

本文是本教程的第三部分,在本文中,我将构建不同的预测模型,并比较结果。 你可以先阅读本教程的第一部分和第二部分,也可以在文末找到本文完整代码的链接。 现在,让我们来构建模型!
对数据帧进行子集化,并将分类变量转换为虚拟变量
为了构建模型,我去掉了“ fav_grp ”一列,因为我们在教程第二部分探索性数据分析中看到的那样,有太多的团体,而 BTS 是占主导地位的团体。
然后,我得到虚拟数据,将分类变量转换为回归模型的虚拟/指标变量。
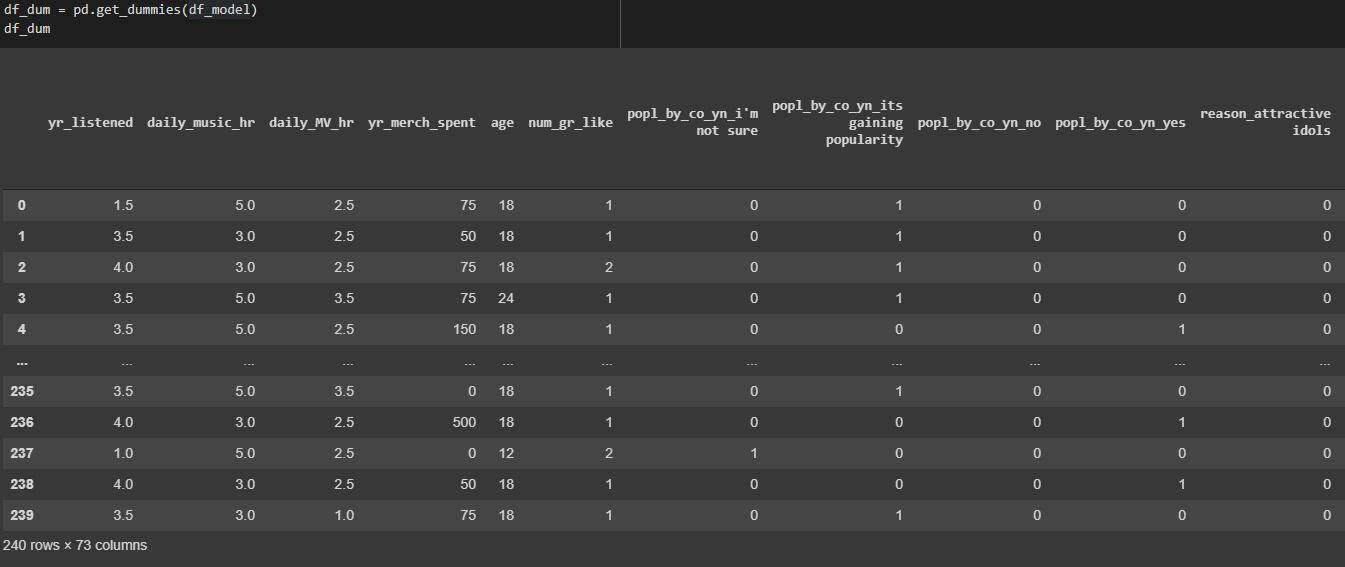
获取虚拟数据来转换分类变量
训练和测试拆分
主要目的是利用其它自变量来预测“ daily_music_hr ”,即韩国流行音乐歌迷听歌的小时数。
设 X 为“ daily_music_hr ”之外的所有其他变量,设 Y 为“ daily_music_hr ”。然后,使用 80%作为训练集,剩下的 20%作为测试集。
多元线性回归
由于我们的数据集很小(只有 240 行),所以我们希望避免使用复杂的模型。因此,让我们从多元线性回归开始。
对于度量,我们将使用 MAE(Mean Absolute Error,平均绝对误差)来检查模型的正确性。
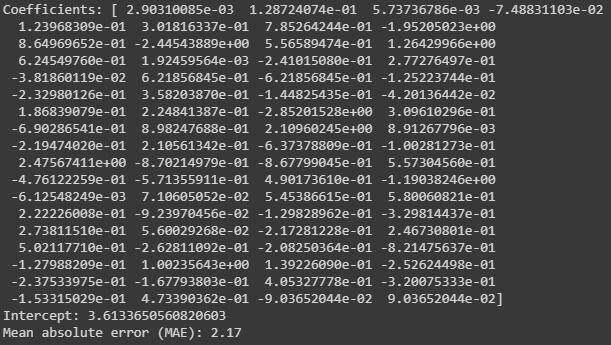
多元线性回归的悉数和 MAE
多元线性回归(Multiple Linear Regression,MLR)模型的 MAE 为 2.17。这意味着我们的预测平均误差为 2.17 小时。由于韩国流行音乐歌迷听歌时间从 0 小时到 10 小时不等,这是相当合理的。但是,让我们看看是否还可以做得更好。
在相同的多元回归模型中,我们将应用 10 倍交叉验证对数据进行泛化。10 倍交叉验证的工作原理是这样的:它在数据中创建 10 个组,留下 1 个组进行验证,使用剩下的 9 个组进行训练。最终,它创建了 10 个不同的 MAE。
然后,我们取它们的平均值,得到一个 MAE:1.98。
我们可以看到它比上面的稍微好一些。

使用 10 倍交叉验证的 MAE 用于 MLR
套索回归
在构建模型时处理小数据的另一种方法是使用正则化模型。Lasso( L east A bsolute S hrinkage and S election O perator,最小绝对值收敛和选择算子)使用收缩(alpha)。收缩是指数据值乡中心店收缩,比如均值。
它应用 L1 正则化,增加了一个等于系数大小绝对值的惩罚。
Lasso 的 MAE 为 1.58。
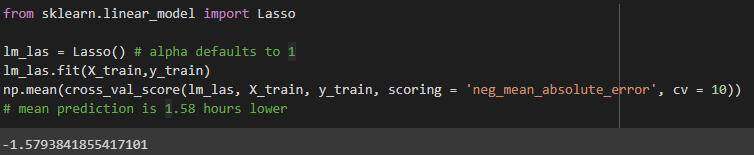
用于套索回归的 MAE
我们也可以尝试找到最佳的 alpha,以找到最好的 Lasso 模型。
我们看到最佳的 alpha 值为 0.09,MAE 现在稍微好一些:1.57。
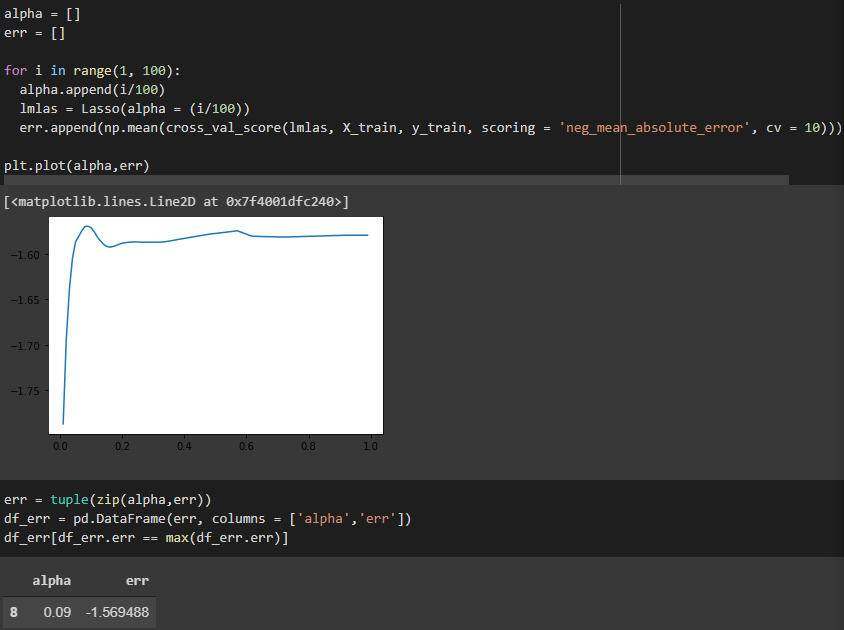
寻找套索回归的最佳 alpha 值
岭回归
与 Lasso 类似,岭回归(Ridge Regression)也增加了惩罚。它使用 L2 正则化。与套索回归的唯一不同之处在于,它使用系数的平方大小,而不是绝对值。
岭回归的 MAE 为 1.85,这与 Lasso 相比不算大。

用于岭回归的 MAE
我们也可以尝试找到最佳的收缩参数,但根据图来看,我们已经有了最佳的收缩参数。
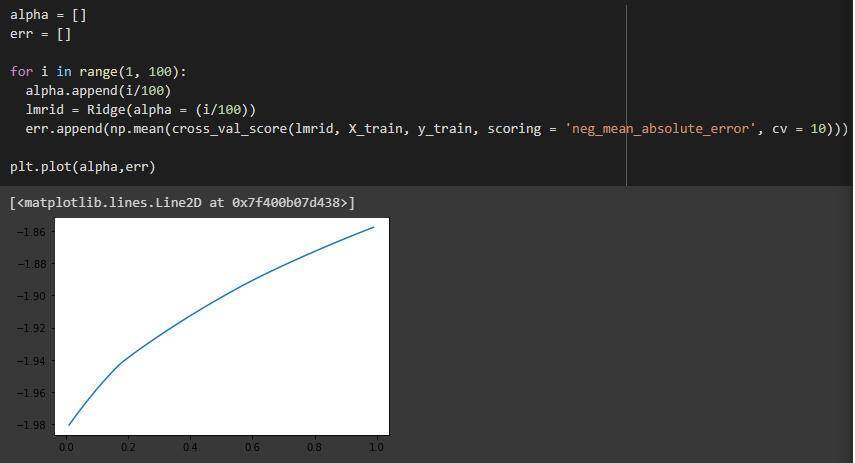
绘图看看能否找到最佳收缩率
随机森林回归
基于树的模型可以是很好的模型,只要它们不是太深。
我们可以看到,随机深林的 MAE 为 1.61。

用于随机森林回归的 MAE
我们还可以尝试调整随机森林模型的超参数。使用 GridsearchCV 是调整参数的好方法。
下面是调整随机回归参数的方法。
使用最佳估计值,最佳 MAE 为 1.51。
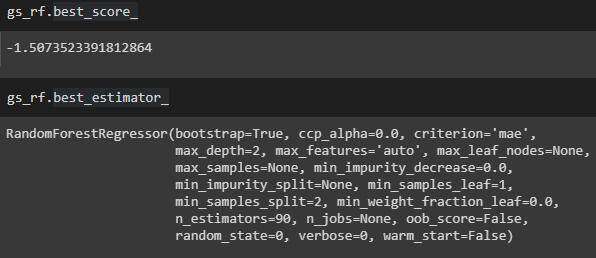
调整随机森林
XGBoost
另一个基于树的模型是 XGBoost。
用于 XGBoost 的 MAE 为 1.54。
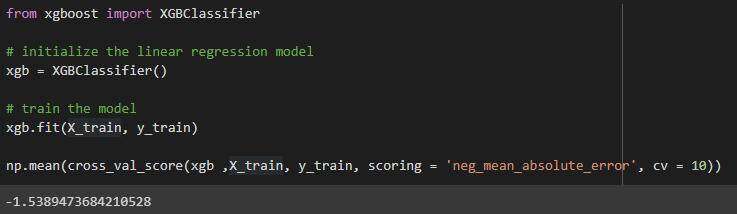
用于 XGBoost 的 MAE
我们也可以尝试调试超参数,就像我们对随机森林模型所做的那样。
调整后的 XGBoost 的 MAE 为 1.33。
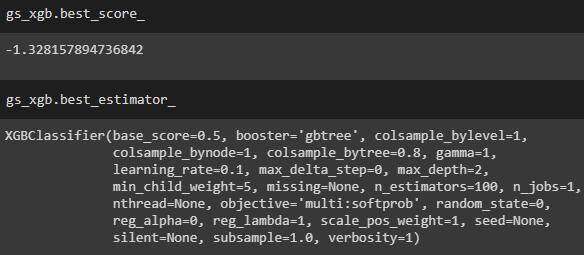
调整 XGBoost
比较所有模型的性能
为结束本教程,我们将比较构建的所有模型的性能。
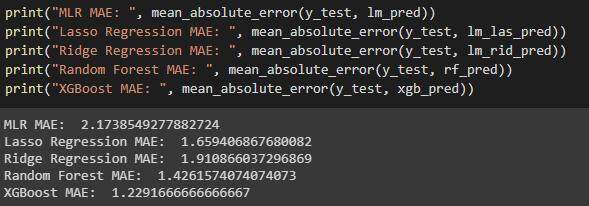
模型性能比较
我们看到,XGBoost 是最好的模型!平均而言,预测误差为 1.23 小时。
当然,你也可以花上几天的时间去寻找“最佳”模型,但同时,我们也希望自己的工作效率更高。
感谢阅读本文,在下一部教程中,我将讨论模型生产。
本文涉及的完整代码在这里。
作者介绍:
Jaemin Lee,专攻数据分析与数据科学,数据科学应届毕业生。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论