

介绍
Etcd 是一个开源的分布式键值存储,它由 CoreOS 团队开发,现在由 Cloud Native Computing Foundation 负责管理。这个词的发音是“et-cee-dee”,表示在多台机器上分发 Unix 系统的“/etc”目录,其中包含了大量的全局配置文件。它是许多分布式系统的主干,为跨服务器集群存储数据提供可靠的方式。它适用于各种操作系统,包括 Linux、BSD 和 OS X。
Etcd 具有下面这些属性:
完全复制:集群中的每个节点都可以使用完整的存档
高可用性:Etcd 可用于避免硬件的单点故障或网络问题
一致性:每次读取都会返回跨多主机的最新写入
简单:包括一个定义良好、面向用户的 API(gRPC)
安全:实现了带有可选的客户端证书身份验证的自动化 TLS
快速:每秒 10000 次写入的基准速度
可靠:使用 Raft 算法实现了存储的合理分布
Etcd 的工作原理
在理解 Etcd 的工作机制之前,我们先定义三个关键概念:leaders、elections 以及 terms。在一个基于 Raft 的系统中,集群使用 election 为给定的 term 选择 leader。
Leader 处理所有需要集群一致协商的客户端请求。不需要一致协商的请求(如读取)可以由任何集群成员处理。Leader 负责接受新的更改,将信息复制到 follower 节点,并在 follower 验证接受后提交更改。每个集群在任何给定的时间内只能有一个 leader。
如果 leader 挂了或者不再响应了,那么其他节点将在预定的时间超时之后开启一个新的 term 来创建新 election。每个节点维护一个随机的 election 计时器,该计时器表示节点在调用新的 election 以及选择自己作为候选之前需要等待的时间。
如果节点在超时发生之前没有收到 leader 的消息,则该节点将通过启动新的 term、将自己标记为候选,并要求其他节点投票来开始新的 election。每个节点投票给请求其投票的第一个候选。如果候选从集群中的大多数节点处获得了选票,那么它就成为了新的 leader。但是,如果存在多个候选且获得了相同数量的选票,那么现有的 election term 将在没有 leader 的情况下结束,而新的 term 将以新的随机选举计时器开始。
如上所述,任何更改都必须连接到 leader 节点。Etcd 没有立即接受和提交更改,而是使用 Raft 算法确保大多数节点都同意更改。Leader 将提议的新值发送到集群中的每个节点。然后,节点发送一条消息确认收到了新值。如果大多数节点确认接收,那么 leader 提交新值,并向每个节点发送将该值提交到日志的消息。这意味着每次更改都需要得到集群节点的仲裁才能提交。
Kubernetes 中的 Etcd
自从 2014 年成为 Kubernetes 的一部分以来,Etcd 社区呈现指数级的增长。CoreOS、谷歌、Redhat、IBM、思科、华为等等均是 Etcd 的贡献成员。其中 AWS、谷歌云平台和 Azure 等大型云提供商成功在生产环境中使用了 Etcd。
Etcd 在 Kubernetes 中的工作是为分布式系统安全存储关键数据。它最著名的是 Kubernetes 的主数据存储,用于存储配置数据、状态和元数据。由于 Kubernetes 通常运行在几台机器的集群上,因此它是一个分布式系统,需要 Etcd 这样的分布式数据存储。
Etcd 使得跨集群存储数据和监控更改变得更加容易,它允许来自 Kubernetes 集群的任何节点读取和写入数据。Kubernetes 使用 Etcd 的 watch 功能来监控系统实际(actual)状态或期望(desired)状态的变化。如果这两个状态不同,Kubernetes 会做出一些改变来调和这两个状态。kubectl 命令的每次读取都从 Etcd 存储的数据中检索,所做的任何更改(kubectl apply)都会在 Etcd 中创建或更新条目,每次崩溃都会触发 etcd 中值的修改。
部署以及硬件建议
出于测试或开发目的,Etcd 可以在笔记本电脑或轻量云上运行。然而,在生产环境中运行 Etcd 集群时,我们应该考虑 Etcd 官方文档提供的指导。它为良好稳定的生产部署提供了一个良好的起点。需要留意的是:
Etcd 会将数据写入磁盘,因此强烈推荐使用 SSD
始终使用奇数个集群数量,因为需要通过仲裁来更新集群的状态
出于性能考虑,集群通常不超过 7 个节点
让我们回顾一下在 Kubernetes 中部署 Etcd 集群所需的步骤。之后,我们将演示一些基本的 CLI 命令以及 API 调用。我们将结合 Kubernetes 的概念(如 StatefulSets 和 PersistentVolume)进行部署。
预先准备
在继续 demo 之前,我们需要准备:
一个谷歌云平台的账号:免费的 tier 应该足够了。你也可以选择大多数其他云提供商,只需进行少量修改即可。
一个运行 Rancher 的服务器
启动 Rancher 实例
在你控制的服务器上启动 Rancher 实例。这里有一个非常简单直观的入门指南:https://rancher.com/quick-start/
使用 Rancher 部署 GKE 集群
参照本指南使用 Rancher 在 GCP 账户中设置和配置 Kubernetes 集群:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/hosted-kubernetes-clusters/gke/
在运行 Rancher 实例的同一服务器上安装 Google Cloud SDK 以及 kubelet 命令。按照上面提供的链接安装 SDK,并通过 Rancher UI 安装 kubelet。
使用 gcloud init 和 gcloud auth login,确保 gcloud 命令能够访问你的 GCP 账户。
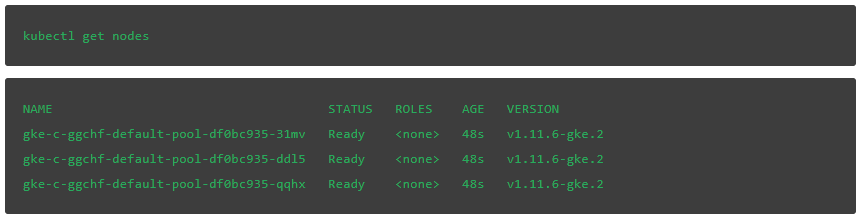
集群部署后,输入下面的命令检查基本的 kubectl 功能:
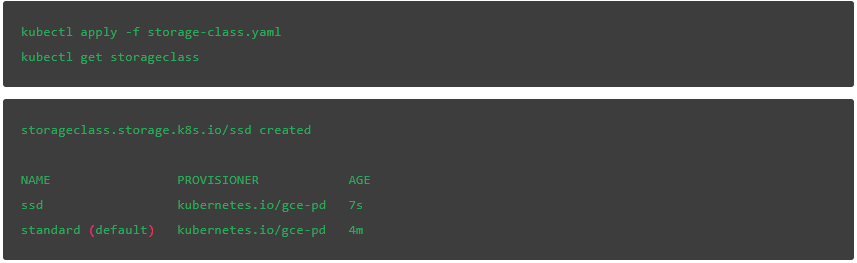
在部署 Etcd 集群(通过 kubectl 或在 Rancher 的 UI 中导入 YAML 文件)之前,我们需要配置一些项。在 GCE 中,默认的持久化磁盘是 pd-standard。我们将为 Etcd 部署配置 pd-ssd。这不是强制性的,不过根据 Etcd 的建议,SSD 是非常好的选择。查看此链接可以了解其他云提供商的存储类:
https://kubernetes.io/docs/concepts/storage/storage-classes/
让我们检查一下 GCE 提供的可用存储类。正如预期的那样,我们看到了一个默认的结果,叫做 standard:

应用下面这个 YAML 文件,更新 zone 的值来匹配你的首选项,这样我们就可以使用 SSD 存储了:

我们再一次检查,可以看到,除了默认 standard 类之外,ssd 也可以使用了:
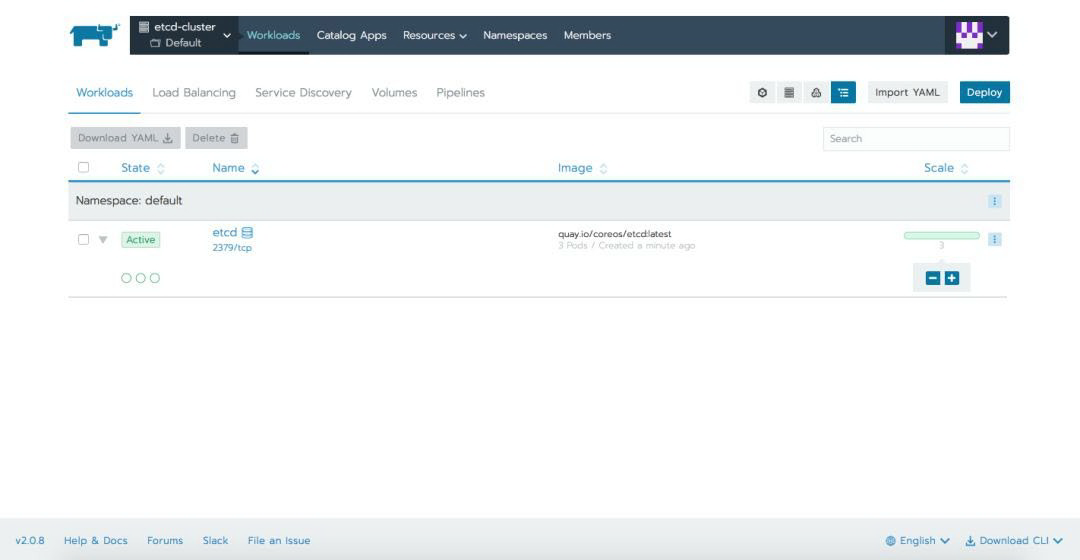
现在我们可以继续部署 Etcd 集群了。我们将创建一个带有 3 个副本的 StatefulSet,每个副本都有一个 ssd storageClass 的专用卷。我们还需要部署两个服务,一个用于内部集群通信,一个用于通过 API 从外部访问集群。
在搭建集群时,我们需要将一些参数传递给 Etcd 二进制文件再到数据存储中。Listen-client-urls 和 listen-peer-urls 选项指定 Etcd 服务器用于接受传入连接的本地地址。指定 0.0.0.0 作为 IP 地址意味着 Etcd 将监听所有可用接口上的连接。Advertise-client-urls 和 initial-advertise-peer-urls 参数指定了在 Etcd 客户端或者其他 Etcd 成员联系 etcd 服务器时应该使用的地址。
下面的 YAML 文件定义了我们的两个服务以及 Etcd StatefulSe 图:
输入下列命令应用 YAML:

在应用 YAML 文件后,我们可以在 Rancher 提供的不同选项卡中定义资源:
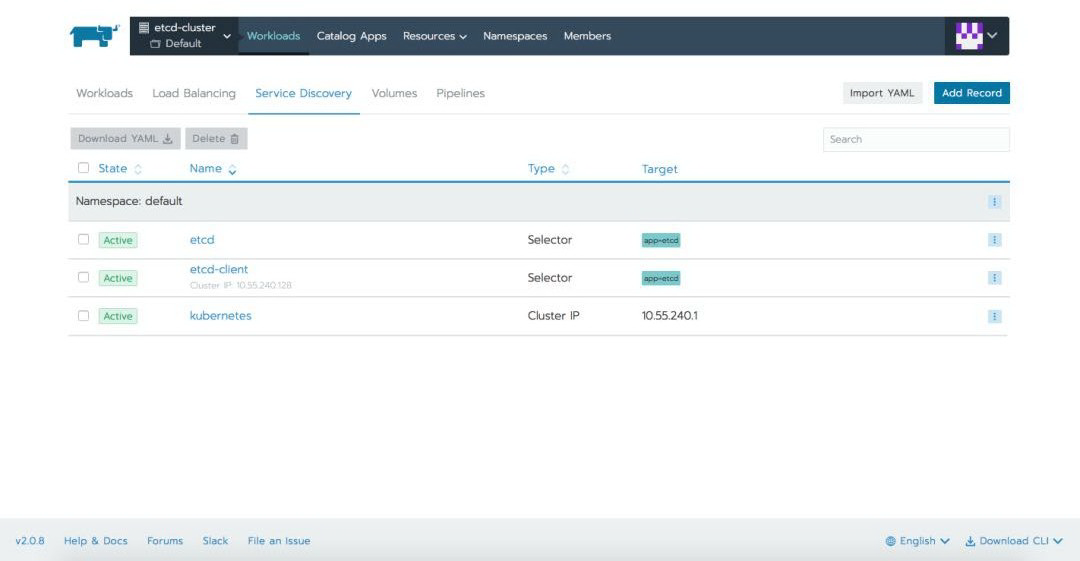
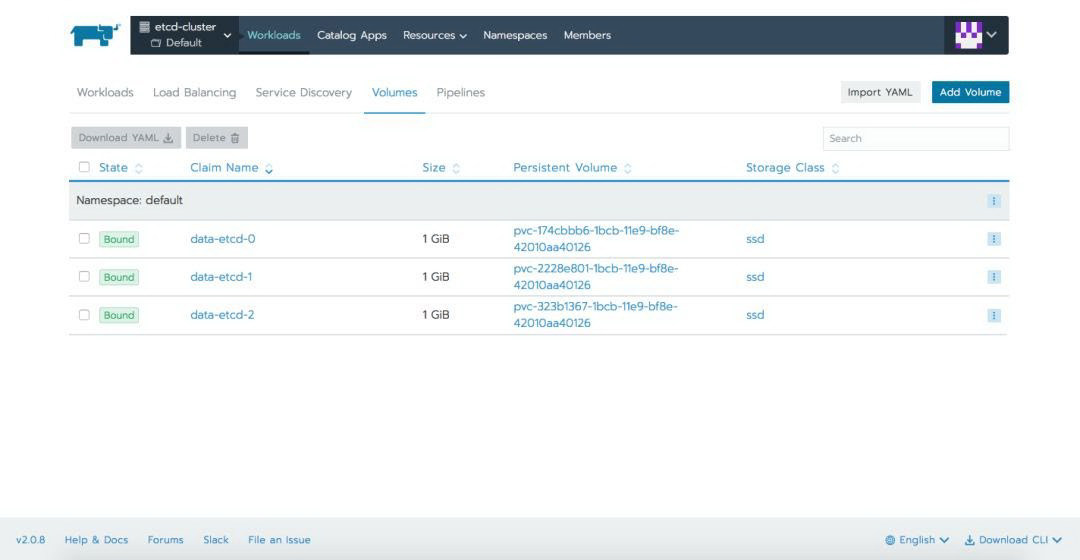
与 Etcd 交互
与 Etcd 交互的方式主要有两种:使用 etcdctl 命令或者直接通过 RESTful API。我们将简要介绍这两种方法,不过你还可以通过访问这里和这里的完整文档找到更加深入的信息和示例。
Etcdctl 是一个和 Etcd 服务器交互的命令行接口。它可以用于执行各种操作,如设置、更新或者删除键、验证集群健康情况、添加或删除 Etcd 节点以及生成数据库快照。默认情况下,etcdctl 使用 v2 API 与 Etcd 服务器通信来获得向后兼容性。如果希望 etcdctl 使用 v3 API 和 Etcd 通信,则必须通过 ETCDCTL_API 环境变量将版本设置为 3。
对于 API,发送到 Etcd 服务器的每一个请求都是一个 gRPC 远程过程调用。这个 gRPC 网关提供一个 RESTful 代理,能够将 HTTP/JSON 请求转换为 gRPC 消息。
让我们来找到 API 调用所需的外部 IP:
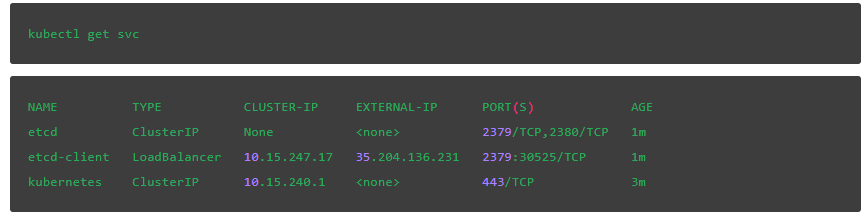
我们应该还能找到 3 个 pods 的名称,这样我们就可以使用 etcdctl 命令:

我们检查 Etcd 版本。为此我们可以使用 API 或 CLI(v2 和 v3).根据你选择的方法, 输出的结果将略有不同。
使用此命令可直接与 API 联系:

检查 API 版本为 v2 的 etcdctl 客户端,输入:

检查 API 版本为 v3 的 etcdctl 客户端,则输入:

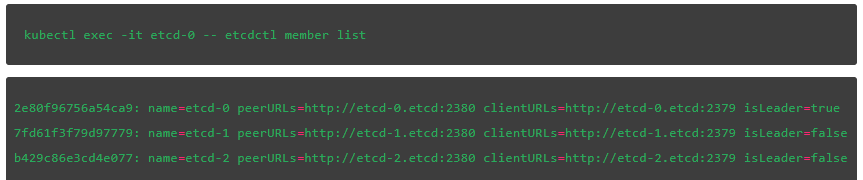
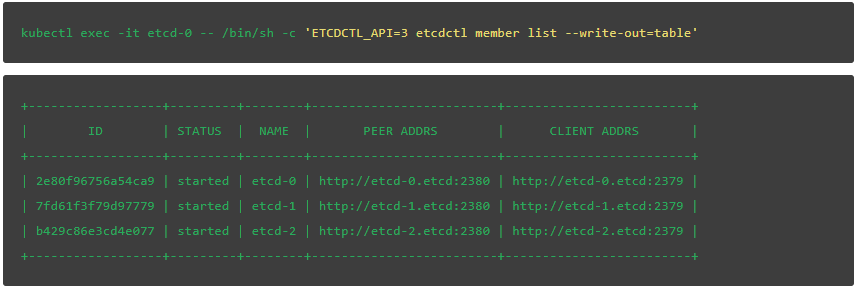
接下来,列出集群成员,就像我们上面做的那样:

V2 版本的 etcdctl:
V3 版本的 etcdctl:
在 Etcd 中设置和检索值
下面我们将介绍的最后一个示例是在 Etcd 集群中全部 3 个 pods 上创建一个键并检查其值。然后我们会杀掉 leader,在我们的场景中是 etcd-0,然后来看看新的 leader 是如何选出来的。最后,在集群恢复之后,我们将在所有成员上验证之前创建的键的值。我们会看到,没有数据丢失的情况发生,集群只是换了一个 leader 而已。
我们可以通过输入下面的命令来验证集群最初是健康的:

接下来,验证当前 leader。最后一个字段表明 etcd-0 是我们集群中的 leader:
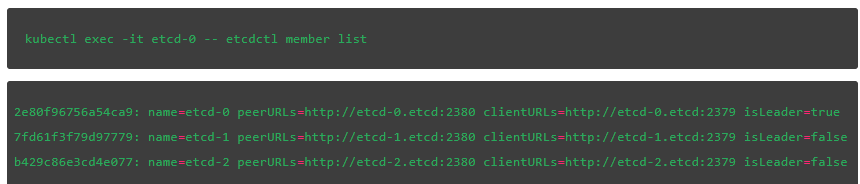
使用该 API,我们将创建一个名为 message 的键并给它分配一个值,请记住在下面的命令中把 IP 地址替换为你在集群中通过下面命令获取到的地址:

无论查询哪个成员,键都具有相同的值。这帮助我们验证值是否已经复制到其他节点并提交到日志。

演示高可用性和恢复
接下来,我们可以杀掉 Etcd 集群 leader。这样我们可以看到新的 leader 是如何选出的,以及集群如何从 degraded 状态中恢复过来。删除与上面发现的 Etcd leader 相关的 pod:

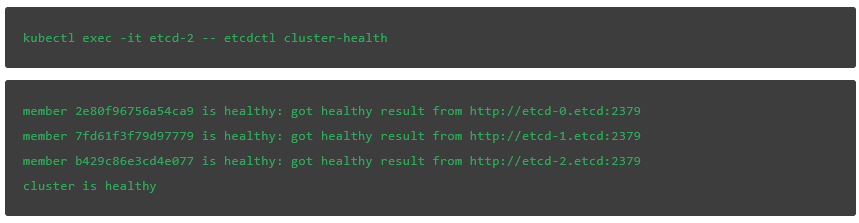
下面我们检查一下集群的健康情况:

上面的信息表明,由于失去了 leader 节点,集群出于 degrade 状态。
一旦 Kubernetes 通过启动新实例来响应删除的 pod,Etcd 集群应该就恢复过来了:
输入下面指令,我们可以看到新的 leader 已经选出来了:
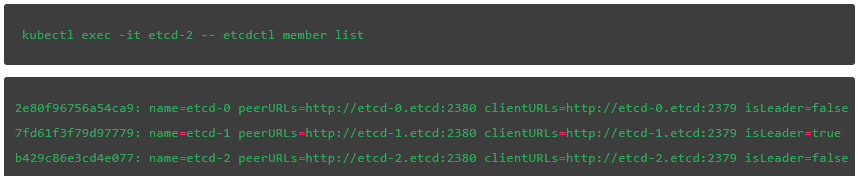
在我们的例子中,etcd-1 节点被选为 leader
如果我们再一次检查 message 键的值,会发现没有出现数据的损失:

结论
Etcd 是一种非常强大、高可用以及可靠的分布式键值存储,专门为特定用例设计。常见的例子包括存储数据哭连接细节、缓存设置、特性标记等等。它被设计成顺序一致的,因此在整个集群中每个事件都是以相同的顺序存储。
我们了解了如何在 Rancher 的帮助下用 Kubernetes 建立并运行 etcd 集群。之后,我们能够使用一些基本的 Etcd 命令进行操作。为了更好的了解这个项目,键是如何组织的,如何为键设置 TTLs,或者如何备份所有数据,参考官方的 Etcd repo 会是个不错的选择:
https://github.com/etcd-io/etcd/tree/master/Documentation

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论