

1 物理内存模型
现代计算机的物理内存模型:
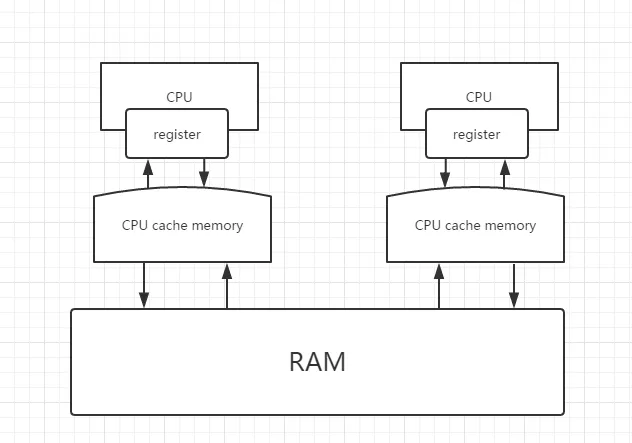
现代计算机的物理内存模型
现在计算机最少的都是应该是双核,当然我们也经常在买个人电脑的时候听过四核四线程、四核八线程等,可以说现在个人电脑标配都是四核心了,为了方便上图只是列举了 2 个核心。现代计算机的内存在逻辑上还是一块。
有人可能问:不对啊,我电脑就插了两块内存,但是操作系统会把两块内存的地址统一抽象,比如每一块的内存是 2048MB 地址是 000000000000-011111111111MB,两块就是 0000000000000-0111111111111MB,操作系统会统一编址。所以整体上看还是一块内存。因为 CPU 的操作速度太快,如果让 CPU 直接操作内存,那么就是对 CPU 资源的一种巨大浪费,为了解决这个问题现在计算机都给 CPU 加上缓存,比如一级缓存,二级缓存,甚至三级缓存。缓存速度比内存快,但是是还是赶不上 CPU 的数据级别,所以在缓存和 CPU 之间又有了 register,register 的存储速度比缓存就快了好多了。
存储速度上有如下关系:
register > 一级缓存 > 二级缓存 > … > n 级缓存 > 内存
容量上一般有如下关系:
内存 > n 级缓存 > … > 二级缓存 > 一级缓存 > register
之所以可以用缓存和 register 来缓解 CPU 和内存之间巨大的速度差别是基于如下原理:
CPU 访问过的内存地址,很有可能在短时间内会被再次访问。
所以,比如 CPU 访问了地址为 0x001fffff 的内存地址,如果没有缓存和 register,那么 CPU 再下次访问这个内存地址的时候就还要去内存读,但是如果有缓存,缓存会把 CPU 访问过的数据先存储起来,等 CPU 待会再找地址为 0x001fffff 的内存地址时候,发现其在缓存中就存在了,那么好了,这就不用在访问内存了。速度自然就提升了。这就涉及到计算机组成原理的知识了,如果想了解可以 google 一下,这里就不在做更深的介绍了到这里就够用了。
2 并发中三个重要概念
了解现代计算机物理内存模型工作原理后,那么再理解多线程开发中最关心的三个概念就有的放矢了。先介绍下三个概念:
2.1 操作原子性 :
一个操作要么全做,要么全不做,那么这个操作就符合原子性。比如你给你老婆银行卡转 500 块钱,就包括两个操作,自己账户先减 500,你老婆账户加 500。这个转账操作应该满足原子性。如果银行只执行了你自己账户的扣钱操作,没有执行给你老婆账户的加钱操作。丢了 500 块钱是小事,被老婆大人罚跪搓衣板可就不得了了。所以你自己账户减钱,老婆账户加钱,这两个操作要么都做了,要么都别做。例如如下操作:
a = a + 1;
结合我们上述的现代计算机的内存模型,计算机执行 a=a+1 时候会分成三个原子性操作:
1)把 a 的值(比如 4)从内存中取出放到 CPU 的缓存系统中
2)从缓存系统中取出 a 的值加 1(4+1)得到新结果
3)把新结果存回到内存中
一个“a=a+1”操作计算机中被拆分成三个原子性操作,那么完全可以出现 CPU 执行完 1.操作后,去执行别的操作了。这就是并发操作原子性问题的根本来源。
2.2 操作有序性 :
例如如下代码:
methodA 方法代码先经过 java 编译器编译成字节码,然后字节码然后被操作系统解释成机器指令,在这个解释过程中,操作系统可能发现,咦?在给变量 b 赋值为 true 后又操作了 a 变量,干脆我操作系统自己改改执行顺序,把对 a 变量的两个操作都执行完,然后再执行对 b 的操作,这就叫指令重排序。这样就会节省操作时间,如下图没有进行指令重排序时:
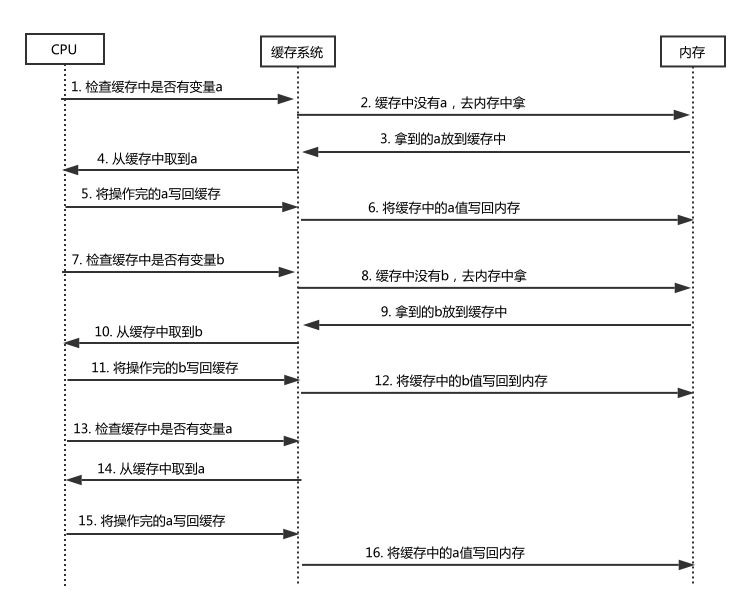
没有指令重排序
图中 CPU 和缓存系统要进行 9 次通信,缓存系统和内存要通信 7 次,假设 cpu 和缓存系统通信一次用时 1ms,缓存系统和内存通信一次用时 10ms,那么总用时 9 乘 1 + 7 乘 10 = 79ms。经过指令重排序后,总共用时 6 乘 1 + 6 乘 10 = 66ms ,如下图所示:
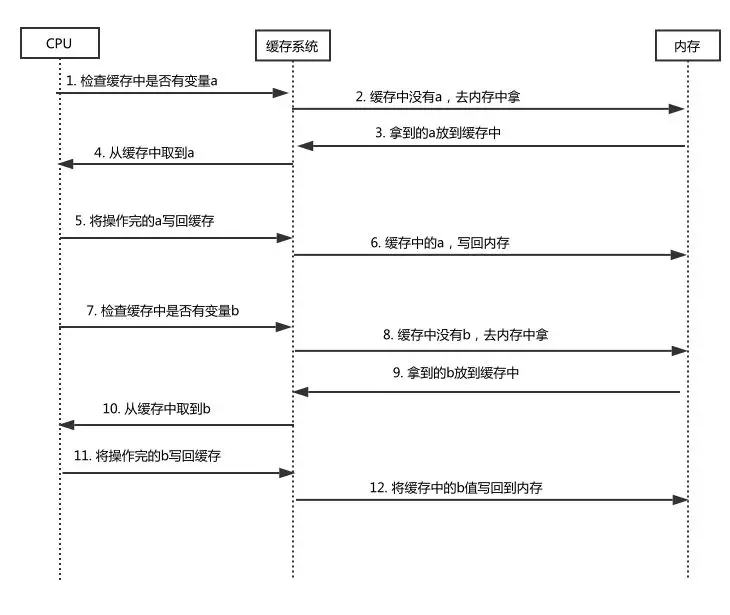
有指令重排序
经过指令重排序的确可以提程序运行效率,所以现代计算机都会对指令进行重排序,但是这种重排序也不是无脑重排序,重排序的基础是前后语句不存在依赖关系时,才有可能发生指令重排序。所以 A 类的 methodB 方法不会发生指令重排序。指令重排序在单线程环境里面这不会有什么问题,但是多线程中就可能发生意外。比如线程 1 中执行如下代码:
另一个线程 2 执行如下代码:
其中 instance 是 A 类的一个实例。如果线程 1 发生了指令重排序, 那么这线程 2 的打印结果很有可能是 false,这就和我们对代码的直观观察结果出处很大。如果线上产品出错的原因是指令重排序导致的,几乎不能可能排查出来。
2.3 操作可见性 :
在“操作有序性” 中的线程线程 2 ,还有可能会没有任何输出结果。因为线程 2 要想有输出必须要满足 instance.a =4,但这是在线程 1 中调用 methodA 方法后 instance.a 的值才为 4 。而要想让线程 2 看到这个新值,必须要把线程 1 的修改及时写回内存, 同时通知线程 2 存在缓存系统中的 instance.a 值已经过期,需要去内存中获取最新值。如果我们的类 A 和线程 1、线程 2 调用的代码没有特殊的声明,那么操作系统不能保证上述过程一定发生。即可能发生线程 1 对 instance.a 的修改对线程 2 不一定可见,这就是操作的可见性问题。
java 多线程的所有问题都植根于“操作原子性”、“操作有序性”、“操作可见性”而引发的。
3java 内存模型
上面介绍了现代计算机的内存模型以及其引起的在并发编程的三个问题,下面来介绍下 java 的内存模型。java 为了实现其夸平台的特性,使用了一种虚拟机技术,java 程序运行在这虚拟机上,那么不管你是 windows 系统,linux 系统,unix 系统,只要我 java 虚拟机屏蔽一切操作系统带来的差异,向 java 程序提供专用的、各系统无差别的虚拟机,那么 java 程序员就不需要关心底层到底是什么操作系统了。对于 int 类型的变量其取值范围永远是 -2^31 -1 至 2^31,即 4 个字节。但是对 C\C++,这个操作系统的 int 可能是 4 字节,那个可能是 8 字节。C++程序员跨平台写代码,痛苦异常。这个给我们编程带来极大方便的虚拟机就是大名鼎鼎的 JVM(Java Virtual Machine)。既然是虚拟机那么就需要模拟真正物理机的所有设备,像 CPU,网络,存储等。和我们程序员最密切的就是 JVM 的存储,这就是 java 内存模型(Java Memory Model 简称 JMM)。有别于我们真实的物理存储模型,JMM 把存储分为线程栈区和堆区。在 JVM 中的每个线程都有自己独立的线程栈,而堆区用来存储 java 的对象实例。
java 中各种变量的存储有一下规则:
1)成员变量一定存储在堆区。
2)局部变量如果是基本数据类型存储在线程栈中,如果是非基本数据类型存储,其引用存储在线程栈中,但具体的对象实例还是存储在栈中。
因为 java 内存模型是在具体的物理内存模型的基础上实现的,并且为了运行效率,java 也支持指令重排序。所以 java 并发编程也有“原子性”、“有序性”、“可见性”三个问题。但是,我们的 JMM 也不是白吃干饭什么也做的,最起码运行在 JVM 上的代码就具备 8 个内存特性,来使得 java 代码有一定的“有序性”和“可见性”。这些特性也被称为 happen-before 原则。
八大 happen-before 特性:
单线程 happen-before 原则:在同一个线程中,书写在前面的操作 happen-before 后面的操作。
锁的 happen-before 原则:同一个锁的 unlock 操作 happen-before 此锁的 lock 操作。
volatile 的 happen-before 原则:对一个 volatile 变量的写操作 happen-before 对此变量的任意操作(当然也包括写操作了)。
happen-before 的传递性原则:如果 A 操作 happen-before B 操作,B 操作 happen-before C 操作,那么 A 操作 happen-before B 操作。
线程启动的 happen-before 原则:同一个线程的 start 方法 happen-before 此线程的其它方法。
线程中断的 happen-before 原则:对线程 interrupt 方法的调用 happen-before 被中断线程的检测到中断发送的代码。
线程终结的 happen-before 原则:线程中的所有操作都 happen-before 线程的终止检测。
对象创建的 happen-before 原则:一个对象的初始化完成先于他的 finalize 方法调用。
happen-before 在这里不能理解成在什么之前发生,它和时间没有任何关系。个人感觉解释成“生效可见于” 更准确。
下面通过对这八个原则详细解释来加深对“生效可见于”的理解。
在同一个线程中,书写在前面的操作 happen-before 后面的操作:
好多文章把这理解成书写在前面先发生于书写在后面的代码,但是指令重排序,确实可以让书写在后面的代码先于书写在前面的代码发生。这是里把 happen-before 理解成“先于什么发生”,其实 happen-beofre 在这里没有任何时间上的含义。比如下面的代码:
这里 //2 对 b 赋值的操作会用到变量 a,那么 java 的“单线程 happen-before 原则”就保证 //2 的中的 a 的值一定是 3,而不是 0,5,等其他乱七八糟的值,因为//1 书写在//2 前面, //1 对变量 a 的赋值操作对//2 一定可见。因为//2 中有用到//1 中的变量 a,再加上 java 内存模型提供了“单线程 happen-before 原则”,所以 java 虚拟机不许可操作系统对//1 //2 操作进行指令重排序,即不可能有//2 在//1 之前发生。但是对于下面的代码:
两个语句直接没有依赖关系,所以指令重排序可能发生,即对 b 的赋值可能先于对 a 的赋值。
同一个锁的 unlock 操作 happen-beofre 此锁的 lock 操作:
话不多说直接看下面的代码:
如果某个时刻执行完“线程 1” 马上执行“线程 2”,因为“线程 1”执行 A 类的 method1 方法后肯定要释放锁,“线程 2”在执行 A 类的 method2 方法前要先拿到锁,符合“锁的 happen-before 原则”,那么在“线程 2”中 method2 方法中的变量 var 一定是 3,所以变量 b 的值也一定是 3。但是如果是“线程 1”、“线程 3”、“线程 2”这个顺序,那么最后“线程 2”method2 方法中的 b 值是 3,还是 4 呢?其结果是可能是 3,也可能是 4。的确“线程 3”在执行完 method3 方法后的确要 unlock,然后“线程 2”有个 lock,但是这两个线程用的不是同一个锁,所以 JMM 这个两个操作之间不符合八大 happen-before 中的任何一条,所以 JMM 不能保证“线程 3”对 var 变量的修改对“线程 2”一定可见,虽然“线程 3”先于“线程 2”发生。
对一个 volatile 变量的写操作 happen-before 对此变量的任意操作:
如果线程 1 执行//1,“线程 2”执行了//2,并且“线程 1”执行后,“线程 2”再执行,那么符合“volatile 的 happen-before 原则”所以“线程 2”中的 a 值一定是 1。
如果 A 操作 happen-before B 操作,B 操作 happen-before C 操作,那么 A 操作 happen-before C 操作:
如果有如下代码块:
假设“线程 1”执行//1 //2 这段代码,“线程 2”执行//3 //4 这段代码。如果某次的执行顺序如下:
//1 //2 //3 //4。那么有如下推导( hb(a,b)表示 a happen-before b):
因为有 hb(//1,//2) 、hb(//3,//4) (单线程的 happen-before 原则)
且 hb(//2,//3) (volatile 的 happen-before 原则)
所以有 hb(//1,//3),可导出 hb(//1,//4) (happen-before 原则的传递性)
所以变量 c 的值最后为 4
如果某次的执行顺序如下:
//1 //3 //2// //4 那么最后 4 的结果就不能确定。其原因是 //3 //2 的顺序不符合上述八大原则中的任何一个,不能通过传递性推测出来什么。
通过对上面的四个原则的详细解释,省下的四个原则就比较显而易见了。这里就不做详细解释了。
4 结束语
本文核心是通过现代计算机的内存模型引出 java 虚拟机 JMM 所支持的和并发相关的 8 个原则。这 8 个原则是 JMM 原生支持的,如果想深入理解并且运营 java 的并发机制,那么对 8 个原则的了解是必要的,而不是简单的会用 java 并发库的各种类。
作者介绍:
一页书(企业代号名),目前负责贝壳找房 java 后台开发工作。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/k0cQ_kIs4FhfAz_ncctRBg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论