

Embedding 向量作为推荐算法中必不可少的部分,主要有四个运用方向(前 3 个引用于王喆老师):
在深度学习网络中作为 Embedding 层,完成从高维稀疏特征向量到低维稠密特征向量的转换(比如 wide&deep,DIN 等模型);
作为预训练的 Embedding 特征向量,与其他特征向量连接后一同输入深度学习网络进行训练,比如 FNN 模型;
通过计算用户和物品的 Embedding 相似度,Embedding 可以直接作为推荐系统或计算广告系统的召回层或者召回方法之一(比如 Youtube 推荐模型)
通过计算用户和物品的 Embedding,将其作为实时特征输入到推荐或者搜索模型中(比如 Airbnb 的 embedding 应用)。
本文将着重梳理一下 embedding 在 3 和 4 上的应用。
1.Item2vec: Neural Item Embedding for Collaborative Filtering
基本上参照 google 的 word2vec 方法,把 item 视为 word,用户的行为序列视为一个集合,item 间的共现为正样本,并按照 item 的频率分布进行负样本采样。缺点就是没有建模用户对不同 item 的喜欢程度高低。
Airbnb: Real-time Personalization using Embeddings for Search Ranking at Airbnb
共训练了三个 embedding,包括 Listing Embedding、User Type Embedding 和 Listing Type Embedding,这里 Listing 可理解为一个商品 item。其中 Listing Embedding 对应的是用户的短期兴趣偏好,通过用户在 Session 中的点击序列训练得到。其中用到了一些 trick,比如在有预定的 session 中,在 loss 函数中加入预定 listing;另外可以随机加入几个同目的地的房源作为负样本。最终的目标函数为:
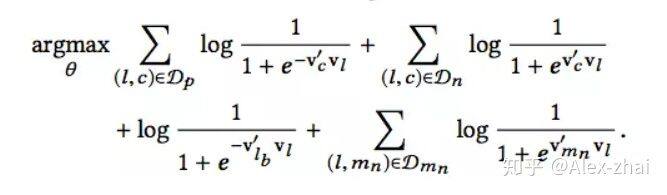
那么怎么解决冷启动问题呢?对于新加入的房源,可以从已有 embedding 的房源中,选择 3 个同种类且距离最近(但是要在半径 10miles 以内)的 3 个房源,并用其 embedding 的平均值来作为新房源的 embedding。
另外为了建模用户的长期兴趣,可以拿用户长期的 booking session 序列,但是 booking session 数据是很稀疏的。解决方案是将 listing 和用户进行分类。就可以产生如下的序列:
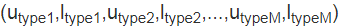
然后基于 word2vec 方法去训练得到 user type 和 item type 的 embedding 表示。
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
可看作是 deep-walk 算法的改进,deep-walk 对于出现次数很少甚至没有用户交互过的商品是学习不到很好的 embedding 表示的。本文使用基于 side information(比如商品品牌、店铺名、类别)的图嵌入学习方法。
首先介绍的是 base 的 Graph Embedding 方法,过程如下图:
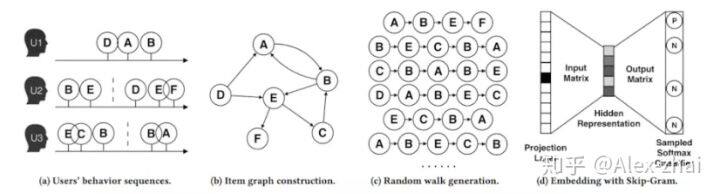
然后是 Graph Embedding with Side information,主要就是加入了 side information 来解决冷启动问题。在加入 Side information 之后,商品表示为一种 aggregated embeddings:
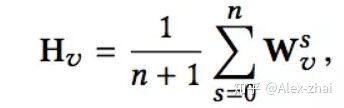
其中 W0 代表 item embedding,W1,Wn 代表每种 Side information 对应的 embedding。
最后介绍的是 Enhanced Graph Embedding with Side information ,不同的 side information 在最终的 aggregated embeddings 中所占的权重应该是不同的,比如一个购买了 iphone 的用户,倾向于查看 mac 或者 ipad,这是因为苹果这个品牌的影响力很大。此时 aggregated embeddings 计算公式为:
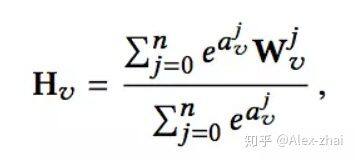
Deep Neural Networks for YouTube Recommendations
主要在候选集生成阶段使用了下面的模型。
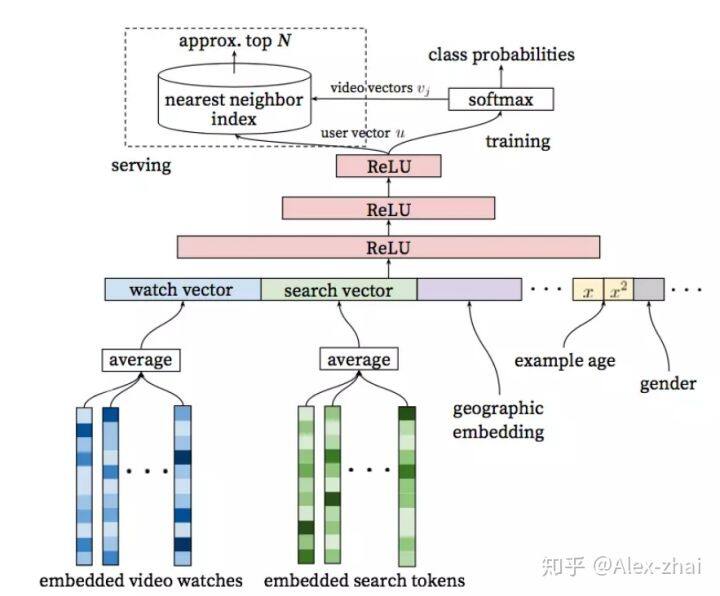
在上面模型进行 serving 的过程中,没有直接使用整个模型去做 inference,而是直接使用 user embedding 和 item embedding 去做相似度的计算。其中 user embedding 是模型最后一层 mlp 的输出,vedio embedding 则直接使用的是 softmax 的权重。
相关文章:
https://zhuanlan.zhihu.com/p/24339183?refer=deeplearning-surfing
https://zhuanlan.zhihu.com/p/55149901
https://zhuanlan.zhihu.com/p/57313656
https://www.jianshu.com/p/229b686535f1
https://zhuanlan.zhihu.com/p/52169807
本文转载自 Alex-zhai 知乎账号。
原文链接:
https://zhuanlan.zhihu.com/p/78144408

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论