
欢迎阅读新一期的数据库内核杂谈。在内核杂谈的第二期(存储演化论)里,我们介绍过数据库如何存储数据文件。对于 OLTP 类型的数据库,通常使用 row-based storage(行式存储)的格式来存储数据,而在大数据系统里,通常会选用 columnar-based storage(列式存储)来存储数据。这一期杂谈,我们介绍为大数据而生的,最广泛被使用的存储格式 parquet(https://parquet.apache.org/)。
简介
Parquet 是一种专为大数据处理系统优化的列式存储文件格式。它由 Twitter 和 Cloudera 两个在大数据生态系统中具有影响力的公司(曾经)于 2013 年共同创建。目标是开发一种高效,高性能的列式存储格式,并且能够与各种数据处理系统兼容。Parquet 从一开始就被设计为开源项目,后来被 Apache 软件基金会采纳为顶级项目。它的开发受到 Apache Parquet 社区的积极推动。自推出以来,Parquet 在大数据社区中广受欢迎。如今,Parquet 已经被诸如 Apache Spark、Apache Hive、Apache Flink 和 Presto 等各种大数据处理框架广泛采用,甚至作为默认的文件格式,并在数据湖架构中被广泛使用。
与传统的基于行存储的格式(如 CSV 和 JSON)相比,Parquet 文件格式具有一系列优势:通过以列式格式存储数据,Parquet 可以提高查询性能,尤其是对涉及汇总或过滤大量数据的分析工作负载。此外,Parquet 的先进压缩和编码技术有助于降低存储成本,同时保持高读写性能。
与传统的基于行存储的格式(如 CSV 和 JSON)相比,Parquet 文件格式具有以下优势:1.可以提高查询性能,尤其是对涉及汇总或过滤大量数据的分析工作负载。2.有助于降低存储成本,由于 Parquet 具有先进的压缩和编码技术,所以在降低存储成本的同时还能保持高读写的性能。
关键特性
是哪些特性让 Parquet 成为大数据处理和分析的理想选择呢?
列式存储格式:相比于 JSON 或者 CSV 或者其他行存储格式,Parquet 最主要的特点是其列式存储设计。这种方法可以实现更高效的压缩和编码,以及提高分析型语句的查询性能。通常,大数据系统中的表都是用宽表的形式存储,即,一个表有很多 column(几十,甚至上百)。而通常的查询语句,特别是分析型语句,只涉及少量列查询。这种情况下,Parquet 可以仅读取所需的列,从而显著减少 I/O 并加快查询执行。
高效压缩和编码:Parquet 的列式存储格式允许更好的压缩比,因为同一列中的数据往往更加同质化。Parquet 支持多种压缩算法,如 Snappy、Gzip 和 LZO,此外,Parquet 使用先进的编码技术,如 RLE、bitpacking 和 dictionary-encoding,以进一步减少存储需求并提高查询性能。
Schema 演进支持:Parquet 旨在能很好地处理数据 schema 随时间推移的变化,这对于大数据系统至关重要。它通过允许添加、删除或修改列而不影响现有数据来支持 schema 演进。
支持复杂数据类型:Parquet 支持丰富的数据类型集合,包括嵌套和重复结构,以及数组、映射(map)和结构(struct)等数据类型。此特性支持构建复杂的层次结构数据,并将其高效地存储在紧凑的二进制格式中。
Parquet 存储格式详解
这一节,我们深入学习 Parquet 是如何存储数据的。为了方便讲解,我们使用一个简单的示例表 - 学生表 student data(如下)。
在讨论 Parquet 前,先来做个对比,看一下 CSV 或者 JSON 这样的基于行的存储格式是如何存储数据的。顾名思义,数据是按行存储在磁盘上的。每一行的数据都存储在一个连续的块中,这使得整体读取和写入比较容易且直观。基于行的存储格式非常适合事务型工作负载,因为记录通常是单条插入、更新或者删除操作。
如果是 CSV 存储上面的数据,会是如下表示:
id,name,age,country,home_address1,Alice,20,USA,123 Main St2,Bob,22,UK,456 Maple Ave3,Carol,19,Canada,789 Oak St
虽然称为列式存储,但 Parquet 其实是将数据组织成多层级的结构,分别为 row groups(行组), columns(列), 和 page(页)。
行组:行组是 Parquet 文件中最大的数据单位。它们将整个表的数据划分为多个块,每个块包含一定数量的行。一个 Parquet 文件可以有一个或多个行组。行组中的行数是可配置的,选择合适的大小对性能至关重要。每个行组包含所有列的数据,分别存储。在设计 Parquet 文件时,需要考虑行组的大小,因为行组大小的选择对查询性能有重大影响。较大的行组可以带来更好的压缩效果,可能带来更好的读性能,因为它允许更高效的 I/O 操作。然而,较大的行组也可能在查询特定行子集时增加读取的数据量。在大多数 Parquet 实现中,默认的行组大小为 128 MB,但可以根据具体用例和数据特性进行调整。
在选择行组大小时,需要考虑以下因素:
查询模式:考虑数据集的典型查询模式。如果查询通常涉及基于特定列过滤或聚合数据,那么可能会有较小的行组,因为这将允许查询引擎在处理这些查询时读取更少的数据。
压缩比:压缩算法在处理较大行组时可以实现更好的压缩比,因为它们有更多的数据可供处理。然而,请注意,较大的行组也可能在查询数据时增加内存使用。
内存使用:在处理查询时,查询引擎需要将相关行组的数据加载到内存中。较大的行组可能需要更多的内存来处理,如果系统没有足够的内存可用,可能会导致性能问题。
列和页:列是 Parquet 中存储数据的主要结构。在每个行组中,每个列的数据都单独存储。每个列都经过编码、压缩,然后被存储进页里。页是 Parquet 中最小的数据单位,也是压缩和编码的基本单位。每个列会被划分为一个或多个页。
因为是按列存储,数据的格式都是一个类型。Parquet 就可以使用多种优化将一列数据有效地存储为二进制格式。主要的优化方式有两种,编码和压缩。
Parquet 常用的编码技术包括:
字典编码(dictionary encoding):用来优化具有少量不同值的列。为唯一值创建字典,并用指向字典的索引替换实际数据。这可以显著减少存储数据量。
Run-length encoding(RLE):用来优化具有重复值的列。RLE 不是单独存储每个值,而是存储值及其连续重复的次数。对于具有大量连续重复值的列,这种方法特别有效。
位打包(bit packing):用来优化具有小整数值的列。不是使用完整的 32 位或 64 位来表示每个值,而是使用表示值范围所需的最小位数,从而减少了所需的存储空间。
在对数据进行编码后,Parquet 会应用压缩算法以进一步减小数据的大小。Parquet 中常用的压缩算法有 Snappy、Gzip 和 LZO。压缩算法的选择取决于压缩比和解压速度之间的权衡。
需要注意的是,在二进制的数据文件中,Parquet 不使用任何分隔符来分隔数据。相反,它依赖于编码和压缩方案来有效地存储和检索数据。文件页脚中存储的元数据提供了关于数据结构的信息,使查询引擎能够正确访问和解释数据。
Parquet 实操演练
这一节,我们通过实操来直观地了解一下 Parquet 的文件存储。虽然 Parquet 通常被应用在大数据系统里,但 pandas 的 DataFrame 也支持直接以 parquet 形式导出数据。 下面是示例代码:
import pandas as pdfrom sklearn.datasets import load_iris, fetch_california_housing# toy dataset iris data: 150 rows x 5 columnsiris_data = load_iris()iris_df = pd.DataFrame(data=iris_data['data'], columns=iris_data['feature_names'])iris_df['target'] = iris_data['target']iris_df.to_csv('iris_data.csv')iris_df.to_json('iris_data.json')iris_df.to_parquet('iris_data.parquet')# example data: student table: 3 rows * 5 columnsdata = { 'Id': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Carol'], 'Age': [20, 22, 19], 'Country': ['USA', 'UK', 'Canada'], 'HomeAddress': ['123 Main St', '456 Maple Ave', '789 Oak St']}df = pd.DataFrame(data)df.to_csv('student_data.csv')df.to_json('student_data.json')df.to_parquet('student_data.parquet')# california housing: 20640 rows x 9 columnscal_house = fetch_california_housing()cal_house_df = pd.DataFrame(data=cal_house['data'], columns=cal_house['feature_names'])cal_house_df['target'] = cal_house['target']cal_house_df.to_csv('cal_house_data.csv')cal_house_df.to_json('cal_house_data.json')cal_house_df.to_parquet('cal_house_data.parquet')
先来解释一下上述的代码示例:分别 load 三个 dataset,iris data(来自 sklearn 的 toy dataset), student dataset(我们上面使用的示例),以及 california housing dataset(sklearn 上比较大的 dataset)。代码本身非常直观:数据导入后分别以 CSV,JSON,和 Parquet 的形式存储到文件中。(注:运行这段代码还需要安装其他依赖包,可以通过 pip install 来安装)。
然后通过`ll`来查看数据文件的大小:
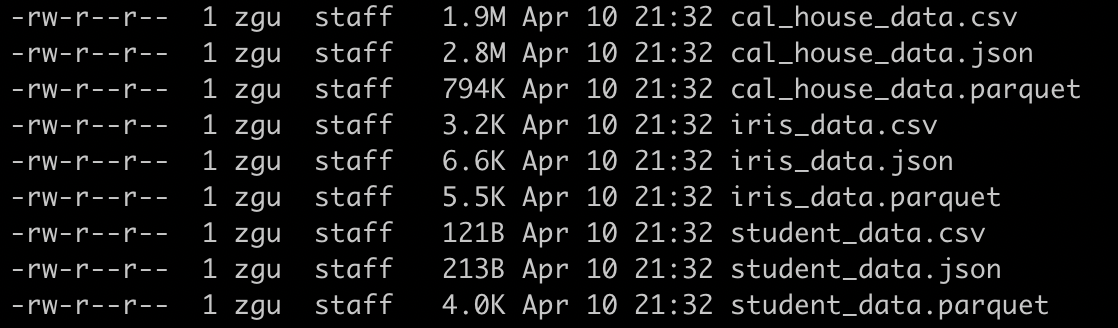
通过比较可以发现:
CSV 和 JSON 的存储大小比大致保持在 1:2。
当数据量小时,Parquet 文件远大于 CSV 和 JSON,因为 Parquet 会存储更多的 metadata,比如 row group 的 column 的 min,max 值,版本管理等等
当数据量大时,Parquet 文件明显小于 CSV 和 JSON。在大数据应用中,压缩比会更明显(考虑到通常,parquet 的文件大小在 128MB 左右)。
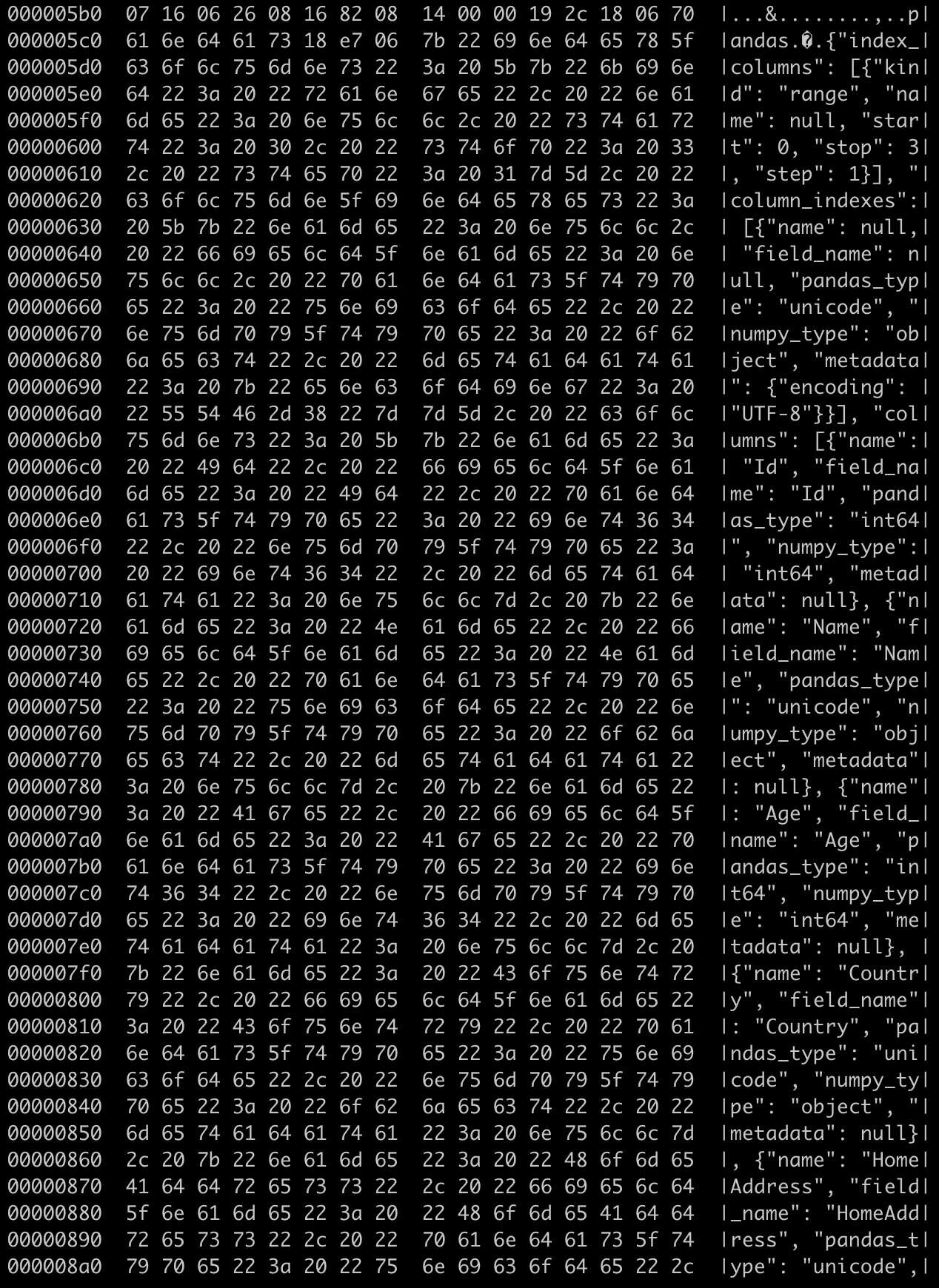
CSV 和 JSON 是明文和 txt-based 存储,可以直接用 cat 或者 vim 打开。Parquet 是以二进制存储数据,如果想查看数据文件,可以使用`hexdump`工具(`hexdump -C student_data.parquet`)。 下面是运行截图。
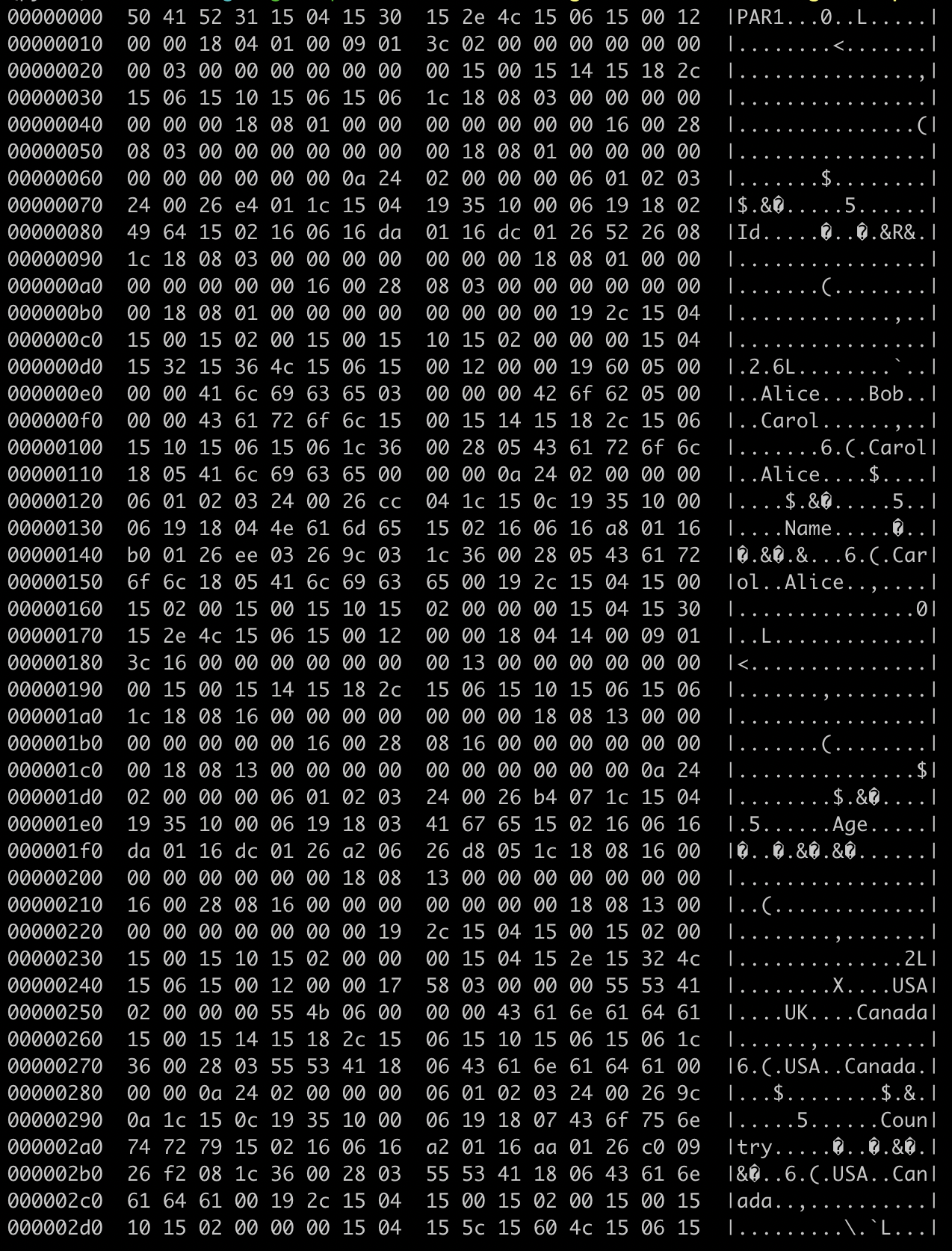
虽然有些特殊的 bytecode,但大致可以看出数据是按照列来存储的。在数据文件的下半段,可以看到 schema 的 definition。
推荐大家可以动手,尝试运行一下代码。再留一道思考题给大家,可以使用 time 包对不同格式的读写加上时间消耗,来比较一下速度。另外,因为是列式存储,parquet 的另一个优势是可以只读取要用到的 column,推荐大家使用相关 API 只读取一到两个 column,再比较一下速度。
总结
本期杂谈介绍了为大数据系统而生的存储格式 Parquet。我们通过介绍 Parquet 的关键特性和其存储格式,讨论了为什么 Parquet 更适合海量数据的分析型查询。最后,我们也通过代码实操来让大家对 parquet 有更直观的了解。感谢阅读!




