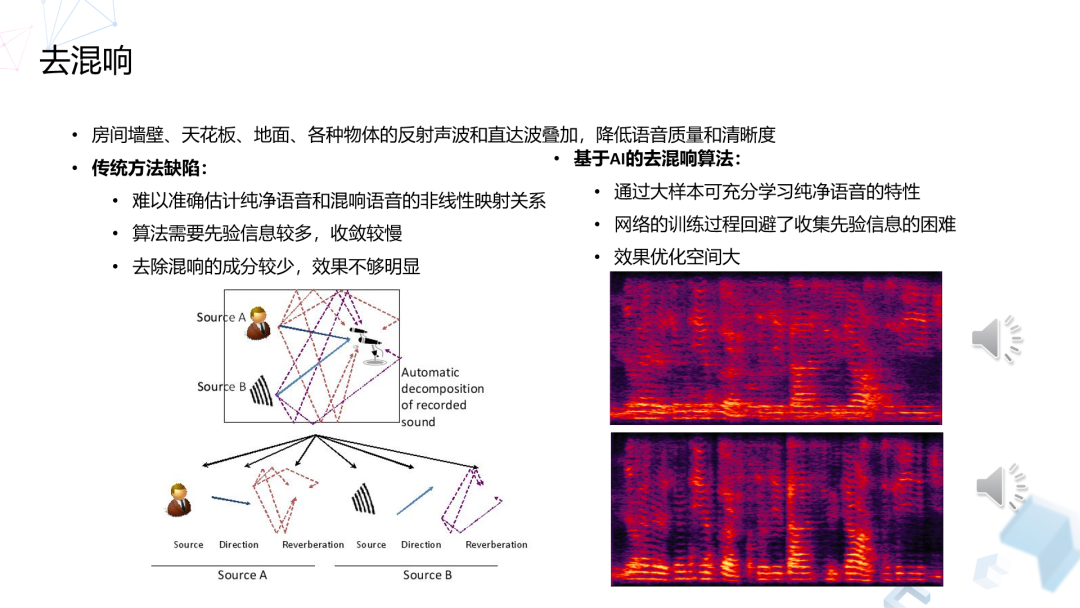
基于这个原因我们自己也做了一套基于 DNN 网络的混响算法,我们在不同的房间、不同的人、不同的数据上面都做了一些数据的自适应,得到了不错的效果。
2. 回声消除
目前的回声消除算法已经做得很好,包括在大部分的设备上,不管是 PC 还是在不同的手机上面效果都非常好。但是,有时候难免会碰到一些比较极端的情况,特别是有些设备尺寸比较大,或者设置有问题、配置有问题,会导致在特定情况下或者在特定的房间中,因为混响或者因为各种各样的原因,有可能会产生漏回声的情况。
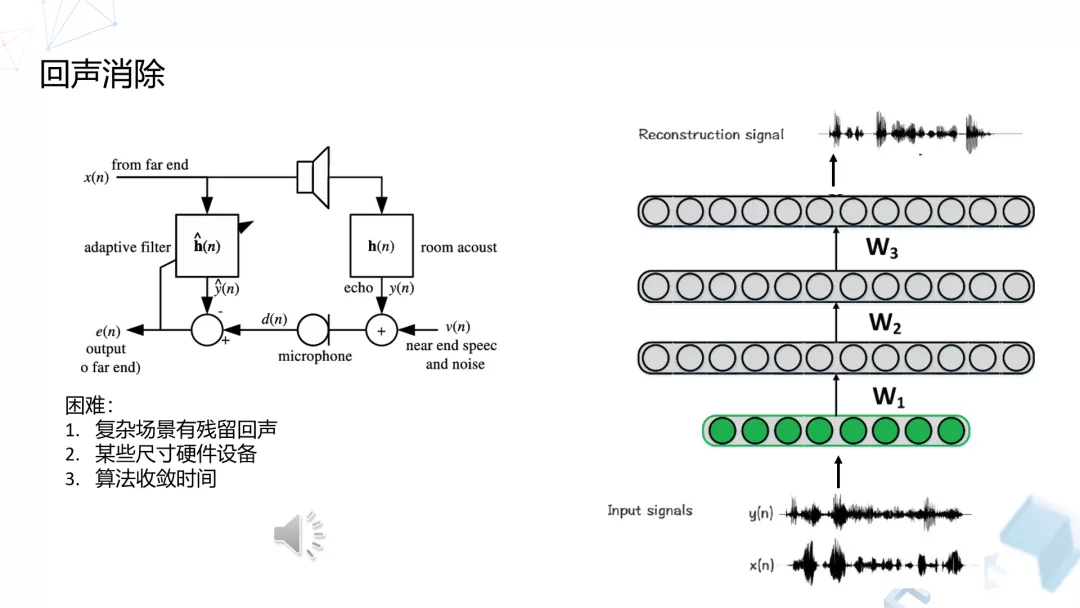
面对这种情况,传统算法一旦没有收敛的话就有可能失效。那么我们在这样的情况下是做了一个后处理,针对特定类型的设备,在特定情况下会产生漏回声的情况,我们自己做了一个回声消除的神经网络,利用这样的网络去把我们经过传统的回声消除算法处理过的信号,再进行一次过滤,相当于做一次融合,从而把我们有可能采集到的回声做一个更干净的消除。
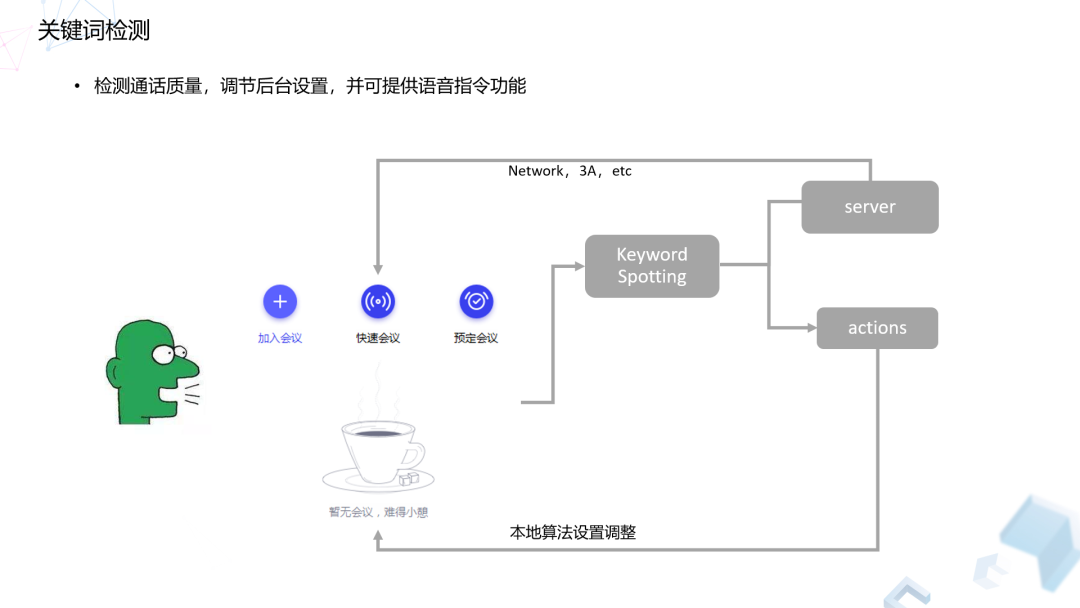
3. 关键词检测
我们在开会过程中难免会碰到各种各样的问题,比如说网络出问题或者电脑出问题,或者突然有麦克风采集问题,导致对端无声。所以我们做了一个算法,主要是为了监测通话中的实时音质,以发现是网络问题,还是算法问题,或者是本身硬件问题,然后我们会基于检测结果对我们的线上算法、甚至对硬件设备进行不同的自适应来调整,目前这个算法还在上线中。
4. 声音事件检测
我们做声音事件检测主要是为了改善通话质量,有的时候说话人身处的环境可能包含一些特殊信息,比如当前的讲话人可能身处在什么环境,或者身处周围有什么不同的一些特点的干扰的特性。
在这方面我们其实可以做很多工作,比如说进行检测,进行分类,我们在这个地方是借鉴了国际比赛中常用的几种不同的任务,包括场景分类、事件检测,通过把算法引到会议里面去,对当前的讲话人所处的环境进行估计。比如他说可能周围有一些狗叫声或者音乐或者其他的乐器,针对这样一个检测结果,我们会对商业算法和网络做一些不同的设置自适应。如果检测到音乐的话,因为音乐的声音信号比较特殊,相比语音细节更多,如果直接采用语音信号的配置去传输音乐的话对音质的损失会比较大,那么我们会对算法做一些调整,包括采样率、码率等都会做一些调整,来尽量提升音乐传输的音质。
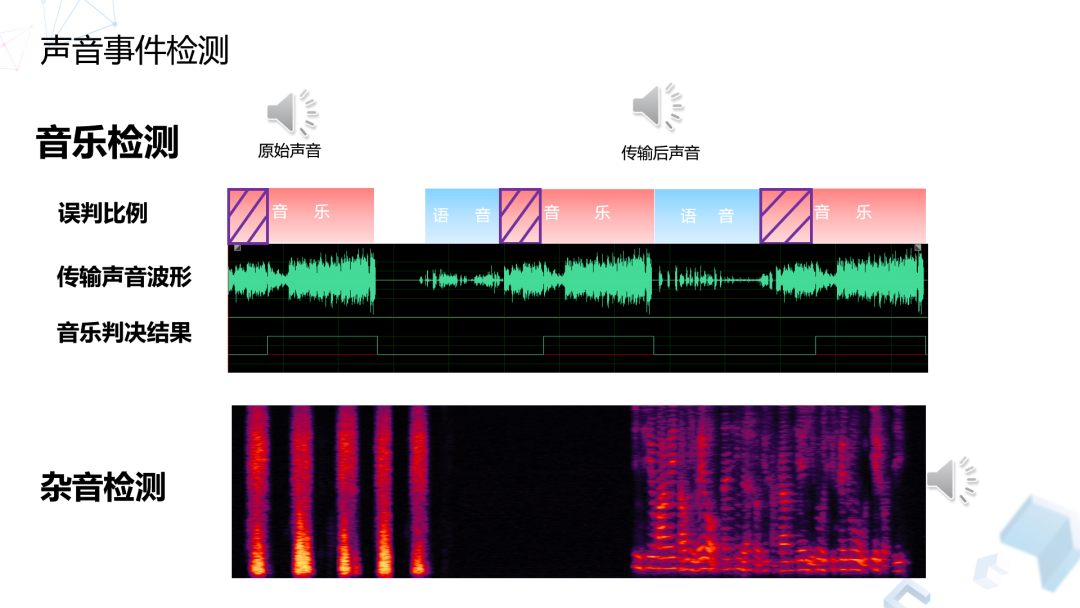
还有一个问题就是我们在线上会碰到各种不同的问题,比如说不同的设备很复杂,或者接入的时候可能由于编解码或者网络,或者有一些服务器,甚至电脑本身产生一些问题导致一些奇怪的信号,这些信号很难查清楚它到底来源于哪儿,所以我们针对这些问题提供类似于杂音检测的功能。检测到当前的通话过程中存在一些特殊的杂音,它有可能是在网络或者在上行下行过程中产生的时候,我们是没办法进行去除的,只能在下行或者是在服务器上进行处理,不管做一些检测或者做一些去除,都能做一些相应的改善。
五、Q&A
Q:回声消除的噪声适用一个模型还是两个模型?
A:我们的回声消除模型和普通的不太一样。在语音结构上面,因为它要处理的全部都是语音,所以跟我们用的噪声做的目标不太一样,模型结构也不太一样,包括处理数据可能都不太一样,所以导致参数是差异很大的。
Q:你们使用 CTRT 的时候调整是什么程度?
A:它其实不是传统的模型或者编码,它是用一个复杂比较低的去预测的,去合成丢失帧。处理的方法其实它有考虑到一定的编解码的特点,但是没有做更多的针对,就是在训练数据方面是有一些调整。
Q: 你们现在做的声学模型,所占的资源大概是多少?会引起技术天花板效应吗?
A: 这个可能就是维度比较高,角度比较多,到底占 CPU 的百分之多少,我们只能说它的量是比传统的高一些,具体的也不太好说,主要不同平台不同设备,占的资源也不一样。
另外,这种模型不是说主要针对语音噪声,所有的只要是噪声我们都能处理。语音技术的天花板效应的话,这个问题基本上是无解的,因为它完全取决于我们的数据,质量越好,那么它的目标或者模型训练效果越好,遇到的相对性也就越高。我们一般能拿到的数据不会那么干净,所以我们一般会先挑选,比如只要在 30 dB 或者 40 dB 以上。由于各种限制,即使在数据干净这样的条件下,我们目前的模型也不可能达到天花板那个点,所以这个问题目前不是我们关注的,如果我们把复杂度做到极致的话,才会考虑是否遇到了天花板。目前我们的策略还是会和一些传统方法进行融合。
头图:Unsplash
作者:王燕南
原文:https://mp.weixin.qq.com/s/d_rQJJ5Iq2HrfAgAal08Hw
原文:千万日活腾讯会议背后:深度学习的最新应用
来源:腾讯多媒体实验室 - 微信公众号 [ID:TencentAVLab]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论