

本篇文章选自数据库内核杂谈系列文章。
在上一篇文章的末尾,我们留了一个坑。虽然通过列存,能够避免读取不必要的数据(没使用的列)来提高查询速度,但是对于下面这类点查询(point query),还能不能进一步优化呢?
答案是肯定的,解决方案就是今天的主题 – 索引(index)。
索引这个概念在我们日常生活中很常见。比如在很多书籍的最后,都配有关键字索引。它能帮助你快速地找到某个关键字所在的书页。试想一下,如果没有索引,想要查询某个关键字所在的章节和书页,可能唯一的办法就是一页一页翻书直到找到为止。索引大大提高了查询的速度!
数据库的索引也正是为了解决这类问题:索引通过引入冗余的数据存储(类比书籍最后的索引章节),以此来提高查询语句的速度。和上一期的结构类似,相较于列举不同索引类型的分类法,我们依然从解决问题的角度来看不同类型的索引是为了解决哪些查询而演化而来的。
回到上面这个点查询语句,你能想到什么办法来优化执行?我们沿用上一期 titanic_survivor 的数据(下图),一起来看。
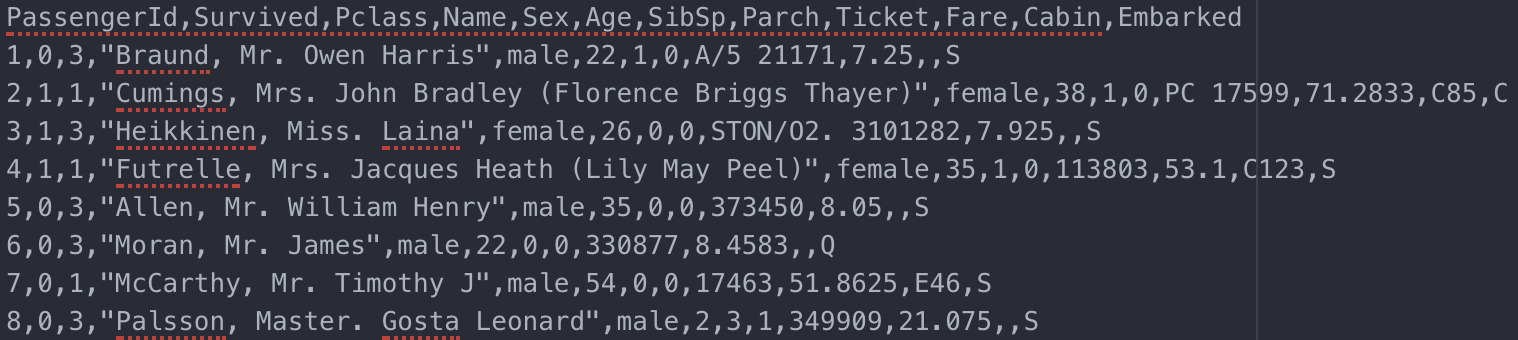
titanic_survivor
读者可能很容易就会想到,我们可以建立一个哈希表(HashMap)。哈希表的键(key)存储 age 的值,哈希表的值(value)存储所有 age 为对应键值的 row 在存储系统中的相对位置(如果使用 csv 文件存储,它就是 row 的行号。如果用字节流存储数据,它就是 row 对应于文件中的 offset)。下图是对于 titanic_survovior 的 age 列作索引。

hash_table_age
有了这样一个哈希表,当需要查询年龄是 35 的幸存者时,只需要读取行 4 和行 5 的数据即可。(可能对于 csv 文件比较难描述这类优化。设想当数据文件是按字节流存储时,可以用随机文件读取的 API 来读取很小一部分数据) 虽然随机读取的平均效率远低于顺序读取(因为文件系统需要寻道 seek),但相比于读取 2 行数据和一百万行数据,前者的速度毋庸置疑得快。
这样一个哈希表,就引出了第一类索引,哈希索引(Hash Index): 根据需要索引的列(并不限制为一个列,可以是多个列的组合),建立一个哈希表。读取数据时,先根据索引列的键值找到对应的数据位置,然后读取相应数据。
本文不是数据结构 101,就不具体讨论如何实现哈希函数,解决键冲突,对哈希表进行扩容缩容等的问题了。稍微聊一些工程实践中的细节:选择哈希函数的指标,肯定是速度越快越好。在输入和输出值域相同的情况下,冲突概率越低越好。下面列举了一些开源且受欢迎的哈希函数实现,有兴趣的同学可以深入学习:
MurmurHash (2008):
Google CityHash (2011):
https://opensource.googleblog.com/2011/04/introducing-cityhash.html
Google FarmHash (2014):
https://opensource.googleblog.com/2014/03/introducing-farmhash.html
CLHash (Carry-less) (2016):
有同学提出疑问,提到哈希算法, 最先想到的就是 MD5, SHA 等的算法,为什么这里并没有提及。因为这类算法被称为密码哈希算法(当然 MD5 已经多次被证明不安全了,请不要继续用于加密。。)。为了追求安全性,这类算法具备特别的属性,比如难以从一个已知的哈希值去逆推原始的消息以及雪崩效应(Avalanche effect): 即输入发生微小变化也会导致输出的不可区分性改变,从而牺牲了哈希运算的效率。建立哈希索引时并不需要这类安全属性,因此会选择性能更高的哈希算法。
著名的开源数据库 PostgreSQL 就支持哈希索引,生成语句如下:
但在对应的文档中,却明确指出了不建议使用哈希索引。至于原因,我们先卖个关子,过一会再详解。总结一下,为了提高点查询的效率,我们引入了第一类索引,哈希索引。
哈希索引虽好,却也不是万能的。比如把查询条件从点查询改为范围查询,如下所示:
有同学说,依然可以用哈希索引解决,只要做 10 次哈希索引的查询即可。那我做得再绝一些:
或者干脆把 age 换成浮点类型。如此,哈希索引是万万没辙了吧。
面对这类查询,有什么方法可以提高速度呢?有读者会想到,如果把要查询的列(此为 age)进行排序,然后进行二分查找来定位,依次扫描列中满足条件的数据,就可以避免全文件扫描了。沿用上面的示例,我们对 titanic_survivor 的 age 列排序,并且纪录相应的行号, 如下图所示:

sorted_age_list
假设需要查询年龄在 20 至 40 岁之间的幸存者,可以通过二分查找先定位到年龄 22,然后依次顺序读取之后 26,35 和 38 岁的对应行的数据,当搜索至 54 岁时停止即可。概括一下方法:对相关列进行排序,用二分查找来快速定位然后顺序查询。二分查找 1 至 100 万中的某个数需要 20 次查询(2^20 约等于 100 万),有什么方法可以再进一步提高效率?于是我们引出第二个使用的数据结构 B 树和 B+树(B - tree, B+ - Tree)。
关于 B 树和 B+树的具体实现细节,请参考相关数据结构书籍资料,这里就不赘述了。简单而言,B 树相当于把二分查找变成了 N 分查找,假设 N 为 100,那查找范围为(1, 100 万)就只需要 3 次分叉了(100^3 = 100 万)。B+树和 B 树的区别就在于 B 树在非叶节点也会存储数据而 B+树仅在页节点存储数据。下图示例为 B+树。
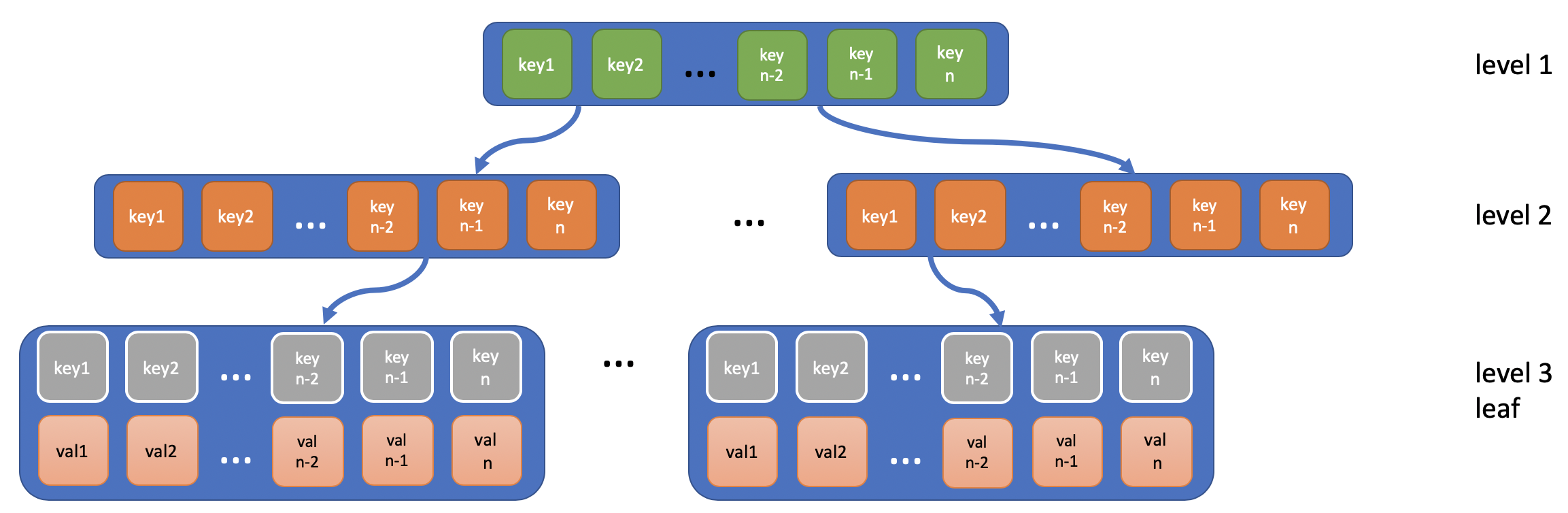
B+ tree
这类索引就称之为 B 树索引。B 树和 B+树通过引入有很多分枝的树节点来提高定位速度以此来提高整体查询速度,算得上是空间换时间的方法。同样,在工程中还有很多可优化的细节。比如对于 B+树,只有页节点存储具体的数据信息,内节点和根节点仅仅是用于快速定位,因此衍生出了合并前缀(prefix compression)以及删除无用后缀(suffix truncation)等的优化方法。再举个常见的优化示例,B+树的页节点原本用来存储对应列值的行在数据文件中的相对位置,所以读取完索引后还需要根据相对位置去数据文件中读取数据。但对于固定的查询语句,可以提前知道其他哪些列也会经常被查询,把这些列的数据直接存储在索引中,进一步用空间来省去读取数据文件的时间。比如,如果我们想要更进一步优化下面这个语句:
就可以把性别的信息存放在索引中。对应的 SQL 语句如下
为了能够进一步优化范围查询,我们引出了第二类索引,B 树索引。现在可以聊聊上面埋下的伏笔为什么 Postgres 并不建议使用哈希索引了。贴出原文(From Postgres 7.2 Doc):
Because of the limited utility of hash indexes, a B-tree index should generally be preferred over a hash index. We do not have sufficient evidence that hash indexes are actually faster than B-trees even for = comparisons. Moreover, hash indexes require coarser locks.
可见,虽然从理论上讲,对于点查询,哈希索引应该更快,而且存储空间相对 B 树索引更少。但是通过工程中的优化,可以让 B 树索引在点查询中也毫不逊色。聊完了哈希索引和 B 树索引,留一个思考题给读者:抛开性能不说,用 B 树索引读取数据还能带来一个隐形的好处,猜猜是什么好处?我会把答案留在本文的最后。
说了这么多 B 树索引的优势,它有什么缺陷吗?B 树的实现,增加和删除数据会牵涉到节点的分离和合并,是比较复杂的(没有同学在面试过程中遇到要求实现 B 树这类的变态问题吧)。尤其是在高并发的环境下,对于节点的操作需要加锁, 会进一步导致速度变慢。有没有办法进一步改进吗?有!有一种比较偏门的数据结构 – 跳表(skip list)比 B 树在这方面就更优秀。跳表的实现是一个多层次的链表,底部链表和 B 树一样是一列有序的键值对,通过在上层加入更松散的有序链表来支持跳跃查询(命名的由来)。下图给出了跳表示例。
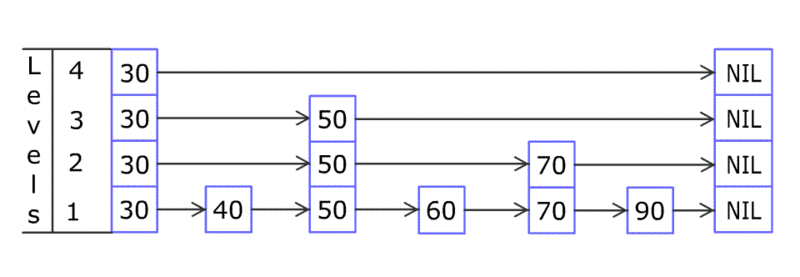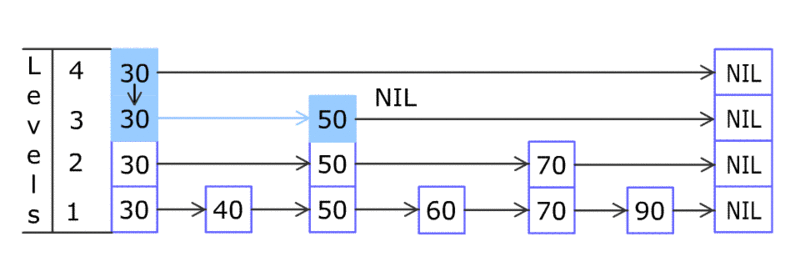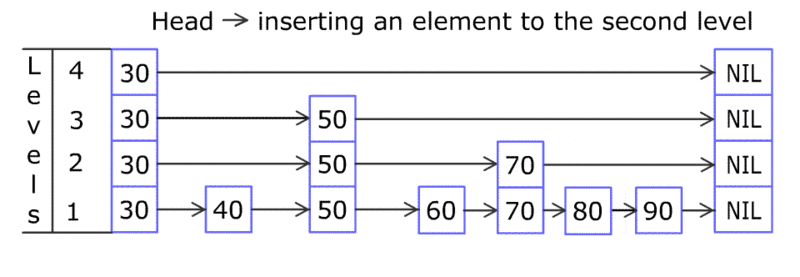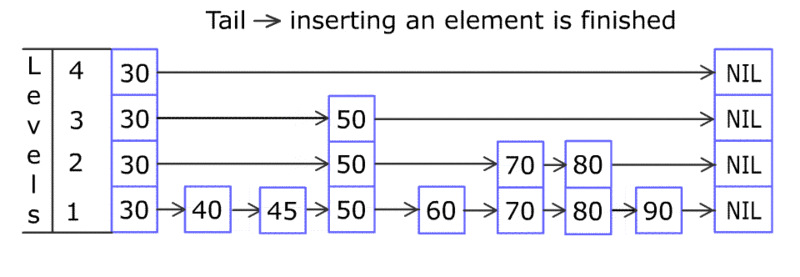
skip list
理论上的时间复杂度和 B 树是类似的。但为什么说跳表对于高并发更好呢,我自己的理解是因为在新增节点时,跳表通过一个概率值来决定是否需要添加上层节点,实现起来,变化比较局部,不会有 B 树那样牵一发而动全身的变化,所以无论是加锁实现,还是无锁实现都对高并发支持更好。如果想要了解更多,请各位同学自行查阅。跳表的另一个优势在于实现中对于内存的需求相对于 B 树更少。可能这也是为什么内存数据库 MemSql 就支持跳表索引。其实跳表也有缺点,因为是用链表实现,所以对于缓存并不是很友好。另一个缺点是,要支持逆向查询,比如(age < 40),这就需要用双向链表实现,复杂度也会更高。
总结一下,为了更好得支持并发操作以及内存优化,我们引入了跳表索引。
B 树索引还有哪些情况是不适用的吗?现在假设我们要对性别或者舱位做索引,但这些列本来基数(distinct value cardinality)就非常小,B 树带来的快速定位优势就没有意义了。有什么索引是适合这类查询吗?引出我们今天最后的一类索引 – 位图索引。
位图索引专门针对基数很小的列来做索引。比如对于性别,我们可以生成下列的索引:
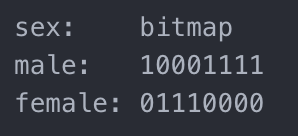
sex bitmap index
我们可以同时对 sex 和 cabin 做位图索引,然后对 sex:female 和 cabin:A 进行位图与操作再读取结果为 1 的行即可。除此之外,位图索引的另一大优势在于,相对于其他索引,存储需求很小:对于每个基数,每一行数据只要 1bit 的存储。所以当列的基数很大时,位图索引就失去意义了。位图索引的另一个劣势在于,不适用于高并发环境,因为任何修改和添加,都需要对索引文件进行加锁。
针对基数较小的列,我们引入了位图索引来提高查询速度。
小结
数据库索引是用来进一步提高查询语句的速度。针对不同的数据环境和不同索引的优缺点,我们介绍了以下这些方法:
1) 引入哈希索引用来提高点查询效率
2) 引入 B 树索引用来提高范围查询
3) 针对 B 树索引对高并发支持的诟病,引入跳表索引
4) 针对基数较小的列,引入位图索引
使用索引时,可以对每个表创建一个或多个索引。读者可能会有疑问,那岂不是对每个列都创建索引,就是万事大吉了。答案是否定的。索引是否能够提升效率,取决于查询语句以及数据的分布。而是否决定使用索引,是由数据库的优化器(之后会有专门的章节介绍优化器)决定的。另外,天下没有免费的午餐。首先,索引是冗余的数据存储,是要占据内存和磁盘空间的。二,索引数据要和表数据同步,在对修改数据的同时,也需要同步更新索引。如果索引太多,会大大降低数据导入和修改的吞吐量(可以在 Postgres 中做小实验,在有和没有索引的情况下,导入数据的时间相差甚远)。工程实践中,一般会在数据更新操作全部完成以后,再对表建索引。如何正确创建的索引,是原先 DBA 的工作;一个有经验的 DBA,能够根据查询需求创建最高效的索引。在越来越智能的数据库时代,很多数据库已经可以根据查询语句的类型,来提供创建索引的建议,毕竟没有数据库比数据库本身更懂自己!
下面揭露思考题答案:用 B 树索引读取数据的另一个好处是什么?那就是读取的数据针对索引列是排过序的。这可是一个非常好的特性,假设查询语句中本来就有排序需求(SQL 关键字 ORDER BY), 就不用再对数据进行排序了。另外有序列对于数据表的联合(join),以及聚类(aggregation)都很有帮助,这些我们留到以后再介绍。
作者介绍:
顾仲贤,现任 Facebook Tech Lead,专注于数据库,分布式系统,数据密集型应用后端架构与开发。拥有多年分布式数据库内核开发经验,发表数十篇数据库顶级期刊并申请获得多项专利,对搜索,即时通讯系统有深刻理解,爱设计爱架构,持续跟进互联网前沿技术。
2008 年毕业于上海交大软件学院,2012 年,获得美国加州大学戴维斯计算机硕士,博士学位;2013-2014 年任 Pivotal 数据库核心研发团队资深工程师,开发开源数据库优化器 Orca;2016 年作为初创员工加入 Datometry,任首席工程师,负责全球首家数据库虚拟化平台开发;2017 年至今就职于 Facebook 任 Tech Lead,领导重构搜索相关后端服务及数据管道, 管理即时通讯软件 WhatsApp 数据平台负责数据收集,整理,并提供后续应用。
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 10 条评论