

1. 绪论
etcd 作为华为云 PaaS 的核心部件,实现了 PaaS 大多数组件的数据持久化、集群选举、状态同步等功能。如此重要的一个部件,我们只有深入地理解其架构设计和内部工作机制,才能更好地学习华为云 Kubernetes 容器技术,笑傲云原生的“江湖”。本系列将从整体框架再细化到内部流程,对 etcd 的代码和设计进行全方位解读。本文是《深入浅出 etcd》系列的第二篇,重点解析 etcd 的心跳和选举机制,下文所用到的代码均基于 etcd v3.2.X 版本。
另,由华为云容器服务团队倾情打造的《云原生分布式存储基石:etcd 深入解析》一书已正式出版,各大平台均有发售,购书可了解更多关于分布式存储和 etcd 的相关内容!
2. 什么是 etcd 的选举
选举是 raft 共识协议的重要组成部分,重要的功能都将是由选举出的 leader 完成。不像 Paxos,选举对 Paxos 只是性能优化的一种方式。选举是 raft 集群启动后的第一件事,没有 leader,集群将不允许任何的数据更新操作。选举完成以后,集群会通过心跳的方式维持 leader 的地位,一旦 leader 失效,会有新的 follower 起来竞选 leader。
3. etcd 选举详细流程
选举的发起,一般是从 Follower 检测到心跳超时开始的,v3 支持客户端指定某个节点强行开始选举。选举的过程其实很简单,就是一个 candidate 广播选举请求,如果收到多数节点同意就把自己状态变成 leader。下图是选举和心跳的详细处理流程。我们将在下文详细描述这个图中的每个步骤。
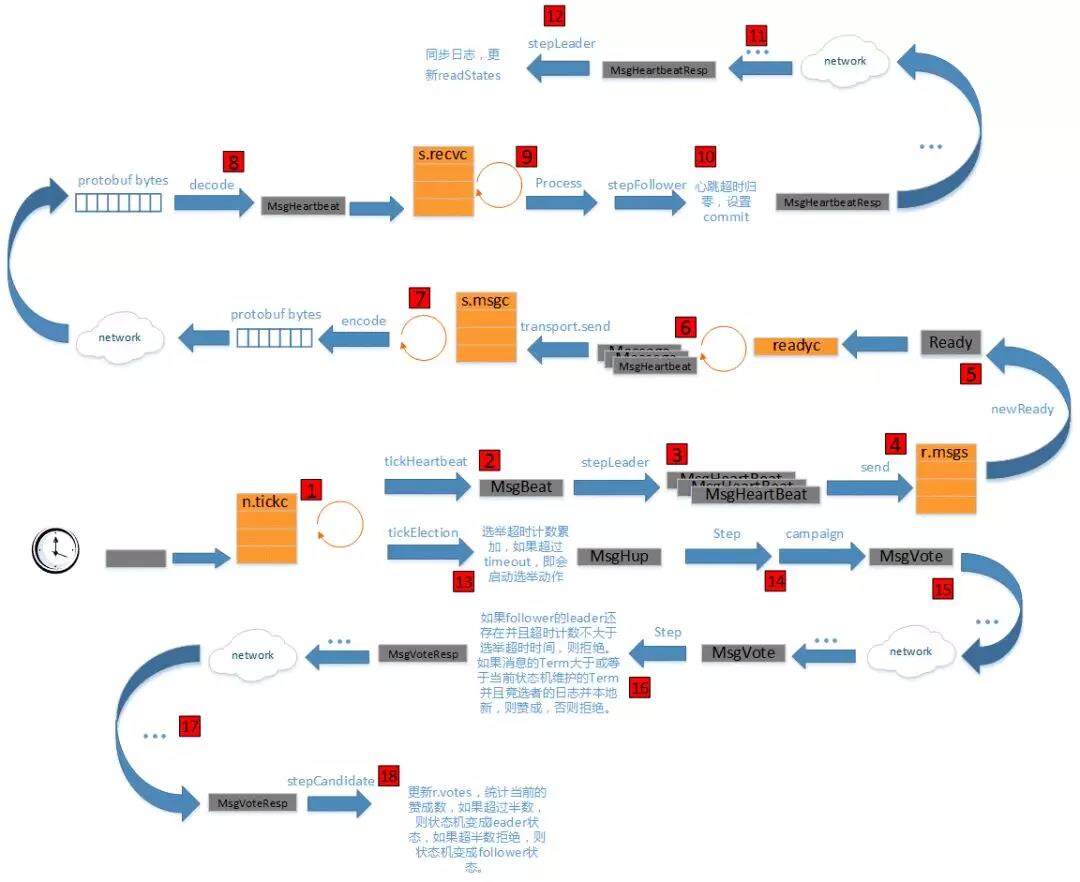
3.1 tick
raftNode 的创建函数 newRaftNode 会创建一个 Ticker。传入的 heartbeat 默认为 100ms,可以通过–heartbeat-interval 配置。
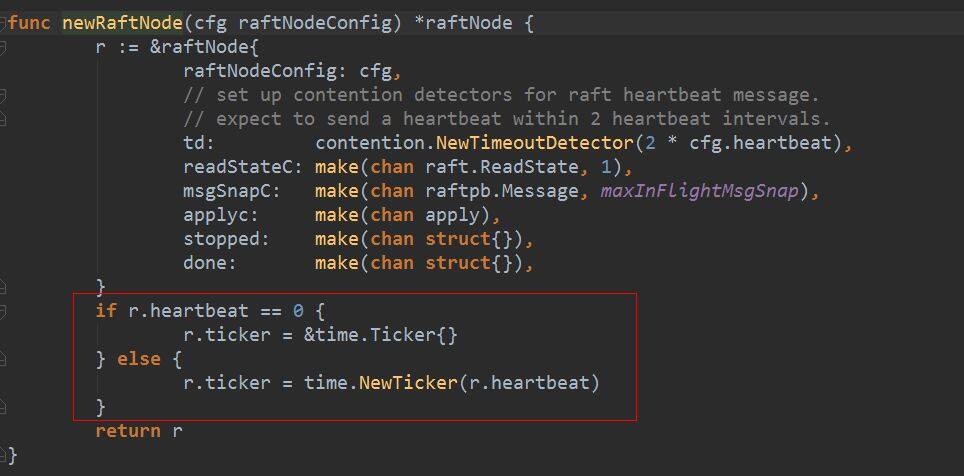
这里要介绍一下代码中出现的几个变量,我把这几个变量都翻译成 XXX 计数,是因为这些值都是整数,初始化为 0,每次 tick 完了以后会递增 1。因此实际这是一个计数。也就是说实际的时间是这个计数值乘以 tick 的时间。
选举过期计数(electionElapsed):主要用于 follower 来判断 leader 是不是正常工作,如果这个值递增到大于随机化选举超时计数(randomizedElectionTimeout),follower 就认为 leader 已挂,它自己会开始竞选 leader。
心跳过期计数(heartbeatElapsed):用于 leader 判断是不是要开始发送心跳了。只要这个值超过或等于心跳超时计数(heartbeatTimeout),就会触发 leader 广播 heartbeat 信息。
心跳超时计数(heartbeatTimeout):心跳超时时间和 tick 时间的比值。当前代码中是写死的 1。也就是每次 tick 都应该发送心跳。实际上 tick 的周期就是通过–heartbeat-interval 来配置的。
随机化选举超时计数(randomizedElectionTimeout):这个值是一个每次任期都不一样的随机值,主要是为了避免分裂选举的问题引入的随机化方案。这个时间随机化以后,每个竞选者发送的竞选消息的时间就会错开,避免了同时多个节点同时竞选。从代码中可以看到,它的值是[electiontimeout, 2*electiontimeout-1] 之间,而 electionTimeout 就是下图中的 ElectionTicks,是 ElectionMs 相对于 TickMs 的倍数。ElectionMs 是由–election-timeout 来配置的,TickMs 就是–heartbeat-interval。

raftNode 的 start()方法启动的协程中,会监听 ticker 的 channel,调用 node 的 Tick 方法,该方法往 tickc 通道中推入一个空对象。
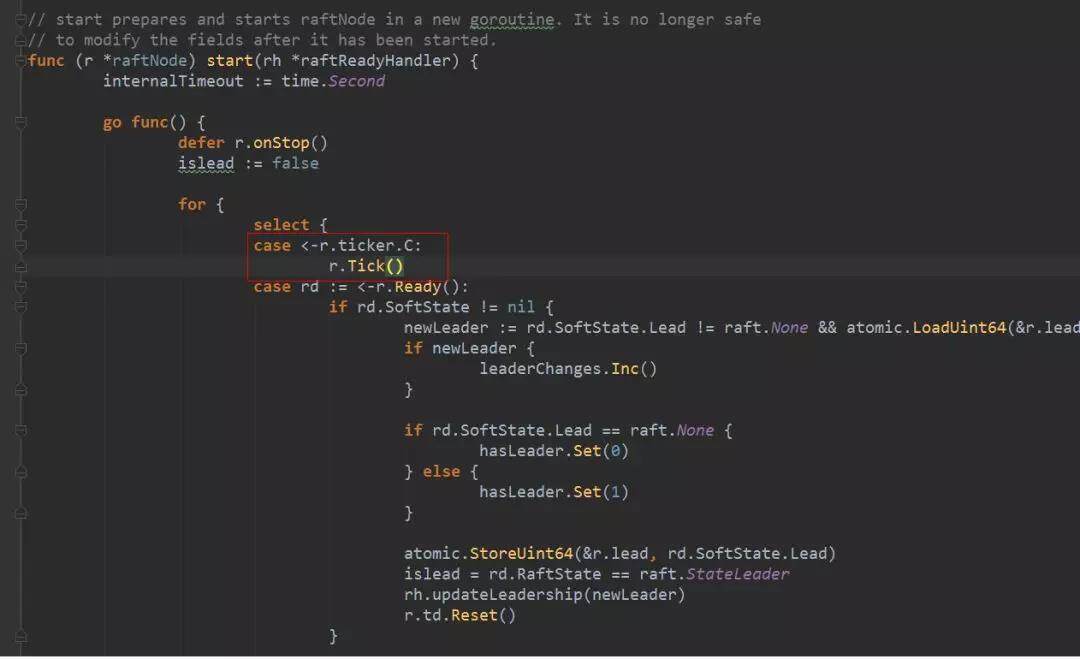
node 启动时是启动了一个协程,处理 node 的里的多个通道,包括 tickc,调用 tick()方法。该方法会动态改变,对于 follower 和 candidate,它就是 tickElection,对于 leader 和,它就是 tickHeartbeat。tick 就像是一个 etcd 节点的心脏跳动,在 follower 这里,每次 tick 会去检查是不是 leader 的心跳是不是超时了。对于 leader,每次 tick 都会检查是不是要发送心跳了。
3.2 发送心跳
当集群已经产生了 leader,则 leader 会在固定间隔内给所有节点发送心跳。其他节点收到心跳以后重置心跳等待时间,只要心跳等待不超时,follower 的状态就不会改变。 具体的过程如下:
对于 leader,tick 被设置为 tickHeartbeat,tickHeartbeat 会产生增长递增心跳过期时间计数(heartbeatElapsed),如果心跳过期时间超过了心跳超时时间计数(heartbeatTimeout),它会产生一个 MsgBeat 消息。心跳超时时间计数是系统设置死的,就是 1。也就是说只要 1 次 tick 时间过去,基本上会发送心跳消息。发送心跳首先是调用状态机的 step 方法。
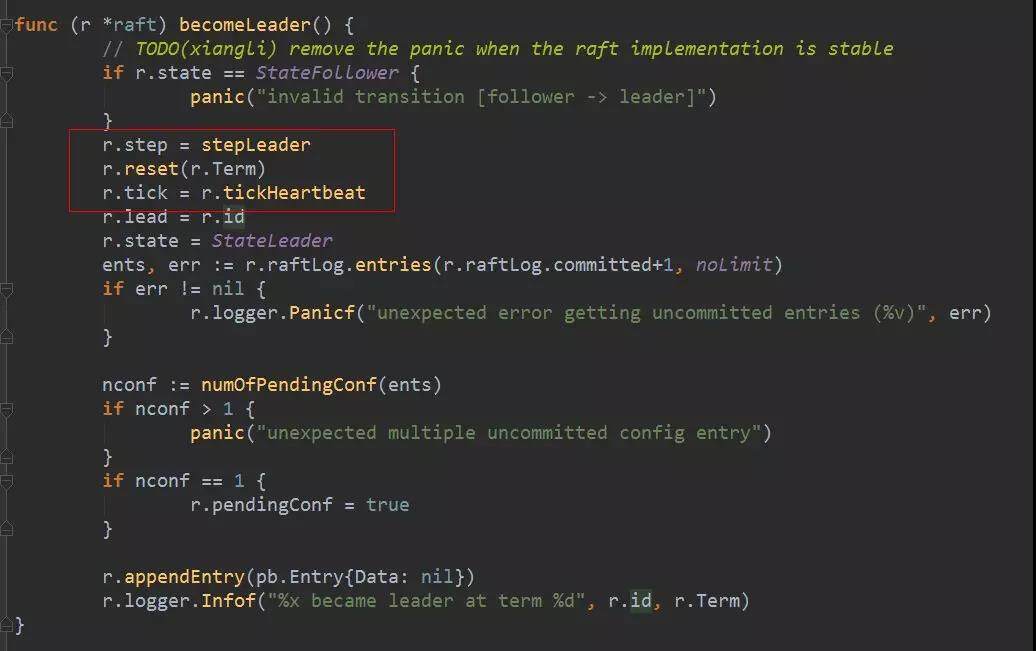
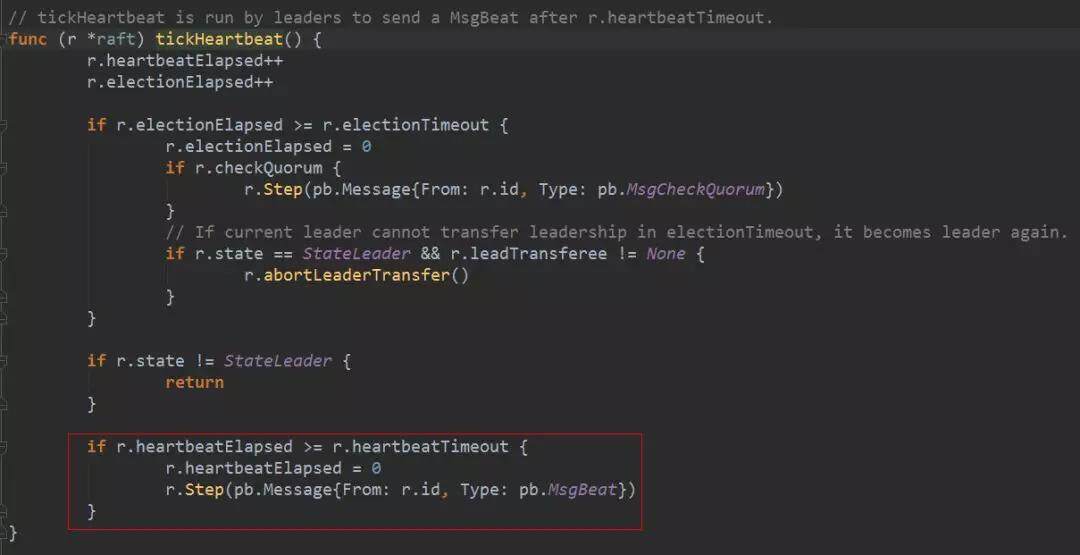
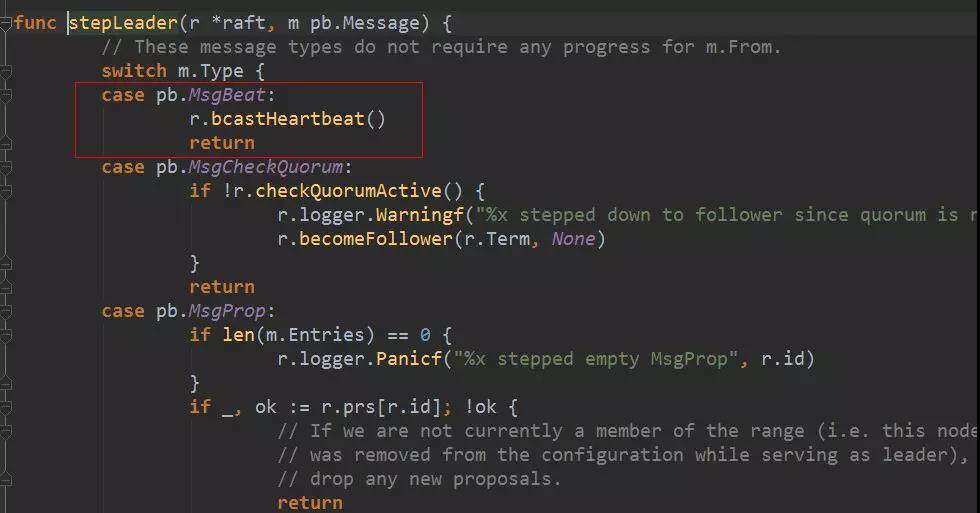
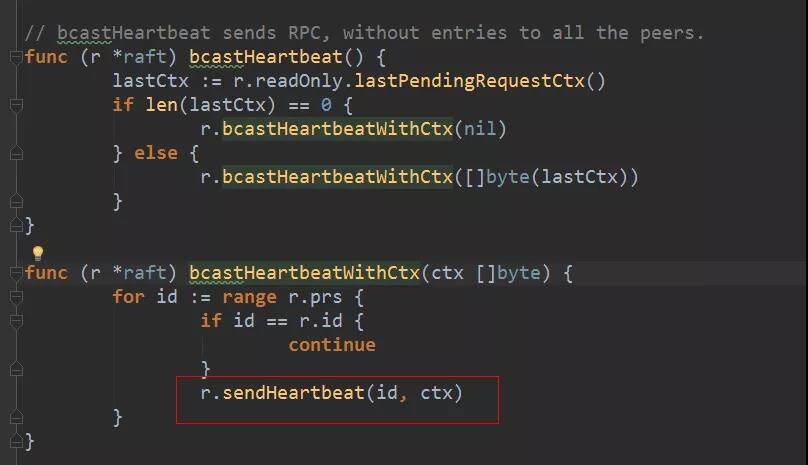
step 在 leader 状态下为 stepLeader(),当收到 MsgBeat 时,它会调用 bcastHeartbeat()广播 MsgHeartbeat 消息。构造 MsgHeartbeat 类型消息时,需要在 Commit 字段填入当前已经可以 commit 的消息 index,如果该 index 大于 peer 中记录的对端节点已经同步的日志 index,则采用对端已经同步的日志 index。Commit 字段的作用将在接收端处理消息时详细介绍。
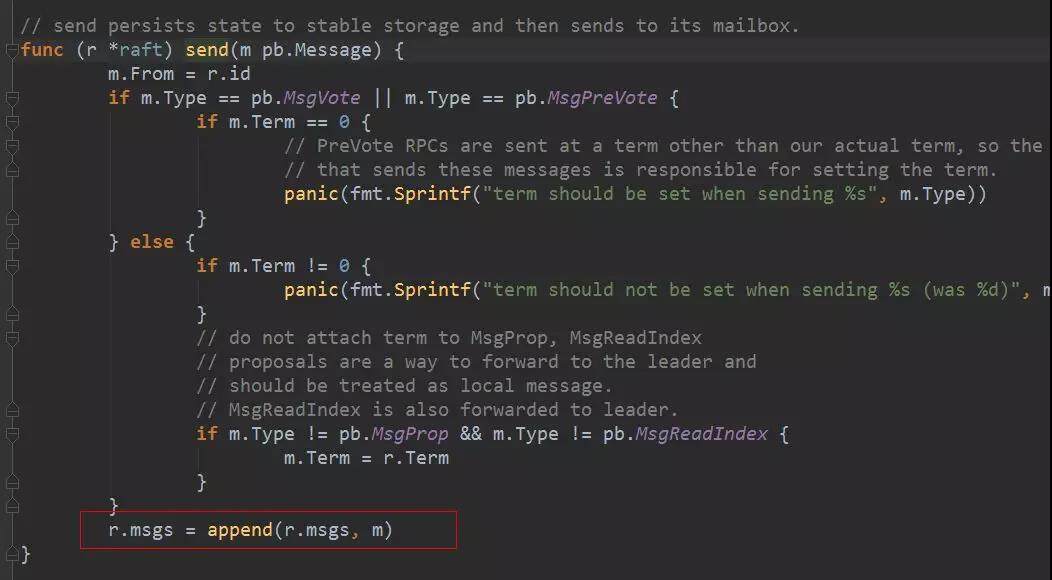
send 方法将消息 append 到 msgs 数组中。
4. node 启动的协程会收集 msgs 中的消息,连同当前未持久化的日志条目、已经确定可以 commit 的日志条目、变化了的 softState、变化了的 hardState、readstate 一起打包到 Ready 数据结构中。这些都是会引起状态机变化的,所以都封装在一个叫 Ready 的结构中,意思是这些东西都已经没问题了,该持久化的持久化,该发送的发送。
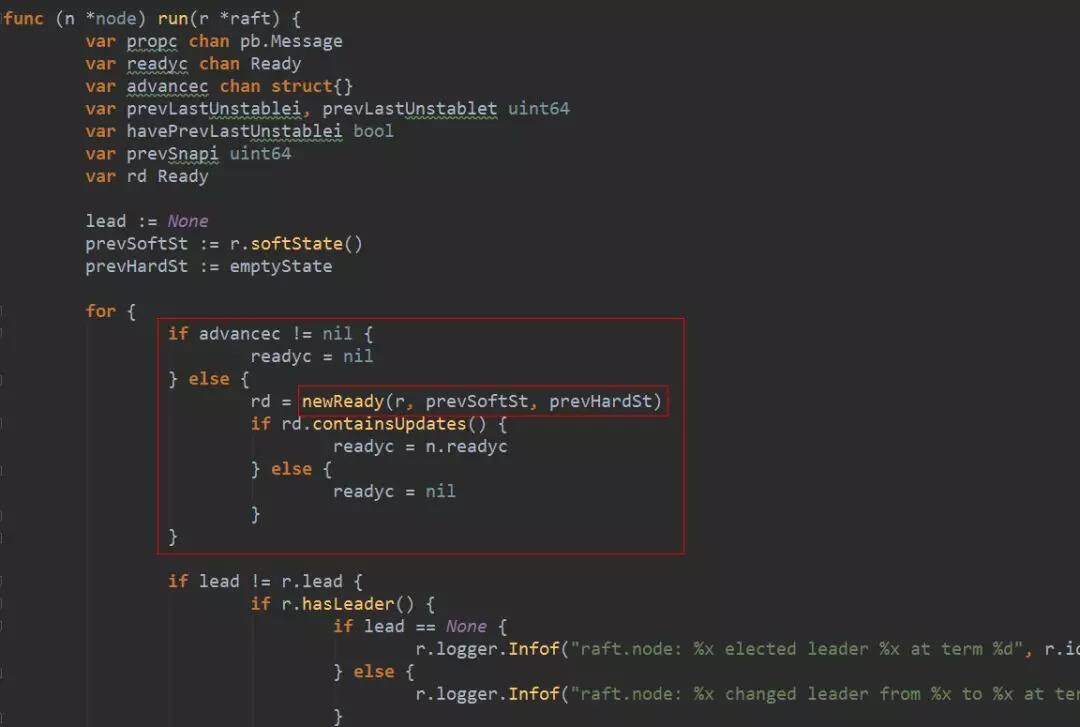
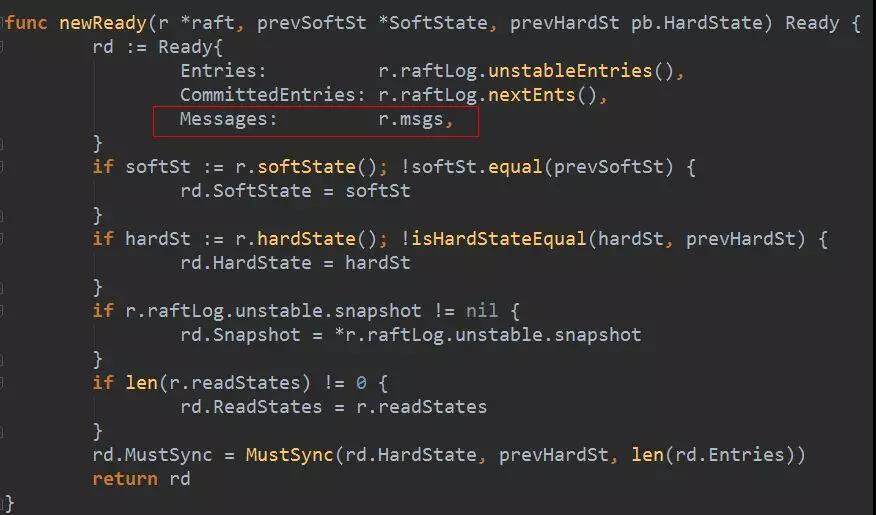
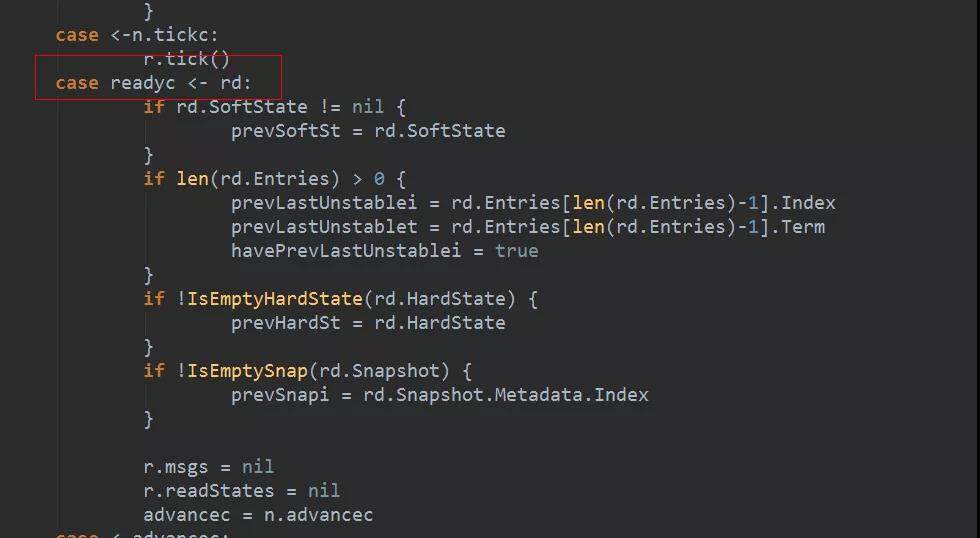
还是 raftNode.start()启动的那个协程,处理 readyc 通道。如果是 leader,会在持久化日志之前发送消息,如果不是 leader,则会在持久化日志完成以后发送消息。
transport 的 Send 一般情况下都是调用其内部的 peer 的 send()方法发送消息。peer 的 send()方法则是将消息推送到 streamWriter 的 msgc 通道中。
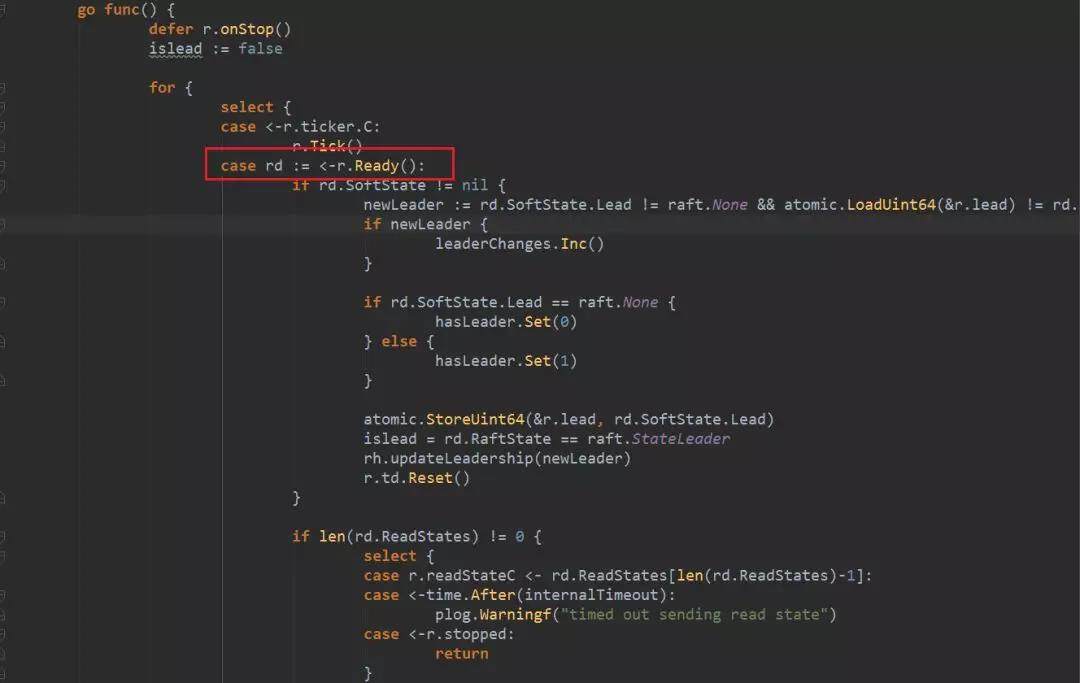
streamWriter 有一个协程处理 msgc 通道,调用 encode,使用 protobuf 将 Message 序列化为 bytes 数组,写入到连接的 IO 通道中。
对方的节点有 streamReader 会接收消息,并反序列化为 Message 对象。然后将消息推送到 peer 的 recvc 或者 propc 通道中。
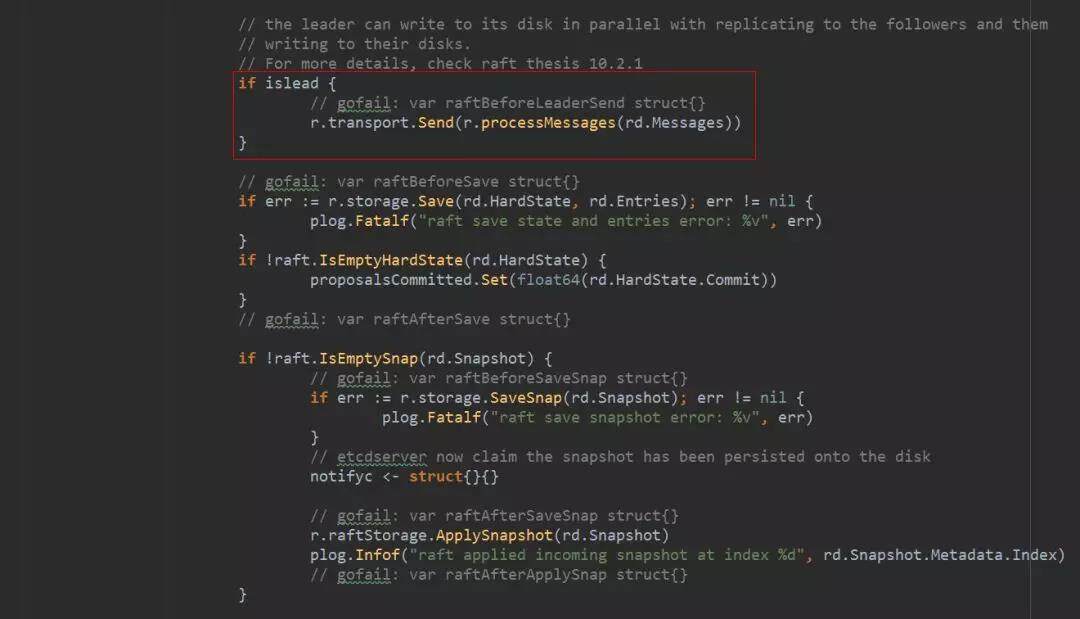
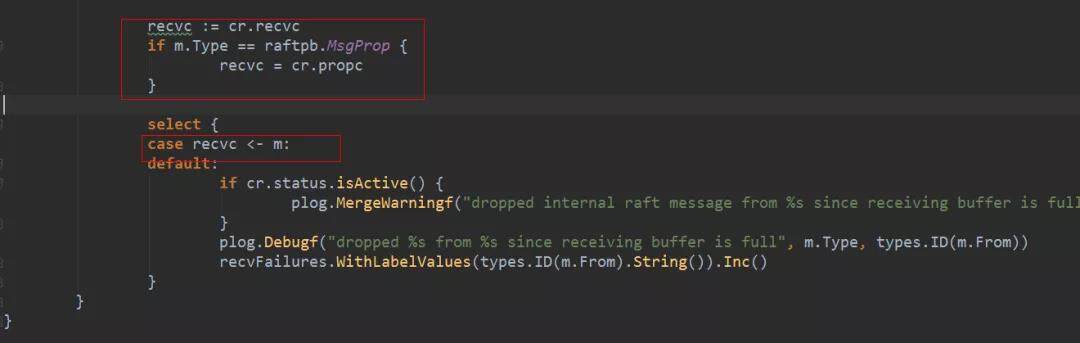
peer 启动时启动了两个协程,分别处理 recvc 和 propc 通道。调用 Raft.Process 处理消息。EtcdServer 是这个接口的实现。
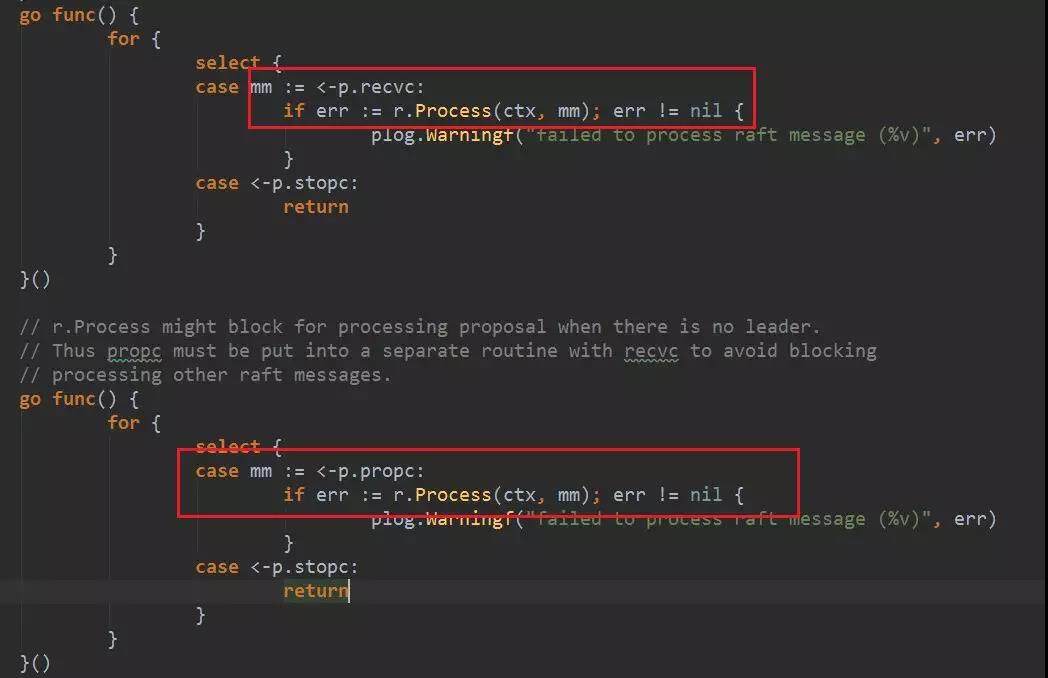
EtcdServer 判断消息来源的节点是否被删除,没有的话调用 Step 方法,传入消息,执行状态机的步进。而接收 heartbeat 的节点状态机正常情况下都是 follower 状态。因此就是调用 stepFollower 进行步进。

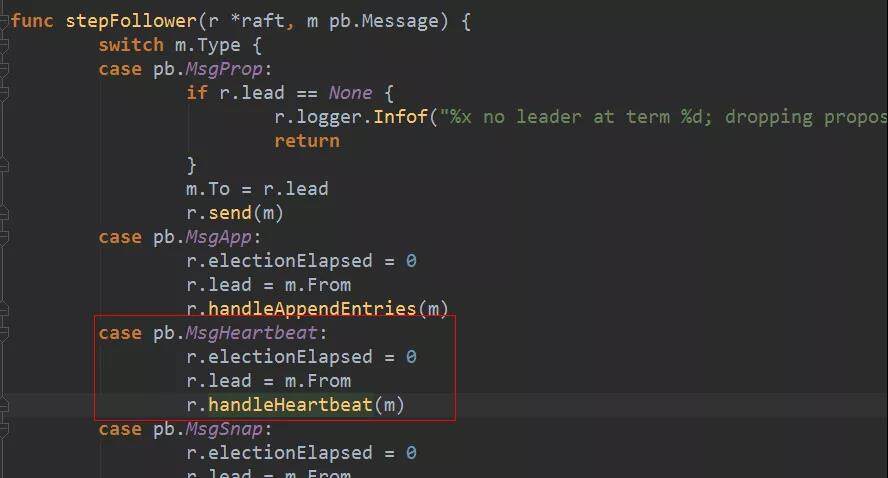
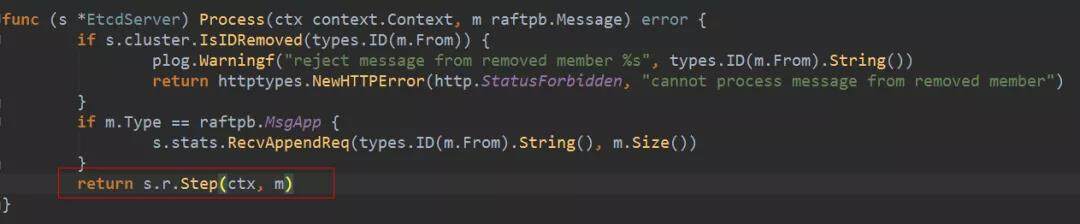
follower 对 heatbeat 消息的处理是:先将选举过期时间计数(electionElapsed)归零。这个时间会在每次 tickElection 调用时递增。如果到了 electionTimeout,就会重新选举。另外,我们还可以看到这里 handleHeartbeat 中,会将本地日志的 commit 值设置为消息中带的 Commit。这就是第 2 步说到设置 Commit 的目的,heartbeat 消息还会把 leader 的 commit 值同步到 follower。同时,leader 在设置消息的 Commit 时,是取它对端已经同步的日志最新 index 和它自己的 commit 值中间较小的那个,这样可以保证如果有节点同步比较慢,也不会把 commit 值设置成了它还没同步到的日志。最后,follower 处理完以后会回复一个 MsgHeartbeatResp 消息。
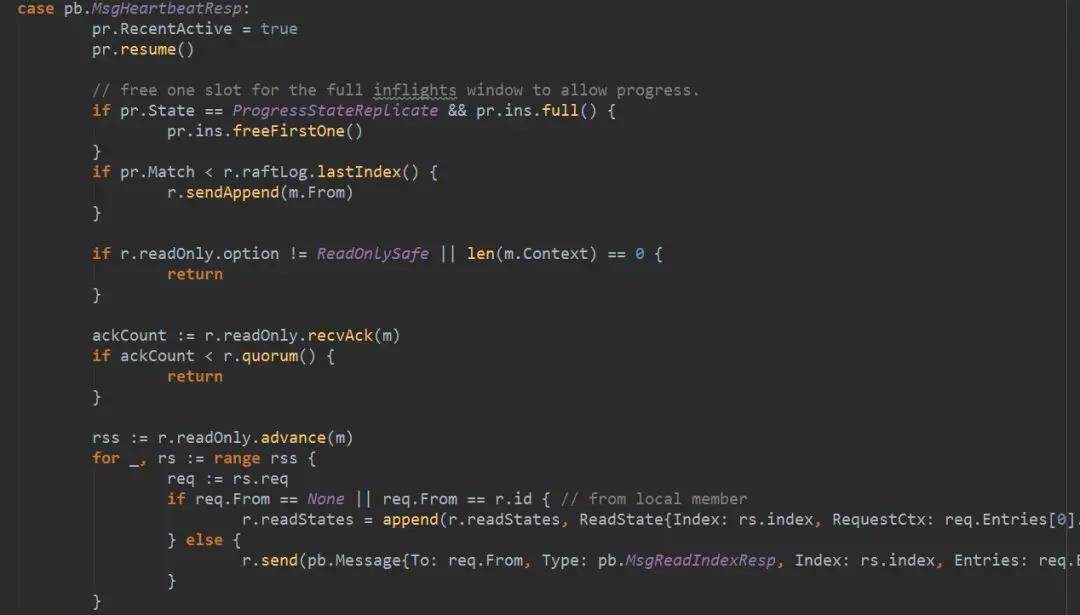
回复消息的中间处理流程和心跳消息的处理一致,因此不再赘述。leader 收到回复消息以后,最后会调用 stepLeader 处理回复消息。
stepLeader 收到回复消息以后,会判断是不是要继续同步日志,如果是,就发送日志同步信息。另外会处理读请求,这部分的处理将在 linearizable 读请求的流程中详细解读。
3.3 选举
检测到选举超时的 follower,会触发选举流程,具体的流程如下:
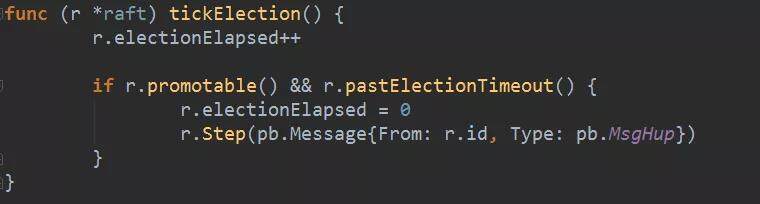
依然从 tick 开始,对于 follower(或 candidate)。tick 就是 tickElection,它的做法是,首先递增选举过期计数(electionElapsed),如果选举过期计数超过了选举超时计数。则开始发起选举。发起选举的话,实际是创建一个 MsgHup 消息调用状态机的 Step 方法。
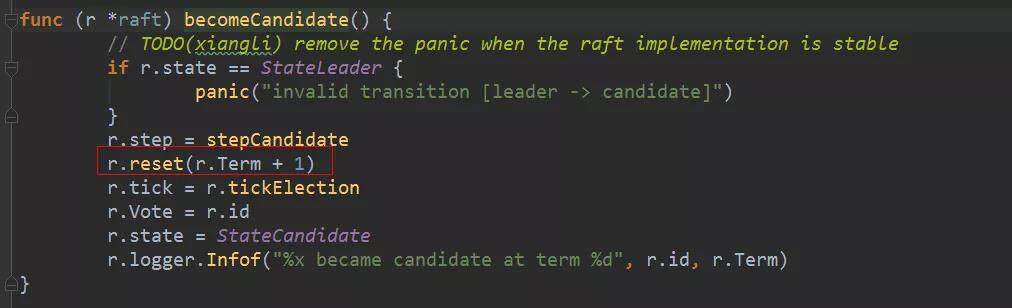
Step 方法处理 MsgHup 消息,查看当前本地消息中有没有没有作用到状态机的配置信息日志,如果有的话,是不能竞选的,因为集群的配置信息有可能会出现增删节点的情况,需要保证各节点都起作用以后才能进行选举操作。从图上可以看到,如果有 PreVote 的配置,会有一个 PreElection 的分支。这个放在最后我们介绍。我们直接看 campaign()方法,它首先将自己变成 candidate 状态,becomeCandidate 会将自己 Term+1。然后拿到自己当前最新的日志 Term 和 index 值。把这些都包在一个 MsgVote 消息中,广播给所有的节点。最新的日志 Term 和 index 值是非常重要的,它能保证新选出来的 leader 中一定包含之前已经 commit 的日志,不会让已经 commit 的日志被新 leader 改写。这个在后面的流程中还会讲到。
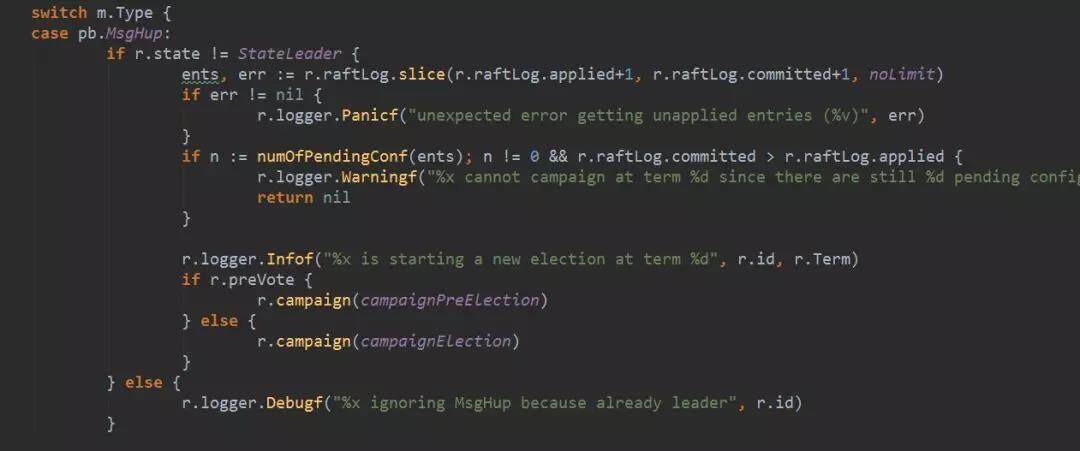
选举消息发送的流程和所有消息的流程一样,不在赘述。
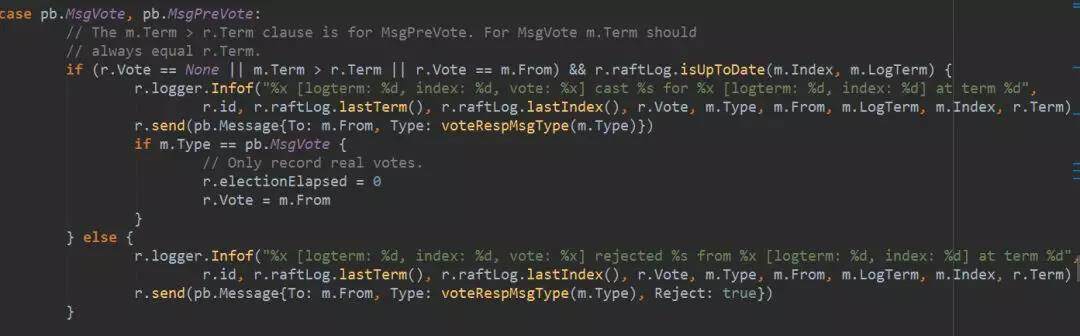
心跳消息到了对端节点以后,进行相应的处理,最终会调到 Step 方法,进行状态机步进。Step 处理 MsgVote 方法的流程是这样的:
首先,如果选举过期时间还没有超时,将拒绝这次选举请求。这是为了防止有些 follower 自己的原因没收到 leader 的心跳擅自发起选举。
如果 r.Vote 已经设置了,也就是说在一个任期中已经同意了某个节点的选举请求,就会拒绝选举
如果根据消息中的 LogTerm 和 Index,也就是第 2 步传进来的竞选者的最新日志的 index 和 term,发现竞选者比当前节点的日志要旧,则拒绝选举。
其他情况则赞成选举。回复一个赞成的消息。

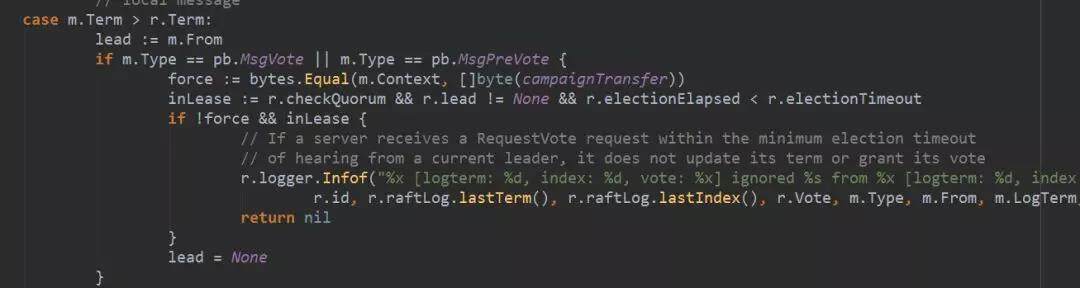
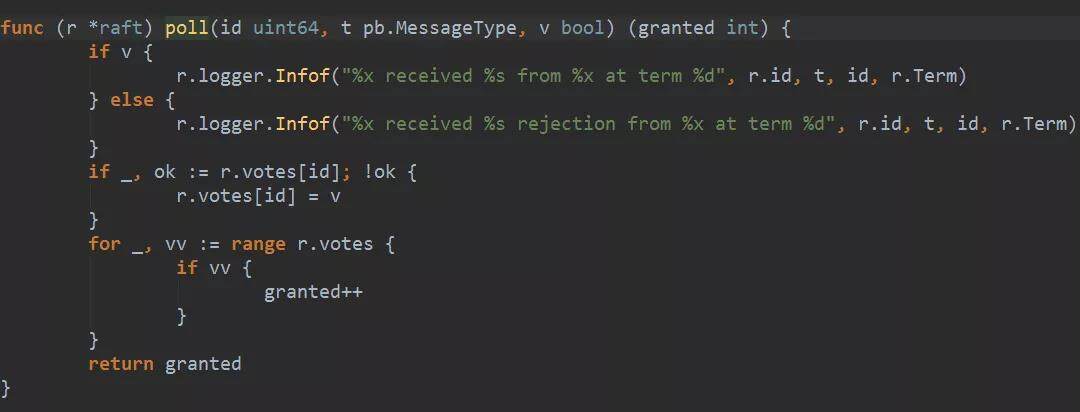
竞选者收到 MsgVoteResp 消息以后,stepCandidate 处理该消息,首先更新 r.votes。r.votes 是保存了选票信息。如果同意票超过半数,则升级为 leader,否则如果已经获得超过半数的反对票,则变成 follower。
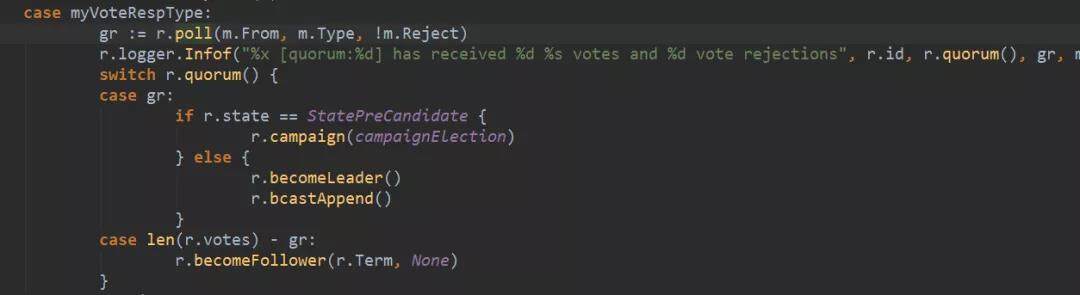
4. PreVote
PreVote 是解决因为某个因为网络分区而失效的节点重新加入集群以后,会导致集群重新选举的问题。问题出现的过程是这样的,假设当前集群的 Term 是 1,其中一个节点,比如 A,它因为网络分区,接收不到 leader 的心跳,当超过选举超时时间以后,它会将自己变成 Candidate,这时候它会把它的 Term 值变成 2,然后开始竞选。当然这时候是不可能竞选成功的。可是当网络修复以后,无论是它的竞选消息,还是其他的回复消息,都会带上它的 Term,也就是 2。而这时候整个集群里其他机器的 Term 还是 1,这时候的 leader 发现已经有比自己 Term 高的节点存在,它就自己乖乖降级为 follower,这样就会导致一次重新选举。这种现象本身布常见,而且出现了也只是出现一次重选举,对整个集群的影响并不大。但是如果希望避免这种情况发生,依然是有办法的,办法就是 PreVote。
PreVote 的做法是:当集群中的某个 follower 发现自己已经在选举超时时间内没收到 leader 的心跳了,这时候它首先不是直接变成 candidate,也就不会将 Term 自增 1。而是引入一个新的环境叫 PreVote,我们就将它称为预选举吧。它会先广播发送一个 PreVote 消息,其他节点如果正常运行,就回复一个反对预选举的消息,其他节点如果也失去了 leader,才会有回复赞成的消息。节点只有收到超过半数的预选举选票,才会将自己变成 candidate,发起选举。这样,如果是这个单个节点的网络有问题,它不会贸然自增 Term,因此当它重新加入集群时。也不会对现任 leader 地位有任何冲击。保证了系统更稳定的方式运行。
5、 如何保证已经 commit 的数据不会被改写?
etcd 集群的 leader 会一直向 follower 同步自己的日志,如果 follower 发现自己的日志和 leader 不一致,会删除它本地的不一致的日志,保证和 leader 同步。
leader 在运行过程中,会检查同步日志的回复消息,如果发现一条日志已经被超过半数的节点同步,则把这条日志记为 committed。随后会进行 apply 动作,持久化日志,改变 kv 存储。
我们现在设想这么一个场景:一个集群运行过程中,leader 突然挂了,这时候就有新的 follower 竞选 leader。如果新上来的 leader 日志是比较老的,那么在同步日志的时候,其他节点就会删除比这个节点新的日志。要命的是,如果这些新的日志有的是已经提交了的。那么就违反了已经提交的日志不能被修改的原则了。
怎么避免这种事情发生呢?这就涉及到刚才选举流程中一个动作,candidate 在发起选举的时候会加上当前自己的最新的日志 index 和 term。follower 收到选举消息时,会根据这两个字段的信息,判断这个竞选者的日志是不是比自己新,如果是,则赞成选举,否则投反对票。
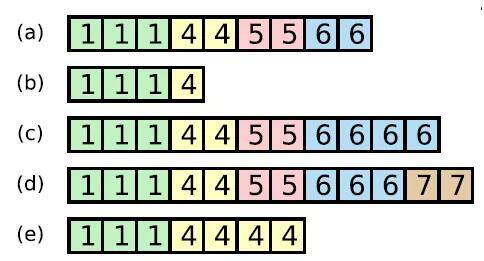
为什么这样可以保证已经 commit 的日志不会被改写呢?因为这个机制可以保证选举出来的 leader 本地已经有已经 commit 的日志了。为什么这样就能保证新 leader 本地有已经 commit 的日志呢?因为我们刚才说到,只有超过半数节点同步的日志,才会被 leader commit,而 candidate 要想获得半数以上的选票,日志就一定要比半数以上的节点新。这样两个半数以上的群体里交集中,一定至少存在一个节点。这个节点的日志肯定被 commit 了。因此我们只要保证竞选者的日志被大多数节点新,就能保证新的 leader 不会改写已经 commit 的日志。简单来说,这种机制可以保证下图的 b 和 e 肯定选不 leader。
6、 频繁重选举的问题
如果 etcd 频繁出现重新选举,会导致系统长时间处于不可用状态,大大降低了系统的可用性。
什么原因会导致系统重新选举呢?
网络时延和网络拥塞:从心跳发送的流程可以看到,心跳消息和其他消息一样都是先放到 Ready 结构的 msgs 数组中。然后逐条发送出去,对不同的节点,消息发送不会阻塞。但是对相同的节点,是一个协程来处理它的 msgc 通道的。也就是说如果有网络拥塞,是有可能出现其他的消息拥塞通道,导致心跳消息不能及时发送的。即使只有心跳消息,拥塞引起信道带宽过小,也会导致这条心跳消息长时间不能到达对端。也会导致心跳超时。另外网络延时会导致消息发送时间过程,也会引起心跳超时。另外,peer 之间通信建链的超时时间设置为 1s+(选举超时时间)*1/5 。也就是说如果选举超时设置为 5s,那么建链时间必须小于 2s。在网络拥塞的环境下,这也会影响消息的正常发送。

IO 延时:从 apply 的流程可以看到,发送 msg 以后,leader 会开始持久化已经 commit 的日志或者 snapshot。这个过程会阻塞这个协程的调用。如果这个过程阻塞时间过长,就会导致后面的 msgs 堵在那里不能及时发送。根据官网的解释,etcd 是故意这么做的,这样可以让那些 io 有问题的 leader 自动失去 leader 地位。让 io 正常的节点选上 leader。但是如果整个集群的节点 io 都有问题,就会导致整个集群不稳定。
本文转载自华为云产品与解决方案公众号。
原文链接:https://mp.weixin.qq.com/s/CAhiZTEw6vQJHbiEvc5u4w

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论