
作者 | 勇幸,小米计算平台负责人
导读:
业界一直希望统一元数据,从而实现多产品间的一致体验:无论是数据开发、数据消费还是数据治理,所有用户都能基于一套元数据体系,采用相同的资源描述方式,这无疑能极大地提升用户体验。
然而真正做到 “多云多数据源多引擎” 下的元数据统一,是非常难的,首先面临的是组织障碍,很多大厂也并未真正实现 “资源坐标统一、权限统一、资产一体化”,这些问题本身就很有挑战。得益于开源与组织时机,小米基于 HMS 与 Metacat 实现了元数据的统一,也借此实现了将 7 个数据平台统一为 1 个平台。
随着湖仓与 AI 的发展,统一元数据面临新的挑战,尤其是 Data AI 资产一体化,Metacat 很难满足需要,小米希望借助 Gravitino 替代 HMS 与 Metacat,真正实现元数据的多场景统一,从而获得元数据在湖仓与 AI 方面的持续迭代。
背景和概要介绍
小米公司是一家以智能手机、智能硬件和电动汽车为核心的消费电子和智能制造公司,通过物联网平台相互连接。截至 2023 年,根据 Canalys 的数据,小米在全球智能手机市场中排名前三,并连续第五年被列为《财富》全球 500 强企业。
小米云计算平台团队致力于为小米业务提供可靠和安全的数据计算与处理能力。我们积极参与许多开源项目,涵盖存储、计算、资源调度、消息队列、数据湖等领域。通过深耕这些先进技术,团队取得了重大成就,包括入围小米百万美金技术奖决赛。
Gravitino[1] 是一个高性能、地理分布式的联合元数据湖开源项目,管理不同来源、类型和区域的元数据,支持 Hive,Iceberg,MySQL,Fileset,Messaging 等类型的数据目录(不断增加中),为用户提供 Data 和 AI 资产的统一元数据访问。
本文重点介绍小米使用 Gravitino 的情况,为未来的工作规划与解决方案提供指引。如下所示,有三个关键点,期待与 Gravitino 共同成长并为业务提供更好的数据资产管理能力:
统一元数据的管理
集成 Data 和 AI 资产管理
统一用户权限管理
1. 统一元数据的管理
随着多区域或多云部署的引入,数据孤岛问题变得更加突出。在不同地区或云服务提供商之间维护数据的统一视图变得具有挑战性。这对于小米来说确实如此。Gravitino 为这些挑战提供了解决方案[2],并帮助打破数据孤岛。它旨在解决多云架构下的数据管理、治理和分析问题。
Gravitino 在小米数据平台中的位置
下图中 Gravitino 具有以下我们需要的特性(以绿色和黄色突出显示):
统一的元数据湖:作为一个统一的数据目录,它支持多种数据源、计算引擎和数据平台,用于数据开发、管理和治理。
实时性和一致性:实时获取元数据以确保 SSOT(单一真相来源)。
动态注册:支持在使用中动态添加 / 修改数据目录,无需重新启动服务,这使得维护和升级比以前容易得多。
多引擎支持:不仅支持数据引擎,如 Trino、Apache Spark、Apache Flink(开发中),还支持 AI/ML 框架,如 Tensorflow、PyTorch 和 Ray*。
多存储支持 *:支持 Data 和 AI 特定领域的存储,包括 HDFS/Hive、Iceberg、RDBMS,以及 NAS/CPFS、JuiceFS 等。
生态友好 *:支持使用外部 Apache Ranger 进行权限管理,外部事件总线进行审计和通知,以及外部的 Schema Registry 进行消息目录的管理。
注:* 功能仍在积极开发中
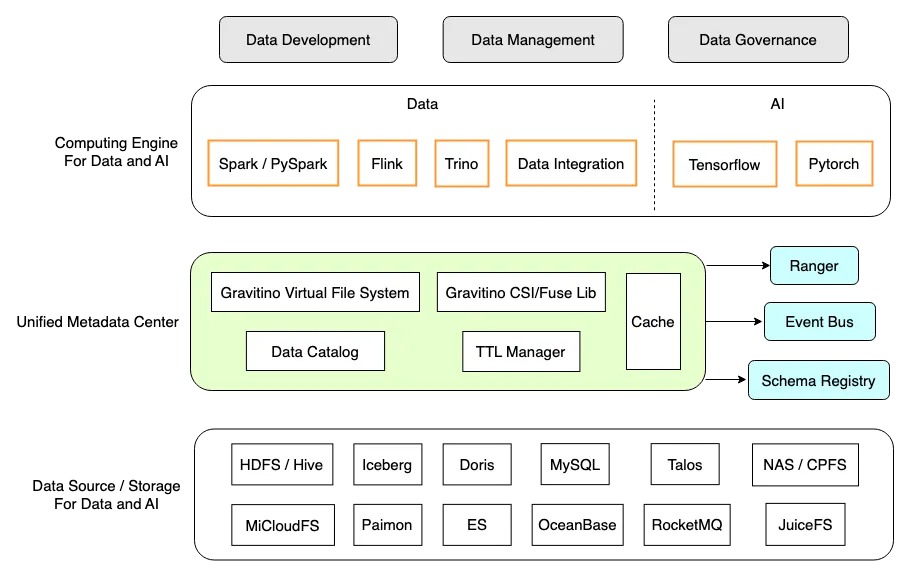
统一元数据湖,统一管理
随着数据源类型的日益丰富,计算引擎如 Trino、Spark 和 Flink 需要为每个引擎维护一个很长的数据源目录列表。这引入了许多重复和复杂的维护工作。
为了在多个数据源和计算引擎之间建立联系,通常期望在一个地方管理所有种类的数据目录,然后使用统一的服务来公开这些元数据。在这种情况下,Gravitino 非常有用,因为它提供了一个统一的元数据湖,标准化了数据目录操作,并统一了所有元数据管理和治理。
用户场景
用户可以使用三级坐标:catalog.schema.entity 来描述所有数据,并用于数据集成、联合查询等。令人兴奋的是,引擎不再需要维护复杂和繁琐的数据目录,这将 O(M*N) 的复杂度简化为 O(M+N)。
注:M 代表引擎的数量,N 代表数据源的数量。
此外,我们可以使用一种简单统一的语言来进行数据集成和联合查询:
Apache Spark: 使用 Gravitino Spark 连接器从 Apache Hive 写入 Apache Doris
INSERT INTO doris_cluster_a.doris_db.doris_table
SELECT
goods_id,
goods_name,
price
FROM
hive_cluster_a.hive_db.hive_table
Trino: 使用 Gravitino Trino 连接器在 Hive 和 Apache Iceberg 之间进行查询。
SELECT
*
FROM
hive_cluster_b.hive_db.hive_table a
JOIN
iceberg_cluster_b.iceberg_db.iceberg_table b
ON a.name = b.name
2. 集成 Data 和 AI 资产管理
在大数据领域,我们通过数据血缘、访问度量和生命周期管理,对表格(或者结构化)数据的管理有了长足的发展。然而,在 AI 领域,非表格数据一直是数据管理和治理最具挑战性的方面,包括 HDFS 文件、NAS 文件和其它格式。
AI 资产管理的挑战
在机器学习领域,读写文件的过程非常灵活。用户可以使用各种格式,如 Thrift-Sequence、Thrift-Parquet、Parquet、TFRecord、JSON、文本等。此外,他们还可以利用多种编程语言,包括 Scala、SQL、Python 等。为了管理我们的 AI 资产,我们需要考虑到这些多样化的使用,并确保适应性和兼容性。
与表格数据管理类似,非表格数据也需要适应各种引擎和存储,包括像 PyTorch 和 TensorFlow 这样的框架,以及各种存储接口,如文件集的 FileSystem、实例磁盘的 FUSE、容器存储的 CSI 等。
非表格数据管理架构
我们的目标是通过利用 Gravitino 建立 AI 资产管理能力,其核心技术在下图中概述。
非表格数据目录管理:实现 AI 资产的审计,并确保文件路径规范的保证;
文件接口支持:确保与各种文件接口的无缝兼容性;
Hadoop 文件系统:通过 GVFS(Gravitino 虚拟文件系统)实现与 Hadoop 文件系统的兼容性。
CSI 驱动程序:支持容器存储内文件的读写。
FUSE 驱动程序:使物理机器磁盘上的文件读写成为可能。
AI 资产生命周期管理:为非表格数据实现 TTL(Time-to-Live,生存时间)管理。
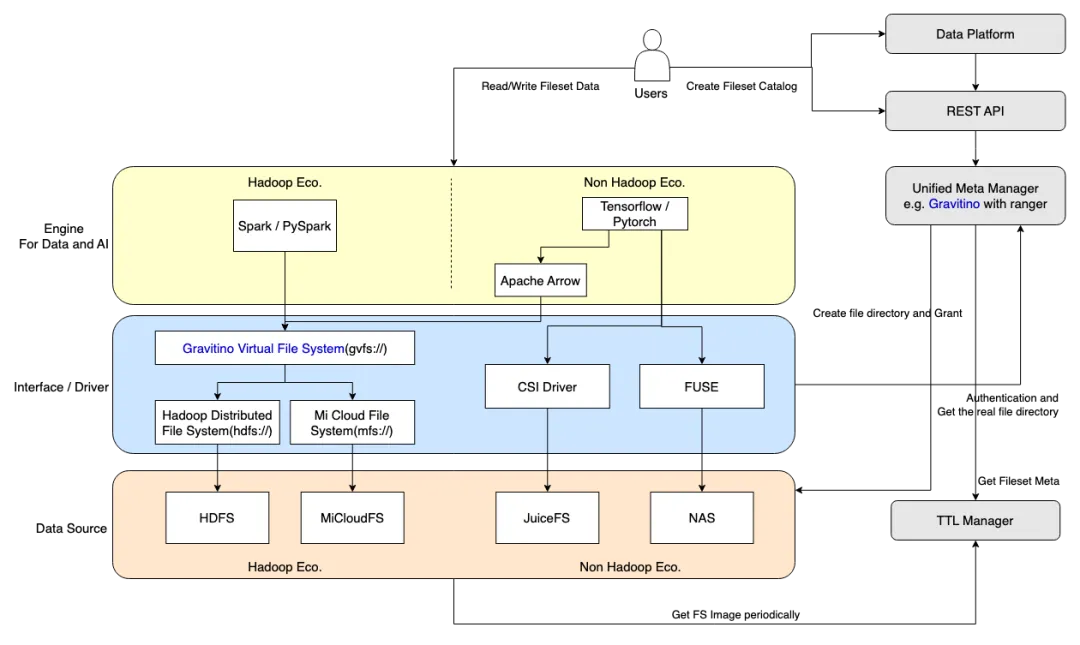
用户场景
我们希望用户从原始方式到新方法的迁移过程将是直接和无缝的。实际上,过渡只涉及两个步骤:
在 Gravitino 基础数据平台上创建文件集 Catalog 并配置 TTL;
用新方式(gvfs:// 路径)替换原始文件路径。
以 Spark 读取 HDFS 文件为例:
// 1.Structured data - Parquet
val inputPath = "hdfs://cluster_a/database/table/date=20240309"
val df = spark.read.parquet(inputPath).select()...
val outputPath = "hdfs://cluster_a/database/table/date=20240309/hour=00"
df.write().format("parquet").mode(SaveMode.Overwrite).save(outputPath)
// 2.Semi-structured data - Json
inputPath = "hdfs://cluster_a/database/table/date=20240309_${date-7}/xxx.json"
val fileRDD = sc.read.json(inputPath)
// 3.Unstructured data - Text
val inputPath = "hdfs://cluster_a/database/table/date=20240309_12"
val fileRDD = sc.read.text(inputPath)
通过利用 Gravitino,我们创建了一个指向原始 HDFS 的文件集“myfileset”,然后我们可以将原始的 hdfs://xxx 替换为新的 gvfs://fileset/xxx 方法,为用户提供一种无缝直观的升级方式。用户将不再需要关心实际的存储位置。
// 1.Structured data - Parquet
val inputPath = "gvfs://fileset/myfileset/database/table/date=20240309"
val df = spark.read.parquet(inputPath).select()...
val outputPath = "gvfs://fileset/myfileset/database/table/date=20240309/hour=00"
df.write().format("parquet").mode(SaveMode.Overwrite).save(outputPath)
// 2.Semi-structured data - Json
inputPath = "gvfs://fileset/myfileset/database/table/date=20240309_${date-7}/xxx.json"
val fileRDD = sc.read.json(inputPath)
// 3.Unstructured data - Text
val inputPath = "gvfs://fileset/myfileset/database/table/date=20240309_12")
val fileRDD = sc.read.text(inputPath)
如前所述,文件读写表现出很大的灵活性,它也适应了多样化的引擎。这里就不举更多例子了,总体原则仍然是用户应该能够以最小的修改来管理和治理非表格数据。
AI 资产管理内的许多挑战需要探索和开发工作。它包括指定文件路径的深度和日期,支持数据共享,探索基于数据湖如 Iceberg 的非表格数据读写解决方案。这些将是我们近期的关注重点。
3. 统一用户权限管理
元数据和用户权限信息如此紧密相关,将它们放在一起管理是再好不过的。元数据服务还需要整合与用户权限相关能力,以验证资源操作。我们期望通过利用 Gravitino 在我们的数据平台上实现这一点。
多系统集成的统一认证挑战
为了为用户提供无缝的数据开发体验,数据平台通常需要与各种存储和计算系统集成。然而,这种集成经常导致管理多个系统和账户的挑战。
用户需要在不同系统中使用不同账户进行身份验证,如 HDFS(Kerberos)、Doris(用户名 / 密码)和 Talos(AK/SK - 小米 IAM 账户)。这种分散的身份验证和授权流程显著减慢甚至可能阻碍开发。
为了解决这个问题,简化不同账户系统的复杂性并建立统一的授权框架是构建一站式数据开发平台的关键一步,以提高数据开发的效率。
基于工作空间的统一用户权限
小米的数据平台围绕工作空间概念设计,并采用 RBAC(基于角色的访问控制)权限模型。Gravitino 允许我们在工作空间内生成所谓的“小账号”(实际资源账户,如 HDFS-Kerberos),有效地将用户与 Kerberos、用户名 / 密码和 IAM/AKSK 账户的复杂性隔离开来。以下是这种设置的关键组件:
工作空间: 工作空间是数据平台内最小的操作单元,包含所有相关资源。
角色:工作空间内的身份,如管理员、开发人员和访客。每个角色被授予访问工作空间资源的不同权限。
资源:工作空间内的资源,如 catalog.database.table,得益于统一元数据,资源可以抽象为三级坐标。
权限:权限决定了用户在工作空间内操作资源的控制水平,包括管理员、写入和读取。
Token:用于识别工作空间内个体的唯一 ID。
身份验证:API 操作使用令牌进行身份验证,而 IAM 身份在登录后通过 UI 操作传递。
授权:通过 Apache Ranger 管理,授予已认证的工作空间角色必要的权限。
小账号:每个工作空间都有一套专用的代理账户来访问资源,如 HDFS(Kerberos)或 Apache Doris(用户名 / 密码)。当引擎访问底层资源时,它无缝地使用相应的小账号身份验证进行每个资源的操作。然而,整个过程对用户来说是透明的,用户只需要关注管理工作空间权限(通过利用 Gravitino 等同于资源权限)。
用户场景
下图展示了用户在我们的数据平台上创建和访问资源的简要过程:
所有用户只知道工作空间身份和工作空间权限。
在创建工作空间时,会自动创建一套工作空间代理小账号。每当在工作空间内创建或导入资源时,相应的代理小账号将被授权必要的资源权限。
当用户尝试读取或写入资源时,系统会验证他们的工作空间权限。如果工作空间权限检查成功,引擎将使用小账号对资源执行所需的读取或写入操作。
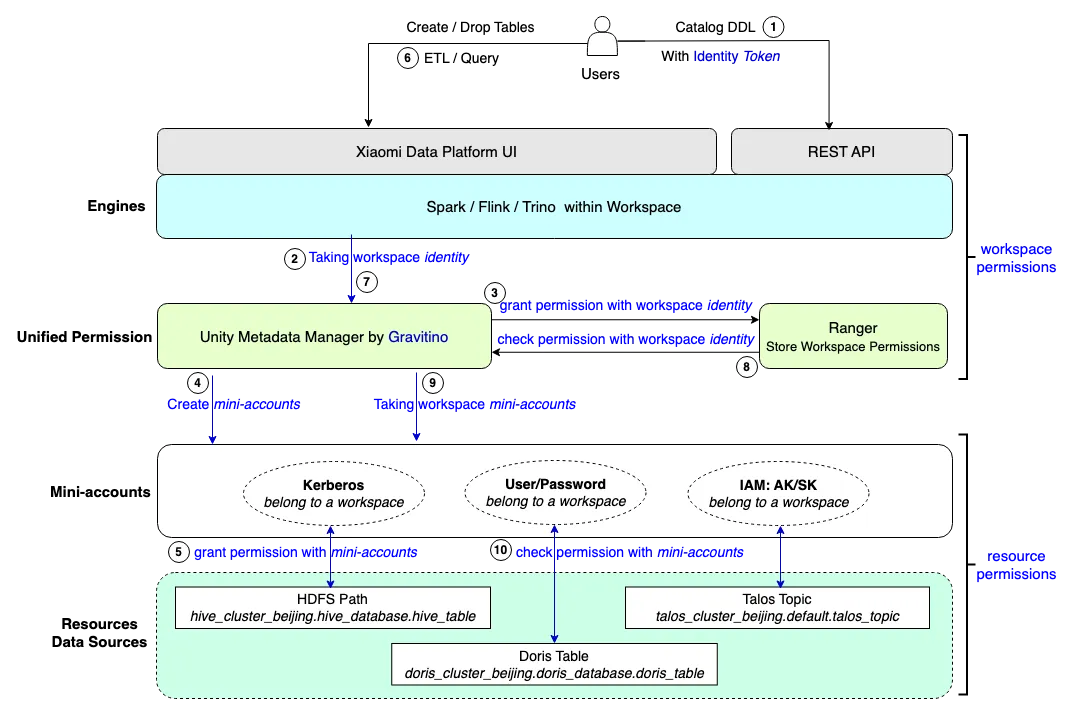
总结
在这篇博客中,我们展示了小米正在使用 Gravitino 完成的三个重要场景——大部分关键工作已经完成,剩余的正在进行中并取得了良好进展。我们对所有上述场景在小米的成功落地充满信心,以更好地支持业务进行数据资产管理,同时我们很高兴成为 Gravitino 社区的一部分,共同创造统一元数据湖的潜在事实标准。
参考链接:
[1] https://github.com/datastrato/gravitino/
[2] https://datastrato.ai/blog/gravitino-unified-metadata-lake/




