
本文作者介绍了数据科学家在编写代码时常犯的几个错误,并给出了自己对问题的看法以及相应的解决方案。希望文中的观点能给读者带来一些启发。
编写应用于数据科学项目的 Python 代码,并按照自己的期望运行起来,可能没有什么困难。但是,如果你想让自己的代码对其他人(包括未来的自己)有高可读性,并且可重现及运行时维持高效率,可能就没那么容易了。我们可以通过减少开发中常见的不良做法来解决这个问题。
在我从事数据科学的职业生涯中,我逐渐意识到,通过应用软件工程的最佳实践,可以交付质量更高的项目。高质量的项目意味着极少的错误、可复现准确结果以及高效的代码执行效率。本文不会事无巨细地向你介绍这些最佳实践。相反,我总结了几点开发中最常见到的问题(也是我自己之前经常犯的错误),并有针对性地给出相应的解决方法及其相关学习资料。
1. 没有配置独立的开发环境
从某一方面来看,这可能不是编码问题,但我仍然坚持认为独立的运行环境是代码健康运行的保证。我认为要给每个项目配置独立的专用环境,这样才能保证代码的可重现性。项目代码未来可能会运行在你的电脑上,或者是你同事的电脑上,甚至有可能部署到生产环境中。
如果你不清楚什么是依赖管理,那么最好先了解和学习下 Anaconda Virtual Environment 以及 Pipenv。我个人最常使用 Anaconda,你可以点击链接学习下入门教程。如果你想进阶或者进行工程化实践,那么可以考虑使用 Docker。
2. 过度使用 Jupyter Notebooks
Notebooks 非常适合用于教学以及初期项目研究,使用它可以快速完成一些小的棘手项目。尽管如此,它仍然不能算是一个好的 IDE。工欲善其事必先利其器,好的 IDE 是数据科学家真正的武器,优秀的工具可以极大地提高你的工作效率。有很多大神指出过 Notebooks 的一些缺点,Joel Grus 曾经发表过一次演讲,内容非常搞笑幽默,这里推荐给大家。
Notebooks 非常适合项目前期的试验研究,而且可以非常方便地向他人展示研究成果,这一点非常不错。然而,当涉及到进行长周期、协作及可部署的项目时,它非常容易出错。这个时候,你最好使用一个专业的 IDE,比如 VScode、Pycharm、Spyder 等。在项目周期不超过一天的情况下,我也会时不时地使用一下 Notebooks,这可能是我想到的唯一使用它的场景了。
3. 项目代码结构混乱
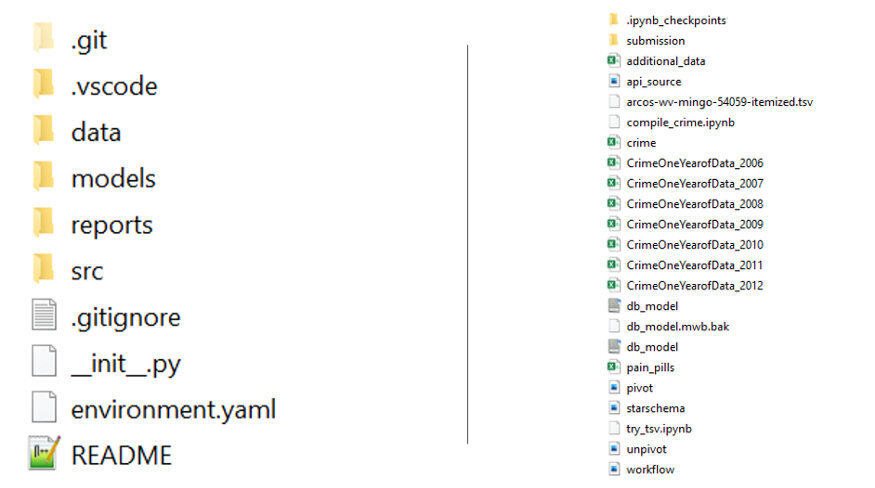
我见过不少人将项目的所有代码以及相关文件存储在一个目录里,这是一个十分不专业的做法。
如下图所示,想象一下你要接手一个项目,你更喜欢哪种项目代码结构。图片中右面的项目代码结构绝对会让你和其他接盘侠疯掉的,因为这会让你花费数倍的时间来研究项目代码。毋庸置疑,左边的代码结构要比右边合理许多。所以,我们应该怎么构建项目结构呢?这里推荐给大家一个工具—— Cookiecutter,这是一个十分优秀的开源项目,它促进了数据科学项目代码结构的标准化,你可以从中学习一下。
4. 项目代码使用绝对路径而不是相对路径
你有在个人开源的项目中有看到过“请修复你的文件路径”的评论吗?这样的评论往往暗示了糟糕的代码设计。修复该问题一般包括两个步骤:
与他人共享项目结构(参考本文第三条建议)
将你的 IDE 根目录/工作目录设置为项目根目录,该目录通常是项目中最外层目录。
第二点有时候不是那么简单,但是值得你花时间这么去做,这样别人就可以在不用修改代码的情况下成功运行你的代码。下面给出一个例子供大家参考。
import pandas as pdimport numpy as npimport os#### BAD WAY ##### please change it to your file pathexcel_path1 = "C:\\Users\\gerold\\Desktop\\CEU\trim1\\DataEng1\\Team_asgn\\CrimeOneYearofData_2006.xlsx"excel_path2 = "C:\\Users\\gerold\\Desktop\\CEU\trim1\\DataEng1\\Team_asgn\\CrimeOneYearofData_2007.xlsx"# read in excelmydf = pd.read_excel(excel_path1)myd2 = pd.read_excel(excel_path2)#### END BAD WAY ######## GOOD WAY ##### first put your 2 excels into the data folder# set the working directory in your IDE to the root (Team_asgn)DATA_DIR = "data" # indicate magical constansts (maybe rather put it on the top of the script)# fix gruesome var namescrime06_filename = "CrimeOneYearofData_2006.xlsx"crime07_filename = "CrimeOneYearofData_2007.xlsx"# fix gruesome var namescrime06_df = pd.read_excel(os.path.join(DATA_DIR, crime06_filename))crime07_df = pd.read_excel(os.path.join(DATA_DIR, crime07_filename))#### END GOOD WAY ####5. 使用“幻数”
幻数是在代码中没有任何上下文的数字。代码中频繁大量地使用幻数,可能会遇到难以追踪的问题。
下面的代码示例中,我们在乘法计算时简单地使用了一个未分配变量的数字,而且没有任何上下文来解释这个数字的含义。如果你以后不得不对其进行修改,就会面临十分尴尬的局面,因为你不知道该数字的具体含义。因此,对于此类常量,按照惯例在 Python 中使用大写命名。当然你也可以坚持不使用大写,但是将“常量”与“常规变量”区分开来,是一个不错的编程习惯。
# assign revenues in $ to marketing campaignscamp1_revenue = 50000camp2_revenue = 100000#### BAD WAY ##### calc whic performed bettercamps_revenue_diff = (camp2_revenue * 0.65) - camp1_revenue#### END BAD WAY ######## GOOD WAY ####CAMP2_NORMALIZER = 0.65 # we need to normalize because the campaign ran in peak season# calc whic performed bettercamps_revenue_diff = (camp2_revenue * CAMP2_NORMALIZER) - camp1_revenue#### END GOOD WAY ####6. 不处理告警信息
估计很多人都有这样的习惯:对代码运行过程中产生的告警信息置之不理。我们对代码能够正常运行并能够输出期望的结果已经非常满意了,所以为什么要处理告警信息呢?确实,告警信息不是错误,但是这些告警信息可能会引起潜在的问题或者错误。尽管代码能运行成功,但出现这些告警信息实际上并不符合我们的预期。
在做数据分析时,我遇到的最常见的告警信息是 Pandas 的 SettingwithCopyWarning 和 DeprecationWarning。DataSchool 的教学视频以简洁的方式解释了如何触发 SettingwithCopyWarning。DeprecationWarning 告警说明 Pandas 已弃用某些方法,未来你的项目代码在使用更高版本时会有中断的风险。当然,还有一些其他的告警类型。依照我的经验,产生这些告警大部分是因为使用了工具类非原本设计的调用方式。所以,了解函数的源代码总是有帮助的,这样就可以避免大多数的异常告警了。
7. 不使用类型注解
这也是我最近学到的一种做法,因为我已经体会到了使用类型注解带来的好处。类型注解(或类型提示)简单来讲就是为变量指定数据类型。基本上,使用 IDE 自带的代码扩展提示就可以完成代码变量的注解。使用代码注解,可以让你的代码更易于自己和他人阅读。
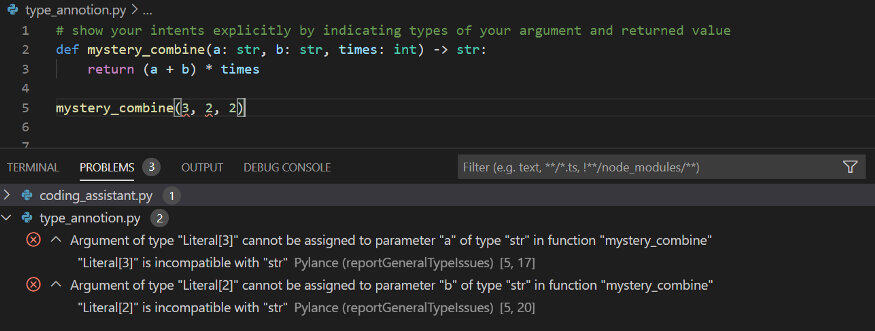
为了证明这一点,我摘取了 Daniel Starner 在dev.to博客中的代码片段来举个例子。如下代码所示,在没有类型提示的情况下,mystery_combine() 使用整数或字符串作为输入并相应地返回整数或字符串作为结果。对于开发人员来讲,该方法的描述有点模棱两可。如果使用了类型注解,就可以清晰的表达函数意图,避免产生误解,同时会给其他开发人员以及未来的自己带来一些便利。
# code taken from https://dev.to/dstarner/using-pythons-type-annotations-4cfe# Our original functiondef mystery_combine(a, b, times):return (a + b) * timesprint(mystery_combine(2, 3, 4))# 20print(mystery_combine('Hello ', 'World! ', 4))# Hello World! Hello World! Hello World! Hello World!# show your intents explicitly by indicating types of your argument and returned valuedef mystery_combine(a: str, b: str, times: int) -> str:return (a + b) * times此外,使用类型注解可以在无需运行代码的情况下,静态地检查代码是否存在错误。下图的示例展示了没有按函数类型注解指定对应参数,静态检查给出了相应的错误提示。静态检查是在运行项目之前进行代码预检查的一种十分有用的方法。
8. 不习惯使用列表推导表达式
列表推导表达式是 Python 非常强大的特性之一。使用列表推导表达式,可以让 for 循环更加易于阅读,更符合 Python 的习惯表达,而且执行效率会更高。
下面的一段示例代码尝试读取目录中的 CSV 文件。在这种情况下你可能会说,不使用列表推导式也挺优雅呀,没有什么不妥。但是,如果目录里有其他格式的文件,比如 JSON 文件,此时,使用列表表达式的便捷性和可读性会提升一个档次,而且,代码也更容易维护。
import pandas as pdimport osDATA_PATH = "data"filename_list = os.listdir(DATA_PATH)#### BAD WAY ##### read in bunch of csv-s from a dircsv_list = []for fileaname in filename_list:csv_list.append(pd.read_csv(os.path.join(DATA_PATH, filename)))#### END BAD WAY ######## GOOD WAY ####csv_list = [pd.read_csv(os.path.join(DATA_PATH, filename)) for filename in filename_list]# what about if not only .csv-s are present? easy to tackle this with list comprehensionscsv_list = [pd.read_csv(os.path.join(DATA_PATH, filename)) for filename in filename_list if filename.endswith(".csv")]#### END GOOD WAY ####9. pandas 代码可读性差
方法链调用是 Pandas 中的一个很棒的特性,但是如果你坚持在一行中表达所有内容,代码的可读性会变差。有一个技巧可以让你对表达式进行分解。如下的代码所示,可以将整个表达式放入括号中,然后表达式的每个组成部分可以单独使用一行,这样处理后的代码看起来就清爽多了。
# lets aggregate click and time spent to its mean in a Qvar_list = ["clicks", "time_spent"]var_list_Q = [varname + "_Q" for varname in var_list]#### BAD WAY ####df_Q = df.groupby("id").rolling(window=3, min_periods=1, on="yearmonth")[var_list].mean().reset_index().rename(columns=dict(zip(var_list, var_list_Q)))#### BAD WAY ######## GOOD WAY ####df_Q = ( df .groupby("id") .rolling(window=3, min_periods=1, on="yearmonth")[var_list] .mean() .reset_index() .rename(columns=dict(zip(var_list, var_list_Q))))#### END GOOD WAY ####10. 排斥使用 Python 自带的 date 工具
在 Python 中使用日期模块确实不是特别友好,因为它的语法比较奇怪,而且让人难以理解并记忆。我经常看到很多人像处理数字一样处理日期对象,这种做法实在不够优雅。虽然很多时候这么做能够跑通代码,但是这样非常容易出错,而且维护起来非常困难。
以下面的实例代码为例,它的功能是实现以 %Y%m 格式列出两个日期之间的所有月份。如果你借助 datetime 工具实现,代码可读性和可维护性得到了提高。实话讲,即使是现在,我在处理日期问题时仍然依赖谷歌搜索,这很正常,习惯就好了。
import datetimefrom dateutil.relativedelta import relativedelta# task: get months between two dates in YM format#### BAD WAY ####start_num = 201910end_num = 202012res_list = []iter_num = start_numwhile iter_num < end_num:if abs(iter_num) % 100 > 12: iter_num += 88 res_list.append(iter_num) iter_num += 1else: res_list.append(iter_num) iter_num += 1res_list.append(iter_num)#### END BAD WAY ######## GOOD WAY ##### initialize datetimesstart_datetime = datetime.datetime(2019, 10, 1)end_datetime = datetime.datetime(2020, 12, 1)# find months between end and astart dater = relativedelta(end_datetime, start_datetime)months_between = r.months + (12*r.years)myres = [ start_datetime + relativedelta(months=_)for _ in range(1, months_between + 1)]# format datesmyres = [element.strftime("%Y%m") for element in myres]#### END GOOD WAY ####11. 变量命名不规范
在循环中给变量使用 i,j,k,df 等非描述性字符进行命名,会使代码的可读性降低,尤其是循环中的逻辑处理较为复杂的时候。代码中变量命名短小精悍,往往容易混淆项目开发人员,这一点相信大家深有体会。不要担心使用较长的变量名,也不要吝啬使用下划线“_”对变量进行命名。推荐给大家一篇有关变量命名的高质量博客,一定会对你有所启发。
12. 不对代码进行模块化重构
模块化意味着将冗长且复杂的代码分解成简单的模块,以执行细粒度的、特定的任务。不要只为项目创建一个冗长的执行脚本。在代码入口文件开头定义大量的类或函数是不推荐的做法,因为这样做代码很难阅读和维护。相反,要根据代码功能创建相应的模块(包)。这方面的详细内容,可以参考这篇博客 Python Modules and Packages 。
13. 没有遵循 PEP 约定
当我刚开始使用 Python 编写项目代码的时候,写出的代码十分丑陋,难以阅读。并且自己还努力地制定属于自己的设计原则,好让自己的代码看起来没有那么糟糕。想出这些原则花费了我不少时间,但是我并没有一直坚持这些原则,回想起来,受限于自己在 Python 的经验,很多自己设计原则没有那么合理。最终,我发现了PEP设计原则,它是 Python 的官方约定指南。我很喜欢 PEP 提出的约定,因为它可以标准化我的代码,从而使协作编程更加方便。顺便说一下,有些特殊情况下我确实没有按照 PEP 规则来做,但在绝大多数情况下,我会按照 PEP 规范来写代码。
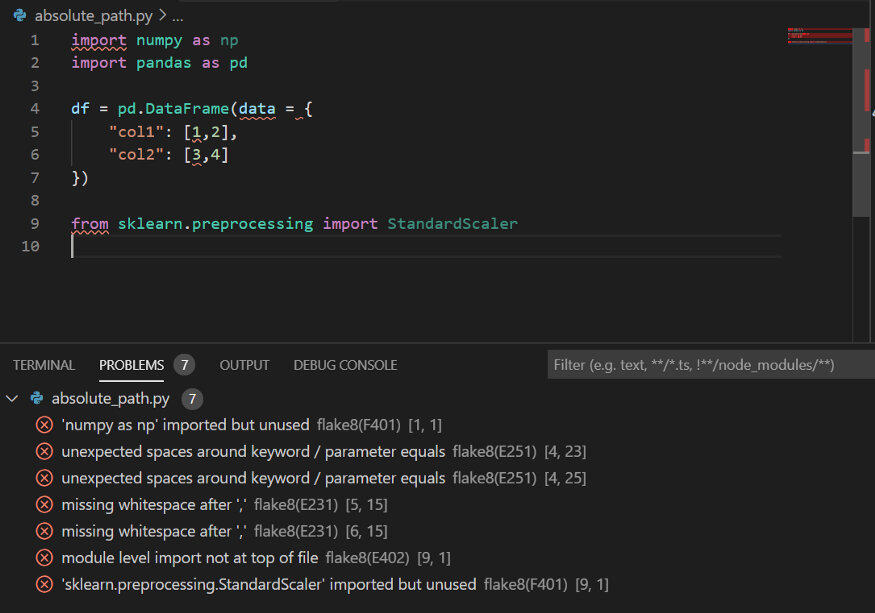
几乎所有的 IDE 都支持 linter 扩展,下图展示了 linter 的工作原理,它可以指出代码中存在的问题。如果你仍然感觉不够直观,你可以查看具体的 PEP 索引提示,如括号中提示所示。如果你想查看有哪些可用的 linter,可以参考realpythong.org 网站上的学习资源。
14. 从不使用编码助手
如果你想大幅提高写代码的效率,那么就开始使用编码助手吧。该工具可以巧妙地帮助你自动完成代码、添加描述文档以及给你的代码提供修改建议。我最喜欢使用的编码提示工具是由微软开发的 pylance,它支持在 VScode 中使用。Kite 是另一个比较流行的编码助手,同样非常好用,许多编辑器都支持使用。
代码提示工具的使用效果视频可以点击此处进行查看。
15. 缺少信息安全意识
将重要信息(密码、密钥)推送到公共 GitHub 仓库是一个普遍存在的安全问题。如果你想了解这个问题的严重性,请查看 qz 上的这篇文章。互联网上有专门的爬虫机器人等待着你犯这样的错误。从我的经历来看,安全这一课题几乎从来没有在数据科学的相关课程中提到过。所以,你需要自己来填充这方面知识的空白。我建议首先去了解一下操作系统的环境变量相关知识,dev.to的这篇文章就是一个很好的开始,强烈推荐大家阅读学习。
作者介绍
Gerold Csendes,现就职于 EPAM,数据科学家,机器学习工程师。
原文链接
15 common mistakes data scientists make in Python (and how to fix them)




