如今,越来越多的业务场景要求 OLTP 系统能及时得到业务数据计算、分析后的结果,这就需要实时的流式计算如 Flink 等来保障。例如,在 TB 级别数据量的数据库中,通过 SQL 语句或相关 API 直接对原始数据进行大规模关联、聚合操作,是无法做到在极短的时间内通过接口反馈到前端进行展示的。若想实现大规模数据的“即席查询”,就须用实时计算框架构建实时数仓来实现。
本文通过一个教育行业的应用案例,剖析业务系统对实时计算的需求场景,并分析了 Flink 和 Spark 两种实现方式的异同,最后通过运用 UCloud UFlink 产品中封装的 SQL 模块,来加速开发效率,更快地完成需求。
1.1 业务场景简述
在这个 K12 教育的业务系统中,学生不仅局限于纸质的练习册进行练习,还可以通过各类移动终端进行练习。基于移动终端,可以更方便地收集学生的学习数据,然后通过大数据分析,量化学习状态,快速定位薄弱知识点,进行查缺补漏。
在这套业务系统中,学生在手机 App 中对老师布置的作业进行答题训练,每次答题训练提交的数据格式如下表所示:
| 字段 | 含义 | 举例 |
|---|
| student_id | 学生唯一ID | 学生ID_16 |
| textbook_id | 教材唯一ID | 教材ID_1 |
| grade_id | 年级唯一ID | 年级ID_1 |
| subject_id | 科目唯一ID | 科目ID_2_语文 |
| chapter_id | 章节唯一ID | 章节ID_chapter_2 |
| question_id | 题目唯一ID | 题目ID_100 |
| score | 当前题目扣分(0 ~ 10) | 2 |
| answer_time | 当前题目作答完毕的日期与时间 | 2019-09-11 12:44:01 |
| ts | 当前题目作答完毕的时间戳(java.sql.Timestamp) | Sep 11, 2019 12:44:01 PM |
例如,传入到后台的单条答题记录数据格式如下:
{ "student_id": "学生ID_16", "textbook_id": "教材ID_1", "grade_id": "年级ID_1", "subject_id": "科目ID_2_语文", "chapter_id": "章节ID_chapter_2", "question_id": "题目ID_100", "score": 2, "answer_time": "2019-09-11 12:44:01", "ts": "Sep 11, 2019 12:44:01 PM"}
复制代码
然后,基于上述实时流入的数据,需要实现如下的分析任务:
实时统计每个题目被作答频次
按照年级实时统计题目被作答频次
按照科目实时统计每个科目下题目的作答频次
1.2 技术方案选型
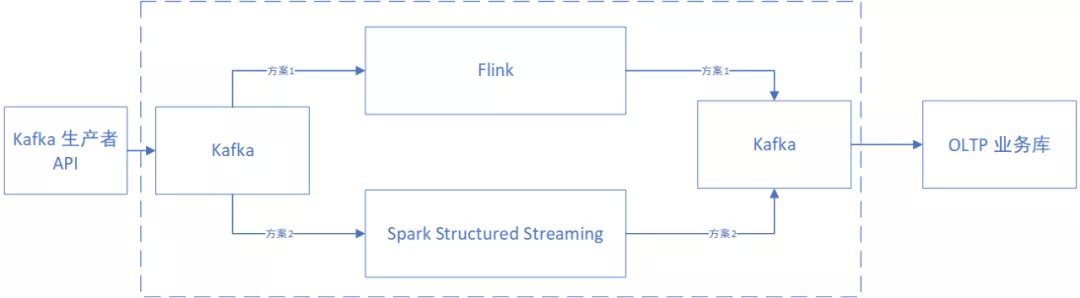
针对上述几个需求点,设计了如下的方案。首先会将数据实时发送到 Kafka 中,然后再通过实时计算框架从 Kafka 中读取数据,并进行分析计算,最后将计算结果重新输出到 Kafka 另外的主题中,以方便下游框架使用聚合好的结果。
下游框架从 Kafka 中拿到聚合好的数据,并实时录入到 OLTP 的业务库中(例如:MySQL、UDW、HBase、ES 等),以便于接口将想要的结果实时反馈给前端。
中间的实时计算框架,则在 Flink 和 Spark 中选择。2018 年 08 月 08 日,Flink 1.6.0 推出,支持状态过期管理(FLINK-9510, FLINK-9938)、支持 RocksDB、在 SQL 客户端中支持 UDXF 函数,大大加强了 SQL 处理功能,同时还支持 DML 语句、支持基于多种时间类型的事件处理、Kafka Table Sink 等功能。随后推出的 Flink 1.6.x 系列版本中,进行了大量优化。这些使得 Flink 成为一个很好的选择。
早先 Spark 要解决此类需求,是通过 Spark Streaming 组件实现。为此需要先生成 RDD,然后通过 RDD 算子进行分析,或者将 RDD 转换为 DataSet\DataFrame、创建临时视图,并通过 SQL 语法或者 DSL 语法进行分析。相比之下显得不够便捷和高效。后来 Spark 2.0.0 新增了 Structured Streaming 组件,具有了更快的流式处理能力,可达到和 Flink 接近的效果。
架构如下图所示:
本篇将省略下游框架的操作,重点介绍 Flink 框架进行任务计算的过程(虚线框中的内容),并简述 Spark 的实现方法,便于读者理解其异同。
1.3 实时计算在学情分析系统中的具体实现
1.3.1 Flink 实践方案
1. 发送数据到 Kafka
后台服务通过 Flume 或后台接口触发的方式调用 Kafka 生产者 API,实时将数据发送到 Kafka 指定主题中。
例如发送数据如下所示:
{"student_id":"学生ID_16","textbook_id":"教材ID_1","grade_id":"年级ID_1","subject_id":"科目ID_2_语文","chapter_id":"章节ID_chapter_2","question_id":"题目ID_100","score":2,"answer_time":"2019-09-11 12:44:01","ts":"Sep 11, 2019 12:44:01 PM"}………
复制代码
提示:此处暂且忽略在 Kafka 集群中创建 Topic 的操作。
2. 编写 Flink 任务分析代码
使用 Flink 处理上述需求,需要将实时数据转换为 DataStream 实例,并通过 DataStream 算子进行任务分析,另外,如果想使用 SQL 语法或者 DSL 语法进行任务分析,则需要将 DataStream 转换为 Table 实例,并注册临时视图。
(1)构建 Flink env
env(StreamExecutionEnvironment) 是 Flink 当前上下文对象,用于后续生成 DataStream。代码如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(3)
复制代码
(2)从 Kafka 读取答题数据
在 Flink 中读取 Kafka 数据需要指定 KafkaSource,代码如下所示:
val props = new Properties()props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")props.setProperty("group.id", "group_consumer_learning_test01")
val flinkKafkaSource = new FlinkKafkaConsumer011[]("test_topic_learning_1", new SimpleStringSchema(), props)val eventStream = env.addSource[](flinkKafkaSource)
复制代码
(3)进行 JSON 解析
这里通过 map 算子实现 JSON 解析,代码示例如下:
val answerDS = eventStream.map(s => { val gson = new Gson() val answer = gson.fromJson(s, classOf[Answer]) answer})
复制代码
(4)注册临时视图
创建临时视图的目的,是为了在稍后可以基于 SQL 语法来进行数据分析,降低开发工作量。需要先获取 TableEnv 实例,再将 DataStream 实例转换为 Table 实例,最后将其注册为临时视图。代码如下所示:
val tableEnv = StreamTableEnvironment.create(env)val table = tableEnv.fromDataStream(answerDS)tableEnv.registerTable("t_answer", table)
复制代码
(5)进行任务分析
接下来,便可以通过 SQL 语句来进行数据分析任务了,3 个需求对应的分析代码如下所示:
//实时:统计题目被作答频次val result1 = tableEnv.sqlQuery( """SELECT | question_id, COUNT(1) AS frequency |FROM | t_answer |GROUP BY | question_id """.stripMargin)
//实时:按照年级统计每个题目被作答的频次val result2 = tableEnv.sqlQuery( """SELECT | grade_id, COUNT(1) AS frequency |FROM | t_answer |GROUP BY | grade_id """.stripMargin)
//实时:统计不同科目下,每个题目被作答的频次val result3 = tableEnv.sqlQuery( """SELECT | subject_id, question_id, COUNT(1) AS frequency |FROM | t_answer |GROUP BY | subject_id, question_id """.stripMargin)
复制代码
此时得到的 result1、result2、result3 均为 Table 实例。
(6)实时输出分析结果
接下来,将不同需求的统计结果分别输出到不同的 Kafka 主题中即可。
在 Flink 中,输出数据之前,需要先将 Table 实例转换为 DataStream 实例,然后通过 addSink 算子添加 KafkaSink 即可。
因为涉及到聚合操作,Table 实例需要通过 RetractStream 来转换为 DataStream 实例。
该部分代码如下所示:
tableEnv.toRetractStream[](result1) .filter(_._1) .map(_._2) .map(new Gson().toJson(_)) .addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092", "test_topic_learning_2", new SimpleStringSchema()))
tableEnv.toRetractStream[](result2) .filter(_._1) .map(_._2) .map(new Gson().toJson(_)) .addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092", "test_topic_learning_3", new SimpleStringSchema()))
tableEnv.toRetractStream[](result3) .filter(_._1) .map(_._2) .map(new Gson().toJson(_)) .addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092", "test_topic_learning_4", new SimpleStringSchema()))
复制代码
(7)执行分析计划
Flink 支持多流任务同时运行,执行分析计划代码如下所示:
env.execute("Flink StreamingAnalysis")
复制代码
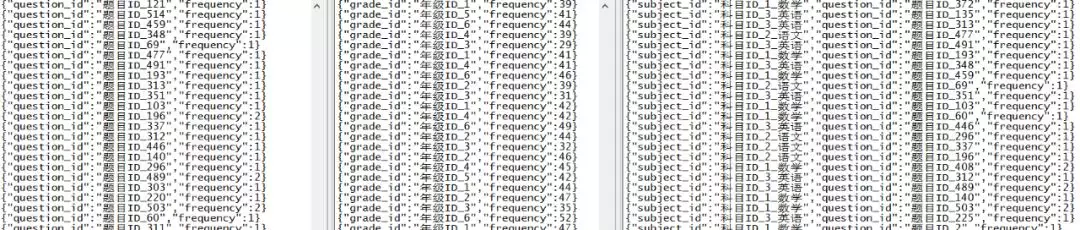
至此,编译并运行项目后,即可看到实时的统计结果,如下图所示,从左至右的 3 个窗体中,分别代表对应需求的输出结果。
1.3.2 Spark 基于 Structured Streaming 的实现
Spark 发送数据到 Kafka,及最后的执行分析计划,与 Flink 无区别,不再展开。下面简述差异点。
1. 编写 Spark 任务分析代码
(1)构建 SparkSession
如果需要使用 Spark 的 Structured Streaming 组件,首先需要创建 SparkSession 实例,代码如下所示:
val sparkConf = new SparkConf() .setAppName("StreamingAnalysis") .set("spark.local.dir", "F:\\temp") .set("spark.default.parallelism", "3") .set("spark.sql.shuffle.partitions", "3") .set("spark.executor.instances", "3")
val spark = SparkSession .builder .config(sparkConf) .getOrCreate()
复制代码
(2)从 Kafka 读取答题数据
接下来,从 Kafka 中实时读取答题数,并生成 streaming-DataSet 实例,代码如下所示:
val inputDataFrame1 = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092") .option("subscribe", "test_topic_learning_1") .load()
复制代码
(3)进行 JSON 解析
从 Kafka 读取到数据后,进行 JSON 解析,并封装到 Answer 实例中,代码如下所示:
val keyValueDataset1 = inputDataFrame1.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
val answerDS = keyValueDataset1.map(t => { val gson = new Gson() val answer = gson.fromJson(t._2, classOf[Answer]) answer})
复制代码
其中 Answer 为 Scala 样例类,代码结构如下所示:
case class Answer(student_id: String, textbook_id: String, grade_id: String, subject_id: String, chapter_id: String, question_id: String, score: Int, answer_time: String, ts: Timestamp) extends Serializable
复制代码
(4)创建临时视图
创建临时视图代码如下所示:
answerDS.createTempView("t_answer")
复制代码
(5)进行任务分析
仅以需求 1(统计题目被作答频次)为例,编写代码如下所示:
//实时:统计题目被作答频次val result1 = spark.sql( """SELECT | question_id, COUNT(1) AS frequency |FROM | t_answer |GROUP BY | question_id """.stripMargin).toJSON
复制代码
(6)实时输出分析结果
仅以需求 1 为例,输出到 Kafka 的代码如下所示:
result1.writeStream .outputMode("update") .trigger(Trigger.ProcessingTime(0)) .format("kafka") .option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092") .option("topic", "test_topic_learning_2") .option("checkpointLocation", "./checkpoint_chapter11_1") .start()
复制代码
1.3.3 使用 UFlink SQL 加速开发
通过上文可以发现,无论基于 Flink 还是 Spark 通过编写代码实现数据分析任务时,都需要编写大量的代码,并且在生产集群上运行时,需要打包程序,然后提交打包后生成的 Jar 文件到集群上运行。
为了简化开发者的工作量,不少开发者开始致力于 SQL 模块的封装,希望能够实现只写 SQL 语句,就完成类似上述的需求。UFlink SQL 即是 UCloud 为简化计算模型、降低用户使用实时计算 UFlink 产品门槛而推出的一套符合 SQL 语义的开发套件。通过 UFlink SQL 模块可以快速完成这一工作,实践如下。
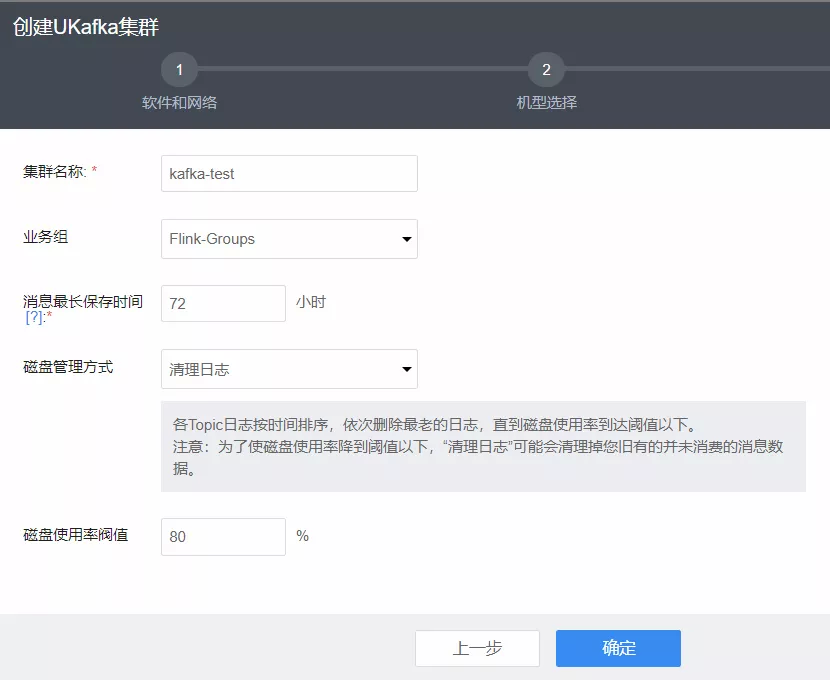
1. 创建 UKafka 集群
在 UCloud 控制台 UKafka 创建页,选择配置并设置相关阈值,创建 UKafka 集群。
更多细节可以参考 UKafka 产品文档 https://docs.ucloud.cn/analysis/ukafka/index
提示:此处暂且忽略在 Kafka 集群中创建 Topic 的操作。
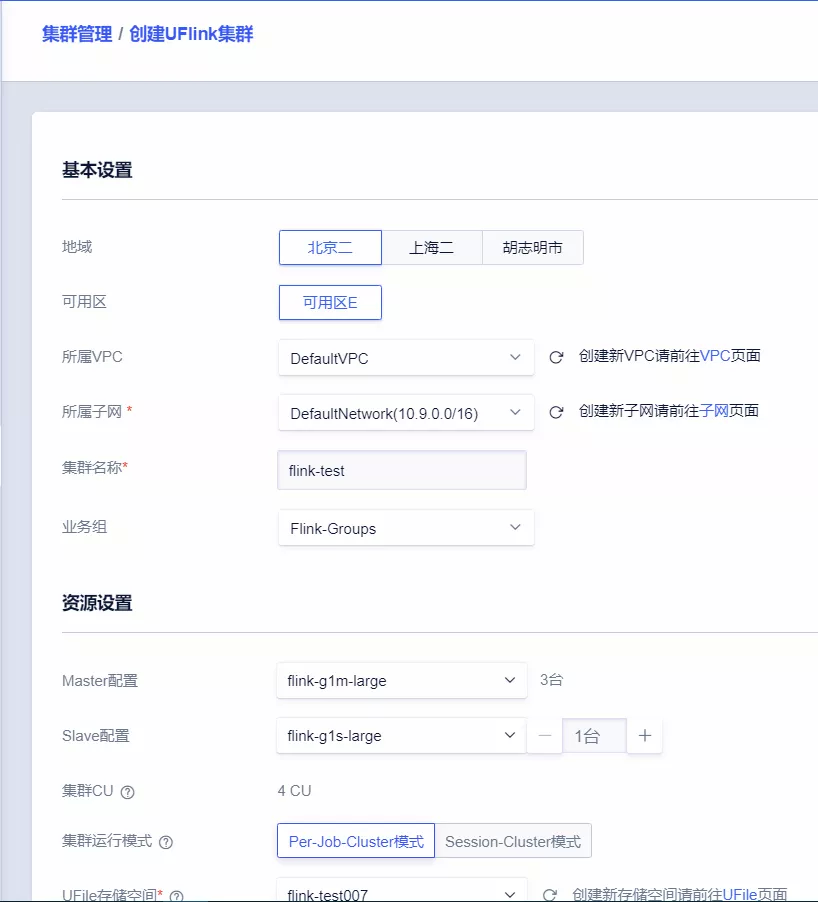
2. 创建 UFlink 集群
在 UCloud 控制台 UFlink 创建页,选择配置和运行模式,创建一个 Flink 集群。
更多细节可以参考 UFlink 产品文档 https://docs.ucloud.cn/analysis/uflink/index
3. 编写 SQL 语句
完成之后,只需要在工作空间中创建如下形式的 SQL 语句,即可完成上述 3 个需求分析任务。
(1)创建数据源表
创建数据源表,本质上就是为 Flink 当前上下文环境执行 addSource 操作,SQL 语句如下:
CREATE TABLE t_answer( student_id VARCHAR, textbook_id VARCHAR, grade_id VARCHAR, subject_id VARCHAR, chapter_id VARCHAR, question_id VARCHAR, score INT, answer_time VARCHAR, ts TIMESTAMP )WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_1', groupId = 'group_consumer_learning_test01', parallelism ='3' );
复制代码
(2)创建结果表
创建结果表,本质上就是为 Flink 当前上下文环境执行 addSink 操作,SQL 语句如下:
CREATE TABLE t_result1( question_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_2', parallelism ='3');
CREATE TABLE t_result2( grade_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_3', parallelism ='3');
CREATE TABLE t_result3( subject_id VARCHAR, question_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_4', parallelism ='3');
复制代码
(3)执行查询计划
最后,执行查询计划,并向结果表中插入查询结果,SQL 语句形式如下:
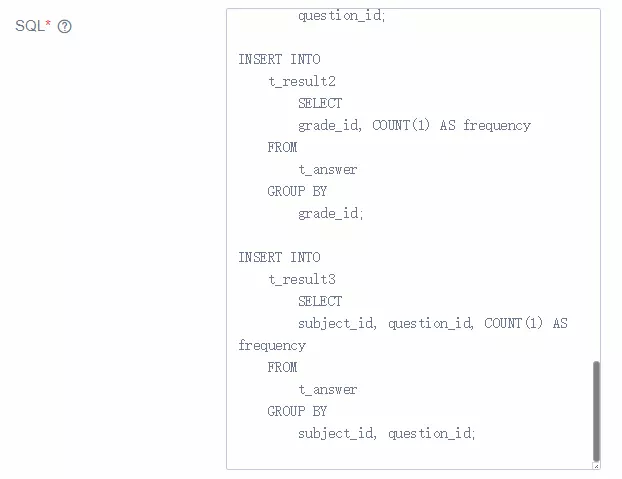
INSERT INTO t_result1 SELECT question_id, COUNT(1) AS frequency FROM t_answer GROUP BY question_id;
INSERT INTO t_result2 SELECT grade_id, COUNT(1) AS frequency FROM t_answer GROUP BY grade_id;
INSERT INTO t_result3 SELECT subject_id, question_id, COUNT(1) AS frequency FROM t_answer GROUP BY subject_id, question_id;
复制代码
SQL 语句编写完毕后,将其直接粘贴到 UFlink 前端页面对话框中,并提交任务,即可快速完成上述 3 个需求。如下图所示:
1.3.4. UFlink SQL 支持多流 JOIN
Flink、Spark 目前都支持多流 JOIN,即 stream-stream join,并且也都支持 Watermark 处理延迟数据,以上特性均可以在 SQL 中体现,得益于此,UFlink SQL 也同样支持纯 SQL 环境下进行 JOIN 操作、维表 JOIN 操作、自定义函数操作、JSON 数组解析、嵌套 JSON 解析等。更多细节欢迎大家参考 UFlink SQL 相关案例展示https://docs.ucloud.cn/analysis/uflink/dev/sql
1.4 总结
UFlink 基于 Apache Flink 构建,除 100%兼容开源外,也在不断推出 UFlink SQL 等模块,从而提高开发效率,降低使用门槛,在性能、可靠性、易用性上为用户创造价值。 今年 8 月新推出的 Flink 1.9.0,大规模变更了 Flink 架构,能够更好地处理批、流任务,同时引入全新的 SQL 类型系统和更强大的 SQL 式任务编程。UFlink 预计将于 10 月底支持 Flink 1.9.0,敬请期待。
本文转载自公众号 UCloud 技术(ID:ucloud_tech)。
原文链接:
https://mp.weixin.qq.com/s?__biz=MzUwOTA1NDg4NQ==&mid=2247486165&idx=1&sn=b8c7459d650435bef138ae1148ddf815&chksm=f919501fce6ed909744d8c6d2b32860c5709265542a683b3c9e4a46316607cd7d7cd89514f19&scene=27#wechat_redirect

















评论