

引言
为什么数据流管理如此重要?react 的核心思想就是:UI=render(data),data 就是我们说的数据,render 是 react 提供的纯函数,所以用户界面的展示完全取决于数据层。
这篇文章希望能用最浅显易懂的话,将 react 中的数据流管理,从自身到借助第三方库,将这些概念理清楚。我会列举几个当下最热的库,包括它们的思想以及优缺点,适用于哪些业务场景。
这篇文章不是教程,不会讲如何去使用它们,更不会一言不合就搬源码,正如文章标题所说,只是浅谈,希望读者在读完以后就算原先没有使用过这些库,也能大致有个思路,知道该如何选择性地深入学习。
在本文正式开始之前,我先试图讲清楚两个概念,状态和数据:
我们都知道,react 是利用可复用的组件来构建界面的,组件本质上是一个有限状态机,它能够记住当前所处的状态,并且能够根据不同的状态变化做出相应的操作。在 react 中,把这种状态定义为 state,用来描述该组件对应的当前交互界面,表示当前界面展示的一种状况,react 正是通过管理状态来实现对组件的管理,当 state 发生变更时,react 会自动去执行相应的操作:绘制界面。
所以我们接下来提到的状态是针对 react component 这种有限状态机。而数据就广泛了,它不光是指 server 层返回给前端的数据,react 中的状态也是一种数据。当我们改变数据的同时,就要通过改变状态去引发界面的变更。
我们真正要关心的是数据层的管理,我们今天所讨论的数据流管理方案,特别是后面介绍的几种第三方库,不光是配合 react,也可以配合其他的 View 框架(Vue、Angular 等等),就好比开头提到的那个公式,引申一下:UI =X(data),但今天主要是围绕 react 来讲的,因此我们在说 react 的状态管理其实和数据流管理是一样的,包括我们会借助第三方库来帮助 react 管理状态,希望不要有小伙伴太纠结于此。
一、react 自身的数据流管理方案
我们先来回顾一下,react 自身是如何管理数据流的(也可以理解为如何管理应用状态):
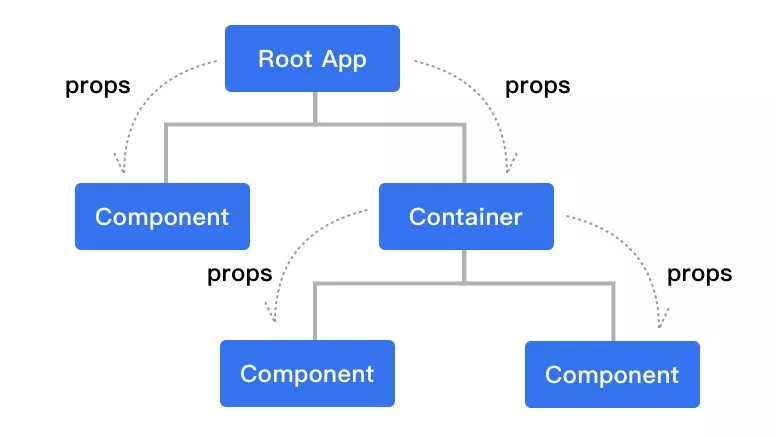
react 是自上而下的单向组件数据流,容器组件 &展示组件(也叫傻瓜组件 &聪明组件)是最常用的 react 组件设计方案,容器组件负责处理复杂的业务逻辑以及数据,展示组件负责处理 UI 层,通常我们会将展示组件抽出来进行复用或者组件库的封装,容器组件自身通过 state 来管理状态,setState 更新状态,从而更新 UI,通过 props 将自身的 state 传递给展示组件实现通信。
这是当业务需求不复杂,页面较简单时我们常用的数据流处理方式,仅用 react 自身提供的 props 和 state 来管理足矣,但是如果稍微增加一点复杂度呢,比如当我们项目中遇到这些问题:
1)如何实现跨组件通信、状态同步以及状态共享?
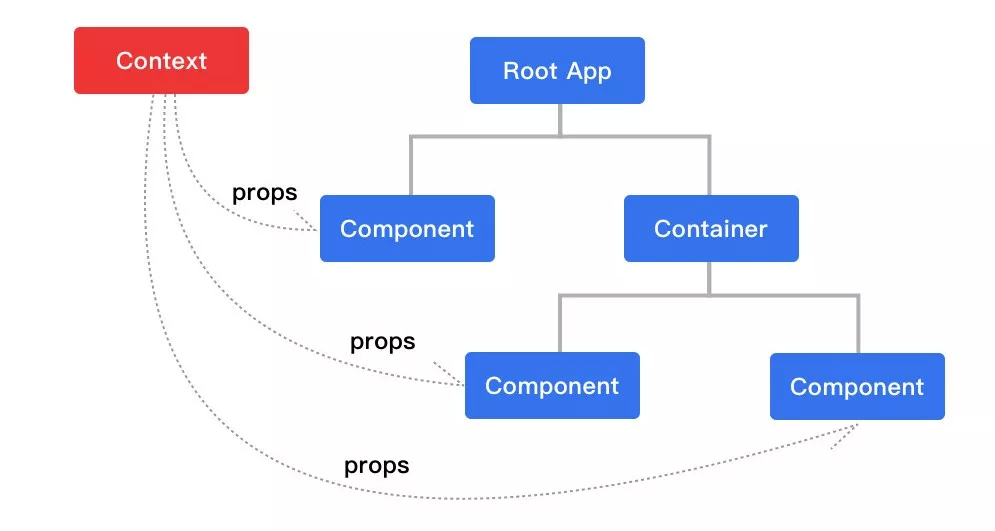
react V16.3 以前,通过状态提升至最近的共同父组件来实现。(虽然有官方提供的 contextAPI,但是旧版本存在一个问题:看似跨组件,实则还是逐级传递,如果中间组件使用了 ShouldComponentUpdate 检测到当前 state 和 props 没有变化,returnfalse,那么 context 就会无法透传,因此 context 没有被官方推荐使用)。
react V16.3 版本以后,新版本 context 解决了之前的问题,可以轻松实现,但依然存在一个问题,context 也是将底部子组件的状态控制交给到了顶级组件,但是顶级组件状态更新的时候一定会触发所有子组件的 re-render,那么也会带来损耗。(虽然我们可以通过一些手段来减少重绘,比如在中间组件的 SCU 里进行一些判断,但是当项目较大时,我们需要花太多的精力去做这件事)
2)如何避免组件臃肿?
当某个组件的业务逻辑非常复杂时,我们会发现代码越写越多,因为我们只能在组件内部去控制数据流,没办法抽离,Model 和 View 都放在了 View 层,整个组件显得臃肿不堪,业务逻辑统统堆在一块,难以维护。
3)如何让状态变得可预知,甚至可回溯?
当数据流混乱时,我们一个执行动作可能会触发一系列的 setState,我们如何能够让整个数据流变得可“监控”,甚至可以更细致地去控制每一步数据或状态的变更?
4)如何处理异步数据流?
react 自身并未提供多种处理异步数据流管理的方案,仅用一个 setState 已经很难满足一些复杂的异步流场景;
如何改进?
这个时候,我们可能需要一个真正的数据流管理工具来帮助 react 了,我们希望它是真正脱离 react 组件的概念的,从 UI 层完全抽离出来,只负责管理数据,让 react 只专注于 View 层的绘制。
那这也是为什么我们需要使用那些第三方数据流管理工具的原因,接下来我们就来了解一些当前社区比较热门的数据流管理工具。
二、redux
我直接跳过了 flux 来说 redux,主要是因为 redux 是由 flux 演变而来,可以说是 flux 的升级加强版,flux 具备的优势 redux 也做到了。
redux 提供了哪些?
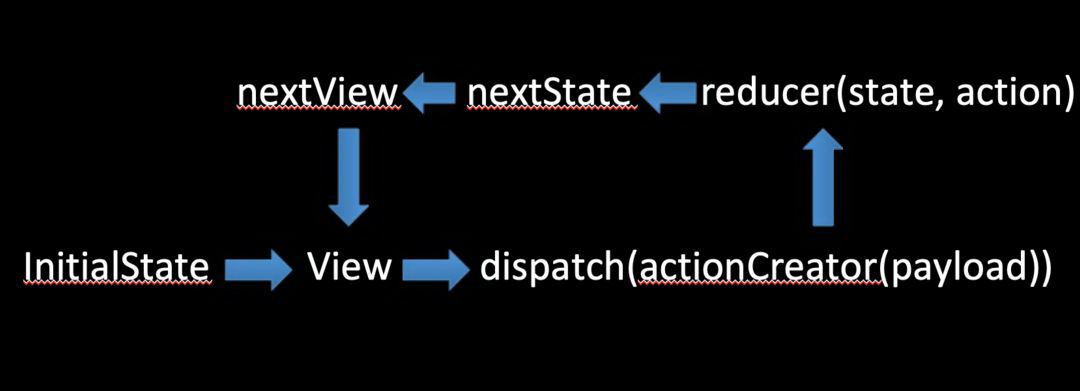
1)store:提供了一个全局的 store 变量,用来存储我们希望从组件内部抽离出去的那些公用的状态;
2)action:提供了一个普通对象,用来记录我们每一次的状态变更,可日志打印与调试回溯,并且这是唯一的途径;
3)reducer:提供了一个纯函数,用来计算状态的变更;
为什么需要 redux?
很多人在用了一段时间的 redux 之后,最大的感想就是,redux 要写大量的模板代码,很麻烦,还不如只用 react 来管理。特别是在 react 的新 context 推出以后,许多人更是直接弃用了 redux,甚至觉得 redux 已死。如果说旧版的 context 的弊端,我们通过 redux 配合 react-redux 来实现跨组件的状态通信同步等问题,那确实新版本的 context 可以替换掉这个功能点,但如果你的项目中仅仅是用 redux 做这些,那思考一下,你是否真的需要 redux?也许从一开始你就不需要它。
(虽然新版的 context 功能强大,但是依然是通过一个新的容器组件来替我们管理状态,那么通过组件管理状态的问题依旧会存在,Consumer 是和 Provider 一一对应的,在项目复杂度较高时,可能会出现多个 Provider,更多个 Consumer,甚至会一个 Consumer 需要对应多个 Provider 的传值等一系列复杂的情况,所以我们依然要谨慎使用)
redux 的核心竞争力
1)状态持久化:globalstore 可以保证组件就算销毁了也依然保留之前状态;
2)状态可回溯:每个 action 都会被序列化,Reducer 不会修改原有状态,总是返回新状态,方便做状态回溯;
3)Functional Programming:使用纯函数,输出完全依赖输入,没有任何副作用;
4)中间件:针对异步数据流,提供了类 express 中间件的模式,社区也出现了一大批优秀的第三方插件,能够更精细地控制数据的流动,对复杂的业务场景起到了缓冲地作用;

与其说是 redux 来帮助 react 管理状态,不如说是将 react 的部分状态移交至 redux 那里。redux 彻头彻尾的纯函数理念就表明了它不会参与任何状态变化,完全是由 react 自己来完成。只不过 redux 会提供一套工具,react 照着说明书来操作罢了。
所以这注定了想要接受 redux,就必须按照它的规矩来做,除非你不愿意接受这种 FP 的模式。这种模式有利有弊,有利就是在一个大型的多人团队中,这种开发模式反而容易形成一种规约,让整个状态流程变得清晰,弊端就是对于小规模团队,尤其是着急发布上线的,这种繁重的代码模板无疑是一种负担。
redux 的缺点:
1)繁重的代码模板:修改一个 state 可能要动四五个文件,可谓牵一发而动全身;
2)store 里状态残留:多组件共用 store 里某个状态时要注意初始化清空问题;
3)无脑的发布订阅:每次 dispatch 一个 action 都会遍历所有的 reducer,重新计算 connect,这无疑是一种损耗;
4)交互频繁时会有卡顿:如果 store 较大时,且频繁地修改 store,会明显看到页面卡顿;
5)不支持 typescript;
关于如何优化,网上有很多优秀的案例,redux 官方也提供了很多方法,这里不再赘述。redux 未来不会有太大的变化,那些弊端还是会继续保留,但是这依然不会妨碍忠爱它的用户去使用它。
如果说 redux 那种强硬的函数式编程模式让很多人难以接受,那么当他们开始 mobx 的使用的时候,无疑是一种解脱。
三、mobx
最开始接触 mobx 也是因为 redux 作者 DanAbramov 的那句:Unhappywith redux?try mobx,我相信很多人也是因为这句话而开始了解学习并使用它的。
下面列举一些 mobx 的优势(和 redux 进行一个对比)
1)redux 不允许直接修改 state,而 mobx 可随意修改;
2)redux 修改状态必须走一套指定的流程较麻烦,而 mobx 可以在任何地方直接修改(非严格模式下);
3)redux 模板代码文件多,而 mobx 非常简洁,就一个文件;
4)redux 只有一个 store,state orstore 难以取舍,而 mobx 多 store,你可以把所有的 state 都放入 store 中,完全交给 mobx 来管理,减少顾虑;
5)redux 需要对监听的组件做 SCU 优化,减少重复 render;而 mobx 都是 SmartComponent,不用我们手动做 SCU;
mobx 的设计思想:

说了这么多,如果你是第一次了解 mobx,是不是听着就感觉很爽!没错,这就是 mobx 的魅力,那它是如何实现这些功能的呢?
这里以 mobx 5 版本为例,实际上它是利用了 ES6 的 proxy 来追踪属性(旧版本是用 Object.defineProperty 来实现的)通过隐式订阅,自动追踪被监听的对象变化,然后触发组件的 UI 更新。
如果说 redux 是把要做的事情都交给了用户,来保证自己的纯净,那么 mobx 就是把最简易的操作给了用户,其它的交给 mobx 内部去实现。用户不必关心这个过程,Model 和 View 完全分离,我们完全可以将业务逻辑写在 action 里,用户只需要操作 Observabledata 就行了。
Observerview 会自动做出响应,这就是 mobx 主打的响应式设计,但是编程风格依然是传统的面向对象的 OO 范式。(熟悉 Vue 的朋友一定对这种响应式设计不陌生,Vue 就是利用了数据劫持来实现双向绑定,其实 React +Mobx 就是一个复杂点的 Vue,Vue 3 版本一个重大改变也是将代理交给了 proxy)
刚刚 mobx 的优势说得比较多了,这边再总结一下:
1)代码量少;
2)基于数据劫持来实现精准定位(真正意义上的局部更新);
3)多 store 抽离业务逻辑(Model View 分离);
4)响应式性能良好(频繁的交互依然可以胜任);
5)完全可以替代 react 自身的状态管理;
6)支持 typescript;
但是 mobx 真的这么完美吗,当然也有缺陷:
1)没有状态回溯能力:mobx 是直接修改对象引用,所以很难去做状态回溯;(这点 redux 的优势就瞬间体现出来了)
2)没有中间件:和 redux 一样,mobx 也没有很好地办法处理异步数据流,没办法更精细地去控制数据流动;(redux 虽然自己不做,但是它提供了 applyMiddleware!)
3)store 太多:随着 store 数的增多,维护成本也会增加,而且多 store 之间的数据共享以及相互引用也会容易出错
4)副作用:mobx 直接修改数据,和函数式编程模式强调的纯函数相反,这也导致了数据的很多未知性
其实现在主流的数据流管理分为两大派,一类是以 redux 为首的函数式库,还有一类是以 mobx 为首的响应式库,其实通过刚刚的介绍,我们会发现,redux 和 mobx 有一个共同的短板,那就是在处理异步数据流的时候,没有一个很好的解决方案,至少仅仅依靠自身比较吃力,那么接下来给大家介绍一个处理异步数据流的高手:rxjs。
四、rxjs
我相信很多人听说过 rxjs 学习曲线异常陡峭,是的,除了眼花缭乱的各类操作符(目前 rxjs V6 版本有 120+个),关键是它要求我们在处理事务的时候要贯彻“一切皆为流”的理念,更是让初学者难以理解。
这一小节并不能让读者达到能够上手使用的程度,正如文章开头所说,希望读者(新手)能对 rxjs 有一个新的认知,知道它是做什么的,它是如何实现的,它有哪些优势,我们如何选择它,如果感兴趣还需要私下花大量时间去学习掌握各种操作符,但我也会尝试尽可能地相对于前两个说得更细致一些。
在开始介绍 rxjs 之前,我们先来简单地聊聊什么是响应式编程?我以一个很简单的小例子来看:a + b = c。
如果站在传统的命令式编程的角度来看这段公式:c 的值完全依赖于 a 和 b,这时候我们去改变 a 的值,那我们就需要再去手动计算 a + b 的值,a、b 和 c 是相互依赖的。
那么如果站在响应式编程的角度来看,这个公式又会变成这样:c := a + b,a 和 b 完全不关心 c 的值,c 也完全不关心等式那边是 a 或者 b,或者还有什么 d,e,f。。。等式右边改变值了,左边会自动更改数值,这就是响应式编程的思维方式。
我们再来看前端的框架历史,传统命令式编程的代表:jQuery,在过去我们是如何绘制一个页面的?我们会用 jQuery 提供的一套 API,然后手动操作 Dom 来进行绘制,很精准,但是很累,因为完全靠手动操作,且改动时性能损耗较大,开发者的注意力完全在“如何去绘制”上面了。
那我们再来看响应式编程的 react,它是如何来实现的?
开发者根本不用关心界面如何绘制,只要告诉 react 我们希望页面长什么样子,就可以了,剩下的交给 react,react 就会自动帮我们绘制界面,还记得开头时的那个核心思想吗:UI =render(data),我们只要操作 data 就可以了,页面 UI 会自动作出响应,而且我们一切的操作都是基于内存之中,不会有较大的性能损耗,这就是 react 响应式编程的精髓,也是为何它叫作 react。
回到我们的 rxjs 上,rxjs 是如何做到响应式的呢?多亏了它两种强大的设计模式:观察者模式和迭代器模式;简单地介绍一下:
1)观察者模式:
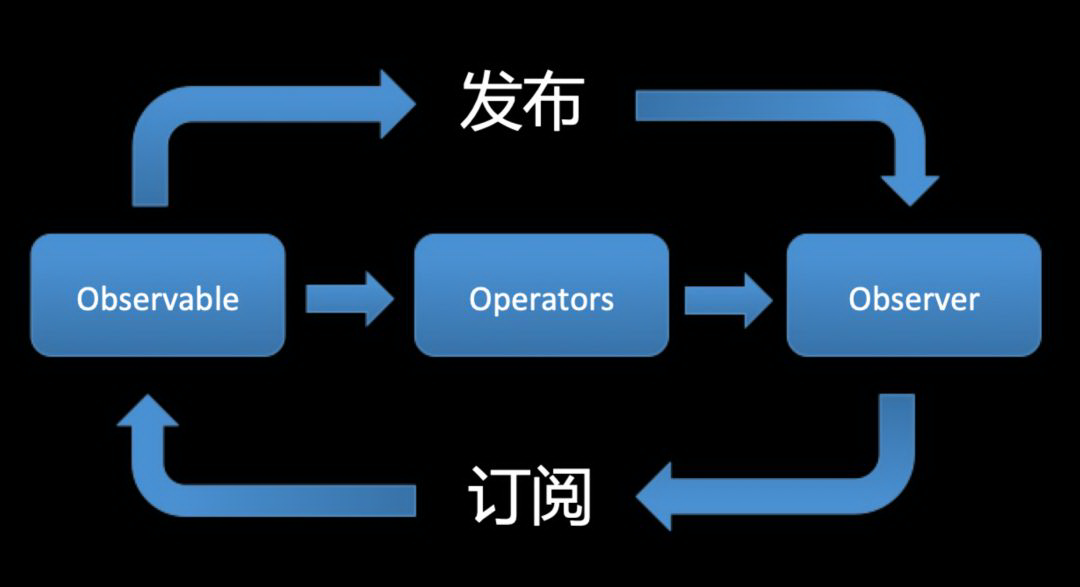
在观察者模式中,有两个重要的角色:Observable 和 Observer,熟悉 mobx 的同学对这个一定不陌生(所以我建议想要学习 rxjs 的同学,如果对 mobx 不熟悉,可以先学习一下 mobx,然后再学习 rxjs,这样会更容易理解一些)。
就是可观察对象和观察者,可观察对象(Observable)也就是事件发布者,负责产生事件,而观察者(Observer)也就是事件响应者,负责对发布的事件作出响应,但是如何连接一个发布者和响应者呢?
通过订阅的形式,也就是 subscribe 方法(这也类似于 redux 的 store.subscribe),而在订阅之前,他们两者是毫无关联的,无论 Observable 发出多少事件,Observer 也不会做出任何响应,同样,当这种订阅关系中断时也不会。
2)迭代器模式:
在这里要先引出一个新的概念:拉取(pull)和推送(push),rxjs 官方这两种协议有更详细的解释,我这里就直接引用一下:

拉取和推送实际上对于观察者来说就是一个主动与被动的区别,是主动去获取还是被动地接收。在 rxjs 中,作为事件响应者(消费者)的 Observer 对象也有一个 next 属性(回调函数),用来接收从发布者那里“推”过来的数据。
(站在开发者的角度,我们一定是希望消息是被动地接收,因为我们倡导的就是通过操作 data 数据层,让 View 层进行一个响应,那么这里 data 数据层一定是事件发布者,而 View 层就是事件响应者,每当 data 数据层发生变化时,都会主动推送一个值给 View 层,这才符合真正意义上的响应式编程,而 rxjs 做到了!)
如何配合 react?
如果说 redux 和 mobx 的出现或多或少是因为 react 的存在,那么不同的是 rxjs 和 react 并没有什么关联,关于 rxjs 的历史这里不多说,感兴趣的可以了解一下 ReactiveExtension,rxjs 只是响应式编程在 JavaScript 中的应用。
那么如何帮助 react 实现状态管理呢,我们只需要将组件作为事件响应者,然后在 next 回调里定义好更新组件状态的动作 setState,当接收到数据推送时,就会自动触发 setState,完成界面更新,这其实有点类似于 mobx 做的事情。(很多人在 react 项目中并没有完全只使用 rxjs,而是用了这个 redux-observable 中间件,利用 rxjs 的操作符来处理异步 action)
除了响应式编程的魅力,rxjs 还有什么优势呢?
1)纯函数:rxjs 中数据流动的过程中,不会改变已经存在的 Observable 实例,会返回一个新的 Observable,没有任何副作用;
2)强大的操作符:rxjs 又被称为 lodash forasync,和 lodash 一样,拥有众多强大的操作符来操作数据流,不光是同步数据,特别是针对各种复杂的异步数据流,甚至可以多种事件流组合搭配,汇总到一起处理;
3)更独立:rxjs 并不依赖于任何一个框架,它可以任意搭配,因为它的关注点完全就是在于数据流的处理上,而且它更偏底层一些
那 rxjs 有哪些缺点呢?
1)学习曲线陡峭:光是这一点就已经让大多数人止步于此;
2)事件流高度抽象:用 rxjs 的用户反馈一般都是两种极端情况,用得好的都觉得这个太厉害了,用得不好的都觉得感觉有点麻烦,增加了项目复杂度。
五、结语
最后,总结一下各类的适用场景:
1)当我们项目中复杂程度较低时,建议只用 react 就可以了;
2)当我们项目中跨组件通信、数据流同步等情况较多时,建议搭配 react 的新 context api;
3)当项目复杂度一般时,小规模团队或开发周期较短、要求快速上线时,建议使用 mobx;
4)当项目复杂度较高时,团队规模较大或要求对事件分发处理可监控可回溯时,建议使用 redux;
5)当项目复杂度较高,且数据流(尤其是异步数据)混杂时,建议使用 rxjs;
其实回顾全篇,我没有提到一个关键点是,各个库的性能对比如何。其实它们之间一定是有差异的,但是这点性能差异,相对于 react 自身组件设计不当而导致的性能损耗来说,是可以忽略的。
如果你现在的项目觉得性能较差或者页面卡顿,建议先从 react 层面去考虑如何进行优化,然后再去考虑如何优化数据管理层。关于上面提到的三个数据流管理工具,有利有弊,针对弊端,网上也有一大批优秀的解决方案和改进,感兴趣的读者可自行查阅。
作者介绍:
颜陈宇,携程玩乐高级前端开发工程师,前端架构组成员,目前主要负责玩乐国际化项目的 App、H5 以及 Online 三端技术架构。热衷于 react 技术栈,喜欢阅读和分享。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/ii6H6mhe2OAUf7RquVxN8g

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论