

近两年,联邦学习技术发展迅速。作为分布式的机器学习范式,联邦学习能够有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,从技术上打破数据孤岛。但是,目前这一技术在很多企业落地遇到了困难,InfoQ 将通过选题的方式逐一揭开各大公司在联邦学习方面的探索。
为了让机器学习模型取得更好的效果,开发者往往希望获得更多数据训练模型,而有助于解决该问题的联邦学习受到了越来越多的关注。简单来说,联邦学习可以在不共享数据的前提下,利用双方数据实现模型优化,在数据隐私越来越重要的今天,联邦学习很好的平衡了隐私和数据利用之间的关系。正因如此,很多科技公司在联邦学习方向有所探索。
近日,百度宣布开源基于飞桨( PaddlePaddle) 开源框架的联邦学习框架 PaddleFL 。据了解,研究人员可以很轻松地用 PaddleFL 复现和比较不同的联邦学习算法;得益于飞桨在大规模并行训练方面的基础能力的积累,PaddleFL 可以帮助开发者快速实现在大规模分布式集群中部署联邦学习系统。对此,InfoQ 采访了百度深度学习研发工程师,为大家进一步剖析 PaddleFL 的技术原理和提供联邦学习部署的建议。
PaddleFL 为何而生?
众所周知,百度在 2016 年就开源了深度学习平台 PaddlePaddle,而为了帮助飞桨开发者快速调研一些联邦学习算法,作为底层编程框架支撑上层应用,PaddleFL 应运而生。
百度工程师表示,PaddleFL 为联邦学习研究人员提供了基础编程框架,并封装了一些公开的联邦学习数据集。针对横向联邦学习场景,PaddleFL 实现了多种不同的优化算法,举例来说 DP-SGD、Fed-Avg、Secure-Aggregate 都是在飞桨开源框架灵活的编程组件之上搭建的。此外,借助于飞桨丰富的模型库和预训练模型,研究人员也可以快速上手针对一些具体的垂直场景应用进行研究。
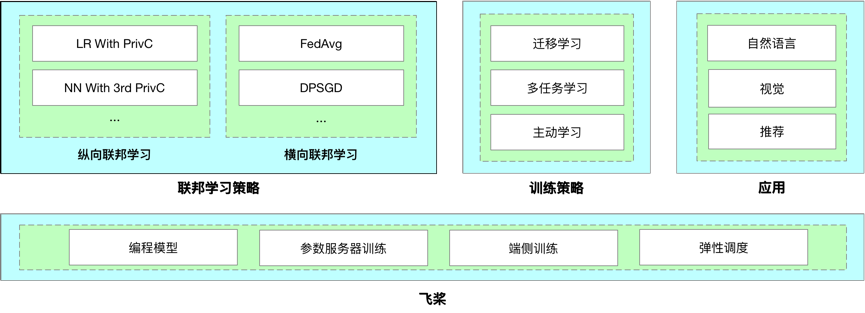
图 1
PaddleFL 整体的建设方向可以参考图 1,当前 PaddleFL 已经开源了完整的横向联邦学习能力,底层的编程模型采用飞桨训练框架,结合飞桨的参数服务器功能,PaddleFL 可以实现在 Kubernetes 集群中进行横向联邦学习系统的部署。值得一提的是,尽管横向联邦学习与传统的数据并行分布式训练原理一致,但在如何部署训练任务的方式上有一些区别:
1)横向联邦学习中,参与训练的各方数据格式可能不同,这需要框架能够支持不同类型数据读取器,并在同一套训练系统里运行。
2)横向联邦学习中的各方以及模型参数维护方可能处于不同的集群当中,很难通过一次统一的调度实现多方训练任务同时启动。
为此,PaddleFL 设计了编译期阶段,在编译期通过多方协商生成一个具有共识的网络配置,然后由 PaddleFL 自动拆分成多方集群需要运行的程序,大大简化部署过程,同时也开发了二次开发接口允许各方定义私有化的数据读取器。编译期和执行期的关系可以参考下图:
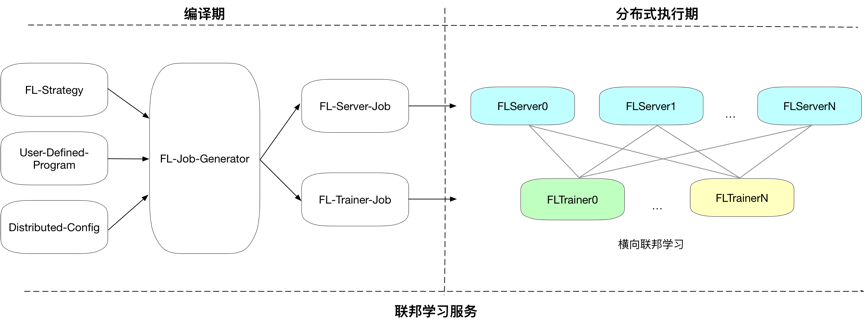
图 2
当前,PaddleFL 已经开源了横向联邦的场景,适合有相同类型任务的多个组织进行联合训练。针对云端提供计算资源,但用户不愿意上传原始数据的应用场景,PaddleFL 也开源了一套两方安全学习的方案。以图像分类为例,可以参考图 3,用户通过本地计算资源,利用图像的预训练模型的前几层进行图片原始数据的编码,云端接收客户端的编码以及对应的标签进行训练,这种模式在保护用户原始数据的情况下可以提供用户云端进行安全训练的能力。
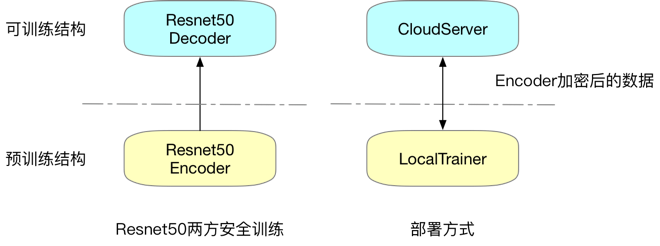
图 3
PaddleFL 未来之路
据了解,在接下来的迭代中,飞桨将会开源纵向联邦学习编程框架,并在横向与纵向之间进行编程接口方面的统一。借助于飞桨训练框架的快速迭代,PaddleFL 在分布式训练的速度,跨地域的稀疏通信以及通信的稳定性方面都会得到稳步的提升。在应用层,PaddleFL 还将提供传统机器学习训练策略的应用,例如多任务学习、联邦学习环境下的迁移学习。基于飞桨丰富的模型库,PaddleFL 还将开放更多适合联邦学习的模型示例和部署教程,方便用户学习。
由于是基于飞桨开源框架的联邦学习框架,所以目前安装 PaddleFL 的时候会自动安装飞桨开源框架依赖,两者有绑定关系。建议开发者能够把 PaddleFL 当成底层编程框架,在上层封装出一些支撑垂直领域的平台,探索联邦学习的更多产品形态。
企业该如何部署联邦学习?
虽然我们已经可以看到联邦学习在一些实际业务场景中有了应用,但只能算是刚刚开始,这项技术目前还远远没有进入大规模落地的阶段,这样意味着存在大量的机会和挑战。
百度工程师表示,搭建一个方便易用的平台还是十分重要的,参与联邦训练的开发者不一定非要知道自己在采用联邦学习技术,平台能够让用户知道自己的数据很安全且不会泄露,以及业务的实际效果有提升,这才是最关键的。
目前来看,百度工程师补充道,面向 C 端用户的端上产品,落地联邦学习的可能性比较大,例如在手机的 app 端利用联邦学习为用户提供快速且安全的个性化能力就是一个典型的横向联邦学习场景。企业级的联邦学习,跨群组、跨分公司的联邦学习更容易成功,前提是有一个置信的、易用的联邦学习平台以及相关的政策法规做保障。

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论