
机器学习工作流可能涉及相互依赖的许多步骤 —— 从数据准备和分析、训练、评估到部署等。很难以一种特别的方式对这些流程进行组合和跟踪—— 例如,以一套 notebook 或者脚本 —— 而审核和可重复性之类的问题会变得越来越严重。
今年早些时候推出的 Cloud AI Platform Pipelines 有助于解决这些问题:AI Platform Pipelines 提供了一种部署健壮、可重复机器学习流水线以及监控、审核、版本跟踪和可重复性的方法,并且为您的 ML 工作流提供了一个企业就绪、易安装的安全执行环境.
尽管通过 Pipelines DashboardUI 可以简便地上传、运行和监控流水线,但有时您可能要以编程方式访问 Pipelines 框架。这样可以让您从 notebook 构建和运行流水线,并以编程方式管理您的流水线、试验和运行。首先,您需要对您的 Pipelines 安装端点进行身份验证。如何做到这一点取决于您的代码运行所基于的环境。所以,这是我们现在要关注的焦点。
事件驱动的 Pipeline 调用
我们将要介绍的一类有趣的用例是通过 Cloud Functions 之类的服务使用 SDK 来设置事件驱动的 Pipeline 调用。这些用例允许您基于添加到 GCS 存储桶的新数据、添加到 PubSub 主题的新信息或者其他事件来开始部署。
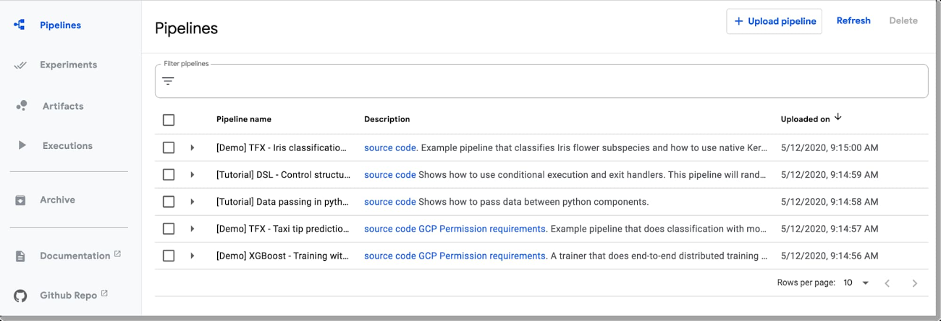
通过 Pipelines Dashboard UI 可以简便地上传和运行流水线,但您也经常需要进行远程访问。
通过 AI Platform Pipelines,您可以使用 Kubeflow Pipelines (KFP) SDK 或者通过采用 TFX SDK 自定义 TensorFlow Extended(TFX)Pipeline 模板,来指定流水线。要使用 SDK 从 Pipelines 集群外部进行连接,必须在远程环境中设置您的凭据,使您有权访问 AI Platform Pipelines 安装端点。多数情况下,为您的账户安装和初始化 gcloud 很简单(或者就像 AI Platform Notebooks 一样,已经为您设置好了),连接是透明的。
而如果您是运行在 Google Cloud 之上,在一种不能简单地进行 gcloud 初始化的场景下,您可以通过底层 VM 的元数据获得并使用访问令牌来进行身份验证。如果运行时环境正在使用与 Pipelines 安装所使用的不同的服务账户,您还需要为该服务账户提供访问 Pipelines 端点的权限。例如,这种情况就是这样,采用 Cloud Functions,其实例使用项目的 App Engine 服务账户。
最后,如果您未在 Google Cloud 中运行并且未安装 gcloud,可使用服务账户凭据文件来生成访问令牌。
接下来,我们将介绍这些选项,并且提供一个示例来说明如何定义对流水线运行进行初始化的 Cloud Function,从而使您能够设置事件驱动的 Pipeline 作业。
使用 Kubeflow PipelinesSDK 通过 gcloud 访问连接 AI Platform Pipelines 集群
要连接 AI PlatformPipelines 集群,您首先需要找到其端点的 URL。
一个简单的方法是访问您的 AIPipelines 仪表板,并点击“SETTINGS”(设置)。
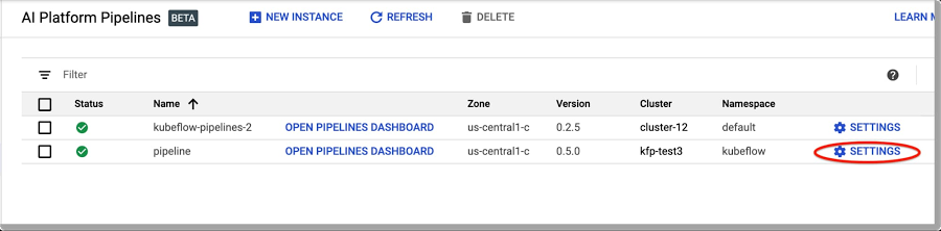
点击“Settings”获得有关您的安装的信息。
将弹出一个与下图类似的窗口:
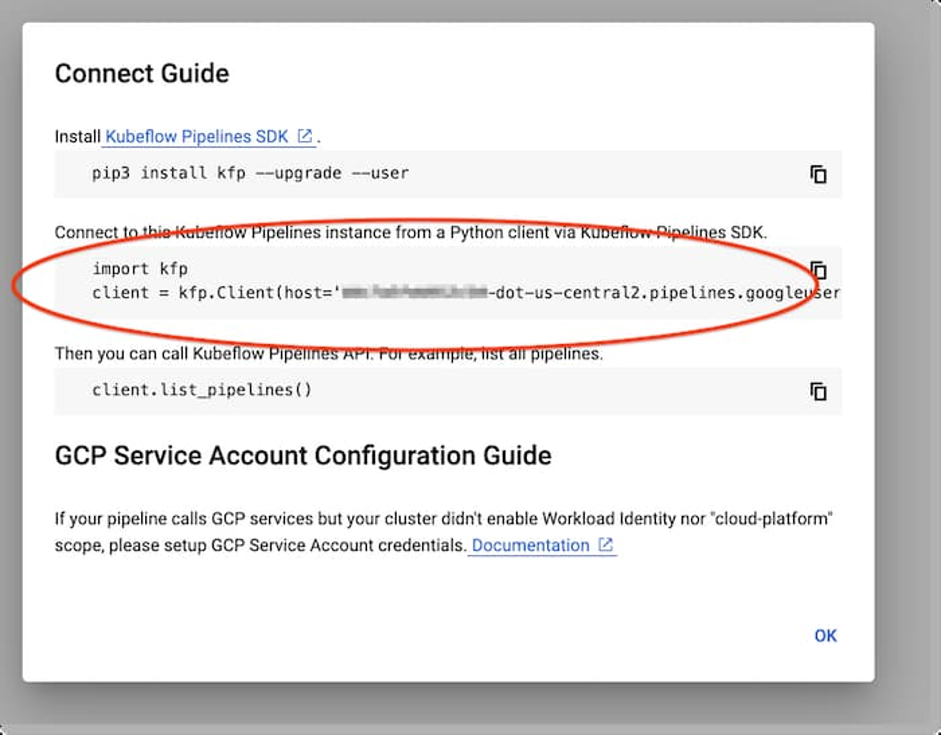
KFP 客户端设置
复制所显示的代码段以使用 KFP SDK 连接您的安装端点。这一简单的 notebook 示例旨在让您对流程进行测试。(在此另有一个使用 TFX SDK 和 TFXTemplates 的示例)。
从 AI Platform Notebooks 进行连接
如果您使用在相同项目中运行的 AI Platform Notebook,连通性会起作用。您只需如上所述提供您的 Pipelines 安装端点的 URL。
从本地或者开发机器进行连接
您可能要从您的本地机器或者其他类似环境进行 Pipelines 安装部署。如果已安装 gcloud 并为您的账号授权,身份验证应当同样直接有效。
从 GCP 运行时连接 AI Platform Pipelines 端点
对于无服务器环境(例如,CloudFunctions、Cloud Run 或者 App Engine),由于有使用不同服务账户的临时实例,设置和初始化 gcloud 可能存在问题。这里我们将使用不同的方法:我们将允许服务账户访问 Cloud AI Pipelines 的反向代理,并且获得创建客户端对象时传递的访问令牌。我们将通过一个 Cloud Functions 示例详细说明如何这样做。
示例:使用 Cloud Functions 进行事件驱动的流水线部署
Cloud Functions 是 Google Cloud 的事件驱动无服务器计算平台。使用 Cloud Functions 触发流水线部署会为支持事件驱动的流水线带来许多可能性,您可以基于添加到 Google Cloud Storage 存储桶的新数据、添加到 PubSub 主题的新信息等来开始部署。
例如,一旦新的一批数据到达或者 AIPlatform Data Labeling Service“导出”完成,您会预期着自动开始运行 ML 训练流水线。
在此,您将看到一个通过向 CloudStorage 存储桶添加新文件触发流水线部署的示例。
对于这种情况,您可能不想在保存您的数据集的 Cloud Storage 存储桶中设置 Cloud Functions 触发器,因为这在每次添加文件时都会触发 —— 如果更新包括多个文件,可能这并非您想要的行为。相反,一旦完成数据导出或者摄取流程,您可以将 Cloud Storage 文件写入一个单独的“触发器桶”,该文件包含有关新添加的数据的路径信息。通过定义一个在该存储桶上触发的 Cloud Functions 函数,这会读取文件内容并且在启动流水线运行时将数据路径信息作为参数进行传递。
通过设置 Cloud Functions 函数来部署流水线有两个主要步骤。首先是提供由 Cloud Functions 使用的服务账户 —— 您的项目的 App Engine 服务账户 —— 通过将其添加为具有 Project Viewer 权限的成员,访问由 Pipelines 安装使用的服务账户。默认情况下,Pipelines 服务账户将是您的项目的 Compute Engine 默认服务账户。
然后,您定义并部署 Cloud Functions 函数,该函数会触发启动流水线运行。该函数获得 Cloud Functions 实例的服务账户访问令牌,此令牌被传递至 KFP 客户端构造函数。接下来,您可以通过客户端对象启动流水线运行(或者提出其他请求)。
有关触发 Cloud Storage 文件或者其内容的信息可作为流水线运行时参数被传递。
import kfp
def get_access_token():
url ='http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token'
r= requests.get(url, headers={'Metadata-Flavor': 'Google'})
r.raise_for_status()
access_token = r.json()['access_token']
return access_token
...
token = get_access_token()
client = kfp.Client(host=HOST_URL,existing_token=token)
...
res = client.run_pipeline(...)
因为 Cloud Function 需要安装 kfp SDK,您需要定义一个 CloudFunctions 部署所使用的 requirements.txt 文件,该文件将指定此要求。
此 notebook会引导您完成设置流程,并显示 CloudFunctions 函数代码。此示例定义了一个非常简单的流水线,只回显一个作为参数传递的文件名。Cloud Function 启动该流水线的运行,传递 Function 调用所触发的新文件或者被修改文件的文件名。
使用服务账户凭据文件连接 Pipelines 端点
如果您正在进行本地开发,并且未安装 gcloud,也可通过本地可用的服务账户凭据文件获得凭据令牌。本示例介绍了如何做到这一点。最简单的方式是使用与用于 Pipelines 安装相同的服务账户的凭据 —— 默认为 ComputeEngine 服务账户。否则,您需要为其他服务账户提供对 Compute Engine 账户的访问权限。
总结
您可以采用几种方法来使用 AI Platform Pipelines API 远程部署流水线,我们在此介绍的 notebook 应当是一个很好的开端。尤其是,Cloud Functions 让您能够支持许多类型的事件驱动的流水线。要了解有关将这些知识付诸实践的更多信息,请参考 Cloud Functions notebook 了解关于如何基于新数据自动启动流水线运行的示例。尝试运行这些 notebook,并让我们了解您的想法。您可以在 Twitter 通过 @amygdala 找到我。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论