


使用 kubernetes 这么多年以来,我们见过的集群不计其数(包括托管的和非托管的,GCP、AWS 和 Azure 上的都有),还见识了很多经常重复出现的错误。其中大部分错误我们自己也犯过,这没什么丢人的!
本文会给大家展示一些我们经常遇到的问题,并谈谈修复它们的方法。
1.资源:请求和限制
这无疑是最值得关注的,也是这个榜单上的第一名。
人们经常不设置 CPU 请求或将 CPU 请求设置得过低(这样我们就可以在每个节点上容纳很多 Pod),结果节点就会过量使用(overcommited)。在需求较高时,节点的 CPU 全负荷运行,而我们的负载只能得到“它所请求的”数据,使 CPU 节流(throttled),从而导致应用程序延迟和超时等指标增加。
BestEffort(不要这样做):
very low cpu(不要这样做):
另一方面,启用 CPU 限制可能会在节点的 CPU 没有充分利用的情况下,对 Pod 进行不必要地节流,这也会导致延迟增加。人们也讨论过关于 Linux 内核中的 CPU CFS 配额,和因为设置了 CPU 限制并关闭 CFS 配额而导致的 CPU 节流问题。CPU 限制造成的问题可能会比它能解决的问题还多。想了解更多信息,请查看下面的链接。
内存过量使用会给我们带来更多麻烦。达到 CPU 限制将导致节流,达到内存限制会导致 Pod 被杀。见过 OOMkill(因内存不足而被杀死)吗?我们要说的就是这个意思。想要尽量减少这类状况?那就不要过量使用内存,并使用 Guaranteed QoS(Quality of Service)将内存请求设置为与限制相等,就像下面的例子那样。了解更多信息,请参考Henning Jacobs(Zalando)的演讲。
Burstable(容易带来更多 OOMkilled):
Guaranteed:
那么我们设置资源时有什么诀窍呢?
我们可以使用 metrics-server 查看 Pod(以及其中的容器)的当前 CPU 和内存使用情况。你可能已经启用它了。只需运行以下命令即可:
不过,这些只会显示当前的使用情况。要大致了解这些数据的话这就够用了,但我们到头来是希望能及时看到这些使用量指标(以回答诸如:昨天上午 CPU 使用量的峰值等问题)。为此我们可以使用 Prometheus 和 DataDog 等工具。它们只是从 metrics-server 接收度量数据并存储下来,然后我们就能查询和绘制这些数据了。
VerticalPodAutoscaler可以帮助我们自动化这一手动过程——及时查看 cpu/内存的使用情况,并基于这些数据再设置新的请求和限制。
有效利用计算资源不是一件容易的事情,就像不停地玩俄罗斯方块。如果我们发现自己花了大笔钱购买计算资源,可是平均利用率却很低(比如大约 10%),那么我们可能就需要 AWS Fargate 或基于 Virtual Kubelet 的产品。它们主要使用无服务器/按使用量付费的的计费模式,这对我们来说可能会更省钱。
2.liveness 和 readiness 探针
默认情况下,Kubernetes 不会指定任何 liveness 和 readiness 探针。有时它会一直保持这种状态……
但如果出现不可恢复的错误,我们的服务将如何重新启动呢?负载均衡器如何知道特定的 Pod 可以开始处理流量,或能处理更多流量呢?
人们通常不知道这两者间的区别。
如果探针失败,liveness 探针将重新启动 Pod
Readiness 探针失败时,会断开故障 Pod 与 Kubernetes 服务的连接(我们可以用
kubectl get endpoints检查这一点),并且直到该探针恢复正常之前,不会向该 Pod 发送任何流量。
它们两个都运行在整个 Pod 生命周期中。这一点是很重要的。
人们通常认为,readiness 探针只在开始时运行,以判断 Pod 何时 Ready 并可以开始处理流量。但这只是它的一个用例而已。
它的另一个用例是在一个 Pod 的生命周期中判断它是否因过热而无法处理太多流量(或一项昂贵的计算),这样我们就不会让它做更多工作,而是让它冷却下来;等到 readiness 探针成功,我们会再给它发送更多流量。在这种情况下(当 readiness 探针失败时),如果 liveness 探针也失败就会非常影响效率了。我们为什么要重新启动一个健康的、正在做大量工作的 Pod 呢?
有时候,不指定任何探针都比指定一个错误的探针要好。如上所述,如果 liveness 探针等于 readiness 探针,我们将遇到很大的麻烦。我们一开始可能只会指定readiness探针,因为liveness探针太危险了。
如果你的任何共享依赖项出现故障,就不要让任何一个探针失败,否则它将导致所有 Pod 的级联故障。我们这是搬起石头砸自己的脚。
3.在所有 HTTP 服务上启用负载均衡器
我们的集群中可能有很多 HTTP 服务,并且我们希望将这些服务对外界公开。
如果我们将 Kubernetes 服务以type: LoadBalancer的形式公开,那么它的控制器(取决于供应商)将提供并协调一个外部负载均衡器(不一定是 L7 的,更可能是 L4 lb);当我们创建很多这种资源时,它们可能会变得很昂贵(外部静态 ipv4 地址、计算、按秒计费……)。
在这种情况下,共享同一个外部负载均衡器可能会更好些,这时我们将服务以type: NodePort的形式公开。或者更好的方法是,部署 nginx-ingress-controller(或 traefik)之类的东西,作为公开给这个外部负载均衡器的单个 NodePort 端点,并基于 Kubernetes ingress 资源在集群中路由流量。
其他相互通信的集群内(微)服务可以通过 ClusterIP 服务和开箱即用的 DNS 服务发现来通信。注意不要使用它们的公共 DNS/IP,因为这可能会影响它们的延迟和云成本。
4.无 Kubernetes 感知的集群自动缩放
在集群中添加节点或删除节点时,不应该考虑一些简单的度量指标,比如这些节点的 CPU 利用率。在调度 Pod 时,我们需要根据许多调度约束来进行决策,比如 Pod 和节点的亲密关系(affinities)、污点(taints)和容忍(tolerations)、资源请求(resource requests)、QoS 等。让一个不了解这些约束的外部自动缩放器(autoscaler)来处理缩放可能会招来麻烦。
假设有一个新的 Pod 要被调度,但是所有可用的 CPU 都被请求了,并且 Pod 卡在了 Pending 状态。可是外部自动缩放器会查看当前的平均 CPU 使用率(不是请求数量),然后决定不扩容(不添加新的节点)。结果 Pod 也不会被调度。
缩容(从集群中删除节点)总是更难一些。假设我们有一个有状态的 Pod(连接了持久卷),由于持久卷(persistent volumes)通常是属于特定可用区域的资源,并且没有在该区域中复制,我们自定义的自动缩放器会删除一个带有此 Pod 的节点,而调度器无法将其调度到另一个节点上,因为这个 Pod 只能待在持久磁盘所在的那个可用区域里。Pod 将再次陷入 Pending 状态。
社区正在广泛使用cluster-autoscaler ,它运行在集群中,能与大多数主要的公共云供应商 API 集成;它可以理解所有这些约束,并能在上述情况下扩容。它还能搞清楚是否可以在不影响我们设置的任何约束的前提下优雅地缩容,从而节省我们的计算成本。
5.不要使用 IAM/RBAC 的能力
不要使用 IAM Users 永久存储机器和应用程序的秘钥,而要使用角色和服务帐户生成的临时秘钥。
我们经常看到这种情况,那就是在应用程序配置中硬编码访问(access )和密钥(secret),并在使用 Cloud IAM 时从来不轮换密钥。我们应该尽量使用 IAM 角色和服务帐户来代替 Users。
请跳过 kube2iam,直接按照Štěpán Vraný在这篇博文中介绍的那样,使用服务账户的 IAM 角色。
只有一个 annotation。没那么难做吧。
另外,当服务帐户或实例配置文件不需要admin和cluster-admin权限时,也不要给它们这些权限。这有点困难,尤其是在 k8s RBAC 中,但仍然值得一试。
6.Pod 的 self anti-affinities
某个部署有 3 个 Pod 副本正在运行,然后节点关闭了,所有的副本也都随之关闭。岂有此理?所有副本都在一个节点上运行?Kubernetes 难道不应该很厉害,并提供高可用性的吗?!
我们不能指望 Kubernetes 调度程序为我们的 Pod 强制使用 anti-affinites。我们必须显式地定义它们。
就是这样。这样就能保证 Pod 被调度到不同的节点上(这仅在调度时检查,而不是在执行时检查,因此需要requiredDuringSchedulingIgnoredDuringExecution )。
我们讨论的是不同节点名称上( topologyKey: "kubernetes.io/hostname" )的 podAntiAffinity,而不是不同可用区域的 podAntiAffinity。如果你确实需要很好的可用性水平,可以在这个主题上再深入做些研究。
7.无 PodDisruptionBudget
我们在 Kubernetes 上运行生产负载。我们的节点和集群必须不时升级或停用。PodDisruptionBudget(pdb)是一种用于在集群管理员和集群用户之间提供服务保证的 API。
请确保创建了pdb ,以避免由于节点耗尽而造成不必要的服务中断。
作为一个集群用户,我们可以告诉集群管理员:“嘿,我这里有个 zookeeper 服务,无论如何我都希望至少有 2 个副本是始终可用的”。
我在这篇博客文章中更深入地讨论了这个话题。
8.共享集群中有不止一个租户或环境
Kubernetes 命名空间不提供任何强隔离。
人们似乎期望,如果将非生产负载放到一个命名空间,然后将生产负载放到生产命名空间,那么这些负载之间就永远不会相互影响了。我们可以在某种程度上公平分配(比如资源的请求和限制、配额、优先级)并实现隔离(比如 affinities、tolerations、taints 或 nodeselectors),进而“物理地”分离数据平面上的负载,但这种分离是相当复杂的。
如果我们需要在同一个集群中同时拥有这两种类型的负载,那么就必须要承担这种复杂性。如果我们用不着局限在一个集群里,而且再加一个集群的成本更低时(比如在公共云上),那么应该将它们放在不同的集群中以获得更强的隔离级别。
9.externalTrafficPolicy: Cluster
经常看到这种情况,所有流量都在集群内路由到一个 NodePort 服务上,该服务默认使用 externalTrafficPolicy: Cluster 。这意味着在集群中的每个节点上都打开了 NodePort,这样我们可以任选一个来与所需的服务(一组 Pod)通信。
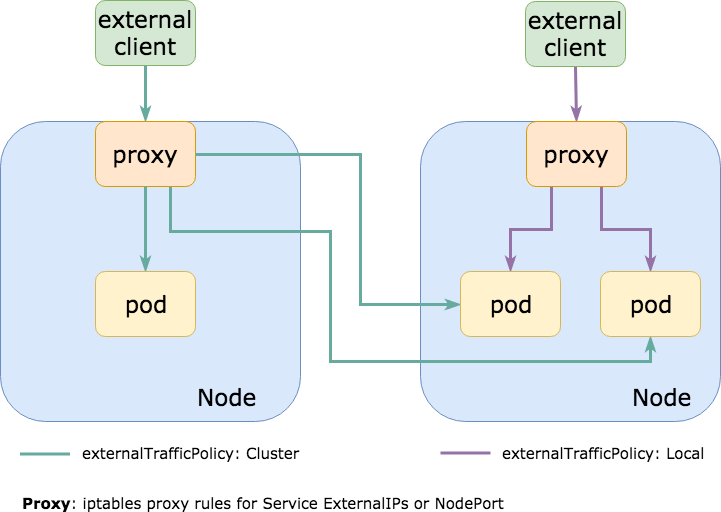
通常情况下,NodePort 服务所针对的那些 Pod 实际上只运行在这些节点的一个子集上。这意味着,如果我与一个没有运行 Pod 的节点通信,它将会把流量转发给另一个节点,从而导致额外的网络跳转并增加延迟(如果节点位于不同的 AZs 或数据中心,那么延迟可能会很高,并且会带来额外的出口成本)。
在 Kubernetes 服务上设置externalTrafficPolicy: Local,就不会在每个节点上都打开 NodePort,只会在实际运行 Pod 的节点上开启它。如果我们使用一个外部负载均衡器来检查它端点的运行状况(就像 AWS ELB 所做的那样),它就会只将流量发送到应该接收流量的节点上,这样就能改善延迟、减少计算开销、降低出口成本并提升健全性。
我们可能会有像 traefik 或 nginx-ingress-controller 之类的东西,被公开成 NodePort(或使用 NodePort 的负载均衡器)来处理入口 HTTP 流量路由,而这种设置可以极大地减少此类请求的延迟。
这里有一篇很棒的博客文章,更深入地讨论了externalTrafficPolicy和它们的权衡取舍。
10.把集群当宠物+控制平面压力过大
你有没有过这样的经历:给服务器取 Anton、HAL9000 或 Colossus 之类的名字(都是带梗的名称,译注),或者给节点随机生成 id,却给集群取个有含义的名称?
还可能是这样的经历:一开始用 Kubernetes 做概念验证,给集群取名"testing",结果到了生产环境还没给它改名,结果谁都不敢碰它?(真实的故事)
把集群当宠物可不是开玩笑的,我们可能需要不时删除集群,演练灾难恢复并管理我们的控制平面。害怕触碰控制平面不是个好兆头。Etcd 挂掉了?好嘞,我们遇到大麻烦。
反过来说,控制平面也不要用过头了。也许随着时间的流逝,控制平面变慢了。这很可能是因为我们创建了很多对象而没有轮换它们(使用 helm 时常见的情况,它的默认设置不会轮换 configmaps/secrets 的状态,结果我们在控制平面中会有数千个对象),或者是因为我们不断从 kube-api(用于自动伸缩、CI/CD、监视、事件日志、控制器等)中删除和编辑了大量内容。
另外,请检查托管 Kubernetes 提供的“SLAs”/SLOs 和保证。供应商可能会保证控制平面(或其子组件)的可用性,但不能保证发送给它的请求的 p99 延迟水平。换句话说,就算我们kubectl get nodes后用了 10 分钟才得到正确结果,也没有违反服务保证。
附赠一条:使用 latest 标签
这一条是很经典的。我觉得最近它没那么常见了,因为大家被坑的次数太多,所以再也不用 :latest ,开始加上版本号了。这下清静了!
ECR有一个标签不变性的强大功能,绝对值得一试。
总结
别指望所有问题都能自动解决——Kubernetes 不是银弹。即使是在Kubernetes上,一个糟糕的应用程序还会是一个糟糕的应用程序(实际上,甚至还可能更糟糕)。如果我们不够小心,最后就会遇到一系列问题:太过复杂、压力过大、控制平面变慢、没有灾难恢复策略。不要指望多租户和高可用性是开箱即用的。请花点时间让我们的应用程序云原生化。
英文原文:
10 most common mistakes using kubernetes

技术是文明进步的力量

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论