
文 / 杨帆,王强强
背景与需求
目前,英语是世界通用语言,掌握了英语就有了与世界沟通、交流的工具。但是,中国普遍存在的“哑巴英语”、“中式英语”、发音不准等现象,极大地影响了英语学习者的听说能力,以及在实际生活中对英语的使用。近年来,随着素质教育改革,英语口语考试被逐步纳入中高考,学生们提升口语水平的需求也日益凸显。然而,口语学习需要大量的练习、及时的反馈和针对性的指导,但课上、课后都很难有一对一的教学机会;老师通常需要花费数倍于批改书面试卷的时间,才能完整地听完学生的语音并给出全面的反馈。采用计算机辅助语言学习技术,通过检测英语学习者的发音是否正确、错误的具体原因,可以及时、高效、便捷地提供针对性的发音指导,且不受传统面授的时空限制。
行业现状
现有的语音评测应用主要是对学习者的发音进行打分,但是很少反馈失分的具体原因并进行针对性地指导,对学习者改善发音助力有限。近年来,音素级发音检错技术在研究领域获得了越来越多的关注,可以检测学习者发音中多读、漏读和错读的音素,还可以通过根据发音错误诊断推送相应的文字及视频发音教程,给学习者提供针对性的专家级发音指导意见。依托作业帮专业的英语教师团队、丰富的口语练习题库、庞大的下沉市场用户规模、海量的中国学生口语练习数据,英语发音检错技术可以在课上、课后为所有英语学习者提供个性化、精准化的辅导,实现科技助力因材施教、教育普惠、“让优质教育触手可及”。
传统的语音评测主要通过强制对齐(Forced Alignment)获得朗读文本中各个音素在音频中的起止时间,然后在各个音素片段内计算目标发音音素与其它音素的概率比值,即 GOP(Goodness of pronunciation)分数,最后通过设定阈值等方式判断各个音素的发音是否正确,或者综合各音素的 GOP 分数回归得到单词、句子的评分。
这类方案主要存在以下几点问题:
发音错误时强制对齐得到的时间边界可能与实际发音音素序列的时间边界不一致,导致计算的实际发音的概率值偏低,无法提供准确的检错与诊断;若在对齐网络中扩展常见的发音错误,需要专家知识并且很难覆盖实际应用中的各种可能;
强制对齐方案无法准确地处理增读、漏读音素的情况,尤其是增读;
GOP 计算对时间边界比较敏感,但是很难获得含准确的时间边界标注的大批量语料库;
传统的帧级识别模型,不论是 GMM-HMM 还是神经网络模型,训练流程都较为繁琐。近年来,端到端模型也被广泛应用于语音识别领域,并达到了和传统方法可比的性能,大大简化了模型的训练流程。在发音检错场景下,采用端到端音素识别可以直接识别学习者的实际发音音素序列,然后,通过最短编辑距离与目标发音音素序列进行匹配、对比,得到正确朗读、增读、漏读、错读音素的检错与诊断结果。相对于传统的强制对齐方案,该方案不需要精确的时间边界,并且能够很方便地检测增读、漏读音素的情况。
作业帮的实践
为了便于后续讨论,首先介绍我们采用的数据集和评价指标。评价发音检错与诊断任务最常用的数据集是 L2-ARCTIC[1]。L2-ARCTIC 是由第一语言分别为印地语、韩语、普通话、西班牙语、阿拉伯语和越南语的非英语母语人士录制的英语句子朗读数据,包含音频、提示文本和标注,标注了音频中增读、漏读和错读的音素。发音检错与诊断任务的评价指标主要有:
虚警率:实际发音正确的音素中,被检测为发音错误的比例;
召回率:实际发音错误的音素中,被检测为发音错误的比例;
诊断正确率:正确地判断为发音错误的音素中,识别为实际发音音素的比例。下面介绍端到端发音检错技术在作业帮落地实践过程中遇到的问题与解决方案。
端到端模型选型
目前主流的端到端语音识别技术有 CTC(Connectionist Temporal Classification)、基于 attention 的 encoder-decoder(AED)、RNN-T(Recurrent Neural Network Transducer)三类[2]。其中,CTC 基于条件独立性假设,即假设序列中的每个元素是互相独立的,而 AED 和 RNN-T 模型均采用自回归解码,即每一时刻的输出都依赖于之前的输出,隐式地学习了序列中的语言模型。虽然在语音识别任务上,相对于 CTC,AED 和 RNN-T 模型都有更好的效果,但是考虑到在发音检错任务中,学习者发音错误后的音素序列模式可能与常见的音素组合不一致,为了避免语言模型对发音错误召回的影响,我们首先验证了 CTC 模型的效果。
基于 attention 的文本信息融合
实验结果表明,仅采用 CTC 音素识别准确率较低,发音检错虚警率约为 21%,这在教学场景下是不可接受的。借鉴人进行发音评价的过程,在无文本参考的情况下转写实际发音音素序列较为困难,但是已知目标发音,判断实际发音与目标发音是否相近,这一任务就相对简单许多。同样的,将目标发音序列也作为模型输入,为模型提供额外的先验知识,可以降低模型学习的难度。
参考论文[3]中的实现,模型结构如下图所示:
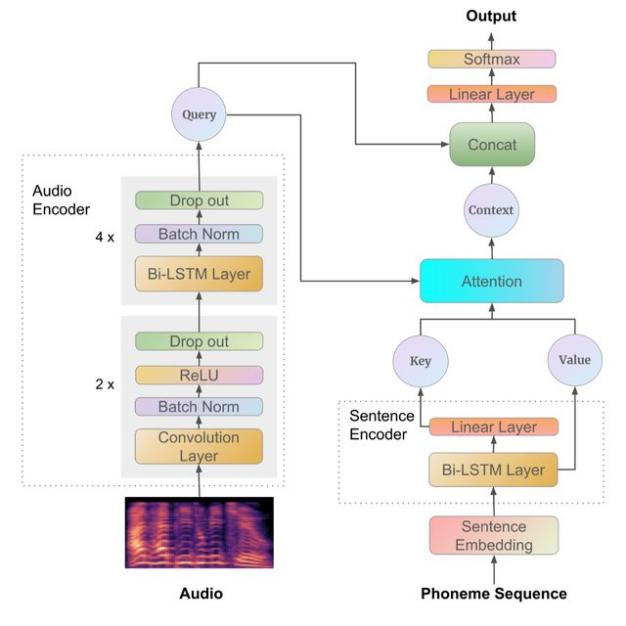
发音错误数据增强
由于标注真实发音错误的音频需要专业人士耗费大量的时间精细地标注,较难大批量获取,因而模型训练集中绝大部分为发音正确的数据。为了增强模型的检错能力,避免原样输出参考音素序列,采用随机替换输入音素序列中的音素来模拟发音错误的情况。
优化后,虚警率由原来的 21%显著降低至 9%左右,同时,诊断正确率也由原来的 65%提升至 77%。但是,发音错误召回率仅有 57%。
确定功能边界
分析发现,高频虚警、高频未召回的音素对主要为发音相近的音素,如将元音/ɪ/误识别为/iː/。相较于明显的发音错误,这类细微的纠音在实际教学活动中优先级较低。为了进一步降低虚警率,鼓励学习者大胆开口说英语,通过与有多年教学经验的教研们沟通,我们约定了对/ʌ/和/ɑː/、/s/和/θ/、词尾的/s/和/z/等发音相近的音素对纠音优先级相对较低。这样,虚警率进一步降低至 7%,不考虑此类发音错误,召回率也提升至 67%。
最终实现的发音检错功能如下图所示:

总结与展望
我们通过将端到端音素识别用于发音检错,避免了传统的强制对齐方案训练流程复杂、时间边界不准、无法处理音素增读漏读的问题。并通过基于 attention 的文本信息融合、发音错误数据增强,取得了显著的检错效果提升。最后,结合实际教学需求,降低发音相近音素的纠音的优先级,进一步优化了实际应用场景下的效果体验。未来可能的优化方向包括:
标注实际应用场景下的真实发音数据;
通过 multi-task 知识迁移的方式,引入发音属性识别等信息,提升模型的音素区分能力;
基于音频和视频的多模态特征融合方案,可以在很大程度上尤其是在噪声环境下提升检错准确率。参考文献
[1] Zhao G, Sonsaat S, Silpachai A, et al. L2-ARCTIC: A non-native English speech corpus[C]//INTERSPEECH. 2018: 2783-2787.
[2] Prabhavalkar R, Rao K, Sainath T N, et al. A Comparison of Sequence-to-Sequence Models for Speech Recognition[C]//Interspeech. 2017: 939-943.
[3] Fu K, Lin J, Ke D, et al. A Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques[J]. arXiv preprint arXiv:2104.08428, 2021.




