

本篇文章选自数据库内核杂谈系列文章。
上篇文章中,我们着重介绍了对于一个 SQL 语句,数据库是怎么生成一个执行计划,并根据这个执行计划,一步一步地读取,计算并获得最后结果的。这一期,我们来聊一下两个非常重要的算子(operator, 上一期我把 operator 翻译成操作符,后来读了其他前辈写的文章,发现还是算子更贴切: 排序(Sort)和聚合(Aggregate)的实现。为什么要把这两个算子放在一起说呢?其实,它们之间有很多的共同点,比如都是 Blocking 的算子,即需要得到所有的输入 tuple,才能完成计算后输出。这就使得它们会遇到同样的困难,比如内存无法存放所有的输入 tuple,怎么办?除了这个问题,排序和聚合还有很多其他藕断丝连的地方。带着这个问题,我们一起进入今天的内容吧。
排序
首先,来了解一下排序算子能够实现哪些 SQL 语法。 既然是排序,第一想到的当然是 ORDER BY 语句啦。下图给出了一些示例语句。
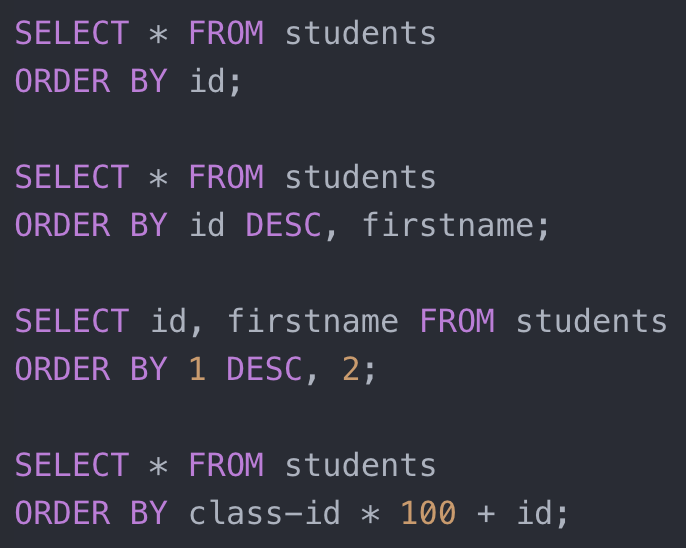
ORDER BY 示例语句
简单介绍一下,数据库系统会按照 ORDER BY 键的排列顺序输出结果。默认是升序(ASEC),也可以通过声明来要求按照降序(DESC)输出。示例二展示了可以对多个列进行组合排序,排序会按照排序列的先后顺序依次进行。示例三展示了一类 ORDER BY 语句的语法糖(syntax sugar)。可以用编号 1, 2 来指定。示例四展示了排序的键并非一定要是某一个列,也可以是列组成的表达式。
除了可以实现 ORDER BY,排序还能实现其他什么语句吗?答案是肯定的,比如下面这个示例:

SELECT DISTINCT 语句
上例展示了一个 distinct 的聚合语句,要求输出所有不重复的 class-id。读者可能有疑问,排序怎么实现这个聚合语句呢?哈,是不是觉得这两个算子的关系有点紧密了?其实答案也并不难想到:先对所有学生以 class-id 进行排序,然后在上一层的聚合算子里,只需要维护一个当前的 class-id,并且同新的输入做对比,如果不同就输出 class-id, 如果相同就保留。示例代码如下:
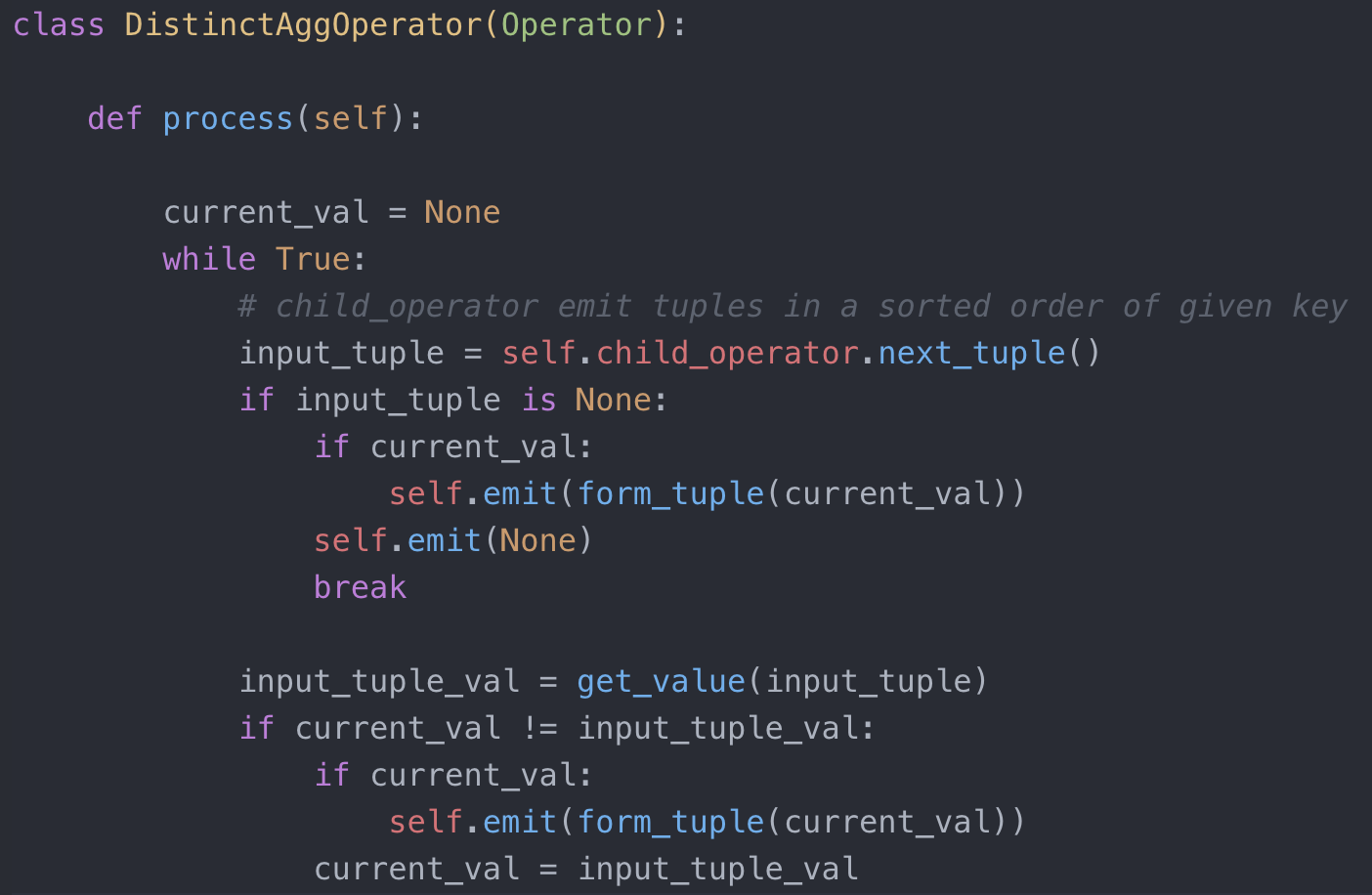
DistinctAgg 实现代码
除了帮助实现这个聚合,排序带来的另一个好处在于,把这个聚合变成了一个 non-blocking 的算子:不再需要等待所有的输入,只要输入的 class-id 和当前不匹配,即可输出当前 class-id,内存的问题也一并消失了。排序是不是挺厉害的,给大家留一个思考题?你还能想到其他 SQL 语句可以用排序来帮忙实现的吗?答案在文末揭晓。
聊完了作用,来聊聊具体实现。前文已经说到,排序是 blocking 的,实现的难点就在于内存消耗。假设输入的数据可以完全存放在内存中,那我们直接用快速排序就万事大吉了。如果还要精益求精,那就需要看如何才能减少比较和交换的次数,更有甚者,去追求 CPU register 或者 L1, L2 缓存的利用率。如果数据量太大,不能一次性全存放在内存中呢。这就需要用到我们上一期提到过的 spill to disk 技巧了:需要把数据暂存到文件系统中。这里,就引出今天提到的第一个算法:外部归并排序(external merge sort)。工程中要实现一个正确并且高效的外部归并排序是挺有挑战的,所以有些数据库系统在执行时需要消耗大量的内存或者干脆要求加入 limit 语句来限制排序数量。
首先,我们应该明确,如何来衡量一个外部归并排序的好坏。对于排序,你可能会脱口而出“快速排序,时间复杂度 O(n * log(n))”。但是一旦牵涉到了文件 IO,什么 O(n * log(n))都是浮云。因为文件读写的速度和内存差了两个量级(100X),正确的衡量方法应该是大致需要读写多少次的数据。为了方便衡量,我们先假设数据都是以页(page)的形式存放在文件系统中,并且以页的形式读取到内存中(即,每次读取的最小单位为 1 页)。
外部归并排序的思路和归并排序(merge sort)一样,都是利用了分治算法。整个算法分成两个阶段:阶段 0)把所有数据分成小段,并对每一段进行排序(这里假设每一小段都能够存放在内存中所以我们可以用各种排序算法实现); 阶段 1) 把每一小段逐渐合并,最终完成全部排序。具体实现起来,我们至少需要分配给这个排序算子 3 页的内存(2 个用来作为输入缓存,1 个用来作为输出缓存):假设输入数据总共有 n 页,排序只能 2 页 2 页地读取,排序,然后输出到文件系统暂存;然后对于已经排序完的 n/2 个文件(每个文件 2 页),再依次读取,排序,然后再输出文件系统暂存,直至得到一个 n 页的全排序文件。下图给出了一个示例:

外部排序示例 (picture credit:https://15445.courses.cs.cmu.edu/fall2018/)
上述的外排算法,总共读取了多少文件页呢。我们这样来算:
n #总共 n 页数据 # * 2 #读写各一次 # * (1 #第一次读和最后一次读 # + log2(n) #总共 log2(n)次归并 #) 即:
如果要对 n 页大小的数据进行排序并且只有 3 页的内存,需要读写 2n * (1 + log2(n))页。
现在假设排序算子能分配 b 页的内存,又该如何计算呢?思路是每一次可以合并 b-1 个页面,最后答案是:
2n * ( 1 + log_b-1(N/b) ):这里对数的底变成了 b-1 而不是原来的 2。留给大家自行推导啦。
据我所知,所有数据库的 spill to disk 排序大体思路都是外部归并排序,当然最后的快慢还是需要工程实践中的精益求精。
除了外排,还有什么方法能够过实现排序?不知大家是否回想起索引就是如果对要排序的键已经建有 B+树索引,可以通过 B+树索引查找到指定的叶节点,然后依次读取数据即可。
总结一下,我们讨论了排序能够过实现哪些 SQL 语句,并且介绍了两种排序的实现,分别是外部归并排序和读取 B+树索引结果。
聚合(aggregation)
聊完了排序,我们再来看聚合算子。聚合算子和聚合语句类型一一对应,那常见的聚合语句又有哪些呢?首先是单项聚合(scalar aggregation), 指聚合后的结果集是一个单一值(线性代数里称标量)。比如下面这些示例:

求学生总人数

求所有学生的平均年龄
其次就是组队聚合(group aggregation),其结果是先对所有数据根据 group by 键分组,然后对每个组分别计算聚合值。比如下面示例:
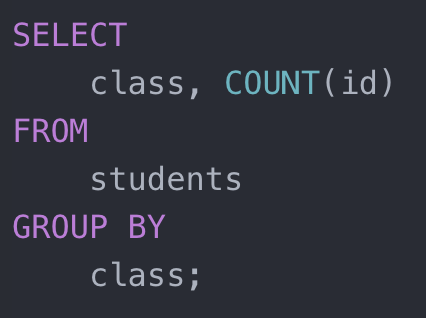
求每个班的学生个数
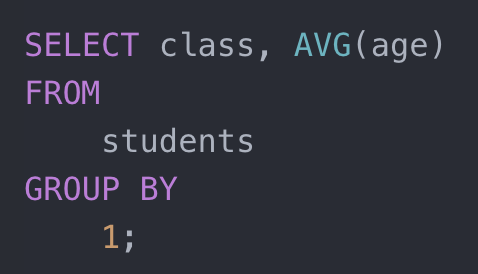
求每个班的学生平均年龄
考考大家,下面这个聚合属于哪个类别呢?

SELECT COUNT DISTINCT 语句
乍看之下,似乎是单项聚合因为结果集是一个标量,求总共有多少个不同的班级。但其实,这个语句可以看成是一个单项聚合和组队聚合的叠加,如下图所示:
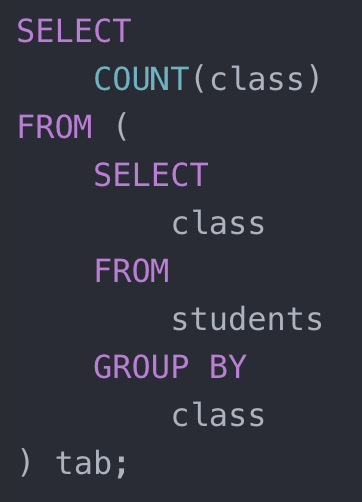
COUNT + GROUP BY
语句中先对班级进行组队聚合,虽然聚合值是空,然后对班级再进行单项聚合求 COUNT。
聊完了作用,来聊实现。单项聚合的实现非常简单,算子只需要保存一个聚合的中间值(running aggregate value),然后根据新输入不断更新即可。而且,绝大部分聚合函数的是不需要存储原始输入的,比如 max, min, count, avg 等,因此内存消耗也不大。示例代码如下:
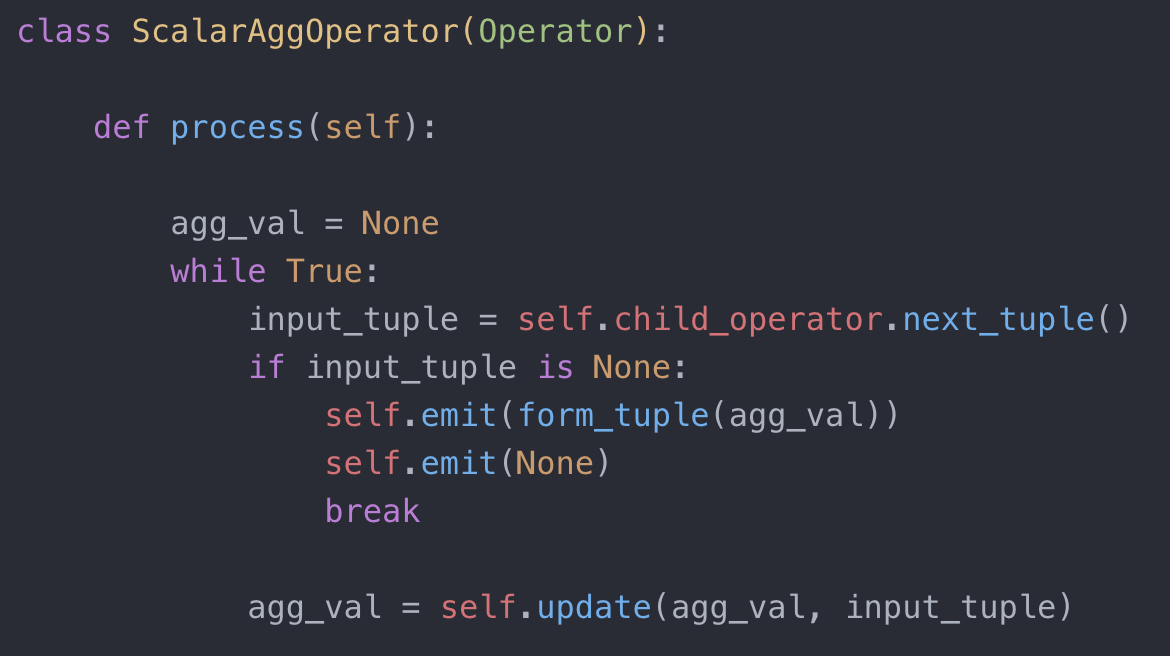
ScalarAgg 实现代码
再考考大家,你能想到有什么单项聚合函数的实现是需要消耗大量内存的吗?我唯一想到的就是求整个输入集合的熵(因为要统计所有不同元素的出现概率,相当于内部建立一个哈希表), 虽然感觉好像熵并不是一个 SQL 标准的聚合函数。
再来看组队聚合的实现。单从聚合函数角度出发,组队聚合于单项聚合的唯一区别就是,先要把 group by 键相同的输入放到一个组里,然后对每个组求解聚合函数即可。具体实现方法又有哪些呢?一就是上文提过的排序。我们可以借助排序先把输入按照 group by 键进行排序,然后我们只要针对相同的键来计算聚合函数即可。示例代码如下:
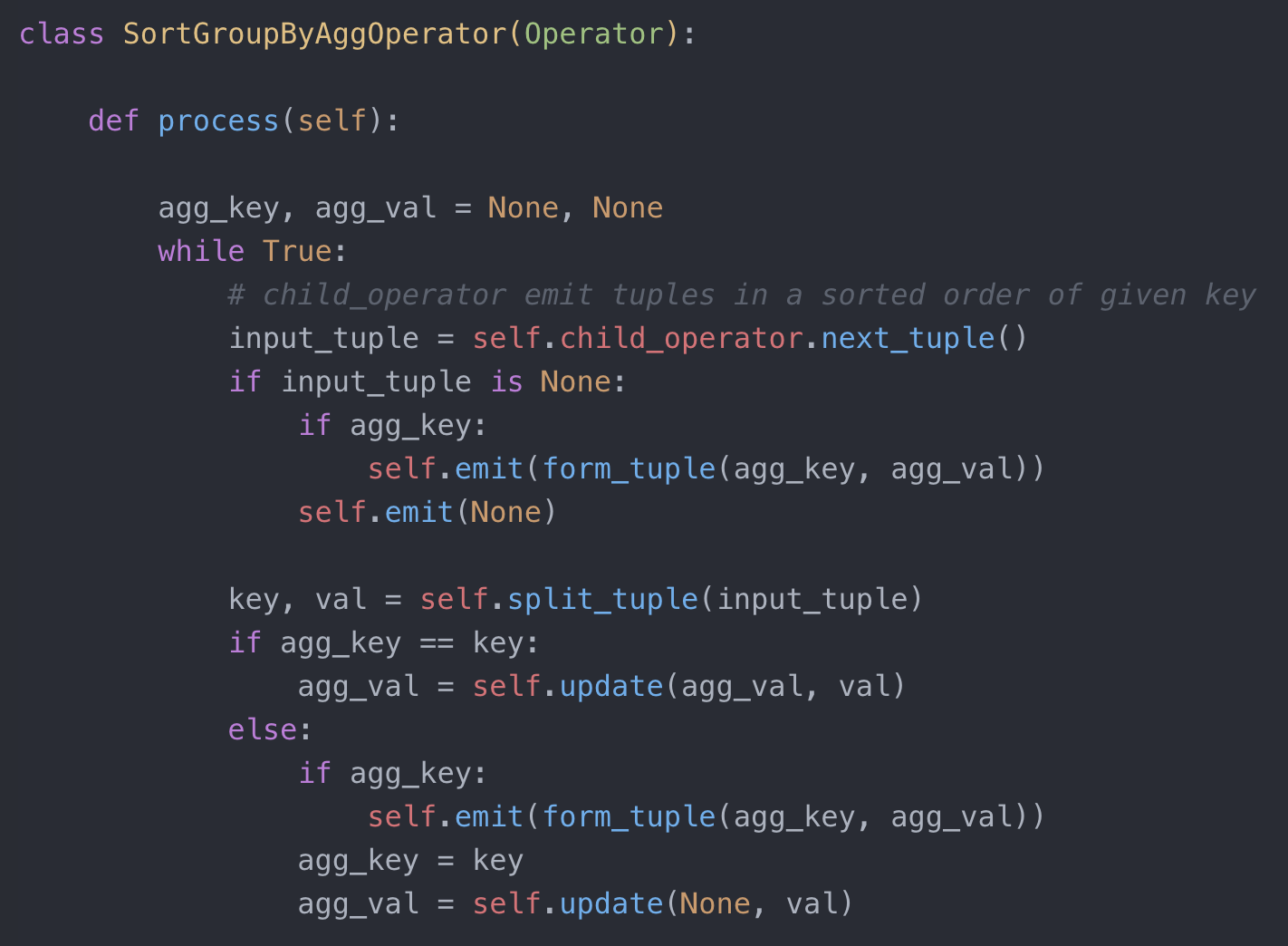
SortGroupByAgg 实现代码
从示例代码来看,由于脏活累活都让排序替我们干了,实现和单项聚合类似,并且从内存消耗角度来看,依然不大。
除了排序,还有什么办法能够帮我们实现聚合? 相信读者马上就能想到了,对 group by 键建立哈希表来维系键和中间值的状态。示例代码如下:
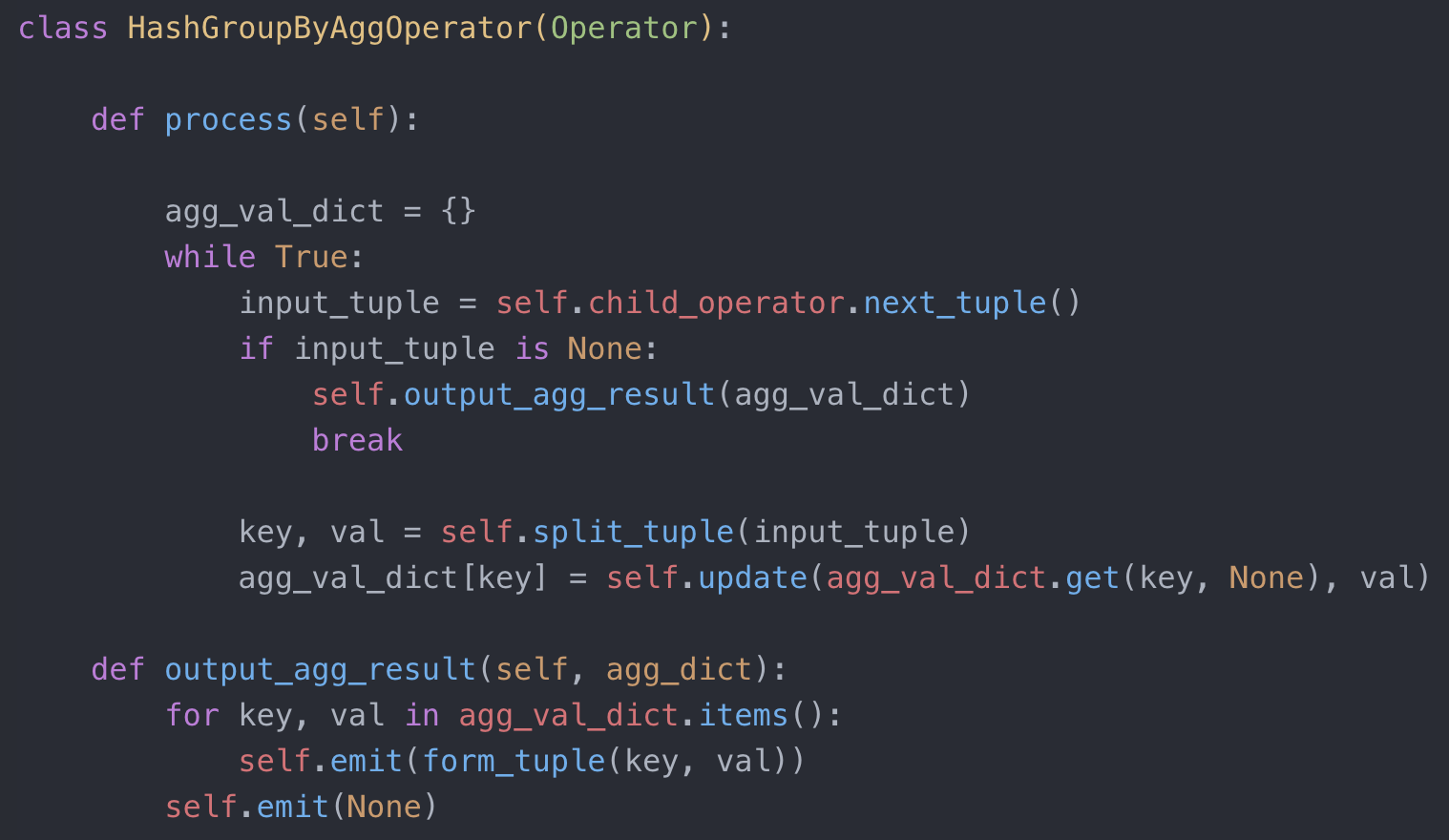
HashGroupByAgg 代码实现
从示例代码来看,逻辑依然简单明了。但难点在于,如果数据量特别大,就需要维护一个超级大的哈希表。考虑到需要维护哈希表的性能,一般维持使用率在 50%左右,所以真正使用的内存空间应该会更大。这就遇到和前面排序一样内存不够的问题了。所以说,出来混,迟早要还的。
解决思路当然依旧是借助文件系统暂存数据。这里,我们引出外部哈希表的算法。算法的思路依然是分而治之。我们假设聚合算子总共能分配到 b 个页面的内存。预留 1 页用作输入缓存,b-1 页用作分区(partition),对于那 1 页输入缓存中的所有数据,根据 group by 键求一个简单的哈希来分配到其他 b-1 页中(可以用下面这样的哈希函数:hash_fun(key) % (b -1 ))。这 b-1 个页作为 b-1 个分区的输出缓存,一旦写满就输出到文件系统中。扫描过一遍数据后,我们把整个数据就分成了 b-1 个文件。假设每个文件的大小在 b 页以内,那对于每一个文件,就可以利用上述的哈希表方法来实现组队聚合,并且能够保证不会超出 b 页内存。
读者可能会有疑问,万一有文件依然大于 b 页呢?有句名人名言怎么说的来着,没有什么事情是一顿火锅不能解决的,如果有,就两顿。解决思路就是对这个超大文件再用一次分区算法:换一个哈希函数,再把这些数据分成 b-1 个小分区。一层分区理论上能够解决 b^2 页大小的数据,而二层分区就能解决 b^3 大小。因此即使输入数据很大,也不会需要很多层的分区。
至此,我们介绍了外部哈希表的算法来解决聚合算子的内存消耗问题。
总结
今天,我们分别讨论了排序和聚合这两个算子用来实现哪些 SQL 语义,详细介绍了工程实现的要点,即通过外部归并排序和外部哈希表方法来解决内存消耗问题。并且也从中了解了排序算子可以用来协助实现聚合算子。
解答开篇的思考题,排序除了能够帮助实现 ORDER BY,GROUP BY 语句,还能实现表的联合 JOIN:思路和归并排序一样,对于二元联合 table_a JOIN table_b,我们只要针对联合键分别对 table_a 和 table_b 进行排序,然后,对于两个表分别维护一个指针,不断往后迭代,当两边的键值相同的时候,就可以输出联合的结果。具体的实现,咱们就放在下期表的联合(JOIN)的时候再聊。
作者介绍:
顾仲贤,现任 Facebook Tech Lead,专注于数据库,分布式系统,数据密集型应用后端架构与开发。拥有多年分布式数据库内核开发经验,发表数十篇数据库顶级期刊并申请获得多项专利,对搜索,即时通讯系统有深刻理解,爱设计爱架构,持续跟进互联网前沿技术。
2008 年毕业于上海交大软件学院,2012 年,获得美国加州大学戴维斯计算机硕士,博士学位;2013-2014 年任 Pivotal 数据库核心研发团队资深工程师,开发开源数据库优化器 Orca;2016 年作为初创员工加入 Datometry,任首席工程师,负责全球首家数据库虚拟化平台开发;2017 年至今就职于 Facebook 任 Tech Lead,领导重构搜索相关后端服务及数据管道, 管理即时通讯软件 WhatsApp 数据平台负责数据收集,整理,并提供后续应用。
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 9 条评论