

机器翻译系统中,非平行数据的训练和解码一直是个挑战。不久前,今日头条和南京大学联合提出了基于镜像生成的NMT,它是一个统一的体系结构,包含目标-源转换模型、源-目标转换模型和两个语言模型,翻译模型和语言模型在同一个隐语义空间,因此,两个翻译方向都可以有效地从非平行数据中学习,对于提升翻译质量非常重要。该论文已被ICLR2020录用。本文是AI前线第106篇论文导读,我们将对这项研究工作进行详细解读。
概览
神经机器翻译(NMT)系统在有大量双语平行数据可供训练的情况下,提供了相当不错的翻译结果。但是,在大多数机器翻译场景中,获得如此大量的平行数据并不容易。例如,有许多 low-resource 语言对(如,英语到泰米尔语),它们缺乏足够的平行数据用于训练。此外,由于测试域和训练用的平行数据之间存在较大的域差异,如果域内平行数据(如医学域)有限,通常很难将 NMT 模型应用到其他域。在这些平行双语数据不充分的情况下,充分利用非平行双语数据(通常获取成本很低)对于获得令人满意的翻译效果至关重要。
我们认为,在训练和解码阶段,目前利用非平行数据的 NMT 方法并不一定是最好的。对于训练,反向翻译(Sennrich 等人,2016)对于单语数据是利用最广泛的方法。但是,反向翻译对机器翻译模型的两个方向分别进行了更新,并不是最有效的。
具体来说,在给定源语言的单语数据 x 和目标语言的单语数据 y 的情况下,反向翻译通过应用 tgt2src 翻译模型(TMy→x),利用 y 得到预测的译文 xˆ。然后利用伪翻译对⟨xˆ,y⟩更新 src2tgt 翻译模型(TMx→y)。x 可以用同样的方式更新 TMy→x。注意这里 TMy→x 和 TMx→y 是独立的和最新的。也就是说,TMy→x 的每一次更新都不会直接对 TMx→y 有益处。一些工作像联合反向翻译和对偶学习引入迭代训练,使 TMy→x 和 TMx→y 隐式、迭代地相互受益。但是这些方法中的翻译模式仍然是独立的。理想情况下,如果我们有相关的 TMy→x 和 TMx→y,则非平行数据的收益可以被放大。在这种情况下,每次更新 TMy→x 后,我们可以直接得到更好的 TMx→y,反之亦然,从而更有效地利用非平行数据。
在解码方面,一些相关工作(Gulcehre 等人,2015 年)建议将外部语言模型 LMy(单独针对目标单语数据进行训练)插入到翻译模型 TMx→y 中,其中包括来自目标单语数据的知识,以便更好地翻译。这对于领域适应特别有用,因为我们可以通过更好的 LMy 获得更适合领域(例如,社交网络)的翻译输出。然而,在解码时直接插入一个独立的语言模型可能不是最好的。首先,这里使用的语言模型是外部的,仍然独立于翻译模型学习,因此两个模型可能无法通过简单的插值机制(甚至冲突)很好地协作。此外,语言模型只包含在解码中,而在训练中不考虑。这就导致了训练和解码的不一致性,从而影响了系统的性能。
本文提出了镜像生成 NMT(mirror generative NMT,MGNMT)来解决上述问题,有效地利用 NMT 中的非平行数据。MGNMT 提出在统一的框架下联合训练翻译模型(TMx→y 和 TMy→x)和语言模型(LMx 和 LMy),这是非常重要的。受生成 NMT(Shah&Barber,2018)的启发,我们提出引入一个在 x 和 y 之间共享的隐语义变量 z。我们的方法利用对称性或镜像特性,分解条件联合概率 p(x,y | z),即:
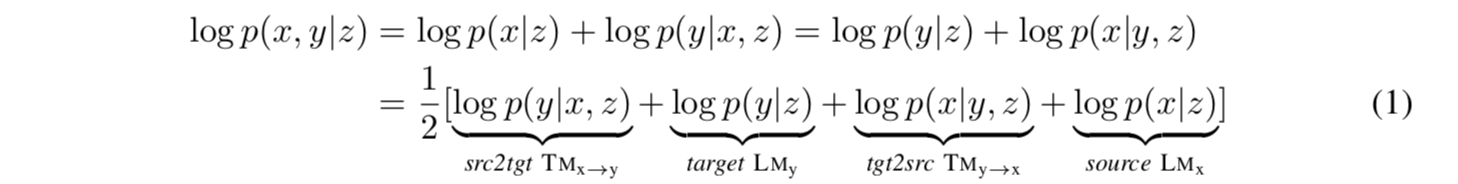
MGNMT 的图模型如图 1 所示。MGNMT 通过一个共享的隐语义空间将两种语言中的双向翻译模型和语言模型对齐(图 2),以便所有这些模型都是相关的,并且在给定 z 的情况下成为条件无关的。在这种情况下,MGNMT 具有以下优点:
在训练中,由于z是一个桥梁,TMy→x和TMx→y不是独立的,因此一个方向的每次更新都会直接有利于另一个方向,就像“1+1>2”的效果一样。这提高了使用非平行数据的效率。(第3.1节)
对于解码,MGNMT可以自然地利用其内部的目标侧语言模型,该模型是与翻译模型共同学习的。他们共同为更好的生成过程做出了贡献。(第3.2节)
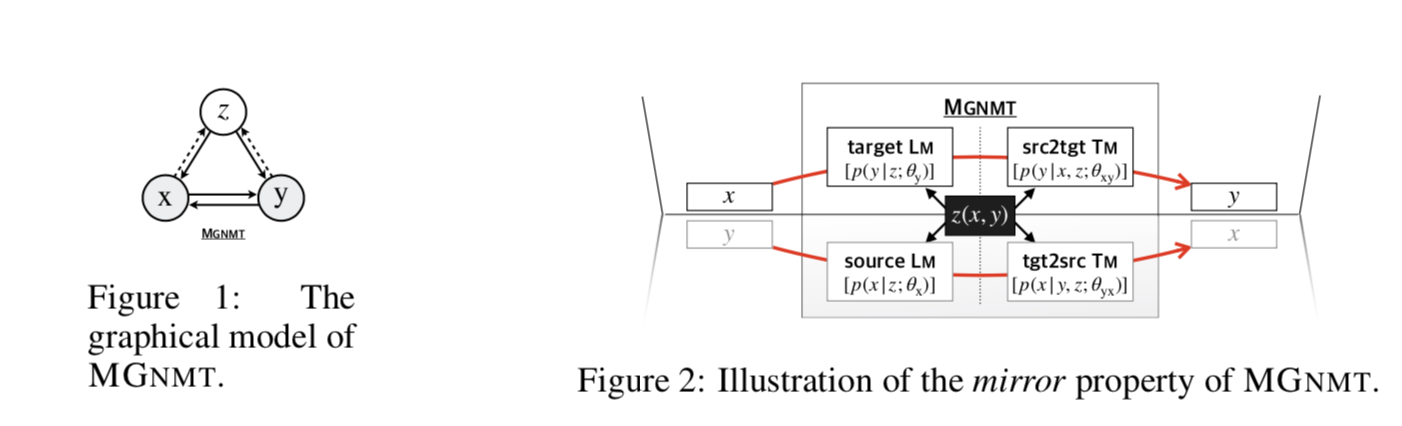
注意,MGNMT 与对偶学习和联合反向翻译(Zhang 等人,2018)是正交的。MGNMT 中的翻译模式是相互依赖的,两种翻译模式可以直接相互促进。不同的是,对偶学习和联合翻译的方法是有效的,而且这两种方法也可以用来进一步提高 MGNMT。对偶学习中使用的语言模型面临着与(Gulcehre 等人,2015 年)同样的问题。给定 GNMT,所提出的 MGNMT 也是有意义的。GNMT 只有一个源端语言模型,因此它不能像 MGNMT 那样增强解码。此外,在(Shah&Barber,2018),他们要求 GNMT 在翻译模型之间共享所有参数和词汇,以便利用单语数据,而这并不最适合远距离语言对。我们将在有关工作中作更多的比较。
实验表明,MGNMT 在平行双语数据上具有很强的竞争力,而 MGNMT 在非平行数据上具有很强的训练能力,在不同的场景和语言对下,包括资源丰富的场景和资源贫乏的场景下,MGNMT 在低资源的语言翻译上均优于多个强基线跨域翻译。此外,我们还发现,当 MGNMT 的联合学习翻译模式和语言模式协同工作时,翻译质量确实会提高。我们还证明了 MGNMT 是无结构的,可以应用于任何神经序列模型,如 Transformer 和 RNN。这些证据证明 MGNMT 满足我们充分利用非平行数据的期望。
镜像生成神经机器翻译
我们提出了镜像生成 NMT(MGNMT),这是一种新的深度生成模型,它以高度集成的方式同时对 src2tgt 和 tgt2src(variational)翻译模型以及一对源和目标(variational)语言模型进行建模。因此,MGNMT 可以从非平行的双语数据中学习,并在解码过程中用翻译模型自然地插值其学习的语言模型。
MGNMT 的总体架构如图 3 所示。MGNMT 利用联合概率的镜像性质,建立了双语句子对上的联合分布模型:log p(x,y | z)=1/2 [log p(y | x,z)+log p(y | z)+log p(x | y,z)+logp(x | z) ],其中 ,潜在变量 z(我们使用标准高斯先验 z∼N(0,I))表示 x 和 y 之间的共享语义,充当所有集成翻译和语言模型之间的桥梁。
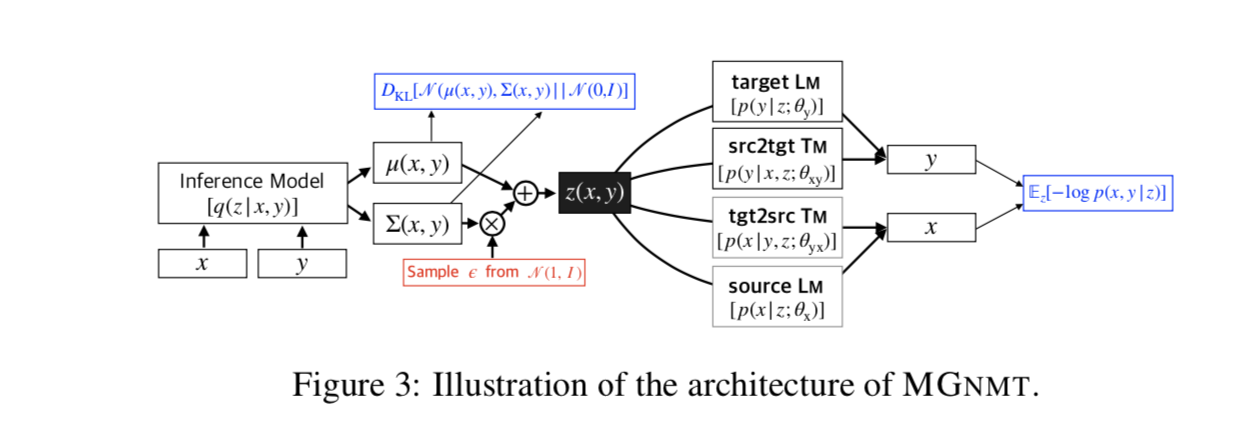
训练
平行数据学习
我们首先介绍如何在一个规则的双语平行数据上训练 MGNMT。给出了一个平行双语言句子对⟨x,y⟩,我们使用随机梯度变分 Bayes(SGVB)(Kingma&Welling,2014)对对数 p(x,y)进行近似最大似然估计。我们将近似后验 q(z | x,y;φ)=N(μφ(x,y),∑φ(x,y))参数化。从方程(1)可以得到联合概率对数似然的证据下界(ELBO)L(x,y;θ;φ)为:
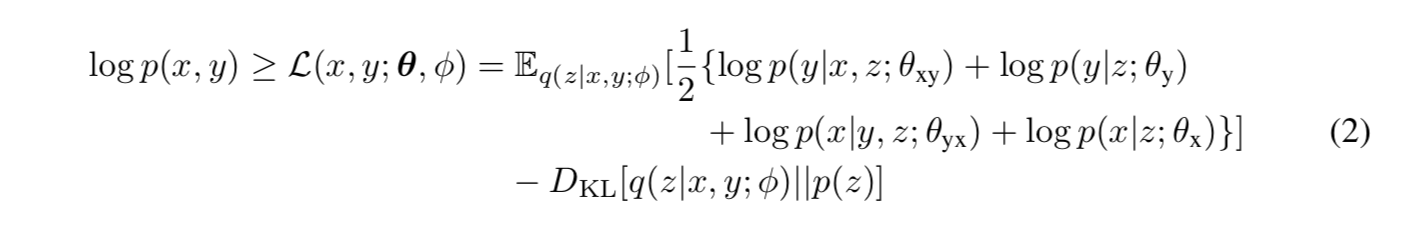
其中θ={θx,θyx,θy,θxy}是翻译和语言模型的参数集。第一项是句子对的(期望)对数似然。期望值是通过蒙特卡洛抽样得到的。第二项是 z 的近似后验分布和先验分布之间的 KL 散度。借助于重新参数化技巧(Kingma&Welling,2014),我们现在可以使用基于梯度的算法联合训练所有组件。
非平行数据学习
由于 MGNMT 本质上是一对镜像翻译模型,我们设计了一种迭代训练方法来开发非平行数据,在这种方法中,MGNMT 的两个方向都可以从单语数据中获益,并相互促进。算法 1 中给出了非平行双语数据的训练过程。

形式上,给定非平行双语句子,即来自源单语数据集 Dx={x(s)| s=1…s}的 x(s)和来自目标单语数据集 Dy={y(t)| t=1…t}的 y(t),我们的目标是最大化它们的边缘分布的可能性下限:
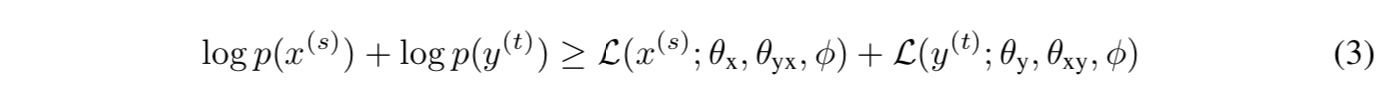
其中,L(x(s);θx,θyx,φ)和 L(y(t);θy,θxy,φ)分别是源和目标边缘对数像的下界。
我们以 L(y(t);θy,θxy,φ)为例。受(Zhang 等人,2018)启发,我们将源语言中的 x 和 p(x | y(t))作为 y(t)的翻译(即反向翻译)进行抽样,得到一个伪平行句子对<x,y(t)>。因此,我们给出了方程(4)中 L(y(t);θy,θxy,φ)的形式。同样,等式(5)适用于 L(y(t);θy,θxy,φ)。(其推导见附录)。
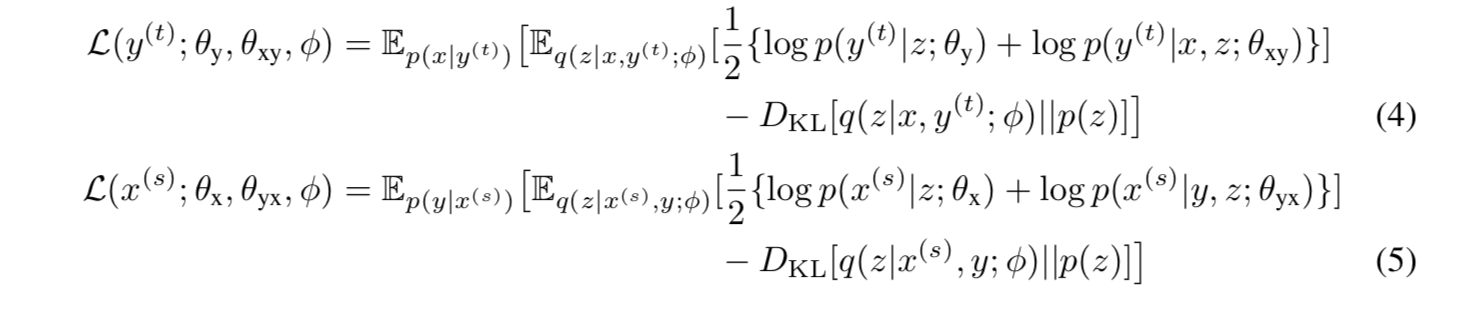
方程(3)中包含的参数可通过基于梯度的算法进行更新,其中偏差在镜像中计算为方程(6)和综合行为:
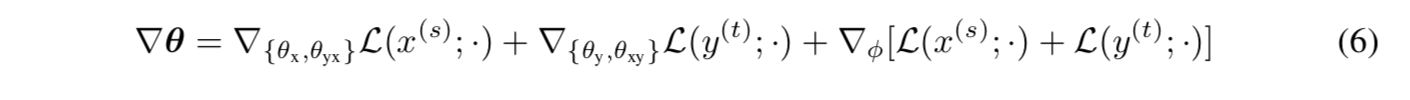
利用非平行数据的整个训练过程在某种程度上与联合反向翻译有相似的想法(Zhang 等人,2018)。但它们只利用非平行数据的一侧来更新每次迭代的一个方向的转换模型。共享的近似后验 q(z|x,y;φ)作为一个桥梁,因此 MGNMT 的两个方向都可以从单语数据中受益,达到“1+1>2”的效果。此外,MGNMT 的“反向翻译”伪翻译通过高级解码过程(见等式(7))得到了改进,从而获得了更好的学习效果。
解码
由于同时对翻译模型和语言模型进行建模,MGNMT 现在能够通过对翻译模型和语言模型的概率进行自然插值来解码。这使得 MGNMT 在译入语方面具有更高的流利性和质量。
由于 MGNMT 的镜像性质,解码过程也具有对称性:给定一个源语句 x(或目标语句 y),我们希望找到 y=argmax y p(y|x)=argmax y p(x,y)(x=argmaxx p(x| y ) = argmaxx p(x,y))的翻译,该翻译近似于 GNMT 中 EM 解码算法思想的镜像变体(Shah&Barber,2018)。算法 2 说明了我们的解码过程。

以 srg2tgt 翻译为例。给定一个源语句 x,1)我们首先从标准高斯先验中选取一个初始 z,然后得到一个初始草稿翻译为̃=argmaxy p(y | x,z);2)此翻译通过这次从近似后验 q(z | x,ỹφ)中重新采样 z 来迭代细化,并通过最大化 ELBO 来使用 beam 搜索重新解码:

现在,每一步的解码分数都由 TMx→y 和 LMy 给出,这有助于发现一个句子 y 不仅是 x 的翻译,而且在目标语言中更为可能。重建排序分数由 LMx 和 TMy→x 给出,在生成翻译候选后使用。MGNMT 可以利用这类分数对候选译文进行排序,并确定对源句最忠实的译文。它本质上与(Tu 等人,2017)和(Cheng 等人,2017)有相同的想法利用双语语义对等作为规范。
实验
数据集
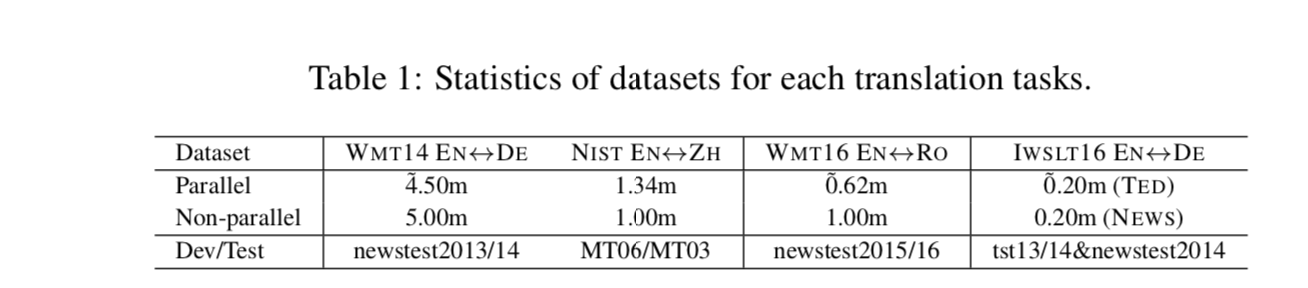
为了在资源匮乏的情况下评估我们的模型,我们进行实验在 WMT16 English-to/from-Romanian 翻译任务上作为低资源翻译和 IWSLT16 English-to/from-German (IWSLT16 EN↔DE)的翻译任务作为跨域翻译的 TED 会话并行数据。对于资源丰富的场景,我们在 WMT14 English-to/from- German (WMT14 EN↔DE)上进行了实验,NIST English-to/from-Chinese (NIST EN↔ZH)翻译任务。对于所有语言,我们都使用来自 News Crawl 的非平行数据,除了 NIST EN↔ZH,从 LDC 语料库中提取汉语单语数据。表 1 列出了统计数据。
实验设置
我们在 Transformer(Vaswani 等人,2017)和 RNMT(Bahdanau 等人,2015),GNMT(Shah&Barber,2018)以及 Pytorch 上实现了我们的模型。对于所有语言对,句子使用字节对编码(Sennrich 等人,2016)和 32k 合并操作进行编码,这些操作仅从平行训练数据集的连接中联合学习(NIST ZH-EN 除外,其 BPE 是单独学习的)。我们使用 Adam optimizer 与(Vaswani 等人,2017)的学习率优化策略相同,4k warmup steps。每个小批量分别由大约 4096 个源和目标令牌组成。我们在一个 GTX 1080ti GPU 上训练我们的模型。为了避免在 DKL(q(z)| | p(z))接近于零的趋势下学习忽略潜在表征的近似后验“collapses”,我们应用 KL-annealing 和单词 dropout 来对抗这一效应。在所有实验中,单词的 dropout 率都被设置为 0.3 的常数。老实说,退火 KL 权重有点棘手。表 2 列出了验证集上每个任务的最佳 KL 退火设置。翻译评估指标是 BLEU(Papineni 等人,2002)。

实验结果和讨论
如表 3 和表 4 所示,MGNMT 在资源贫乏和资源丰富的情况下均优于我们的竞争 Transformer 基线(Vaswani 等人,2017 年)、基于 Transformer 的 GNMT(Shah&Barber,2018 年)和相关工作。
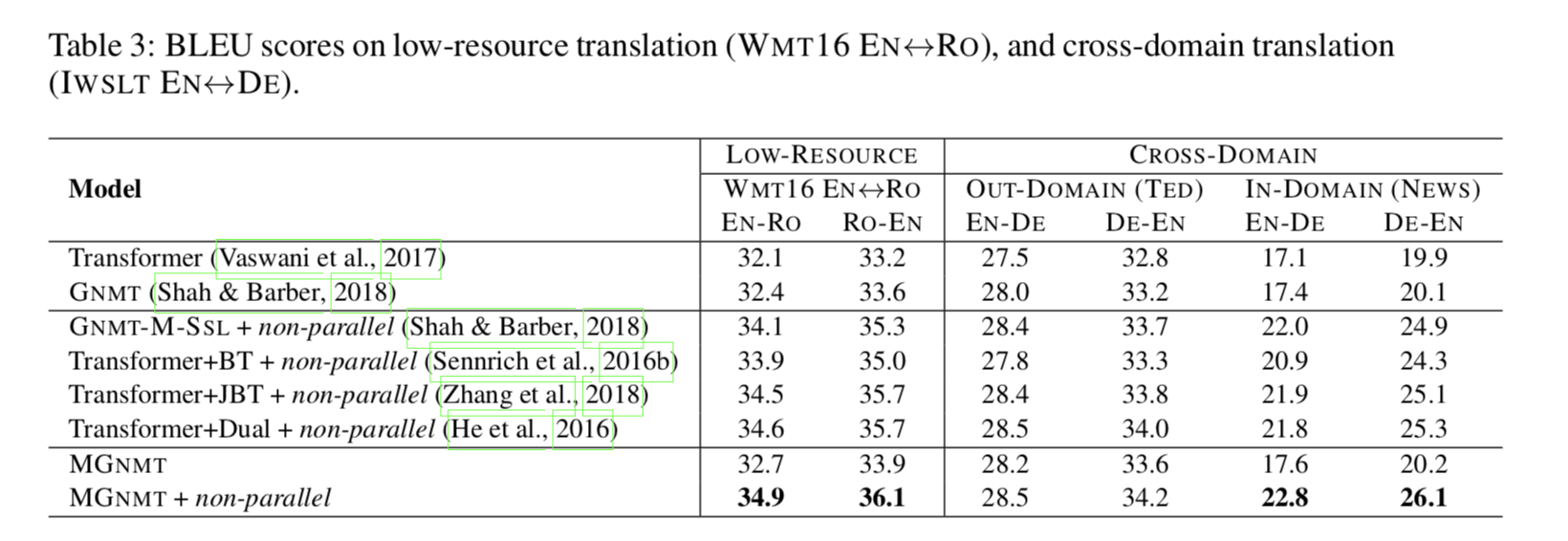
MGNMT 更好地利用了非平行数据 如表 3 所示,在两种资源匮乏的情况下,MGNMT 均优于我们的竞争 Transformer 基线(Vaswani 等人,2017 年)、基于 Transformer 的 GNMT(Shah&Barber,2018 年)和相关工作。
在低资源语言对上 该方法在缺乏双语数据的情况下,比传统方法和 GNMT 方法有了一定的改进。利用非平行数据可以获得很大的改进空间。
跨领域翻译 为了评估我们的模型在跨域集合中的能力,我们首先对来自 IWSLT 基准的 TED 数据进行域内训练,然后将模型暴露于域外新闻非平行双语数据中,从新闻爬网到域内知识访问。如表 3 所示,对于域内训练数据不可见会导致 Transformer 和 MGNMT 的域内测试集性能不佳。在这种情况下,域内非平行数据贡献显著,导致 5.7∼6.4 BLEU 增益。
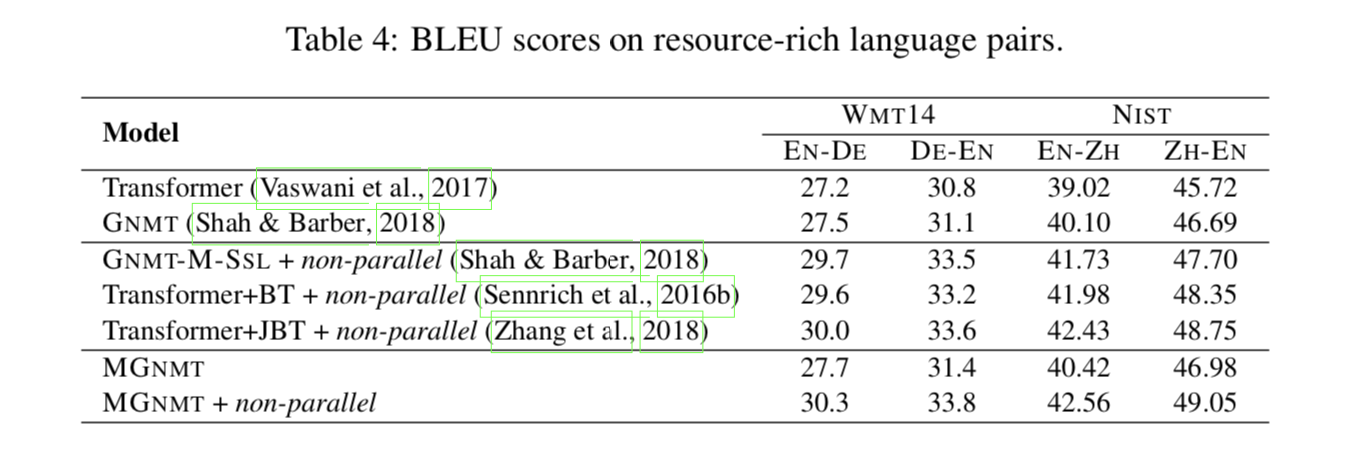
关于资源丰富的场景 我们还定期对两种资源丰富的语言对进行翻译实验,例如,EN↔DE 和 NIST EN↔ZH。如表 4 所示,在纯平行设置下,MGNMT 可以获得与判别基线 RNMT 和生成基线 GNMT 相比的可比结果。我们的模型在非平行双语数据的辅助下也能取得比以前的方法更好的性能,与资源贫乏情况下的实验结果一致。
与其他半监督工作的比较 我们将我们的方法与成熟的方法进行比较,这些方法也是为利用非平行数据而设计的,包括反向翻译(Sennrich et al.,2016b,Transformer+BT)、联合反向翻译训练(Zhang et al.,2018,Trans-Forder+JBT)、多语言和半监督的 GNMT 变体(Shah&Barber,2018,GNMT-M-SSL),以及对偶学习(He 等人,2016,Transformer+dual)。如表 3 所示,当将非平行数据引入低资源语言或跨域翻译时,所有列出的半监督方法都得到了实质性的改进。其中,我们的 MGNMT 成绩最好。同时,在资源丰富的语言对中,结果是一致的。我们认为,由于联合训练的语言模型和翻译模型能够协同解码,因此 MGNMT 优于联合反向翻译和对偶学习。有趣的是,我们可以看到 GNMT-M-SLL 在 NIST EN↔ZH 上的性能很差,这意味着参数共享不太适合远程语言对。研究结果表明,该方法在跨域场景下,具有很好的促进低资源翻译和从非并平行数据中挖掘领域相关知识的能力。
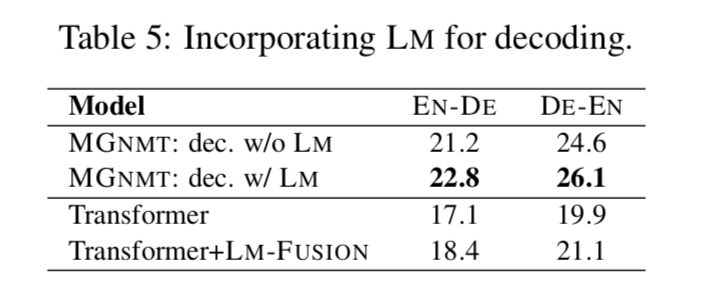
MGNMT 在解码时更善于结合语言模型 此外,我们从表 5 中发现,简单的 NMT 和外部 LM 插值(分别针对目标侧单语数据进行训练)(Gulcehre 等人,2015,Transformer-LM-FUSION)仅产生轻微的效果。这可以归因于不相关的概率建模,这意味着像 MGNMT 这样更自然的集成解决方案是必要的。除此之外,我们发现对于 MGNMT,解码收敛于 2∼3 次迭代,这消耗了∼2.7×的时间作为 Transformer 基线。减小速度的牺牲将是我们未来的方向之一。
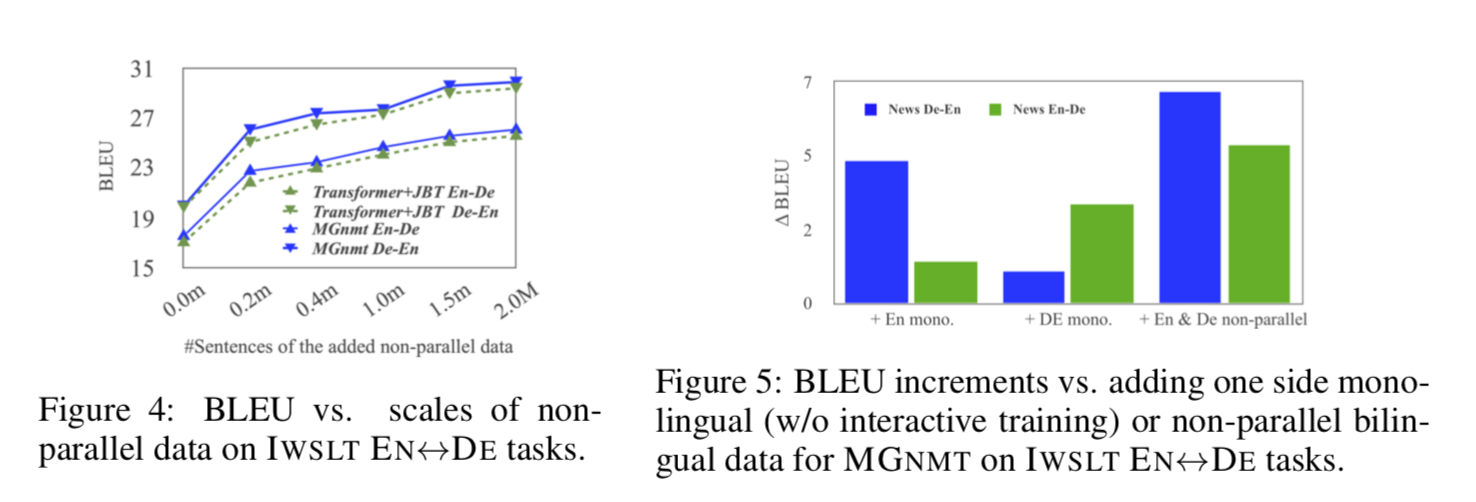
非平行数据的影响 我们在 IWSLT-EN↔DE 上进行了关于非平行数据尺度的实验来调研收益与数据量表之间的关系。如图 4 所示,随着非平行数据量的增加,所有模型逐渐变强。MGNMT 在所有数据尺度上都始终优于 Transformer+JBT。然而,增长率下降可能是由于非平行数据的噪声。我们还研究了非平行数据的一侧是否有利于 MGNMT 的两个翻译方向。如图 5 所示,我们惊奇地发现,仅使用单语数据,例如英语,也可以稍微提高英语到德语的翻译,这符合我们对“1+1>2”效果的预期。
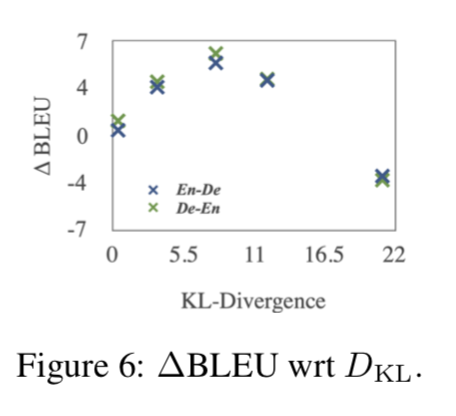
隐变量 x 的影响 经验上,图 6 显示当 KL 项接近 0 时(z 变得不详细)收益变小,而过大的 KL 会产生负面影响;同时,表 2 显示 DKL[q(z)| | p(z)]的值是相对合理的;此外,从零 z 解码导致大的损失。这表明 MGNMT 学习了一个有意义的双语隐变量,并且在很大程度上依赖于它来模拟翻译任务。此外,MGNMT 还通过使用基于有意义语义 z 的语言模型进一步改进了解码(表 5)。这些证据表明了 z 的必要性。
结论
为了更好地利用非平行数据,本文提出了镜像生成 NMT 模型。MGNMT 在共享双语语义的潜在空间中共同学习双向翻译模型以及源语和目标语模型,在这种情况下,MGNMT 的两个翻译方向可以同时受益于非平行数据。此外,MGNMT 可以很自然地利用其学习到的目标侧语言模型进行解码,从而获得更好的生成质量。实验结果表明,该方法在所有研究场景中均优于其他方法,在训练和解码方面均有一定优势。在以后的工作中,我们将研究 MGNMT 是否可以在完全无监督的环境中使用。
论文原文链接:
https://openreview.net/forum?id=HkxQRTNYPH

InfoQ高级编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论