

AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务,您可以用来登记、清理和丰富数据,并可以在数据存储之间可靠地移动数据。
Glue 的组件包括:
数据目录
爬网程序和分类器
ETL操作
作业系统
在本篇文章中,主要展示了 Glue 的爬网程序,数据目录和 ETL 操作的功能,并通过一个业务场景完成一个简单的 demo。
先决条件: 到https://mockaroo.com/生成一份测试数据,上传到 s3://myglue-sample-data/rawdata/sampledata/。具体步骤,请参考:https://docs.aws.amazon.com/AmazonS3/latest/gsg/CreatingABucket.html
一.AWS Glue 数据目录
AWS Glue 数据目录是您的持久性元数据存储。它是一项托管服务,可让您在 AWS 云中存储、注释和共享元数据,就像在 Apache Hive 元存储中一样。
数据目录可以用于:
Athena
Redshift Spectrum
EMR
以及自建Hadoop的Hive
使用 Glue 托管的数据目录有很多好处
只需通过爬虫爬取一次表结构就可以在多个地方使用
您无需再为数据目录进行每天备份,无需额外创建RDS来存储,节省维护成本
Glue托管的数据目录是通过IAM策略进行管理,可以对不同的IAM用户限制相应的库表权限,非常灵活
同时Glue的库表也可以跨region,跨账户授权,非常适合多账户,跨region的集中式的元数据管理
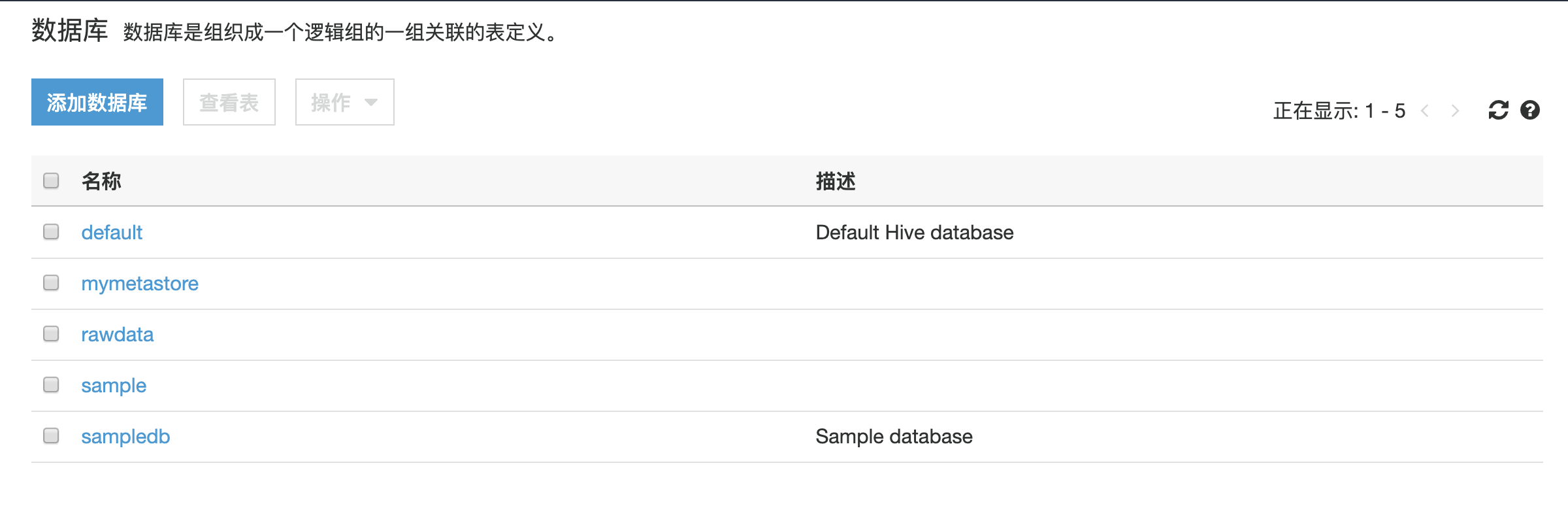
数据库的创建
进入 Glue 控制台,在左侧导航栏选择<数据库>,点击添加数据库

创建后,数据库会在下面显示

在添加完数据库后,需要使用爬虫来爬取表,将表信息写入到数据库里
二.通过爬网程序解析并存储数据的元数据(metadata)
在传统的大数据业务场景中,一般都需要先建表,然后再进行操作,Glue 的爬网程序很好的解决了这部分操作,通过爬虫爬取源数据和 ETL 后数据的数据结构,并保存在 DataCatalog 相应的 Database 下。
具体操作
爬取 s3://myglue-sample-data/rawdata/sampledata/sampledata.csv 的数据结构
在 Glue 控制台,在左侧导航栏选择<爬网程序>,右侧主窗口点击“添加爬往程序”,输入爬网程序的名称

选择 Data Stores,即创建新的表

源数据在 S3 上,所以选择 S3,选择 S3 源数据的位置,表名不写,爬虫会自动根据文件名创建表名

添加另一个数据存储,选“否”

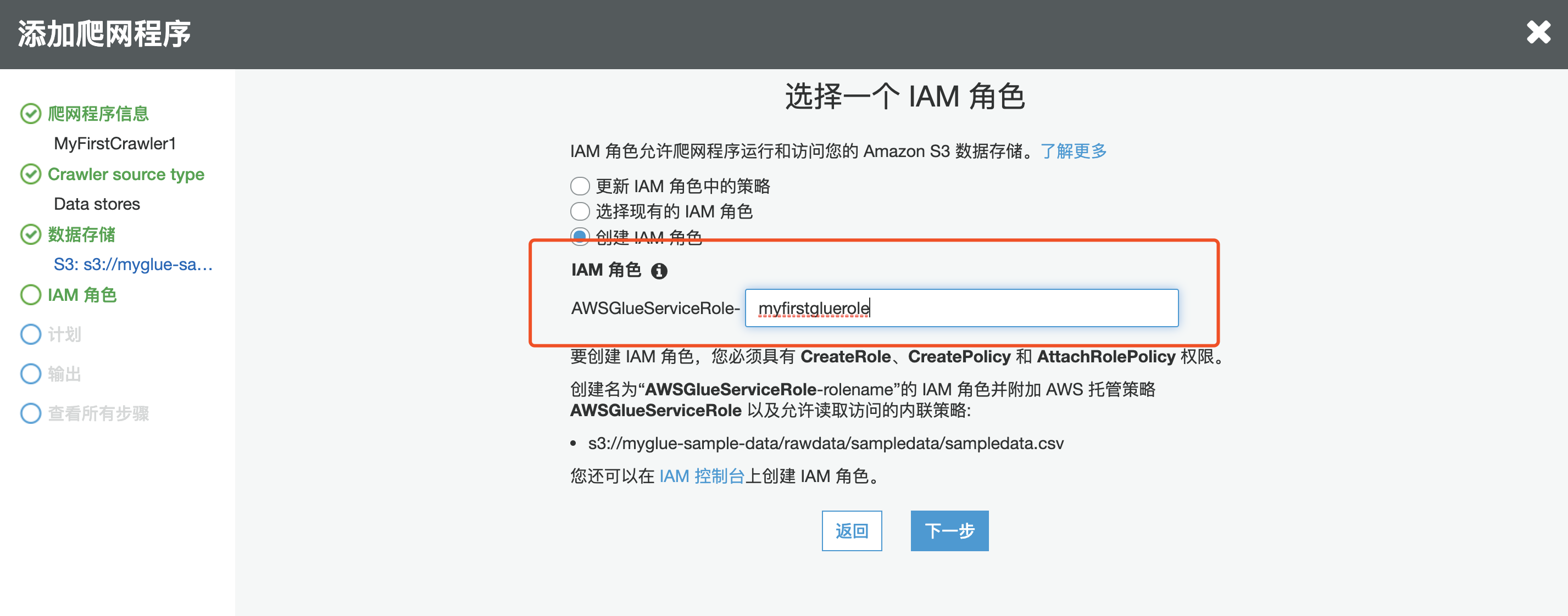
下一步,创建执行爬虫做需要的 Role,
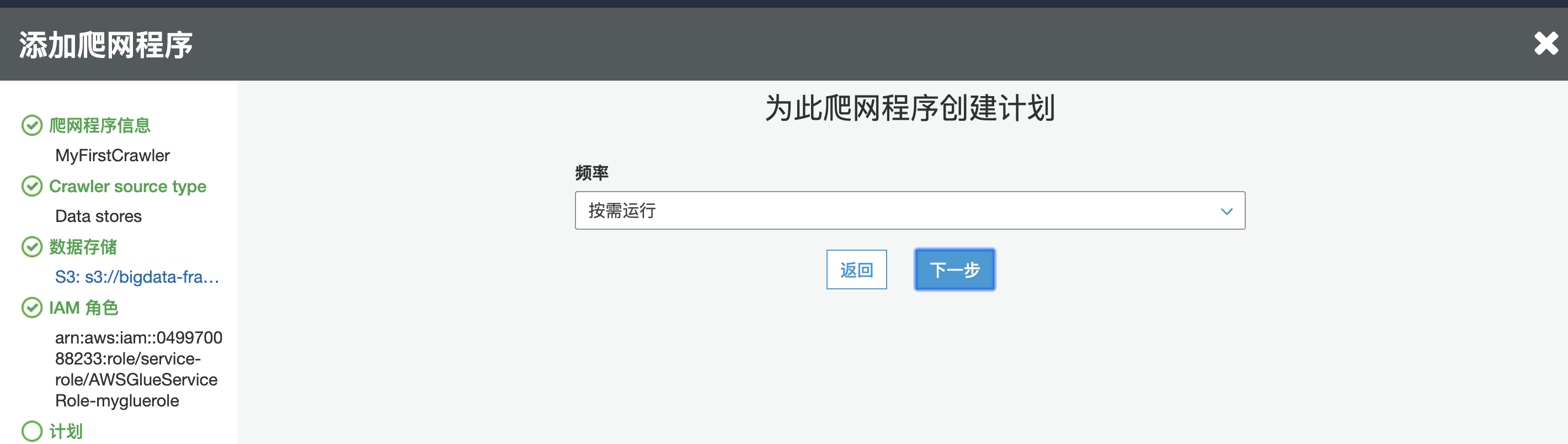
为此爬往程序创建计划,选择“按需运行“
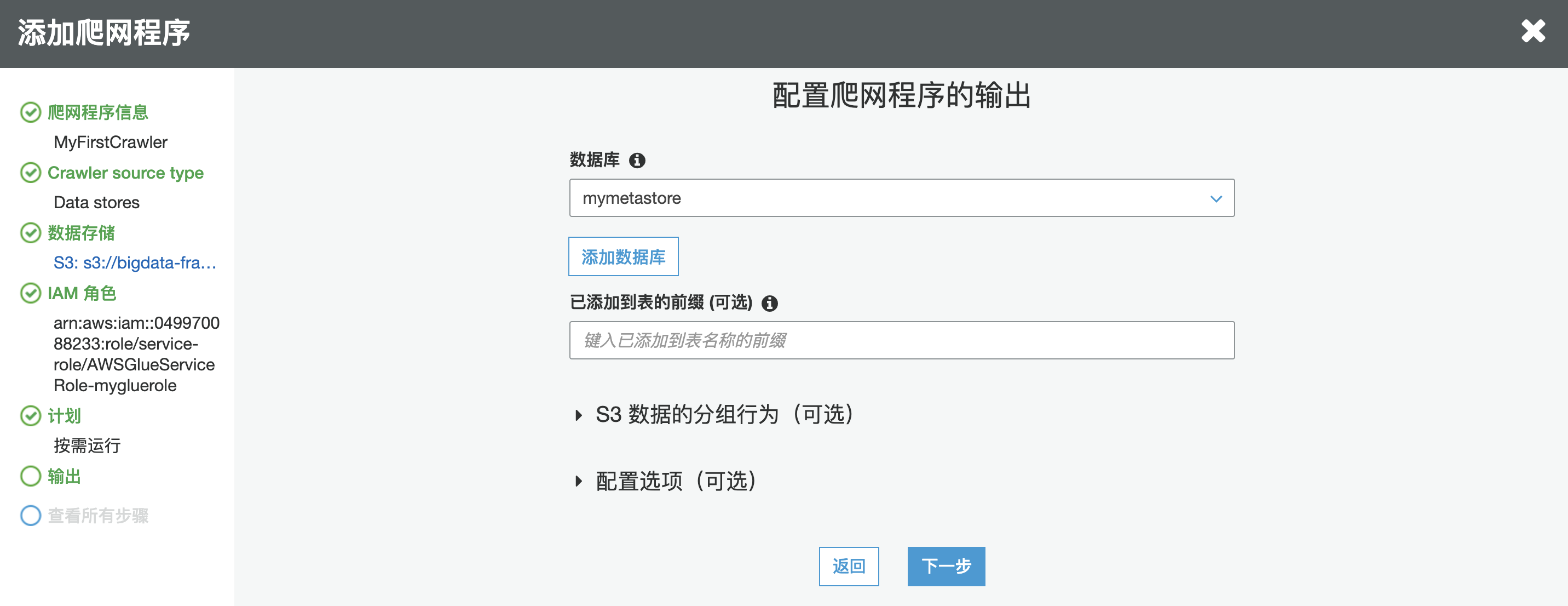
设置爬往程序的输出,选择之前创建过的 mymetastore
点击“下一步“,点击”完成“
至此,在“爬往程序“窗口,您可以看到新创建的爬虫程序已经在列表里。
点击“立即运行“

在页面下方,您可以看到爬网程序的运行状态。等待该爬网程序运行结束。
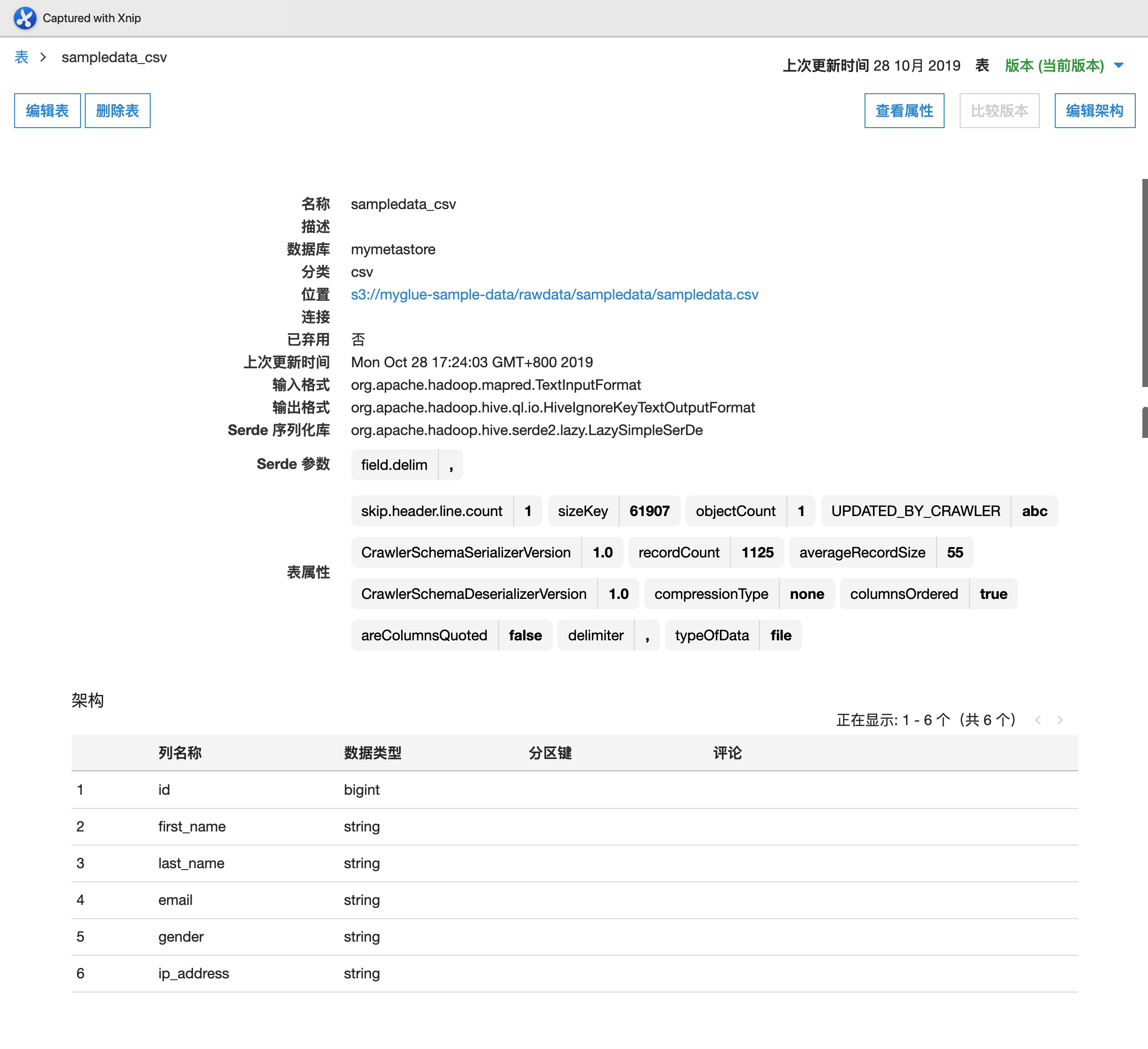
在左侧导航栏中,选择“表“,右侧筛选框中,输入之前创建的数据库“mymetastore“,您可以看到表 sampledata_csv 已经创建完毕

点击表,查看表结构如下
三.Serverless ETL
下面我们对该表进行 ETL,把源数据的字段进行 rename 后,写入到另一个 S3 位置
在左侧导航栏中,选择“表“,右侧页面点击”添加作业“
输入作业名称,Role 选择之前创建的 AWSGlueServiceRole-myfirstgluerole

指定数据源,选择要进行 ETL 的数据源

转换类型,选择默认值

指定数据目标,这里将 ETL 之后的数据存放在 S3 上的一个新位置,并以 Parquet 格式存储。这里选 S3://myglue-sample-data/etldata/sampledata

这里修改字段名称,然后点击”保存作业并编辑脚本”

进入 Glue ETL UI 编辑页面,可以看到代码部分,这里只做简单功能展示(具体 Glue 可以进行的操作见https://docs.aws.amazon.com/zh_cn/glue/latest/dg/aws-glue-programming.html),点击”运行作业”
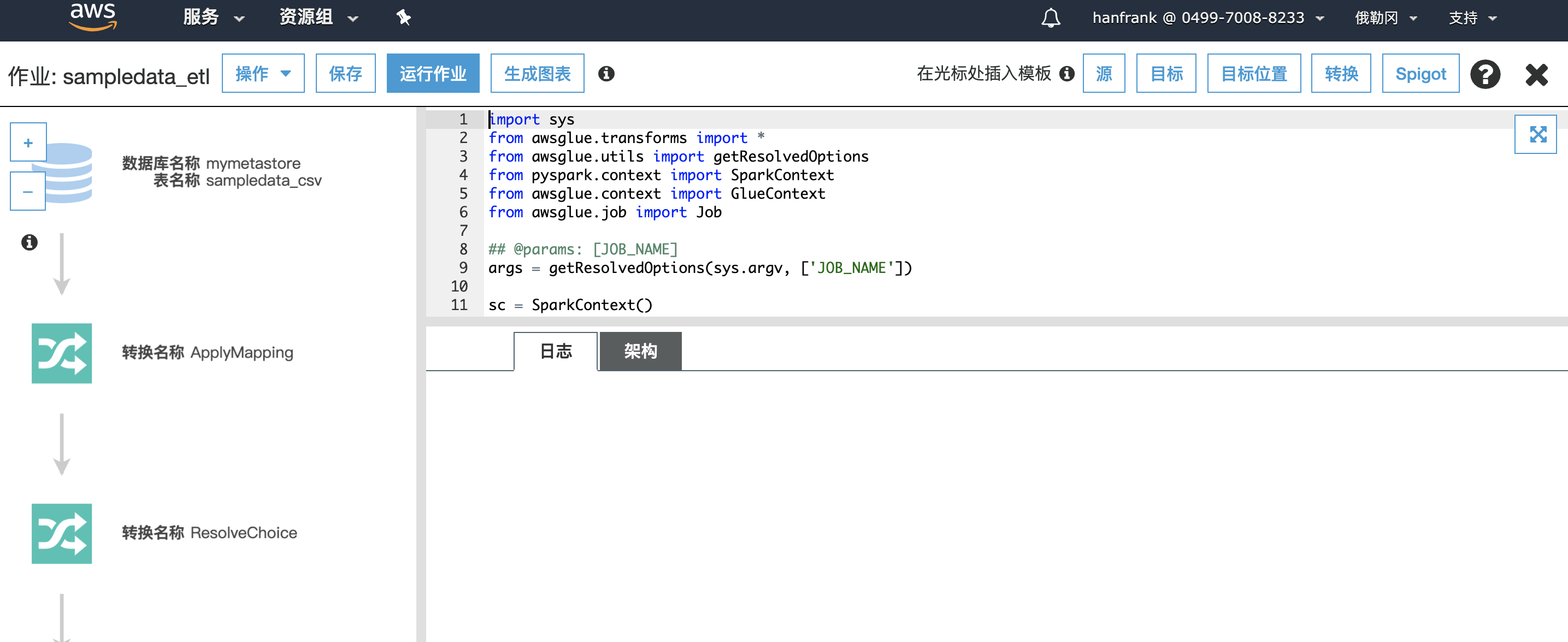
显示运行成功后,到 S3 里可以看到文件已经成功输出

重复前述的第 2 步,创建一个新的爬网程序,对 ETL 后的数据进行爬取。
完成后,你将会看到新的数据结构已经变化

附: Data Catalog 在 Athena 和 EMR 里的应用
进入 Athena 的页面,左侧导航栏<数据库>下面选择”mymetastore”,
我们可以看到 Athena 里已经有这两张表了,对其中一张表进行查询

在创建 EMR 的时候,选择 Glue 作为 Hive 的 metastore

Glue 的 DB 如下
Hive 里显示的如下

依次执行
Python
可以看出表结构信息和 Glue console 显示的一样,

执行简单的 Hive SQL 查询,成功
Bash

使用 Glue 作为 EMR Hive 的 metastore 有一些限制,详看
https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-hive-metastore-glue.html
本篇作者
本文转载自 AWS 技术博客。
原文链接:https://amazonaws-china.com/cn/blogs/china/glue-function-introduction-build-serverless-etl-quickly/

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论