

在本文中,我们探索了未来软件发展的新途径。我们已经证明,用户可以保留对数据的所有权和控制权,同时还可以从与云相关的功能中受益:无缝协同和随时随地访问。两个世界都有可能做到最好。
我们在这个系列的第一个部分,介绍了本地优先的七个理念,这里再重复强调一下都是什么原则需要我们遵循的:
无需等待:立即工作
工作不会被困在一台设备上
多选的网络
与同事无缝协同
永远是最新
默认的安全和隐私
保留最终控制权
现有数据存储和共享模型
我们相信专业和有创造力的用户应该拥有能够实现本地优先目标的软件,帮助他们无缝协同,同时还让他们保留对工作的完全所有权。如果我们能让用户在他们用来进行最重要工作的软件中获得这些特性,就能帮助他们更好地完成他们所做的工作,并可能对许多人的职业生涯产生重大影响。
然而,虽然本地优先的理念可能会引起我们的共鸣,但我们仍然想知道在实践中是如何实现它的。只是乌托邦式的空想吗?
在本文的其余部分,我们将讨论在实践中实现本地优先软件意味着什么。我们研究了各种现有技术,并分析了它们如何满足本地优先的理念。在下表中,✓表示技术符合理念,- 意味着部分符合理念,✗ 意味着不符合理念。
正如我们将看到的,虽然许多技术满足了一些目标,但没有一种能够满足所有目标。最后,我们研究了一种来自计算机科学研究前沿的技术,它可能是未来实现本地优先的基础。
应用程序架构如何影响用户体验
让我们首先从最终用户的角度来测试软件,并分解不同的软件架构看看如何满足本地优先的七个目标。在下一节中,我们将比较软件工程师用于构建应用程序的存储技术和 API。
文件和电子邮件附件
从这七个目标的角度来看,传统的文件具有许多令人满意的特性:它们可以离线查看和编辑,它们可以完全控制用户,并且可以随时备份和长期保存。依赖本地文件的软件也有可能非常快。
但是,从多个设备访问文件比较棘手。可以使用各种技术跨设备传输文件:
其中,电子邮件附件可能是最常见的共享机制,尤其是对非技术专家的用户。附件易于理解,值得信赖。获得文档副本后,它不会自动改变:如果在六个月后查看电子邮件,附件仍以原始格式存在。与 Web 应用程序不同,不需要任何额外的登录过程就可以打开附件。
电子邮件附件最薄弱的地方就是协同。通常,一次只有一个人可以对文件进行更改,否则需要进行困难的手动合并。文件版本控制很快变得混乱:带有附件的来回电子邮件线程通常会生成很奇怪的文件名,如 Budget draft 2 (Jane’s version) final final 3.xls。
然而,对于那些希望融入本地优先理念的应用程序,一个好的起点是提供一种导出功能,可以生成广泛支持的文件格式(例如纯文本、PDF、PNG 或 JPEG),并允许通过电子邮件附件、Slack 或 WhatsApp 进行共享。
Web 应用:Google Docs,Trello,Figma,Pinterest 等**
与此相反的是纯 Web 应用,用户的本地软件(Web 浏览器或移动应用)是瘦客户端,数据存储位于服务器上。服务器通常使用大型数据库,其中数百万用户的数据全部混合在一个巨型的集合中。
Web 应用为实时协同设定了标准。用户可以相信,当在任何设备上打开文档时,将看到当前的最新版本。这对于团队工作来说非常有用,这些应用程序已成为主导。即使是传统的仅限本地的软件(如 Microsoft Office),也正在向云服务过渡,截至 2017 年,Office 365已超过本地安装的Office。
随着远程工作和分布式团队的兴起,实时协同生产力工具变得更加重要。团队视频通话中的十个用户可以调出相同的 Trello 任务板,每个用户在自己的计算机上进行编辑,同时查看其他用户正在做什么。
另一方面是完全丧失了所有权和控制权:服务器上的数据才是最重要的,客户端设备上的任何数据都不重要 — 它只是一个缓存。大多数 Web 应用很少或根本不支持离线工作:如果网络偶尔会出现问题,那么将无法继续完成工作。

如果Google Docs检测到它处于离线状态,则会阻止对文档的编辑。
一些最好的 Web 应用隐藏了使用 JavaScript 进行服务器通信的延迟,并尝试提供有限的离线支持(例如,Google Docs离线插件)。然而,这些努力似乎被改造成一个基本上以与服务器的同步交互为中心的应用程序体系结构,用户在尝试离线工作时报告各种结果的混合信息。

Google Docs离线扩展程序的负面用户评论
一些 Web 应用,例如 Milanote 和 Figma,提供基本上是重新打包的 Web 浏览器的可安装桌面客户端。如果尝试使用这些客户端来访问工作,网络是间歇性的,而供应商的服务器正在经历中断,或者在供应商被收购和关闭之后,很明显,工作从来不是真正属于自己的。
FIGMA桌面客户端正在运行
Dropbox,Google Drive,Box,OneDrive 等
基于云的文件同步产品(如Dropbox、Google Drive、Box或OneDrive),可以在多个设备上使用文件。在桌面操作系统(Windows、Linux、Mac OS)上,这些工具通过监视本地文件系统上指定的文件夹来工作。计算机上的任何软件都可以读取和写入此文件夹中的文件,并且每当在其中一台计算机上更改某个文件时,它都会自动复制到所有其他计算机上。
由于这些工具使用本地文件系统,它们有许多吸引人的特性:对本地文件的访问速度很快,离线工作也没有问题(离线编辑的文件会在下一次 Internet 连接可用时进行同步)。如果同步服务关闭,文件仍将在本地磁盘上保持不受影响,并且可以轻松切换到其他同步服务。如果计算机的硬盘驱动器出现故障,只需安装应用程序并等待其同步即可恢复工作。这提供了良好的使用寿命和对数据的控制。
但是,在移动平台(iOS 和 Android)上,Dropbox 及其同类产品使用了完全不同的模式。移动应用不会同步整个文件夹,它们是瘦客户端,每次从服务器获取一个文件的数据,默认情况下它们不能离线工作。它有一个“Make available offline”选项,但是需要记住在离线之前调用它,这很笨拙,并且仅在应用程序打开时才起作用。Dropbox API也以服务器为中心。
Dropbox移动应用程序的用户花费大量时间盯着等待的旋转指针,这与Dropbox桌面产品触手可及的感觉形成鲜明对比。
文件同步产品最薄弱的地方是缺乏实时协同:如果在两个不同的设备上编辑相同的文件,则结果是需要手动合并冲突,如前所述。这些工具可以同步任何格式的文件,这既是一个优点(与任何应用程序的兼容性),也是一个弱点(无法执行特定格式间的合并)。
Git 和 GitHub
Git和GitHub主要被软件工程师用于协同源代码。它们可能是我们与真正的本地优先软件包最接近的东西:与以服务器为中心的版本控制系统(如Subversion)相比,Git 完全离线工作,速度快,完全控制用户,适用于长期保存数据。这是因为本地文件系统上的 Git 存储库是数据的主副本,而不是从属于任何服务器。
我们在这里重点介绍Git/GitHub作为最成功的例子,但这些经验也适用于其他分布式修订控制工具,如Mercurial或Darcs,以及其他存储库托管服务,如GitLab或Bitbucket。原则上,可以在没有存储库服务的情况下进行协同,例如通过电子邮件发送补丁文件,但大多数Git用户依赖于GitHub。
像 GitHub 这样的存储库托管服务支持围绕 Git 存储库进行协同,访问来自多个设备的数据,并提供备份和存档位置。虽然Working Copy是一个很有前途的 iOS 版 Git 客户端,但目前对移动设备的支持很弱。GitHub 保存未加密的存储库,如果需要更强的隐私,可以运行自己的存储库服务器。
我们认为 Git 模型为本地优先软件的未来指明了方向。然而,就目前而言,Git 有两个主要弱点:
Git非常适合异步协同,尤其是pull请求,它接受粗粒度的更改,并可以在将它们合并到共享主分支之前进行讨论和修改。但Git无法进行实时、细粒度的协同,例如Google Docs、Trello和Figma等工具中的自动即时合并。
Git针对代码和类似基于行的文本文件进行了高度优化,其他文件格式被视为二进制blob,无法进行有意义的编辑或合并。尽管GitHub努力显示和对比图像、散文和CAD文件,但非文本文件格式在Git中仍然是次要的。
有趣的是,大多数软件工程师都不愿意为他们的编辑器、IDE、运行时环境和构建工具采用云软件。从理论上讲,我们可能希望这些高级用户比其他类型的用户更快地接受新技术。但是如果你问工程师他们为什么不使用像Cloud9或Repl.it这样的基于云的编辑器,或者像Colaboratory这样的运行时环境,答案通常是“速度太慢”,或“我不相信它”,或“我想在本地系统上使用我的代码”,这些态度似乎反映了一些与本地优先相同的动机。如果作为开发人员为自己和工作想要这些东西,我们会想到其他类型的创造性专业人士也会想要这些相同的特点。
应用构建开发人员基础架构
现在,我们已经通过本地优先理念的视角研究了一系列应用的用户体验,让我们将思维模式转换为应用开发人员的思维模式。如果正在创建一个应用程序,并希望为用户提供部分或全部本地优先的体验,那么对数据存储和同步的基础架构有哪些选择?
Web 应用(瘦客户端)
最纯粹的 Web 应用通常是运行在服务器上的 Rails、Django、PHP 或 Node.js 程序,将数据存储在 SQL 或 NoSQL 数据库中,并通过 HTTPS 提供 Web 页面。所有数据都在服务器上,用户的 Web 浏览器只是一个瘦客户端。
这种架构提供了许多好处:零安装(只需访问一个 URL),用户无需管理,因为所有数据都由部署应用程序的工程师和 DevOps 专业人员在一个地方存储和管理。用户可以通过任何设备访问应用,同事可以通过登录同一个应用轻松地进行协同。
诸如Meteor和ShareDB之类的JavaScript框架,以及Pusher和Ably之类的服务可以更轻松地为Web应用添加实时协同功能,构建在WebSocket之类的低级协议之上。
另一方面,需要针对每个用户的操作向服务器执行请求的 Web 应用将变得缓慢。在某些情况下,可以通过使用客户端 JavaScript隐藏往返时间,但如果用户的互联网连接不稳定,这些方法很快就会失效。
尽管付出了许多努力(manifests、localStorage、服务工作者和Progressive Web Apps等)想让 Web 浏览器更易于离线,但 Web 应用的体系结构仍然基本上以服务器为中心。在大多数 Web 应用中,离线支持是事后的想法,其结果也因此变得很脆弱。在许多 Web 浏览器中,如果用户清除了 cookie,则本地存储中的所有数据也将被删除 ,虽然这对缓存来说不是问题,但它使浏览器的本地存储不适合保存任何长期都重要的数据。
依赖第三方的 Web 应用在持久、隐私和用户控制方面的得分也很低。如果 Web 应用是开源的,并且用户愿意自托管自己的服务器实例,可以改进这些属性。但是,我们认为,对于绝大多数不想成为系统管理员的用户来说,自托管不是一个可行的选择。此外,大多数 Web 应用程序都是非开源的,完全排除了这种选择。
总而言之,我们推测,由于平台基本的瘦客户端特性,Web 应用将永远无法提供我们正在寻找的所有本地优先属性。当我们选择如何构建 Web 应用时,考虑的应该是属于我们和公司的数据路径,而不是用户的。
带本地存储的移动应用(胖客户端)
iOS 和 Android 应用程序是本地安装的软件,在运行应用程序之前下载并安装整个应用程序的二进制文件。然而,许多应用程序都是瘦客户端,类似于 Web 应用,需要一个服务器才能运行(例如,Twitter、Yelp 或 Facebook)。如果没有可靠的 Internet 连接,这些应用程序将出现等待、错误消息和意外行为。
但是,还有另一类移动应用更符合本地优先的理念。这些应用首先使用一个持久层(如SQLite、Core Data或纯文件)将数据存储在本地设备上。其中一些(例如Clue或Things)是作为一个没有任何服务器的单用户应用程序开始的,后来又添加了一个云后端,作为在设备之间同步或与其他用户共享数据的一种方式。
因为服务器的同步发生在后台,这些胖客户端应用程序具有快速和离线工作的优势。如果服务器关闭,它们通常会继续工作。它们提供隐私和用户控制数据,程度取决于相关的应用程序。
如果可以在多个设备上或由多个协同用户修改数据,事情就会变得更加困难。移动应用的开发人员通常是终端用户应用程序开发的专家,而不是分布式系统。我们已经看到多个应用程序开发团队编写自己 ad-hoc(临时)的差异、合并和冲突解决算法,并且生成的数据同步解决方案通常不可靠且脆弱。下一节中讨论的更专门化的存储后端可以有所帮助。
后端即服务:Firebase,CloudKit,Realm
Firebase是最成功的移动后端即服务的选择。它本质上是一个本地设备上的数据库,结合了云数据库服务和两者之间的数据同步。Firebase 允许跨多个设备共享数据,并支持离线使用。但是,作为专有的托管服务,我们在隐私和持久方面给它一个很低的分数。
另一个受欢迎的后端即服务是Parse,但它在2017年被Facebook 收购然后关闭。依赖它的应用程序被迫转向其他后端服务,这也凸显了持久的重要性。
Firebase 为开发人员提供了极佳的体验:可以在 Firebase 控制台中以自由格式查看、编辑和删除数据。但是,用户没有一种类似的方式来访问、操作和管理他们的数据,这使得用户几乎没有所有权和控制权。
Firebase控制台:非常适合开发人员、非标准的用户
Apple 的CloudKit为那些愿意将自己限制在 iOS 和 Mac 平台上的应用程序提供了类似 Firebase 的体验。它是一个具有同步、良好的离线功能的键值存储,并且具有内置于平台中的好处(避免了用户创建帐户和登录的麻烦)。对于独立的 iOS 开发者来说,它是一个很好的选择,并且通过Ulysses、Bear、Overcast等工具可以很好地发挥作用。
借助一个复选框,由于使用了CloudKit,Ulysses可以跨用户连接的所有设备进行同步
另一个项目是Realm,与 Core Data 相比,这个 iOS 的持久库借助更简介的 API 而广受欢迎。用于本地持久性的客户端库称为 Realm**数据库,相关联的类似 Firebase 的后端服务称为Realm对象服务器。值得注意的是,这个对象服务器是开源的并且可以自托管,这降低了被锁死在可能有一天消失的服务的风险。
将设备上的数据视为主要副本(或至少是非一次性的缓存),并使用 Firebase 或 iCloud 之类的同步服务的移动应用程序,为我们提供了一条通向本地优先的良好道路。
CouchDB
CouchDB是一个以开创多主(multi-master)复制方法而闻名的数据库:多台机器都有一个完整的数据库副本,每个副本可以独立地对数据进行更改,任何一对副本都可以相互同步交换最新的更改。CouchDB 被设计在服务器上使用,Cloudant提供版本托管,PouchDB和Hoodie使用相同同步协议的但在终端用户设备上运行的兄弟项目。
从哲学角度来看,CouchDB 与本地优先原则紧密结合,这一点在CouchDB的书中尤为明显,该书对分布式一致性、复制、变更通知和多版本并发控制等相关主题进行了很好的介绍。
虽然 CouchDB/PouchDB 允许多个设备同时对数据库进行更改,但这些更改会导致需要应用程序代码来显式解决冲突。这种冲突解决代码很难正确地编写,使得 CouchDB 对于具有非常细粒度协同的应用程序(如 Google Docs)而言是不切实际的,在这些应用程序中的每一次击键都可能是一个单独的更改。
实际上,CouchDB 模型尚未被广泛采用。原因有很多:当每个用户需要一个单独的数据库时会出现可伸缩性问题,难以在 iOS 和 Android 上的本机应用程序中嵌入 JavaScript 客户端,解决冲突的问题,执行查询时不熟悉 MapReduce 模型,等等。总而言之,虽然我们同意 CouchDB 背后的许多理念,但我们认为,在实践中并没有能够实现本地优先的愿景。
迈向更美好的未来
正如我们所展示的,用于应用程序开发的现有数据层中没有一个能完全满足本地优先理念。因此,三年前,我们的实验室开始寻找能给出七个绿色对勾的解决方案。
我们发现一些技术似乎是本地优先理念有前景的基础。最显著的是称为无冲突复制数据类型(Conflict-free Replicated Data Types,CRDTs)的分布式系统算法系列。
CRDT 作为基础技术
CRDT 于2011年从学术计算机科学研究中脱颖而出。它们是通用的数据结构,如哈希映射和列表,但是它们的特殊之处在于从一开始就是支持多用户的。
每个应用程序都需要一些数据结构来存储其文档状态。例如,如果应用程序是文本编辑器,则核心数据结构是组成文档的字符数组。如果应用程序是电子表格,则数据结构是包含引用其他单元格的文本、数字或公式的单元格矩阵。如果它是矢量图形应用程序,则数据结构是图形对象的树,例如文本对象、矩形、线条和其他形状。
如果要构建单用户应用程序,则可以在内存中使用模型对象、哈希映射、列表、记录/结构等来维护这些数据结构。如果要构建协同式多用户应用程序,则可以将这些数据结构替换为 CRDT。
这意味着,如果拥有文档的副本,则可以对 CRDT 进行更改,并且数据结构会跟踪更改。这些更改可以编码为字节字符串,并通过喜欢的任何通信渠道发送给协同者(例如,通过服务器、点对点连接、本地设备之间的蓝牙,甚至是 USB 记忆棒)。
协同者可以接收这些更改并将其应用于文档的副本。与 Git 中的合并不同,在 Git 中可能需要手动解决合并冲突,CRDT 会自动执行合并。
CRDT 分解:
无冲突:当多个协同者进行更改时,它们可以自动合并到一致的文档视图中;
复制:每个协同者都有自己的数据副本,存储在本地设备上;
数据类型:通用数据结构,如映射和列表。
这些属性可以直接对应到我们的本地优先理念。在本地拥有数据副本而不是依赖于服务器,可实现离线工作、持久、良好性能和用户控制。能够自动合并更改,支持多设备使用和协同,通信通道的灵活性允许加密,从而提高隐私和安全性。
CRDT 跟踪的更改可以小到一次击键,从而支持 Google Docs 风格的实时协同。但也可以收集更大的更改集合,并将其作为批处理发送给协同者,更像是 Git 中的 pull 请求。由于数据结构是通用的,我们可以开发通用的工具来存储、通信和管理 CRDT,从而避免在每个应用程序中重复实现这些功能。
有关 CRDT 的更多技术介绍,我们建议阅读以下文章:
Shapiro等,综合调查
Gomes等,对CRDT的形式验证
Ink&Switch 基于我们之前对JSON CRDT的研究,开发了一个叫Automerge的开源 JavaScript CRDT 实现。然后我们将 Automerge 与Dat网络堆栈结合起来形成了Hypermerge。我们并不认为这些图书馆完全实现了本地优先理想。他们仍然需要做更多的工作。
但是,根据我们与他们的经验,我们相信 CRDT 有潜力成为新一代软件的基础。正如分组交换是互联网和网络的一种赋能技术,或者电容式触摸屏是智能手机的赋能技术,我们认为 CRDT 可能是协同软件的基础,可为用户提供对数据的完全所有权。
Ink & Switch 原型
尽管学术研究在设计 CRDT 算法和验证其理论正确性方面取得了很好的进展,但迄今为止这些技术的工业应用相对较少。此外,大多数工业 CRDT 都用于以服务器为中心的计算,但我们相信这项技术在客户端应用中具有巨大的创造性潜力。
使用CRDT的以服务器为中心的系统包括Azure Cosmos DB、Riak、Weave Mesh、SoundCloud的Roshi和Facebook的OpenR。但是,我们最感兴趣的是如何在终端用户设备上使用CRDT。
我们实验室开发一系列实验原型的动机,这些原型具有基于 CRDT 构建的协同式本地优先应用。每个原型都提供了一个模仿已有应用的终端用户体验,如 Trello、Figma 或 Milanote。
这些实验探讨了三个方面的问题:
技术可行性。还有多久CRDT可以用于工作软件?我们需要什么来进行网络通信,或者从安装软件开始?
用户体验。本地优先软件的使用感觉如何?在没有可信的集中式服务器的情况下,我们能获得像Google Docs这样的无缝实时协同体验吗?对于源代码以外的数据类型,一个类似Git的、离线友好的异步协同体验如何?通常来说,没有集中式服务器,用户界面如何变化?
开发人员经验。对于应用程序开发人员,如何使用基于CRDT的数据层与现有存储层(如SQL数据库、文件系统或核心数据)进行比较?分布式系统更难为其编写软件吗?我们需要模式和类型检查吗?开发人员将使用什么来调试和反思应用程序的数据层?
我们使用Electron、JavaScript 和React构建了三个原型。这给了我们 Web 技术的快速发展能力,同时也为我们的用户提供了他们可以下载和安装的软件,我们发现这是本地优先感觉的重要组成部分。
看板
Trellis是一款以流行的Trello项目管理软件为蓝本的看板。
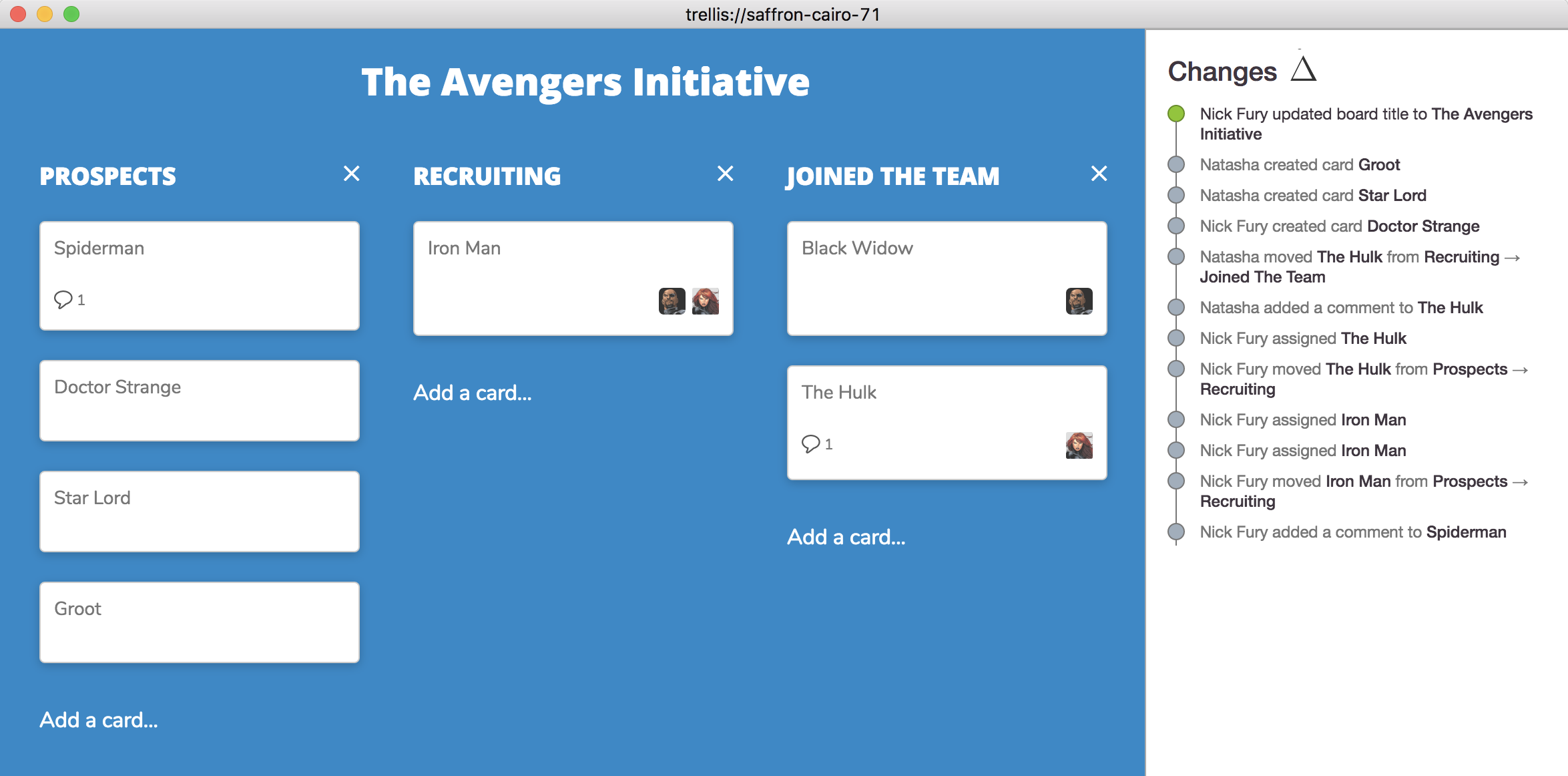
Trellis使用本地优先提供类似Trello的体验。右侧的更改历史记录反映了文档中所有活动用户所做的更改。
在这个项目中,我们在网络通信层尝试使用了WebRTC。
在用户体验方面,我们设计了一个基本的“变更历史”,灵感来自 Git 和 Google Docs 的“查看新的变更”,允许用户查看其看板上的操作,包括及时后退以查看文档的早期状态。
协同绘图
PixelPusher是一个协同绘图程序,为Javier Valencia的像素艺术(Pixel Art)提供了一种类似 Figma 的实时体验。
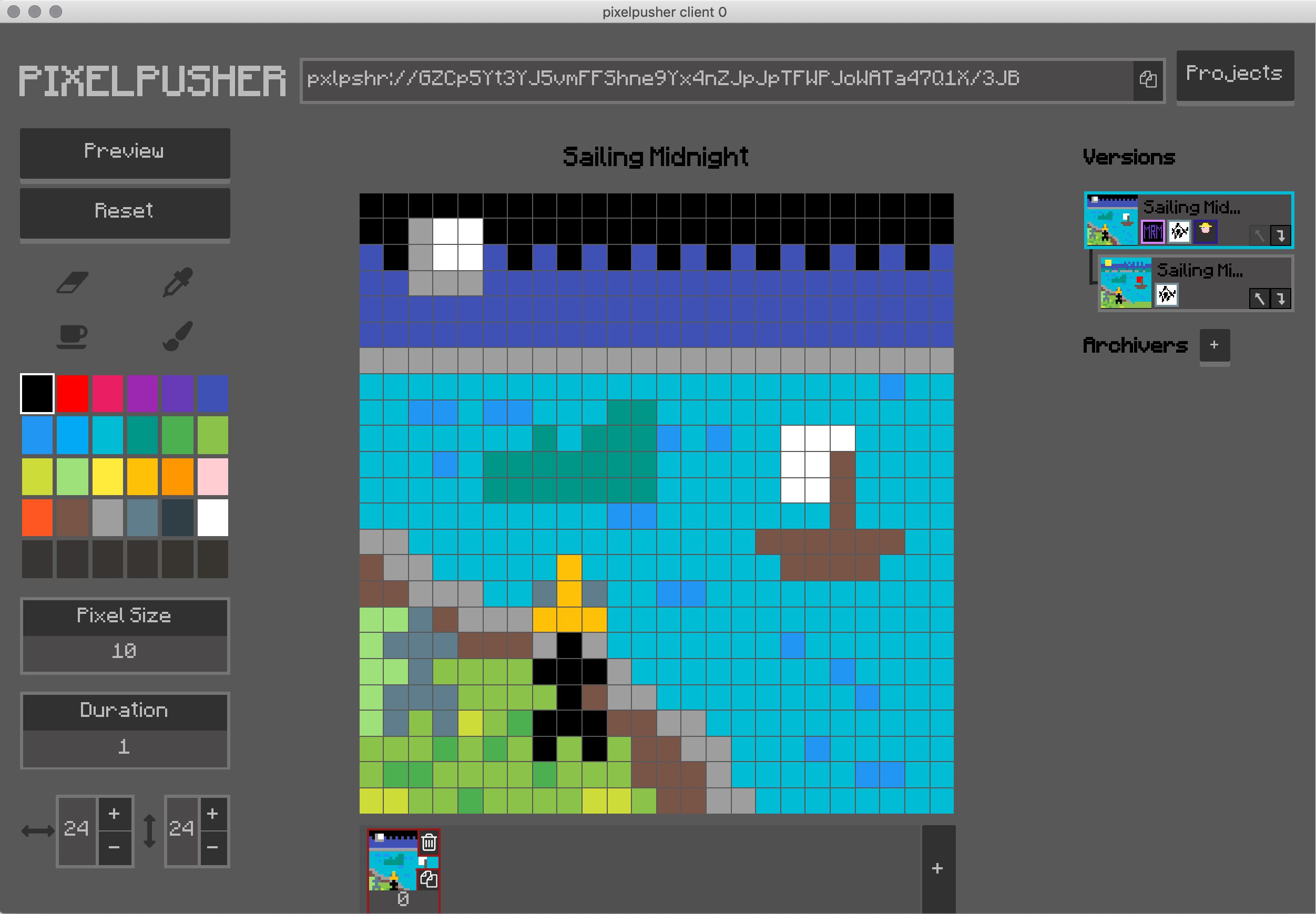
支持同步实时绘制。顶部的URL提供了与其他用户共享此文档的快捷方式。右侧的“版本”面板显示当前文档的所有分支。箭头按钮提供分支之间的实时合并。
在这个项目中,我们尝试通过Dat项目中的点对点库进行网络通信。
用户体验实验包括文档共享的 URL、受 Git 启发的可视分支/合并功能、突出显示红色的冲突像素的冲突解决机制,以及通过用户绘制的头像实现的基本用户标识。
媒体画布
PushPin是一个类似于Miro或Milanote的混合媒体画布工作区。作为我们第三个基于 Automerge 的项目,它是这三个项目中实现最完整的。我们的团队和外部测试用户的实际使用给底层数据层带来了更多的压力。
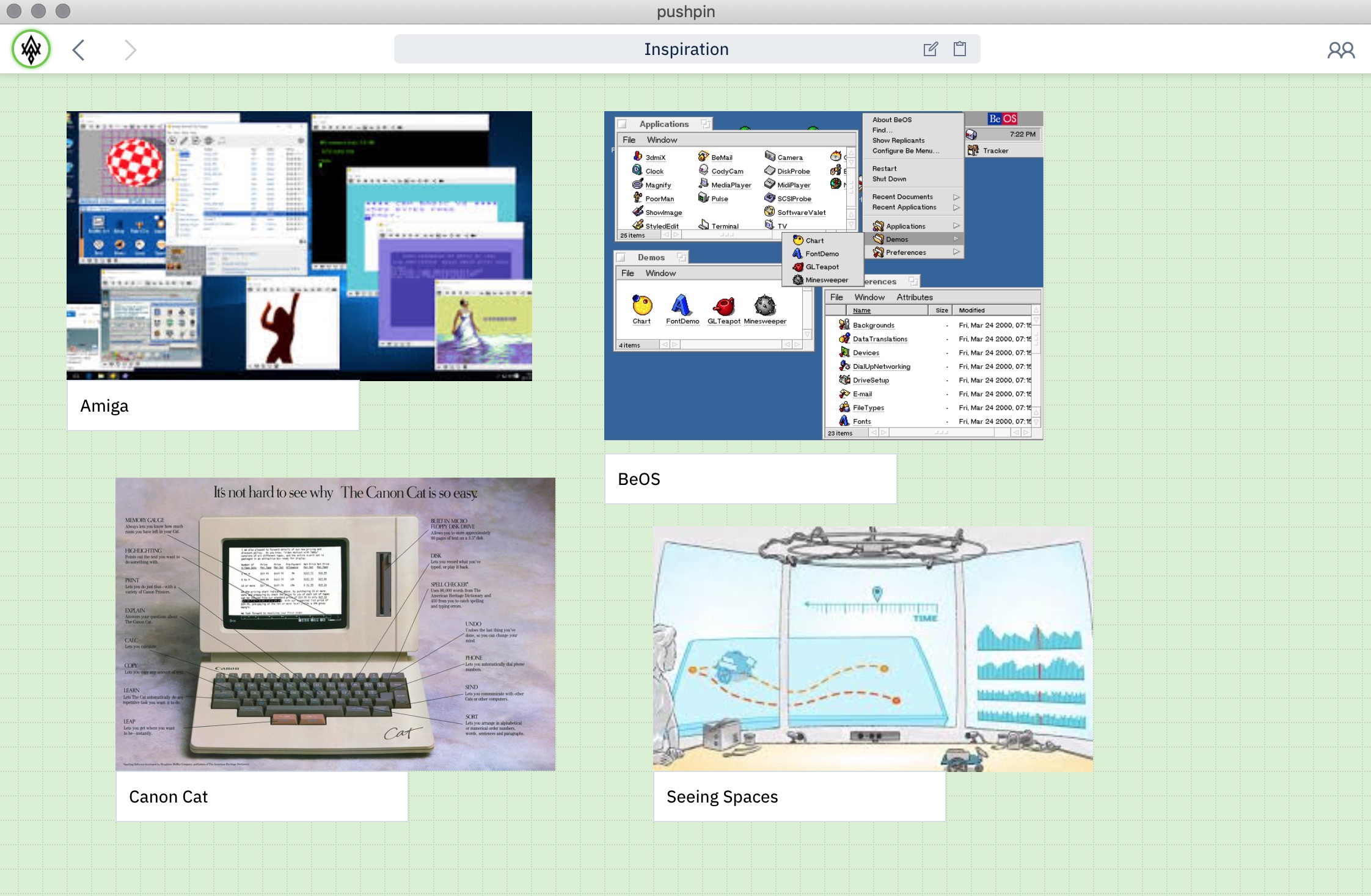
PushPin的画布混合了文本、图像、讨论线程和Web链接。用户通过工具栏中的状态头像互相查看,并使用URL栏在自己的文档之间导航。
PushPin 研究了嵌套和连接的共享文档、CRDT 文档的各种渲染器、更高级的标识系统,包括用于共享的“发件箱”模型,以及支持共享的临时数据(如选择突出显示)。
可观看PushPin演示视频或下载版本亲自试用。
研究发现
我们从构建和使用这些原型中学到了以下经验教训:
CRDT技术有效。
从一开始,我们就对 Automerge 的可靠性感到惊喜。我们团队中的应用程序开发人员能够相对轻松地集成库,并且数据的自动合并几乎总是直接而无缝的。
离线工作的用户体验非常出色。
离线,继续做想做的工作,然后重新连接与同事合并更改,整个过程工作得很好。当系统上的其他应用程序抛出错误(“离线!警告!”)并阻止用户工作时,无论网络状态如何,本地优先的原型都能正常运行。与基于浏览器的系统不同,永远不用担心应用程序是否工作,或者当用户需要时能否找到数据。正如我们所希望的那样,这让用户对他们的工具和工作拥有归属感。
反应式的 FRP 模型非常适合 CRDT。基于 CRDT 的数据层意味着用户的文档同时从本地用户(例如,当他们键入文本文档时)以及网络(当其他用户和其他设备对文档进行更改时)获得更新。
由于 FRP 模型能可靠地将应用程序的可见状态与共享文档的基础状态同步,因此开发人员可以跟踪来自其他用户的更改,并从调和当前视图的繁琐工作中解脱出来。此外,确保只能通过单个函数(“reducer”)对基础状态进行所有更改,可以轻松确保将所有相关的本地更改发送给其他用户。
这个模型的结果是,我们所有的原型都实现了实时协同和完全离线的功能,而应用程序开发人员几乎不费吹灰之力。这是一个重要的好处,因为它让应用程序开发人员关注他们的应用程序,而不是面对数据分发的挑战。
冲突并不像我们担心的那样严重。
我们很好奇用户在与他人协同时,在工作中会经常遇到冲突。我们惊喜地发现,用户有一种直觉的人类协同感,并避免与合作者产生冲突。在确实发生冲突的情况下,解决冲突的方式往往是随意的,无论哪种方式都令人满意。例如,如果两个用户修复了文档标题中的一个拼写错误,他们可能不会以同样的方式进行,但他们似乎并不关心选择的结果。
不同的用户会同时修改文档状态的不同部分,Automerge 可以毫不费力地合并这些更改。例如,对于看板应用程序,一个用户可以在卡片上发表评论,另一个用户可以将其移动到另一个列,合并的结果将反映这两个变化。
如果冲突解决不清楚,Automerge 会保留冲突的值,留给应用程序来解决它们。在 PixelPusher 的原型中,我们探索了用于解决冲突的用户界面。如何将这些特征与变更的历史检查相结合,是一个未解决的研究问题。
可视化文档的历史记录非常重要。
在分布式协同系统中,用户可以随时进行任意的更改。与通过服务器来调解变更的集中式系统不同,本地优先的应用需要找到自己的方案来解决这些问题。如果没有合适的工具,就很难理解文档外观怎么来的、文档有多少版本,或者贡献来自何处。
在 Trellis 项目中,我们尝试使用“时间旅行”界面,允许用户及时返回以查看合并文档的早期状态,并在收到其他用户的更改时自动突出显示最近更改的元素。用线性方式遍历那些具有潜在复杂性的合并文档的历史记录,这种能力有助于提供上下文,并且可以成为理解如何协同的通用工具。
URL是一种很好的共享机制。
我们尝试了许多与其他用户共享文档的机制,发现受 Web 启发的 URL 模型对用户和开发人员来说最有意义。URL 可以被复制、粘贴,并通过电子邮件或聊天等通信渠道共享。对机密 URL 以外的文档的访问权限仍然是一个未解决的研究问题。
点对点系统永远不会完全“在线”或“离线”,很难推断数据在其中的移动方式。
传统的集中式系统通常是“向上”或“向下”,由每个客户端通过保持与服务器的稳定网络连接的能力来定义。服务器确定给定数据的真实性。
在去中心化的系统中,我们的数据可能有千变万化的复杂性。任何用户可能对他们拥有、选择共享或接受的数据有不同的看法。例如,在飞机上的用户会用笔记本电脑对文档进行编辑,当飞机着陆并且计算机重新连接时,这些更改将被分发给其他用户。其他用户可能选择接受对其文档版本所做的全部、部分或全部更改。
文档的不同版本可能会导致混淆。与 Git 存储库一样,特定用户在“主”分支中看到的内容是上次与其他用户通信时的功能。新到达的更改可能会意外地修改正在处理的文档的某些部分,但手动合并每个用户的每个更改是很繁琐的。分散文档使用户能够控制自己的数据,但需要进一步研究来了解这在实际用户界面的术语中意味着什么。
CRDT累积了大量的更改历史记录,从而产生了性能问题。
我们的团队将 PushPin 用于“真实”文档,例如规划 Sprint。性能和内存/磁盘的使用率很快成为一个问题,因为 CRDT 会保存所有的历史记录,包括逐个字符的文本编辑。这些文件堆在一起,不容易被截断,因为无法知道有人可能在六个月之后重新连接到共享文档,并且需要从那时起合并更改。
我们将继续优化 Automerge,这是正在进行的工作的一个主要领域。
网络通信仍然是一个未解决的问题。
CRDT 算法只提供合并数据的功能,但对不同用户如何在同一台物理机上进行编辑却一无所知。
在实验中,我们尝试通过WebRTC进行网络通信,通过“SneakerNet”实现使用 Dropbox 和 USB 密钥来复制文件,可能会使用IPFS协议,并且最终选择了Dat的Hypercore点对点库。
CRDT 不需要点对点的网络层,使用服务器进行通信对 CRDT 来说是可行的。但是,为了充分实现本地优先的持久化目标,我们希望应用程序比其供应商管理的任何后端服务都持久,因此分散式解决方案是合乎逻辑的最终目标。
在我们的原型中使用 P2P 技术产生了不同的结果。一方面,这些技术远未达到可以发布的阶段,特别NAT遍历依赖于用户所连接的特定路由器或网络拓扑,还不是很可靠。但是 P2P 协议和去中心化网络社区所提出的承诺才是实质性的。在一个依赖于集中化 API 的世界里,没有互联网接入的计算机之间的实时协同感觉就像在玩魔术一样。
云服务器仍然可以用于探索、备份和突发计算(Burst Compute)。
像 PushPin 这样实时协同的原型,允许用户在没有中间服务器的情况下与其他用户共享文档。这非常适合隐私和所有权,可能会导致用户共享文档但和其他用户连接之前关闭了笔记本。如果用户不同时在线,他们就不能互相连接。
因此,服务器可以在本地优先的世界中发挥作用 — 不是作为中央机构,而是作为支持客户端应用程序而不在关键路径上的“云结对”(Cloud Peers)。例如,云结对保存文档的副本,并在其他结对机联机时将其转发,可以解决上述的笔记本关机问题。
Hashbase是Dat和Beaker Browser云结对和桥接的示例。
类似地,云结对可以用于:
存档/备份位置(特别是对于存储空间有限的电话或其他设备);
连接传统服务器API(例如天气预报或股票行情)的桥梁;
突发计算资源的提供者(例如使用强大的GPU渲染视频)。
传统系统与本地优先系统之间的关键区别不是缺少服务器,而是职责的改变:它们是支持角色,而不是事实的根源。
您能为我们做些什么
这些实验表明本地优先是可行的。协同和所有权并不是相互矛盾的 — 我们可以从两个方面都得到最好的结果,用户也可以从中受益。
但是,基础技术仍在研究进行中。它们适合开发原型,我们希望它们在未来几年内能够发展并稳定下来。但现实地说,目前还不建议在生产环境中使用像 Automerge 这样的实验项目来替换 Firebase 这样的成熟产品。
如果你像我们一样相信本地优先的未来,那么你(以及所有技术领域的人才)能做些什么来推动我们走向它?以下是一些建议:
对于分布式系统和编程语言研究人员
本地优先从最近对分布式系统的研究(包括 CRDT 和点对点技术)中获益匪浅。目前,研究界在提高 CRDT 的性能和功效方面取得了很大进展,我们热切期待这项工作的进一步成果。不过,还有一些有趣的进一步工作的机会。
大多数 CRDT 的研究工作都在一个模型中运行,所有合作者立即将他们所做的编辑应用到文档的单个版本中。但是,实际的本地优先应用需要更大的灵活性:用户必须能够自由拒绝其他协同者所做的编辑,或者对不与他人共享的文档版本进行私人更改。用户可能希望以推测方式应用更改或重新格式化更改的历史记录。在分布式源代码管理世界中,这些概念被很好地理解为“分支”、“分叉”、“变基”等。在同时存在多个文档版本和分支的情况下,对用于协同的算法和编程模型的了解工作还很少。
我们看到了更多关于类型、Schema 迁移和兼容性的有趣问题。不同的协同者可能正在使用不同版本的应用程序,可能具有不同的功能。由于没有中央数据库服务器,因此数据没有可信的“当前”Schema。我们如何编写软件,即使数据的格式在不断发展,不同的应用程序版本也可以安全地进行互操作?这个问题在基于云的 API 设计中有类似之处,但本地优先设置提出了额外的挑战。
对于人机交互(HCI)研究人员
对于集中式系统,今天在该领域中有大量示例表明它们与服务器的“同步”状态。去中心化系统有许多有趣的新机会来探索用户界面的挑战。
我们希望研究人员能够考虑如何进行在线和离线状态下的通信,或者其他用户可能持有不同数据副本的系统的可用和不可用状态。当每个人都是同伴时,我们应该如何考虑连接?当我们可以直接与其他节点协同而无法访问更广泛的互联网时,“在线”意味着什么?
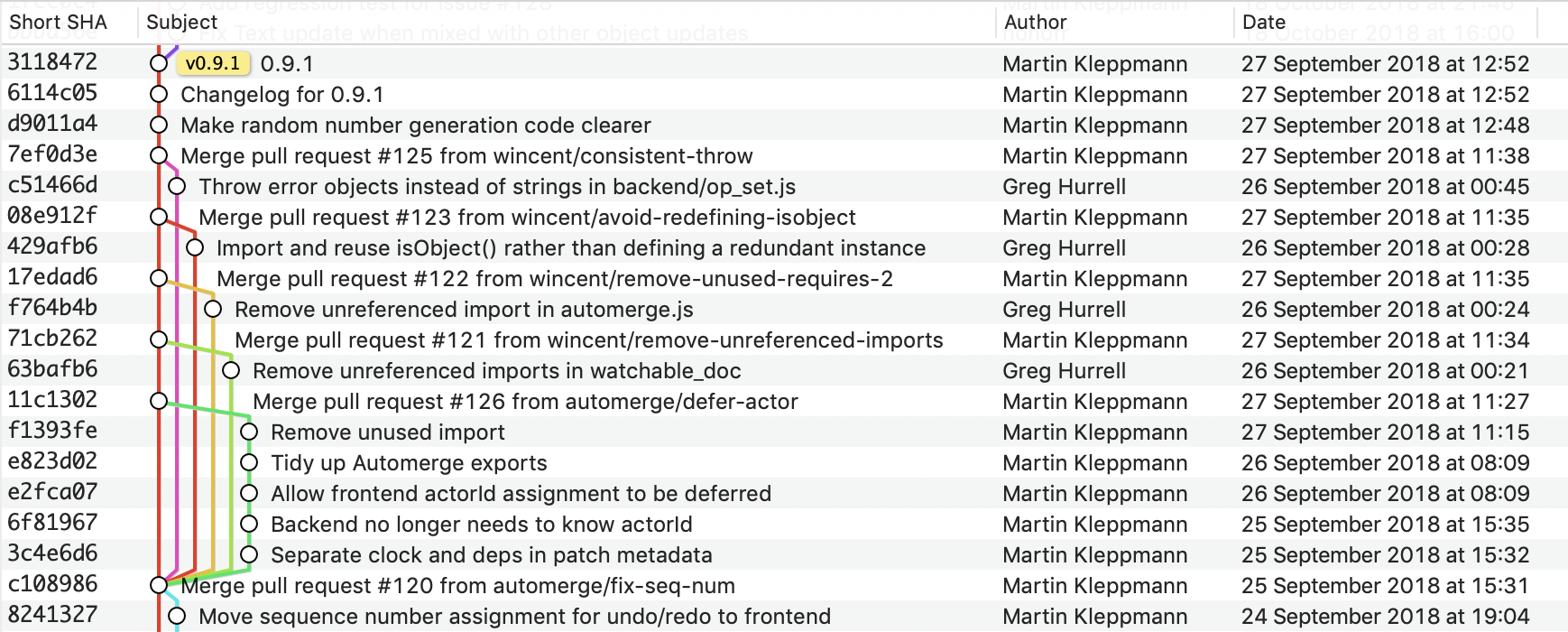
“铁路轨道”(Railroad Track)模型,在GitX中用于可视化Git存储库中源代码的历史结构。
当每个文档都可以开发复杂的版本历史时,只要通过日常操作,就会出现一个严重的问题:我们如何将这个版本历史记录传达给用户?用户应该如何考虑版本控制、共享和接受更改,以及理解当没有真正的事实来源时,他们的文档是如何以某种方式形成的?今天有两种主流的变更管理模型:差异和补丁的源代码模型,以及 Google Docs 的建议和评论模型。这些是我们能做到的最好的了吗?我们如何将这些想法概括为非文本的数据格式?我们渴望看到能被发现的东西。
虽然集中式系统严重依赖访问控制和权限,但相同的概念并不直接应用于本地优先的上下文。例如,不能阻止任何拥有某些数据副本的用户在本地修改它;但是,其他用户可以选择是否订阅这些更改。用户应该如何考虑共享、权限和反馈?如果我们无法从其他人的计算机上删除文档,那么“停止与其他人共享”意味着什么?
我们相信集中化的假设在我们今天的用户体验中根深蒂固,并且我们只是才开始发现改变这种假设的后果。我们希望这些开放式问题能激发研究人员去探索我们认为尚未开发的领域。
对于从业者
如果您是一名软件工程师、设计师、产品经理或独立的应用程序开发人员,正在开发准备发布的软件,能提供什么帮助?我们建议朝着本地优先的未来采取渐进的步骤。从给应用打分开始:
然后是改善每个方面的一些策略:
快速。主动缓存和提前下载资源可以防止用户在打开应用程序或以前打开的文档时等待。默认情况下信任本地缓存,而不是让用户等待网络获取。
多设备。同步基础设施(如FireBase和iCloud)使多设备相对轻松,尽管它们确实带来了持久和隐私问题。像Realm对象服务器这样的自托管基础架构提供了另一种替代的权衡。
离线。在网络世界中,Progressive Web应用提供诸如服务工作者和应用程序清单之类的功能可以提供帮助。在移动世界中,请注意WebKit框架和其他依赖于网络的组件。通过关闭WiFi或使用网络链接调节器(如Chrome Dev Tools网络条件模拟器或iOS网络链接调节器)来测试应用。
协同。除了CRDT之外,更成熟的实时协同技术是运营转型(Operational Transformation,OT),像在ShareDB中实现的那样。
持久。确保软件可以很容易地导出为扁平的标准格式,如JSON或PDF。例如:Google Takeout大量导出;GoodNotes连续备份到稳定的文件格式;Trello下载JSON文档。
隐私。云应用基本上是非私有的,公司和政府的员工可以随时查看用户数据。但对于移动或桌面应用程序,请尝试向用户明确数据仅存储在其设备上,而不是传输到后端。
用户控制。用户是否可以轻松地备份、复制或删除应用程序中的部分或全部文档?这通常涉及重新实现所有的基本文件系统操作,就像Google Docs对Google Drive所做的一样。
呼吁创业公司
如果您是一位对开发人员基础设施建设感兴趣的企业家,以上所有的建议都是有趣的市场机会:“Firebase for CRDTs”。
这样的创业需要提供优秀的开发人员体验和本地持久性库(如 SQLite 或 Realm)。它需要适用于移动平台(iOS、Android),本地桌面(Windows、Mac、Linux)和 Web 技术(Electron、Progressive Web 应用)。
用户控制、隐私、多设备支持和协同都是必不可少的。应用程序开发人员可以专注于构建他们的应用程序,因为他们知道最简单的实现路径也会在本地优先的记分卡上给出最高分。作为检验是否成功的试金石,我们建议思考:即使所有服务器都关闭了,所有客户的应用程序是否会持续工作?
我们相信,随着 CRDT 的成熟,“Firebase for CRDT”的机会将是巨大的。
结论
计算机是人类有史以来最重要的创造性工具之一,软件已经成为我们完成工作的管道和工作所在的存储库。
为了追求更好的工具,我们将许多应用迁移到云端。云上的软件在很多方面都优于“老式”软件:它提供了协同性的、始终最新的应用程序,可从世界任何地方访问。我们不再担心正在运行的软件版本,或者文件所在的机器是什么。
然而,云上数据的所有权属于服务器,而不是用户,因此我们成为了自己数据的借用者,在云应用中创建的文档注定会在这些服务的创建者停止维护时消失。云服务无法长期保存,Wayback Machine(译者注:一个提供备份的网站,被称为互联网时光机)也无法恢复被弃用的 Web 应用,Internet 备份也无法保留您的 Google Docs。
在本文中,我们探索了未来软件发展的新途径。我们已经证明,用户可以保留对数据的所有权和控制权,同时还可以从与云相关的功能中受益:无缝协同和随时随地访问。两个世界都有可能做到最好。
但在实践中,要实现本地优先,还需要做更多的工作。应用程序开发人员可以采取增量的步骤,例如改进离线支持并更好地利用设备上的存储。研究人员可以继续改进本地优先软件的算法、编程模型和用户界面。企业家可以将 CRDT 和点对点网络等基础技术开发成能够为下一代应用提供动力的成熟产品。
今天,很容易创建一个 Web 应用程序,服务器拥有所有数据的所有权。但是,要构建尊重用户所有权和代理权的协同软件太难了。为了改变这种平衡,我们需要改进开发本地优先软件的工具。我们希望您加入我们。
原文链接:https://www.inkandswitch.com/local-first.html

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论