

基于 Amazon Simple Storage Service (Amazon S3)服务,您可以通过跨区域复制功能(CRR)来自动异步地拷贝分布在不同 AWS 区域桶中的对象。CRR 是一个桶级别的配置,它能满足您在合规方面的要求,通过在不同区域存储备份数据以最大限度地帮助您减少潜在风险。CRR 可以复制源存储桶中的所有对象,或者通过前缀和标签来选择其中的一个子集进行复制。在您启用 CRR 之前就已经预先存在的对象(pre-existingobjects) 是不会被复制的。同样的,如果是所使用的 IAM 角色复制权限不足或者存储桶政策授权不到位(当存储桶属于不同的 AWS 帐号),也可能无法完成对象的复制(failed objects)。在与客户合作过程中,我们发现大量基于上述原因而没能复制的对象。在本文中,我们会给您展示如何针对这些 pre-existing 和 failed objects(早于 CRR 启用就已经存在的和复制失败的对象)进行跨区域复制。
方法论
从大的方向上来说,我们的策略是执行 copy-in-place 来实现 pre-existing 和 failed objects 的复制,利用 Amazon S3 API 在这些对象之上进行复制,保留标签、接入控制列表(ACL)、元数据和压缩密钥。该操作也会在对象上重新设置复制状态(Replication_Status)标签。
具体来说我们通过以下来实现:
通过 Amazon S3 inventory 来识别 copy in place 的对象。这些对象没有复制状态,或者状态显示为失败。
通过 Amazon Athena 和 AWS Glue 把 S3 inventory 文件提取成表。
通过 Amazon EMR 来执行 Apache Spark 任务以查询 AWS Glue 生成的表,并执行 copy-in-place。
对象过滤
为了减少问题的出现(我们已经见过存储了数十亿对象的桶!)并杜绝 S3 list 操作,我们采用了 Amazon S3 inventory 服务。该服务在桶级别上启用,会提供一个 S3 对象的报告。Inventory 文件包含对象的复制状态:PENDING, COMPLETED, FAILED,或 REPLICA。Pre-existing objects 在 inventory 中没有复制状态。
交互分析
为了简化使用 S3 inventory 创建的文件的过程,我们在 AWS Glue Data Catalog 中创建了一个表。您可以通过 Amazon Athena 来查询该表并分析对象,也可以利用它在 Amazon EMR 的 Spark 任务运行时识别出 copy in place 的对象。
Copy-in-place 的执行
我们通过在 Amazon EMR 上运行一个 Spark 任务来执行针对 S3 对象的并发的 copy-in-place。该步骤可以增大同时复制的运行规模,与使用单线程应用的连续复制相比,在进行大量对象的复制时性能会更好。
帐号设置
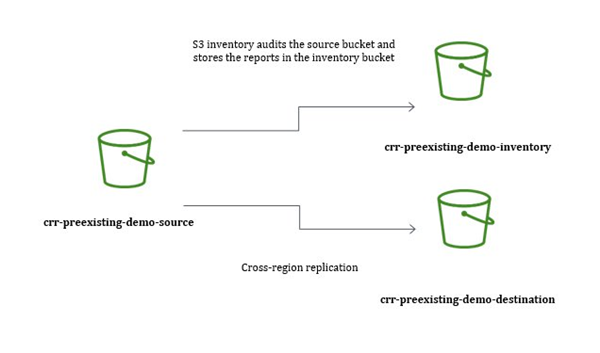
作为示例,我们为这次演示专门创建了三个 S3 存储桶。如果您想跟着一起操作的话,您需要以不同的名字先创建您自己的存储桶。我们分别将源存储桶和目标桶命名为 crr-preexisting-demo-source 和 crr-preexisting-demo-destination,源桶中还有预先存在的和复制状态为失败的对象。我们还将 S3 inventory 文件存储于名叫 crr-preexisting-demo-inventory 的第三个桶。
基本设置见以下图表:
您可以用任何桶来存储 inventory,但是桶政策必须包含以下声明(需修改 Resource 和 aws:SourceAccount 来与之匹配)
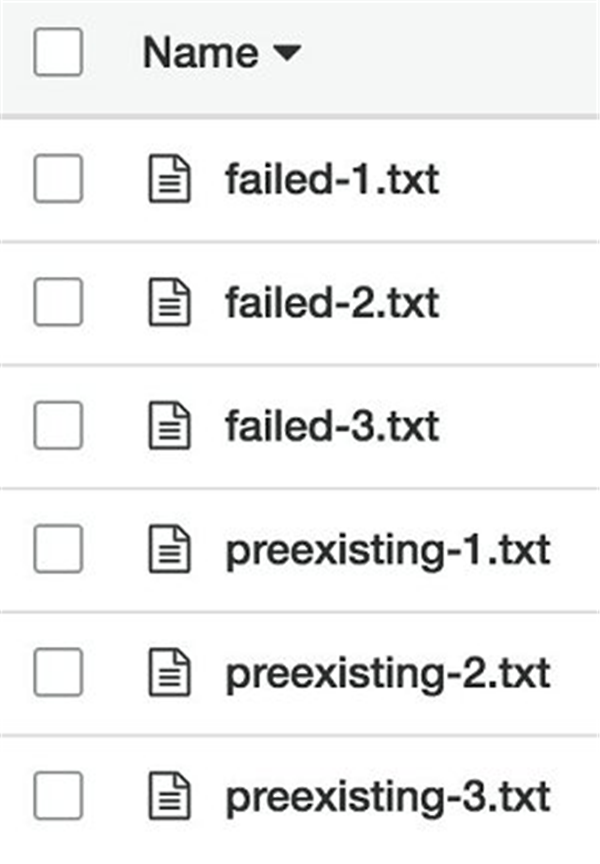
在本示例中,我们上载了六个对象到 crr-preexisting-demo-source。我们添加了三个在 CRR 被启用之前预先存在的对象(preexisting-.txt) ,以及三个由于 CRR IAM 角色的许可被移除而导致的 CRR 复制失败的对象(failed-.txt)。
启用 S3 inventory
您需要在 Amazon S3 console 中完成以下操作,来启用源桶中的 S3 inventory :
在源桶的 Management 标签处选择 inventory。

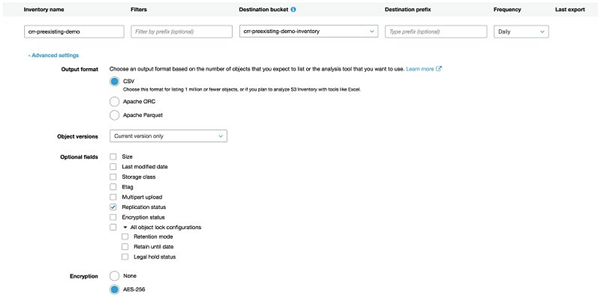
选择 Add new,并完成下图设置,选择 CSV 格式,勾选 Replication status。不想了解如何创建 inventory 的详细信息,请参考 Amazon S3 Console User Guide 中的 How Do I Configure Amazon S3 Inventory?
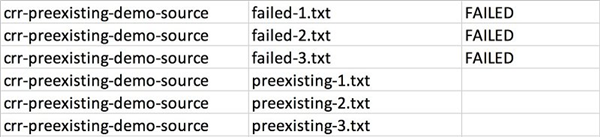
启用 S3 inventory 后,请等待 inventory 文件的送达,第一份报告会在 48 小时以内送到。如果您正跟着演示操作的话,请确保在进行下一步之前 inventory 报告已被送达。以下是 inventory 文件的样例:
你也可以看到对象的 Overview 的标签上的 S3 console。预先存在的对象没有一个复制状态,但是复制失败的对象会显示如下:

通过 Amazon Athena 来注册 AWS Glue Data Catalog 中的表
为了能够用 SQL 来查询 inventory 文件,首先您需要在 AWS Glue Data Catalog 中创建一个外部表。点击https://console.aws.amazon.com以打开 Amazon Athena console,在 Query Editor 标签上运行如下 SQL 声明。该声明会把这个外部表注册在 AWS Glue Data Catalog 中。
创建完这个表格以后,您需要通过在表中添加 partition metadata 以使 AWS Glue Data Catalog 能察觉到任何现存的数据和 partitions。请使用 Metastore Consistency Check 功能来扫描和添加 partition metadata 到 AWS Glue Data Catalog 中。
如您想进一步了解这么做的原因,请参考 Amazon Athena User Guide 中的 MSCK REPAIR TABLE 和 data partitioning 文献。
现在表和 partitions 都已经在 Data Catalog 中注册,您就可以用 Amazon Athena 来查询 inventory 文件了。
查询结果如下:
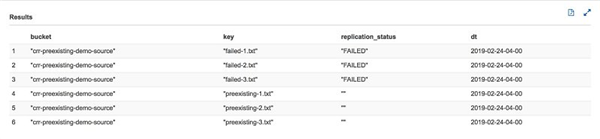
查询结果会显示 S3 inventory 中的某一个特定送达日期的所有行。现在您可以启动 EMR cluster 来复制(copy in place)预先存在的和之前复制失败的对象了。
注意:如果您的目的是解决之前复制失败的问题,在进行下一步之前请确保你已经纠正了导致失败的因素(IAM 的权限或 S3 桶政策)
创建一个 EMR cluster 用于拷贝对象
为了并行 copy in place,请在 Amazon EMR 上运行 Spark job。我们写了一个 bash 脚本(详见:this GitHub repository)用于促进 EMR cluster 的创建和 EMR 步骤提交。请您先克隆 GitHub repo 来运行该脚本,然后参考以下启动 EMR cluster:
注意:运行 bash 脚本会产生 AWS 费用。默认会创建两个 Amazon EC2 实例,一个 m4.xlarge 和一个 m4.2xlarge。由于启用了自动终止,当 cluster 完成 in-place 复制后会自动终止。脚本会执行以下任务:
创建默认 EMR 角色(EMR_EC2_DefaultRole 和 EMR_DefaultRole).
上传用于 bootstrap 动作和 steps 的文件至 Amazon S3(我们采用 crr-preexisting-demo-inventory 来存储这些文件)
使用 create-cluster 创建带 Apache Spark 的 EMR 集群。
完成 cluster 的配置之后:
通过 bootstrap action 安装 boto3 和 awscli
会执行两个步骤,先复制 Spark 应用到 master node 上,然后再运行该应用。
以下是 Spark 应用中的重点部分。您可以点击 amazon-s3-crr-preexisting-objectsrepo 在 Github 上找到本例的完整编码。
在此,我们从通过 AWS Glue Data Catalog 注册的表中挑选了 replication_status 为”FAILED” or “”的记录。
针对之前查询中返回的每个 key,我们调用 copy_object 功能
注意:在 Spark 应用添加了一个 forcedreplication key 到对象的 metadata 中。之所以这么做是因为 Amazon S3 不允许您在没有改变对象或其 metadata 的情况下执行 copy in place
通过在 Amazon Athena 中运行一个查询来验证 EMR 工作是否成功
Spark 应用将结果输出到 S3。您可以用 Amazon Athena 创建另一个外部表并用 AWS Glue Data Catalog 来注册。然后用 Athena 来查询表以确保此次 copy-in-place 操作是成功的。
查询结果在控制台上显示如下:
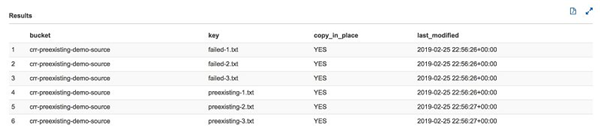
虽然这表明此次 copy-in-place 操作是成功的,CRR 仍然需要复制对象。接下来的 inventory 文件显示对象复制状态为 COMPLETED。您也可以在 console 上验证 preexisting-.txt and failed-.txt 是否为 COMPLETED 状态。

值得提醒的是,因为 CRR 要求存储桶开启了多版本的功能,copy-in-place 操作会产生对象的另一个版本,对此您可以用 S3 lifecycle policies 来管理过期的版本。
结论
在本文中,我们展示了如何用 Amazon S3 inventory, Amazon Athena, AWS Glue Data Catalog 和 Amazon EMR 来对预先存在的和之前复制失败的对象进行规模化的 copy-in-place。
注意:Amazon S3 batch operations 是复制对象的备选方案。区别在于 S3 batch operations 不会检查每一个对象目前的属性和设置对象的 ACLs 和存储级别,以及对每个对象逐个进行加密。如想了解更多相关信息,请参考 Amazon S3 Console User Guide 中的 Introduction to Amazon S3 Batch Operations。
作者介绍:
本篇作者
Michael Sambol
AWS 高级顾问,他获得了佐治亚理工学院的计算机科学硕士学位。Michael 喜欢锻炼、打网球、旅游和看西部电影
Chauncy McCaughey
AWS 高级数据架构师,他目前在做的业余项目是利用驾驶习惯和交通模式的统计分析来了解自己是如何做到总是开在慢车道的
校译作者
陈昇波
亚马逊 AWS 解决方案架构师,负责基于 AWS 的云计算方案架构的咨询和设计,同时致力于 AWS 云服务在国内的应用和推广。现致力于网络安全和大数据分析相关领域的研究。在加入 AWS 之前,在爱立信东北亚区担任产品经理,负责产品规划和方案架构设计和实施,在用户体验管理以及大数据变现等服务方面有丰富经验。
本文转载自 AWS 博客。
原文链接:


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论